关于操作系统模块的一些介绍
开源工具和中间件服务
- 1: ActiveMQ
- 1.1: 服务端配置
- 2: ApacheHttp
- 2.1: apache日志记录真实ip-
- 2.2: apache限制某个目录下的php文件没有执行权限
- 2.3: apache在虚拟主机中实现用户验证
- 2.4: httpd2.4不能查看状态
- 2.5: 安装ApacheHttp
- 2.6: 禁止ip访问
- 2.7: 设置不允许访问文件
- 2.8: 自定义header
- 3: Docker
- 3.1: docker-compose
- 3.2: DockerNetword
- 3.3: 拉取并推送到阿里云docker仓库的shell脚本
- 3.4: 容器相关命令解析
- 4: ElasticSearch
- 5: K8S
- 5.1: 案例解析
- 5.1.1: 001创建一个名称为nginx的pod
- 5.1.2: 002进入名为nginx的pod
- 5.1.3: 003创建一个名称为nginx的deployment
- 5.1.4: 004模拟一次deployment的上线发布回滚
- 5.1.5: 005手动创建一个一定会发生故障推出的pod并跟踪这个pod
- 5.1.6: 005手动创建一个一定会发生故障推出的pod并跟踪这个pod
- 5.1.7: 007在k8s集群内使用nameServer进行网络访问
- 5.1.8: 008将外部服务纳入到k8s集群网络
- 5.1.9: 009让pod只在具有指定标签的节点上运行
- 5.1.10: 010部署ingress-nginx-controller
- 5.1.11: 011基于010实现一次灰度发布
- 5.1.12: 012HPA自动水平伸缩pod.md
- 5.2: K8S案例解析
- 5.3: K8S应用笔记
- 6: Nginx
- 6.1: 安装Nginx
- 7: ThingsBoard
- 8: JetBrains全家桶
- 9: certbot
- 10: easytier
- 10.1: 完全私有化部署
- 11: firebase
- 12: Git
- 12.1: 常见报错处理
- 13: Gitlab
- 13.1: 安装
- 13.2: 关于如何定义一个流水线
- 14: infinityfree
- 14.1: InfinityFree白嫖攻略
- 15: MyBatis
- 15.1: mybatisSql语句拼装
- 16: MySQL
- 16.1:
- 16.2:
- 16.3: MySQL通用
- 17: VPN
- 17.1: v2ray
- 18: zerotier
- 19: 通用数据库语言
- 20: 文件快传
1 - ActiveMQ
1.1 - 服务端配置
Mapping to JMS
场景: java客户端消费使用openwire协议连接 go客户端使用amqp协议,生产消息,采用默认配置将在java消费端获取到ascii码, 是由于消息头不一致造成的 使用transport.transformer=jms,将amqp消息头和消息体的编码方式转换成jms的消息头和消息体 java的客户端就可以正确接收到消息了 http://activemq.apache.org/amqp.html
There are three basic conversion strategies that can be used with AMQP and inter-operating with the JMS API.
| Strategy | Description |
|---|---|
native |
(Default) Wraps the bytes of the AMQP message into a JMS BytesMessage and maps the headers of the AMQP message to headers on the JMS message. |
raw |
Wraps the bytes of the AMQP message into a JMS BytesMessage. |
jms |
Maps headers of the AMQP message to JMS message headers and the body of the AMQP message to the JMS body. |
Set the transformer transport option on the transportConnector to the desired mapping strategy. For example, to inter-operate with JMS at the payload level, set the transformer option to jms:
<transportConnector name="amqp" uri="amqp://localhost:5672?transport.transformer=jms"/>
修改使用账号密码:
当前目录下,找到activemq.xml。滑到最底下 在节点前添加以下代码:
...
<!-- destroy the spring context on shutdown to stop jetty -->
<shutdownHooks>
<bean xmlns="http://www.springframework.org/schema/beans" class="org.apache.activemq.hooks.SpringContextHook" />
</shutdownHooks>
<!-- 添加访问ActiveMQ的账号密码 -->
<plugins>
<simpleAuthenticationPlugin>
<users>
<authenticationUser username="elink" password="elink888" groups="users,admins"/>
</users>
</simpleAuthenticationPlugin>
</plugins>
</broker>
2 - ApacheHttp
2.1 - apache日志记录真实ip-
默认情况下log日志格式为: LogFormat “%h %l %u %t "%r" %>s %b "%{Referer}i" "%{User-Agent}i"” combined 其中%h 是记录访问者的IP,如果在web的前端有一层代理,那么这个%h其实就是代理机器的IP,这不是我们想要的。在这种情况下, %{X-FORWARDED-FOR}i 字段会记录客户端真实的IP。所以log日志改为: LogFormat “%h %{X-FORWARDED-FOR}i %l %u %t "%r" %>s %b "%{Referer}i" "%{User-Agent}i"” combined
2.2 - apache限制某个目录下的php文件没有执行权限
为了安全期间,有时我们需要限制网站下的某些目录对于php脚本不能执行。 有两种方法可以参考:
- 使用.htaccess 文件限制
在要限制php执行的目录下,创建.htaccess文件,加入内容
php_flag engine off
- 使用apache的配置文件httpd.conf
在相关的虚拟主机段,加入
<Directory /www/htdocs/path>
php_admin_flag engine off
<filesmatch "(.*)php">
Order deny,allow
Deny from all
Allow from 127.0.0.1
</filesmatch>
</Directory>
2.3 - apache在虚拟主机中实现用户验证
##两种方法
方法一
虚拟主机配置文件中,需要加入 <Directory /data/web/test> AllowOverride AuthConfig
然后在虚拟主机的主目录,即DocumentRoot 目录下 vi /data/web/test/.htaccess
加入 AuthName “frank share web” AuthType Basic 这种要重启 下面的那种不需要重启 AuthUserFile /data/web/test/.htpasswd require valid-user
保存后,然后 创建apache的验证用户
htpasswd -c /data/web/test/.htpasswd test #第一次创建用户要用到-c 参数 第2次添加用户,就不用-c参数
如果你想修改密码,可以如下
htpasswd -m .htpasswd test2
重启apache,即可。
方法二
到此,你已经配置完成。下面介绍另一种方式: ################################## vi http.conf 在相应的虚拟主机配置文件段,加入 <Directory *> AllowOverride AuthConfig AuthName “自定义的” AuthType Basic AuthUserFile /data/.htpasswd // 这个目录你可以随便写一个,没有限制 require valid-user
保存后,然后 创建apache的验证用户
htpasswd 默认创建的密码只有前8位有效
按照如下命令创建密码 htpasswd -c .htpasswd user1 假如,密码为123456789 那么访问时,不管是输入 12345678 还是 123456789 甚至是 123456781234 都能顺利通过验证。这是为什么呢? htpasswd默认情况,是使用系统库中的crypt()函数来对密码明文进行单向加密的。在网上找到该函数的说明: crypt()将使用Data Encryption Standard(DES)演算法将参数key所指的字符串加以编码,key字符串长度仅取前8个字符,超过此长度的字符没有意义。参数salt为两个字 符组成的字符串,由a-z,A-Z,0-9,".",和"/“所组成,用来决定使用4096种不同内建表格的哪一个。函数执行成功后会返回指向编码过的字符串指针,参数key所指的字符串不会有所更动。编码过的字符串长度为13个字符,前两个字符为参数salt代表的字符串。
所以,如果你想创建超过8位的密码,请使用-m参数或者-s 参数,这两个参数分别表示创建的密码以MD5加密方式加密和以SHA方式加密。 htpasswd -c -m .htpasswd user1 这样创建的密码没有8位数限制了。
2.4 - httpd2.4不能查看状态
httpd无法apachectl status 直接查看状态,虽然没有大的影响。
但是让人十分不悦。解决方法如下。
1,先加查模块是否存在
[root@jingwangweilai ~]# apachectl -M |grep status
status_module (shared)
2,存在就忽略这一步,不存在去/etc/httpd/httpd.conf把这个模块注释掉去掉
LoadModule status_module modules/mod_status.so
3,添加如下字段
<Location /server-status>
SetHandler server-status
Require host localhost
</Location>
2.5 - 安装ApacheHttp
系统包安装
sudo apt install apache2 | sudo yum install httpd | sudo dnf install httpd
源码安装
# 这份文档应该已经过时了, 这是n年前整理的不保证有效性
源码编译安装httpd
> http://httpd.apache.org/download.cgi 下载httpd源码包
> http://apr.apache.org/ 下载apr and apr-uril
> http://www.pcre.org/ 下载pcre
> yum install gcc* -y
1.安装apr
```shell
[root@localhost apr-1.4.5]# ./configure --prefix=/usr/local/apr
[root@localhost apr-1.4.5]# make
[root@localhost apr-1.4.5]# make install
2.安装apr-util
[root@localhost apr-util-1.3.12]# ./configure --prefix=/usr/local/apr-util -with-apr=/usr/local/apr/
[root@localhost apr-util-1.3.12]# make
[root@localhost apr-util-1.3.12]# make install
3.安装pcre
[root@localhost pcre-8.31]# ./configure --prefix=/usr/local/pcre
[root@localhost pcre-8.31]# make
[root@localhost pcre-8.31]# make install
4.安装apache
groupadd apache
useradd -r -g apache apache -s /sbin/nologin
编译参数
./configure --prefix=/usr/local/apache24 --sysconfdir=/etc/httpd --enable-so --enable-cgi --enable-rewrite --with-zlib --with-pcre --with-apr=/usr/local/apr --with-apr-util=/usr/local/apr-util --with-pcre=/usr/local/pcre --enable-mpms-shared=all --with-mpm=event
--prefix=/usr/local/apache24 -- 安装位置
--with-apr=/usr/local/apr --依赖包
--with-apr-util=/usr/local/apr-util --依赖包
--with-pcre=/usr/local/pcre --依赖包
vim /etc/sysconfig/iptables
-A INPUT -m state --state NEW -m tcp -p tcp --dport 80 -j ACCEPT
service iptables restart
cd /usr/local/apache24
vim /etc/httpd/httpd.conf --配置配置文件
找到ServerName 打开
./bin/apachectl start
curl localhost
apache配置文件加上这句话,要不php编译完不能解析,需要重新编译安装
AddType application/x-httpd-php .php .phtml
2.6 - 禁止ip访问
NameVirtualHost 1.1.1.1
## 这里假设要禁止的ip为1.1.1.1
<VirtualHost 1.1.1.1>
ServerName 1.1.1.1
<Location />
Order Allow,Deny
Deny from all
</Location>
</VirtualHost>
2.4 Require all denied
## 实现拒绝直接通过1.1.1.1这个IP的任何访问请求,这时如果你用1.1.1.1访问,会提示拒绝访问
<VirtualHost 1.1.1.1>
DocumentRoot "/var/www/cainiaoer"
ServerName www.cainiaoer.com
</VirtualHost>
## 允许通过www.cainiaoer.com这个域名访问,主目录指向/var/www/cainiaoer(这里假设网站的根目录是/var/www/cainiaoer)
2.7 - 设置不允许访问文件
在配置文件"/usr/local/apache2/conf/httpd.conf" 中添加内容:
<Files "*.txt">
Require all denied
</Files>
2.8 - 自定义header
- 在设置自定义header前,需要先检测一下你的httpd是否加载了mod_headers
/usr/local/apache2/bin/apachectl -l
如果,显示有mode_headers.c 则是加载了这个模块,否则就需要重新编译一下了。
另外,如果你使用的是rpm安装的话,那肯定是已经加载了mod_headers这个模块的。
- 在httpd.conf 中加入
<IFModule mod_headers.c>
Header add MyHeader "Hello"
</IFModule>
保存后,重启apache就可以了
双引号中的内容为自定义内容。当然这里的"MyHeader"也是可以自定义的。
- 测试
curl -I http://localhost
看是否显示有 MyHeader “Hello”
3 - Docker
3.1 - docker-compose
docker-compose.yml中添加自定义网络
1. 如果是3.5以下版本(3.4及以下)
网络配置如下定义
networks:
自定义网络名1:#此名称在当前docker-compose文件中作为id出现,当前文件使用网络写 "自定义网络名1"即可
driver: "bridge"
运行后使用 docker network list
会创建一个名为: "目录名_自定义网络名1" 的docker网络
2. 在3.5版本的docker-compose.yml文件中可以定义网络
networks:
自定义网络2:
name: 自定义网络2-custom
driver: "bridge"
此时添加了name属性,在运行 docker network list 命令则创建的docker网络名即为 "自定义网络2-custom"
在docker-compose.yml中使用已有的网络
此以3.4 3.5版本文件为例
此时另一个目录中的docker-compose.yml文件的容器启动也要使用 "目录名_自定义网络名1" 的docker网络
可以如下写法
networks:
自定义网络3:#"自定义网络3" 作为当前文件中的一个ID标记使用
external:
name: 自定义网络2-custom || 目录名_自定义网络名1
#(也就是在运行docker network list 命令能打印出来的网络名称)
覆盖镜像中启动的默认命令
command: [“bundle”, “exec”, “thin”, “-p”, “3000”]
3.2 - DockerNetword
Docker 网络与容器互联
简单整理一下 Docker 中 network 子命令,以及 docker 中相关 network 方面的内容。
在安装完 Docker 后,使用 ifconfig -a 查看可以看到多出一个虚拟的 docker0 接口,这个接口是 Docker 默认的网关地址。
不同 Network driver 介绍
Docker 容器默认有三种连接方式:
- bridge
- host
- none
bridge 模式
Docker 默认会生成一个 docker0 网桥,如果不指定,默认创建的容器都会默认走此网桥,使用 bridge 模式联网。默认 bridge 会产生 docker0 的虚拟接口,在宿主机上可以使用 ifconfig -a 来查看,一般的网关地址是 172.17.0.1,所有的容器都会使用这个地址作为网关,容器的 IP 地址会从 172.17.0.2 到 172.17.0.254 这个范围 IP 段划分。
此模式下,容器可以单向连接外网,外网或宿主要访问容器则需要容器映射端口。
host 模式
host 模式等同于容器直接使用物理机的网络,宿主机的 IP 就是容器的 IP,端口也可以直接调用。
此模式的缺点是容易造成宿主机和容器端口冲突,而且降低了安全性,在有多个容器的情况下使用也不方便。
none
none 模式,也就是容器默认不联网的模式。通常会合自定义网络的容器一起使用。non 在 swarm 服务中不可用。
macvlan
还有两种更高级的网络模式,overlay 和 macvlan,分别用于跨宿主机的容器通信和给每个容器分配一个 mac 地址。
macvlan 网络允许给容器分配一个 MAC 地址,这样在网络中就可以以物理设备存在。Docker daemon 会通过 Mac 地址将流量导给容器。在处理一些历史遗留应用,期望直接使用物理网络的场景非常适合使用 macvlan.
overlay
Overlay 网络会连接多个 Docker daemon,开启 swarm 服务来相互通信。也可以通过 overlay 网络来帮助 swarm 服务和独立容器之间的通信,或者帮助两个独立的容器,或者帮助不同的 Docker daemons。通过 overlay 就不需要系统级别在不同容器中的路由了。
Docker 本身也有一个 link 指令,可以用于连接两个容器,但这命令的缺点是只能单向连接,也就是 A 和 B 两个容器,只能 A 访问 B 或者 B 访问 A,做不到 AB 之间直接同时互访。
使用
创建新网络
docker network create network-name
docker network create -d bridge network-name
使用 ls 查看:
docker network ls
审查 network 信息:
docker network inspect network-id
删除网络:
docker network rm name
docker network rm network-id
创建时指定 IP 段:
docker network create --subnet=192.168.1.0/24 net-name
创建名为 net-name 的网络,默认 bridge,IP 段是: 192.168.1.0 ~ 192.168.1.255
3.3 - 拉取并推送到阿里云docker仓库的shell脚本
#!/bin/bash
#使用脚本前 需要登录到阿里云仓库 命令
#docker login --username=#{你的用户名} registry.cn-beijing.aliyuncs.com
#输入密码
image_name=$1
image_tag=$2
# 检查 image_name 是否为空
if [ -z "$image_name" ];then
echo "请输入镜像名称"
exit 1
fi
# 检查 image_tag 是否为空
if [ -z "$image_tag" ]; then
echo "image_tag 为空,赋值为 latest"
image_tag="latest"
fi
# 在本地拉去镜像
image_all="$image_name":"$image_tag"
sudo docker pull "$image_all"
# 获取镜像id
image_id=`sudo docker images --filter=reference=$image_all -q`
# 获取镜像名称
image_last_part=$(echo "$image_name" | awk -F'/' '{print $NF}')
aliyun_image_path=registry.cn-beijing.aliyuncs.com/#{这里填你的命名空间}$/"$image_last_part":"$image_tag"
sudo docker tag $image_id $aliyun_image_path
sudo docker push $aliyun_image_path
sudo docker rmi $aliyun_image_path
echo $aliyun_image_path
sudo docker images
#sudo docker $image_all
3.4 - 容器相关命令解析
一、命名空间相关
貌似在docker里面没有命名空间
容器启动的时候,默认会在默认的命名空间中启动 即 default
可以通过-n 指定命名空间
Docker 使用的 containerd 下面的命名空间默认是 moby,而不是 default
所以假如我们有用 docker 启动容器,那么我们也可以通过 ctr -n moby
同样 Kubernetes 下使用的 containerd 默认命名空间是 k8s.io,所以我们可以使用 ctr -n k8s.io 来查看 Kubernetes 下面创建的容器
- 查看命名空间
ctr ns ls
- 创建命名空间
ctr ns create my-ns
- 删除命名空间
ctr ns rm my-ns
ctr ns remove my-ns
- 指定命名空间操作
ctr -n test i ls -q
一、镜像相关命令
- 拉取镜像
- docker
docker pull nginx:latest
- containerd
ctr i pull docker.io/library/nginx:latest ctr i pull –all-platforms docker.io/library/nginx:latest
- 列出镜像
- docker
docker images
- containerd
ctr i ls [-q 只显示名称]
- 镜像重新打标签
- docker
docker tag nginx:latest harbor.k8s.local/course/nginx:latest
- containerd
ctr i tag docker.io/library/nginx:alpine harbor.k8s.local/course/nginx:alpine
- 删除镜像
- docker
docker rmi nginx:latest docker rmi hashID
- containerd
ctr i rm docker.io/library/nginx:alpine
- 推送本地镜像
- docker
- containerd
- 将镜像挂载到主机目录
- docker
不知道,每用过
- containerd
ctr i mount docker.io/library/nginx:alpine /mnt
- 将镜像从主机目录上卸载
- docker
不知道,每用过
- containerd
ctr i unmount /mnt 因为挂在的时候挂在到了 /mnt 所以卸载的时候直接卸载 /mnt
- 将镜像导出为压缩包 在使用export命令是需要添加–platform参数,否则会报错。
- docker
不知道,每用过
- containerd
ctr image export –all-platforms nginx.tar.gz
ctr image export –platform=linux/amd64 nginx.tar.gz
- 从压缩包导入镜像
- docker
不知道,每用过
- containerd
ctr i import nginx.tar.gz
如果 直接导入可能会出现类似于 ctr: content digest sha256:xxxxxx not found 的错误,要解决这个办法需要 pull 所有平台镜像:
➜ ~ ctr i pull --all-platforms docker.io/library/nginx:alpine
➜ ~ ctr i export --all-platforms nginx.tar.gz docker.io/library/nginx:alpine
➜ ~ ctr i rm docker.io/library/nginx:alpine
➜ ~ ctr i import nginx.tar.gz
二、容器相关
容器相关的很多操作在docker中从来每用过, 也就不去写对比的命令了, 以后用到再查
- 创建容器, 理解就是只创建不运行, 在docker里从来每这么用过
- docker
- containerd
ctr c create docker.io/library/nginx:alpine nginx
- 列出容器
- docker
docker ps | docker ps -a
- containerd
ctr c ls
- 查看容器详细配置
- docker
- containerd
ctr c info nginx
- 删除容器
- docker
- containerd 除了使用 rm 子命令之外也可以使用 delete 或者 del 删除容器
ctr c rm nginx
- 启动容器
- docker
docker start nginx
- containerd
ctr task start -d nginx
- 暂停容器
- docker
docker stop nginx
- containerd
ctr task pause nginx
- 恢复容器
- docker
docker start nginx
- containerd
ctr t resume nginx #resume 继续,重新开始
- 启动容器
- docker
- containerd
- 进入容器
- docker
docker exec -it nginx sh
- containerd 必须要指定 –exec-id 参数,这个 id 可以随便写,只要唯一就行
ctr task exec –exec-id 0 -t nginx sh
- 查看正在运行的容器
- docker
docker ps containerd ctr task ls [-q]
- 杀掉容器
- docker 没用过
docker kill -s KILL mynginx
- containerd ctr里面没有stop 只能暂停或者杀掉
ctr t kill nginx
- 删除容器
- docker
docker rm nginx
- containerd 要想删除一个正在运行的Task,必须先kill掉这个task,然后才能删除
ctr c rm nginx
- 取容器的内存、CPU 和 PID 的限额与使用量
- docker
docker stats
- containerd
ctr t metrics nginx
- 查看容器中所有进程在宿主机中的 PID
- docker
docker top nginx
- containerd
ctr task ps nginx
- 查看容器的日志
- docker
docker logs nginx
- containerd
ctr task logs nginx
4 - ElasticSearch
4.1 - 安装
4.2 - 杂谈
docker启动的es如何安装插件
docker exec -it 容器名 bash
bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.1.1/elasticsearch-analysis-ik-7.1.1.zip
或者
先在物理机下载好插件的压缩包
docker cp /tmp/elasticsearch-analysis-ik-6.5.4.zip elasticsearch:/usr/share/elasticsearch/plugins
然后
docker exec -it 容器名 bash
如果是docker-compose 启动的, 执行down命令后,安装的插件就被还原了
一个字段不能被聚合时
PUT /索引名/_mapping/
{
"properties":{
"字段名":{
"type":"text",
"fielddata": true
}
}
}
5 - K8S
5.1 - 案例解析
5.1.1 - 001创建一个名称为nginx的pod
# 通过命令创建一个pod容器
kubectl run nginx --image=docker.io/library/nginx:1.21.6
pod/nginx created
# 查看default命名空间下的pod
kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 17s 172.20.177.22 k8s-192-168-0-19 <none> <none>
# 访问pod
curl 172.20.177.22
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
5.1.2 - 002进入名为nginx的pod
本案例基于案例001
kubectl -it exec nginx -- bash
root@nginx:/# echo 'Hello K8S' > /usr/share/nginx/html/index.html
root@nginx:/# exit
exit
curl 172.20.177.22
Hello K8S
5.1.3 - 003创建一个名称为nginx的deployment
本案例基于案例001
kubectl create deployment nginx --image=docker.io/library/nginx:1.21.6
deployment.apps/nginx created
kubectl get deployment -w
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 0/1 1 0 15s
nginx 1/1 1 1 15s
kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
# 注意这里pod名称分段 784757bdfb为rs的hash
nginx-784757bdfb-z6gd6 1/1 Running 0 45s 172.20.177.24 k8s-192-168-0-19 <none> <none>
kubectl scale deployment nginx --replicas=2
deployment.apps/nginx scaled
kubectl get deployment -w
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/2 2 1 70s
nginx 2/2 2 2 75s
kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-784757bdfb-2q58h 1/1 Running 0 25s 172.20.182.149 k8s-192-168-0-11 <none> <none>
nginx-784757bdfb-z6gd6 1/1 Running 0 85s 172.20.177.24 k8s-192-168-0-19 <none> <none>
5.1.4 - 004模拟一次deployment的上线发布回滚
创建一个名为nginx的deployment初始副本为2,然后修改nginx的镜像tag,最后在回滚到之前的版本
root@k8s-192-168-0-17:/home/node1# kubectl create deployment nginx --image=docker.io/library/nginx:1.21.6 --replicas=2
deployment.apps/nginx created
root@k8s-192-168-0-17:/home/node1# kubectl get deployment nginx -o wide -w
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
nginx 2/2 2 2 22s nginx docker.io/library/nginx:1.21.6 app=nginx
root@k8s-192-168-0-17:/home/node1# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-784757bdfb-bs4rt 1/1 Running 0 42s 172.20.182.150 k8s-192-168-0-11 <none> <none>
nginx-784757bdfb-jjmzv 1/1 Running 0 43s 172.20.177.25 k8s-192-168-0-19 <none> <none>
# 注意这里的版本号
root@k8s-192-168-0-17:/home/node1# curl 172.20.182.150/1
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx/1.21.6</center>
</body>
</html>
root@k8s-192-168-0-17:/home/node1# kubectl set image deployment/nginx nginx=docker.io/library/nginx:1.25.1
deployment.apps/nginx image updated
root@k8s-192-168-0-17:/home/node1# kubectl annotate deployment/nginx kubernetes.io/change-cause="image updated to 1.25.1"
deployment.apps/nginx annotated
root@k8s-192-168-0-17:/home/node1# kubectl rollout history deployment nginx
deployment.apps/nginx
REVISION CHANGE-CAUSE
1 <none>
2 image updated to 1.25.1
# 注意这里的版本号 已经换成 1.25.1 了
root@k8s-192-168-0-17:/home/node1# curl 172.20.182.153/1
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx/1.25.1</center>
</body>
</html>
root@k8s-192-168-0-17:/home/node1# kubectl set image deployments/nginx nginx=nginx:1.21.6
deployment.apps/nginx image updated
root@k8s-192-168-0-17:/home/node1# kubectl annotate deployment/nginx kubernetes.io/change-cause="image updated to 1.21.6"
deployment.apps/nginx annotated
root@k8s-192-168-0-17:/home/node1# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-796bdc6f77-66hcm 1/1 Running 0 35s 172.20.182.154 k8s-192-168-0-11 <none> <none>
nginx-796bdc6f77-n5wng 1/1 Running 0 49s 172.20.177.29 k8s-192-168-0-19 <none> <none>
# 注意这里的版本号 已经换成 1.21.6 了
root@k8s-192-168-0-17:/home/node1# curl 172.20.182.154/1
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx/1.21.6</center>
</body>
</html>
## 假设我们这次升级版本出现了问题 那么我们查看历史,我们要回滚到1.25.1
root@k8s-192-168-0-17:/home/node1# kubectl rollout history deployment nginx
deployment.apps/nginx
REVISION CHANGE-CAUSE
1 <none>
2 image updated to 1.25.1
3 image updated to 1.21.6
# --to-revision=2 就是上一步的索引
root@k8s-192-168-0-17:/home/node1# kubectl rollout undo deployment nginx --to-revision=2
deployment.apps/nginx rolled back
# 这里版本号已经回滚到1.25.1
root@k8s-192-168-0-17:/home/node1# curl 172.20.177.30/1
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx/1.25.1</center>
</body>
</html>
# 我们再查询rs
root@k8s-192-168-0-17:/home/node1# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-784757bdfb 0 0 0 19m
nginx-796bdc6f77 0 0 0 16m
nginx-79df7c55d7 2 2 2 19m
5.1.5 - 005手动创建一个一定会发生故障推出的pod并跟踪这个pod
```shell
root@k8s-192-168-0-17:~# kubectl run busybox --image=busybox --dry-run=client -o yaml > testHealthz.yaml
root@k8s-192-168-0-17:~# vim testHealthz.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: busybox
name: busybox
spec:
containers:
- image: busybox
name: busybox
resources: {}
# 添加启动参数模拟启动后10s就以返回码1退出
args:
- /bin/sh
- -c
- sleep 10; exit 1
dnsPolicy: ClusterFirst
# 将默认的Always 改成 OnFailure
restartPolicy: OnFailure
status: {}
root@k8s-192-168-0-17:~# kubectl apply -f testHealthz.yaml
pod/busybox created
root@k8s-192-168-0-17:~# kubectl get pod -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox 1/1 Running 0 22s 172.20.177.32 k8s-192-168-0-19 <none> <none>
nginx-796bdc6f77-7r5ts 1/1 Running 0 10m 172.20.177.31 k8s-192-168-0-19 <none> <none>
busybox 0/1 Error 0 32s 172.20.177.32 k8s-192-168-0-19 <none> <none>
busybox 1/1 Running 1 (8s ago) 38s 172.20.177.32 k8s-192-168-0-19 <none> <none>
busybox 0/1 Error 1 (19s ago) 49s 172.20.177.32 k8s-192-168-0-19 <none> <none>
busybox 0/1 CrashLoopBackOff 1 (14s ago) 61s 172.20.177.32 k8s-192-168-0-19 <none> <none>
busybox 1/1 Running 2 (19s ago) 66s 172.20.177.32 k8s-192-168-0-19 <none> <none>
busybox 0/1 Error 2 (30s ago) 77s 172.20.177.32 k8s-192-168-0-19 <none> <none>
busybox 0/1 CrashLoopBackOff 2 (13s ago) 89s 172.20.177.32 k8s-192-168-0-19 <none> <none>
busybox 1/1 Running 3 (34s ago) 110s 172.20.177.32 k8s-192-168-0-19 <none> <none>
busybox 0/1 Error 3 (44s ago) 2m 172.20.177.32 k8s-192-168-0-19 <none> <none>
busybox 0/1 CrashLoopBackOff 3 (16s ago) 2m14s 172.20.177.32 k8s-192-168-0-19 <none> <none>
busybox 1/1 Running 4 (48s ago) 2m46s 172.20.177.32 k8s-192-168-0-19 <none> <none>
busybox 0/1 Error 4 (58s ago) 2m56s 172.20.177.32 k8s-192-168-0-19 <none> <none>
busybox 0/1 CrashLoopBackOff 4 (15s ago) 3m10s 172.20.177.32 k8s-192-168-0-19 <none> <none>
# 一直再running error CrashLoopBackOff 并且kubelet会以指数级的退避延迟(10s,20s,40s等)重新启动它们,上限为5分钟
```
5.1.6 - 005手动创建一个一定会发生故障推出的pod并跟踪这个pod
部署一个mytest的 Deployment 副本数量为10,之后模拟一次发版导致了失败,我们用Readiness来保证不健康的pod不被请求
1. 先准备两个Deployment配置
```yaml
# cat myapp-v1.yaml 是可以通过健康检查
apiVersion: apps/v1
kind: Deployment
metadata:
name: mytest
spec:
replicas: 10 # 这里准备10个数量的pod
selector:
matchLabels:
app: mytest
template:
metadata:
labels:
app: mytest
spec:
containers:
- name: mytest
image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2
args:
- /bin/sh
- -c
- sleep 10; touch /tmp/healthy; sleep 30000
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10
periodSeconds: 5
# cat myapp-v2.yaml v2是不能通过检测的 模拟升级发版失败
apiVersion: apps/v1
kind: Deployment
metadata:
name: mytest
spec:
strategy:
rollingUpdate:
maxSurge: 35% # 滚动更新的副本总数最大值(以10的基数为例):10 + 10 * 35% = 13.5 --> 14
maxUnavailable: 35% # 可用副本数最大值(默认值两个都是25%): 10 - 10 * 35% = 6.5 --> 7
replicas: 10
selector:
matchLabels:
app: mytest
template:
metadata:
labels:
app: mytest
spec:
containers:
- name: mytest
image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2
args:
- /bin/sh
- -c
- sleep 30000 # 可见这里并没有生成/tmp/healthy这个文件,所以下面的检测必然失败
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10
periodSeconds: 5
```
2. 启动myapp-v1.yaml
```shell
kubectl apply -f myapp-v1.yaml
# 别忘了加备注
kubectl annotate deployment/mytest kubernetes.io/change-cause="kubectl apply --filename=myapp-v1.yaml"
# 过一会就会看到pod状态为Running
root@k8s-192-168-0-17:~# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mytest-59887f89f5-fq6hv 1/1 Running 0 112s 172.20.182.159 k8s-192-168-0-11 <none> <none>
mytest-59887f89f5-gpsnx 1/1 Running 0 113s 172.20.182.157 k8s-192-168-0-11 <none> <none>
mytest-59887f89f5-gwkmg 1/1 Running 0 113s 172.20.177.33 k8s-192-168-0-19 <none> <none>
mytest-59887f89f5-ltdw9 1/1 Running 0 115s 172.20.182.156 k8s-192-168-0-11 <none> <none>
mytest-59887f89f5-m4vkn 1/1 Running 0 112s 172.20.177.37 k8s-192-168-0-19 <none> <none>
mytest-59887f89f5-m9z2t 1/1 Running 0 112s 172.20.182.160 k8s-192-168-0-11 <none> <none>
mytest-59887f89f5-mq9n6 1/1 Running 0 113s 172.20.177.35 k8s-192-168-0-19 <none> <none>
mytest-59887f89f5-nwsc9 1/1 Running 0 115s 172.20.177.34 k8s-192-168-0-19 <none> <none>
mytest-59887f89f5-pzm68 1/1 Running 0 115s 172.20.177.36 k8s-192-168-0-19 <none> <none>
mytest-59887f89f5-qd74c 1/1 Running 0 113s 172.20.182.158 k8s-192-168-0-11 <none> <none>
```
3. 启动myapp-v2.yaml
```shell
kubectl apply -f myapp-v2.yaml
# 别忘了加备注
kubectl annotate deployment/mytest kubernetes.io/change-cause="kubectl apply --filename=myapp-v2.yaml"
# 过一会查看deployment 输出结果 会稳定在以下结果
root@k8s-192-168-0-17:~# kubectl get deployment mytest
NAME READY UP-TO-DATE AVAILABLE AGE
mytest 7/10 7 7 3m43s
# READY 现在正在运行的只有7个pod
# UP-TO-DATE 表示当前已经完成更新的副本数:即 7 个新副本
# AVAILABLE 表示当前处于 READY 状态的副本数
# 查看pod
root@k8s-192-168-0-17:~# kubectl get pod
NAME READY STATUS RESTARTS AGE
mytest-59887f89f5-fq6hv 1/1 Running 0 5m9s
mytest-59887f89f5-gpsnx 1/1 Running 0 5m10s
mytest-59887f89f5-gwkmg 1/1 Running 0 5m10s
mytest-59887f89f5-ltdw9 1/1 Running 0 5m12s
mytest-59887f89f5-m9z2t 1/1 Running 0 5m9s
mytest-59887f89f5-pzm68 1/1 Running 0 5m12s
mytest-59887f89f5-qd74c 1/1 Running 0 5m10s
mytest-8586c6547d-6sqwt 0/1 Running 0 2m19s
mytest-8586c6547d-b9kql 0/1 Running 0 2m20s
mytest-8586c6547d-cgkrj 0/1 Running 0 2m7s
mytest-8586c6547d-dw6kv 0/1 Running 0 2m18s
mytest-8586c6547d-ht4dq 0/1 Running 0 2m19s
mytest-8586c6547d-v7rh9 0/1 Running 0 2m8s
mytest-8586c6547d-vqn6w 0/1 Running 0 2m7s
# 查看deployment的信息
root@k8s-192-168-0-17:~# kubectl describe deployment mytest
...
Replicas: 10 desired | 7 updated | 14 total | 7 available | 7 unavailable
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 5m46s deployment-controller Scaled up replica set mytest-59887f89f5 from 0 to 10
Normal ScalingReplicaSet 2m52s deployment-controller Scaled up replica set mytest-8586c6547d from 0 to 4
Normal ScalingReplicaSet 2m50s deployment-controller Scaled down replica set mytest-59887f89f5 from 10 to 7
Normal ScalingReplicaSet 2m45s deployment-controller Scaled up replica set mytest-8586c6547d from 4 to 7
```
4. 如此我们保证了集群中有7个可用的pod
下面来解析一下整个过程
maxSurge:
规定了滚动更新过程中pod副本数可以超过总副本数的上限。配置项可以是一个具体的数字也可以是一个比例,如果是比例则会向上取整
我们的例子副本总数是10 maxSurge: 35% 所以 10 + 10 * 35% = 13.5 --> 14
所以对mytest这个deployment的副本描述Replicas: 10 desired | 7 updated | 14 total | 7 available | 7 unavailable
10个目标值 7个已经更新 14为最大值 7个可用 7个不可用
maxUnavailable:
控制滚动过程中最大pod不可用数量。同样可以是一个数字也可以是一个比例。如果是比例则向上取整
我们例子中 maxUnavailable:35% 所以 10 - 10 * 35% = 6.5 --> 7
我们本次滚动更新的完整过程为
1) 根据maxSurge得到最大副本数14 所以 先创建4个新版本的pod副本,使副本总数达到14
2) 然后根据maxUnavailable 的到最大不可用数量为7 14-7(最大不可用数)=7(最小可用数) 所以销毁3个旧版本的pod
3) 3个旧版本pod销毁完成之后,再创建3个新版本pod使总副本数保持14
4) 当新版本pod通过Readiness检测后,会使可用pod副本超过7个
5) 再销毁更多旧pod使可用副本保持7个。
6) 随着旧pod销毁,新pod会自动创建,使副本数保持14
7) 依此类推一直到全部更新完成。
我们的实际情况在第4步卡住了。新的pod无法通过Readiness的检测。
此时在实际生产环境中我们需要rollout undo 来回滚上一个版本保证集群整体
```shell
root@k8s-192-168-0-17:~# kubectl rollout history deployment mytest
deployment.apps/mytest
REVISION CHANGE-CAUSE
1 kubectl apply --filename=myapp-v1.yaml
2 kubectl apply --filename=myapp-v2.yaml
root@k8s-192-168-0-17:~# kubectl rollout undo deployment mytest --to-revision=1
deployment.apps/mytest rolled back
# 然后 观察全局pod的变化过程
kubectl get pod -w
```
5.1.7 - 007在k8s集群内使用nameServer进行网络访问
1. 准备一个svc的yaml配置
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: web
status:
loadBalancer: {}
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx:1.21.6
name: nginx
- 启动一个工具pod容器并验证
kubectl run -it --rm busybox --image=registry.cn-shanghai.aliyuncs.com/acs/busybox:v1.29.2 -- sh
# --rm的意思是当推出pod容器 sh 时, pod容器会自动删除
/ # wget -q -O- http://web
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
5.1.8 - 008将外部服务纳入到k8s集群网络
案例使用python开放一个http服务,并将其纳入到k8s集群网络
- 先启动一个非k8s集群的服务
# 在任意节点启动一个http服务这里用python3
node1@k8s-192-168-0-17:~$ python3 -m http.server 8088 # 这里启动了8088端口
- 创建一个svc的yaml
# 注意我这里把两个资源的yaml写在一个文件内,在实际生产中,我们经常会这么做,方便对一个服务的所有资源进行统一管理,不同资源之间用"---"来分隔
apiVersion: v1
kind: Service
metadata:
name: myhttp
spec:
ports:
- name: http-port
port: 3306 # Service 暴露端口 3306
protocol: TCP
type: ClusterIP # 仅集群内访问
---
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: myhttp-slice # 指定这个endpointslice的名称
labels:
kubernetes.io/service-name: myhttp # 必须关联Service 关联了哪个svc
addressType: IPv4
ports:
- name: http-port # 与Service端口名一致
port: 8088 # 外部服务实际端口 这样旧相当于把8088给了 myhttp 这个svc中名称为http-port的port
protocol: TCP
endpoints:
- addresses:
- "192.168.0.17" # 外部http服务IP
conditions:
ready: true # 标记端点可用
- 验证
node1@k8s-192-168-0-17:~$ sudo kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 5d2h
myhttp ClusterIP 10.68.48.233 <none> 3306/TCP 9s
new-nginx NodePort 10.68.194.158 <none> 81:30759/TCP 4h19m
node1@k8s-192-168-0-17:~$ curl 10.68.48.233:3306
<!DOCTYPE HTML>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Directory listing for /</title>
</head>
<body>
<h1>Directory listing for /</h1>
<hr>
<ul>
<li><a href=".ansible/">.ansible/</a></li>
<li><a href=".bash_history">.bash_history</a></li>
<li><a href=".bash_logout">.bash_logout</a></li>
<li><a href=".bashrc">.bashrc</a></li>
<li><a href=".cache/">.cache/</a></li>
<li><a href=".profile">.profile</a></li>
<li><a href=".ssh/">.ssh/</a></li>
<li><a href=".sudo_as_admin_successful">.sudo_as_admin_successful</a></li>
<li><a href=".viminfo">.viminfo</a></li>
<li><a href=".Xauthority">.Xauthority</a></li>
<li><a href="httpproxy.yaml">httpproxy.yaml</a></li>
<li><a href="nginx-svc.yaml">nginx-svc.yaml</a></li>
<li><a href="nginx.yaml">nginx.yaml</a></li>
<li><a href="planet">planet</a></li>
<li><a href="ubuntu-install-k8s/">ubuntu-install-k8s/</a></li>
</ul>
<hr>
</body>
</html>
- 备注
这里svc使用的是ClusterIP 如果使用了NodePort
sudo kubectl patch svc myhttp -p ‘{“spec”:{“type”:“NodePort”}}’
那么同样可以 通过集群内任意ip进行访问这里就不重复演示了
5.1.9 - 009让pod只在具有指定标签的节点上运行
1. 创建deployment的yaml
```yaml
# 修改好yaml配置
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: nginx
name: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
resources: {}
nodeSelector: # <--- 这里
apps/nginx: "true" # <--- 基于这个label来选择
status: {}
```
2. 应用这个配置
```shell
kubectl apply -f node-selector.yaml
```
3. 查看pod, 这时没有节点具有 apps/nginx=true
```shell
node1@k8s-192-168-0-17:~$ sudo kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-756c69b65f-7vfv5 0/1 Pending 0 2m5s <none> <none> <none> <none>
nginx-756c69b65f-8gl9m 0/1 Pending 0 2m4s <none> <none> <none> <none>
```
4. 节点打label
```shell
# 先尝试给主节点打label
kubectl label node k8s-192-168-0-17 apps/nginx=true
kubectl get node k8s-192-168-0-17 --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-192-168-0-17 Ready,SchedulingDisabled master 5d3h v1.33.1 apps/nginx=true,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-192-168-0-17,kubernetes.io/os=linux,kubernetes.io/role=master
```
可以看到虽然给17主节点打了标签,但是还是无法调度因为主节点状态是SchedulingDisabled的, 这个状态优先级更高
```shell
# 尝试给worker节点打label
kubectl label node k8s-192-168-0-19 apps/nginx=true
kubectl get node k8s-192-168-0-19 --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-192-168-0-19 Ready node 5d3h v1.33.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-192-168-0-19,kubernetes.io/os=linux,kubernetes.io/role=node
# 再查看pod, 马上从pending到ContainerCreating又转到了running 并且node都在19这个节点上,如果没有节点标签。pod是基本平均分布的
kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-756c69b65f-7vfv5 0/1 ContainerCreating 0 5m38s
nginx-756c69b65f-8gl9m 0/1 ContainerCreating 0 5m37s
kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-756c69b65f-7vfv5 1/1 Running 0 7m22s 172.20.177.63 k8s-192-168-0-19 <none> <none>
nginx-756c69b65f-8gl9m 1/1 Running 0 7m21s 172.20.177.62 k8s-192-168-0-19 <none> <none>
```
5.1.10 - 010部署ingress-nginx-controller
基于这个ingress-nginx-controller 创建一个nginx应用 然后再配置https访问
必看:
-
在大规模生产集群上,ingree-nginx 独占一台节点,他就只跑 ingree-nginx 不要再跑其他pod了
-
kind: ConfigMap 段落的data.worker-processes = 实际服务器ingress-nginx-controller 所在的pod的那个节点的服务器的cpu核数(最好比实际核心数-1)
-
kind: ConfigMap 段落的data.worker-cpu-affinity 目前配置是空, 留空就行
-
kind: DaemonSet 如果是自建集群使用DaemonSet类型的控制器。 他会把容器端口映射到宿主机上这样就不用再使用NodePort映射了如果是是云上比如阿里云的ack 集群,使用Deployment类型的控制器,因为ack的pod使用的是云主机的弹性网卡他可以和你的云主机在同一个网络(网段)所以在这一段的内容中默认用了kind: DaemonSet 如果要用kind: Deployment 那么需要检查 “Deployment need” 和 “DaemonSet need"跟随的一些配置项
-
基于kind: DaemonSet|Deployment的resources(资源配置)如果limits分配的资源和requests分配的资源是一致的,那么这个pod在k8s集群中的优先级是最高的。当我们集群资源不够时, k8s会驱逐一些优先级低的pod。保证高优先级
-
如果日志报错提示 “mount: mounting rw on /proc/sys failed: Permission denied”, 那么就打开 privileged: true、procMount: Default、runAsUser: 0 这三条注释的内容,如果不报错就不用管他
-
给对应节点打标签
nodeSelector:
boge/ingress-controller-ready: "true"
打标签的方法 kubectl label node ${节点的hostname} boge/ingress-controller-ready=true
查看标签的方法 kubectl get node –show-labels
删除标签的方法 kubectl label node ${节点的hostname} boge/ingress-controller-ready-
- 基于ingress-nginx独立一台节点部署的情况。
给这个节点打上标签后。最好再给这个节点标记上污点
打污点的方法是 kubectl taint nodes xx.xx.xx.xx boge/ingress-controller-ready=“true”:NoExecute
去掉污点的方法是 kubectl taint nodes xx.xx.xx.xx boge/ingress-controller-ready:NoExecute-
如果给节点打上了污点需要把下面这段注释打开,
tolerations:
- effect: NoExecute # effect: NoExecute:表示节点污点的驱逐效果,会驱逐已运行但不耐受的Pod
key: boge/ingress-controller-ready
operator: Equal # 要求value必须完全匹配(若为Exists则只需key存在)
value: "true"
他的作用是Kubernetes中Pod的容忍度(Toleration)定义,用于控制Pod能否调度到带有特定污点(Taint)的节点上
所以上面这段的配置含义是
- 允许Pod被调度到带有boge/ingress-controller-ready=true:NoExecute污点的节点上,确保它们只运行在特定节点。
基于ingress-nginx-controller 创建一个nginx应用 然后再配置https访问
新建nginx.yaml
---
kind: Service
apiVersion: v1
metadata:
name: new-nginx
spec:
selector:
app: new-nginx
ports:
- name: http-port
port: 80
protocol: TCP
targetPort: 80
---
# 新版本k8s的ingress配置
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: new-nginx
annotations:
#kubernetes.io/ingress.class: "nginx" 这是被放弃的api方式
nginx.ingress.kubernetes.io/force-ssl-redirect: "false"
nginx.ingress.kubernetes.io/whitelist-source-range: 0.0.0.0/0
nginx.ingress.kubernetes.io/configuration-snippet: |
if ($host != 'www.boge.com' ) {
rewrite ^ http://www.boge.com$request_uri permanent;
}
spec:
ingressClassName: nginx-master
rules:
- host: boge.com
http:
paths:
- backend:
service:
name: new-nginx
port:
number: 80
path: /
pathType: Prefix
- host: m.boge.com
http:
paths:
- backend:
service:
name: new-nginx
port:
number: 80
path: /
pathType: Prefix
- host: www.boge.com
http:
paths:
- backend:
service:
name: new-nginx
port:
number: 80
path: /
pathType: Prefix
# tls:
# - hosts:
# - boge.com
# - m.boge.com
# - www.boge.com
# secretName: boge-com-tls
# tls secret create command:
# kubectl -n <namespace> create secret tls boge-com-tls --key boge-com.key --cert boge-com.csr
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: new-nginx
labels:
app: new-nginx
spec:
replicas: 3 # 数量可以根据NODE节点数量来定义
selector:
matchLabels:
app: new-nginx
template:
metadata:
labels:
app: new-nginx
spec:
containers:
#--------------------------------------------------
- name: new-nginx
image: nginx:1.21.6
env:
- name: TZ
value: Asia/Shanghai
ports:
- containerPort: 80
volumeMounts:
- name: html-files
mountPath: "/usr/share/nginx/html"
#--------------------------------------------------
- name: busybox
image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2
args:
- /bin/sh
- -c
- >
while :; do
if [ -f /html/index.html ];then
echo "[$(date +%F\ %T)] ${MY_POD_NAMESPACE}-${MY_POD_NAME}-${MY_POD_IP}" > /html/index.html
sleep 1
else
touch /html/index.html
fi
done
env:
- name: TZ
value: Asia/Shanghai
- name: MY_POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: MY_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
volumeMounts:
- name: html-files
mountPath: "/html"
- mountPath: /etc/localtime
name: tz-config
#--------------------------------------------------
volumes:
- name: html-files
emptyDir:
medium: Memory
sizeLimit: 10Mi
- name: tz-config
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
---
kubectl apply -f nginx.yaml
kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
new-nginx nginx-master boge.com,m.boge.com,www.boge.com 10.68.216.0 80 9m51s
kubectl -n kube-system get pod -o wide|grep nginx-ingress
nginx-ingress-controller-6vtl4 1/1 Running 0 3h1m 192.168.0.11 k8s-192-168-0-11 <none> <none>
nginx-ingress-controller-tg6pq 1/1 Running 0 3h3m 192.168.0.19 k8s-192-168-0-19 <none> <none>
可以看到pod已经在 11 和19两个节点上运行了
此时我们在集群中的其他节点上修改宿主机的hosts文件,添加配置
192.168.0.19|192.168.0.11 boge.com m.boge.com www.boge.com 都可以
然后用
curl www.boge.com
[2025-07-08 07:09:25] default-new-nginx-6df56b5c4b-hktqc-172.20.177.13
上面已经可以通过域名访问了。然后我们来配置https, 这里就用自签名了
先生成一个私钥
openssl genrsa -out boge.key 2048
再基于key生成tls证书(注意:这里我用的*.boge.com,这是生成泛域名的证书,后面所有新增加的三级域名都是可以用这个证书的)
openssl req -new -x509 -key boge.key -out boge.csr -days 360 -subj /CN=*.boge.com
把证书创建给k8s集群的命名空间中
kubectl -n
kubectl get secret
NAME TYPE DATA AGE
boge-com-tls kubernetes.io/tls 2 25m
然后修改nginx.yaml文件
nginx.ingress.kubernetes.io/force-ssl-redirect: "false" # 改成true
rewrite ^ http://www.boge.com$request_uri permanent; # 改成https://
spec:
tls:
- hosts:
- www.boge.com
- boge.com
- m.boge.com
secretName: boge-com-tls (导入到集群的证书名称)
重新应用nginx.yaml
再在命令行访问http的就会提示301跳转
curl http://www.boge.com
<html>
<head><title>301 Moved Permanently</title></head>
<body>
<center><h1>301 Moved Permanently</h1></center>
<hr><center>nginx</center>
</body>
</html>
所以此时我们用chrome浏览器 访问http://www.boge.com 就会跳转到https://www.boge.com 由于是自签名证书所以是不安全的,直接继续就好了
5.1.11 - 011基于010实现一次灰度发布
实现一次灰度发布,实现将50%的流量打到旧的nginx 50打到新的nginx
kubectl create deployment old-nginx --image=nginx:1.21.6 --replicas=1
deployment.apps/old-nginx created
kubectl expose deployment old-nginx --port=80 --target-port=80
service/old-nginx exposed
# 修改nginx.yaml
# 在kind: Ingress的matadata.annotations 中添加如下内容
nginx.ingress.kubernetes.io/service-weight: |
new-nginx: 50, old-nginx: 50
在 spec.rules 中 host: www.boge.com 的部分 http.paths 中添加如下内容
- backend:
service:
name: old-nginx # 老版本服务
port:
number: 80
path: /
pathType: Prefix
# 最终重新应用 nginx.yaml
kubectl apply -f nginx.yaml
service/new-nginx unchanged
ingress.networking.k8s.io/new-nginx configured
deployment.apps/new-nginx unchanged
再通过浏览器访问 https://www.boge.com/ 就会发现几乎是一半打到new-nginx上一般打到old-nginx上
5.1.12 - 012HPA自动水平伸缩pod.md
- 先准备一个svc 和 deployment
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: web
status:
loadBalancer: {}
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx:1.21.6
name: nginx
resources:
limits: # 因为我这里是测试环境,所以这里CPU只分配50毫核(0.05核CPU)和20M的内存
cpu: "50m"
memory: 20Mi
requests: # 保证这个pod初始就能分配这么多资源
cpu: "50m"
memory: 20Mi
- 创建一个hpa
# autoscale 表示自动伸缩
# web 是hpa的名称
# --max=3 表示最大扩容数量为3
# --min=1 表示最小扩容数量为1
# --cpu-percent=50 表示当CPU使用率超过50%时扩容
kubectl autoscale deployment web --max=3 --min=1 --cpu-percent=30
kubectl get hpa -w
- 再启动一个终端 启动一个临时pod
kubectl run -it --rm busybox --image=registry.cn-shanghai.aliyuncs.com/acs/busybox:v1.29.2 -- sh
/ # while :;do wget -q -O- http://web;done
- 回到前一个终端
# 查看 kubectl get hpa -w 的输出
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web Deployment/web cpu: 0%/30% 1 3 1 30s
web Deployment/web cpu: 58%/30% 1 3 1 107s
web Deployment/web cpu: 100%/30% 1 3 2 2m4s
web Deployment/web cpu: 100%/30% 1 3 3 2m22s
web Deployment/web cpu: 95%/30% 1 3 3 2m35s
# 至此可以推出跟踪
# 查看hpa web 的描述
kubectl describe hpa web
Name: web
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Thu, 10 Jul 2025 16:58:31 +0800
Reference: Deployment/web
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 76% (38m) / 30%
Min replicas: 1
Max replicas: 3
Deployment pods: 3 current / 3 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited True TooManyReplicas the desired replica count is more than the maximum replica count
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 101s horizontal-pod-autoscaler New size: 2; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 84s horizontal-pod-autoscaler New size: 3; reason: cpu resource utilization (percentage of request) above target
- 停掉临时pod中的死循环并监听hpa的变化(这个收缩大概时需要在停止临时pod五分钟后才有效)
kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web Deployment/web cpu: 68%/30% 1 3 3 5m47s
web Deployment/web cpu: 83%/30% 1 3 3 5m54s
web Deployment/web cpu: 68%/30% 1 3 3 6m9s
web Deployment/web cpu: 0%/30% 1 3 3 6m24s (6分24s降为0)
kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web Deployment/web cpu: 0%/30% 1 3 3 9m45s
kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web Deployment/web cpu: 0%/30% 1 3 3 11m
web Deployment/web cpu: 0%/30% 1 3 3 11m
web Deployment/web cpu: 0%/30% 1 3 1 11m (11分收缩到1)
5.2 - K8S案例解析
helm的官方网站: https://helm.sh/zh/
helm是一个包管理器,用于Kubernetes,它可以将Helm Chart安装到Kubernetes集群中。Helm Chart是一个可重复使用的软件包,包含所有必需的资源定义,如Deployment、Service、Ingress、Secret、ConfigMap等。
helm相对k8s来说就像 apt 对Ubuntu yum对CentOS一样。
安装直接看官方文档
这里把命令补全的方式: https://helm.sh/zh/docs/helm/helm_completion/
针对bash 环境
https://helm.sh/zh/docs/helm/helm_completion_bash/ 贴出来
为当前会话提供命令补全
source <(helm completion bash)
为每个新的会话加载命令补全 (其他系统看文档)
Linux: helm completion bash | sudo tee /etc/bash_completion.d/helm
此处提供一个阿里云开发者中心的文档链接 https://developer.aliyun.com/article/1473220
命令演示
# 添加存储库 我这里添加了多个存储库
[root@master01 linux-amd64]# helm repo add stable http://mirror.azure.cn/kubernetes/charts
"stable" has been added to your repositories
[root@master01 linux-amd64]# helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
"aliyun" has been added to your repositories
# 更新所有仓库
[root@master01 linux-amd64]# helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "aliyun" chart repository
...Successfully got an update from the "stable" chart repository
Update Complete. ⎈Happy Helming!⎈
# 列出所有已配置的Helm仓库
[root@master01 linux-amd64]# helm repo list
NAME URL
stable http://mirror.azure.cn/kubernetes/charts
aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
# 搜索Helm仓库中可部署的Chart列表,Redis 为例
# 显示出了 两个仓库的 Chart 包
[root@master01 linux-amd64]# helm search repo redis
NAME CHART VERSION APP VERSION DESCRIPTION
aliyun/redis 1.1.15 4.0.8 Open source, advanced key-value store. It is of...
aliyun/redis-ha 2.0.1 Highly available Redis cluster with multiple se...
stable/prometheus-redis-exporter 3.5.1 1.3.4 DEPRECATED Prometheus exporter for Redis metrics
stable/redis 10.5.7 5.0.7 DEPRECATED Open source, advanced key-value stor...
stable/redis-ha 4.4.6 5.0.6 DEPRECATED - Highly available Kubernetes implem...
aliyun/sensu 0.2.0 Sensu monitoring framework backed by the Redis ...
stable/sensu 0.2.5 0.28 DEPRECATED Sensu monitoring framework backed by...
# 删除仓库
helm repo remove aliyun
5.3 - K8S应用笔记
K8S资源
-
Namespace(命名空间):
k8s通过命名空间实现资源隔离, 简称为ns
我们在获取任何资源时,如果不明确指定命名空间那么会缺省的使用default命名空间
-
Pod:
K8s的最小运行单元(不太恰当的比喻,一个pod就详单与用docker启动了一个容器)
-
Controller(控制器):
一般来说生产环境都是通过各种Controller来管理pod的生命周期。在控制器中每一个副本都是一个pod 通过控制副本数来控制pod的创建和销毁
常用的Controller有Deployment、DaemonSet、StatefulSet、Job、CronJob
最常用的是 Deployment(无状态应用)
-
replicas:副本数
Deployment通过replicas属性来指定副本数 简称rs
-
service: 不论单独创建的pod 还是通过deployment创建的pod 都是一个在k8s集群中的资源,他们的访问只能通过集群内ip访问,不能通过外网访问 所以需要通过service来暴露pod访问
service常用的四种网络
- ClusterIP:集群内部访问,分配了一个稳定的虚拟ip。
- NodePort:集群外部访问,会在每个node节点上分配固定的端口(端口范围30000-32767),流量可以从外部转发到service,
- LoadBalancer:集群外部访问,主要在云环境中使用。他为service创建一个外部的负载均衡器,可以通过云环境的负载均衡器将流量打到service上
- ExternalName:通过返回一个CNAME记录,可以将服务映射到集群外部的服务。
-
endpoints(v1 Endpoints is deprecated in v1.33+; use discovery.k8s.io/v1 EndpointSlice): 1.33以后被弃用
-
EndpointSlice: 用于描述Service的实际访问点。它包含了提供服务的Pod的IP地址和端口信息。
这些信息是Kubernetes实现服务发现和流量分发的关键依据
增(创建)
-
新增命名空间
kubectl create ns ${nsName} #新建一个deployment # 应用名 镜像地址 副本数 -
创建(运行)一个pod
kubectl run ${podName} --image=${镜像名称}:${镜像tag} -
心中一个deployment 应用
kubectl create deployment ${deploymentName} --image=${镜像名称}:${镜像tag} --replicas=${副本数} -
创建一个deployment的配置文件
kubectl create deployment nginx --image=nginx --dry-run=client -o yaml > nginx.yamlapiVersion: apps/v1 # 资源类型 kind: Deployment # 元数据,其中name是必填项 metadata: creationTimestamp: null labels: app: nginx name: nginx # 规格说明 spec: # 副本数 replicas: 1 selector: matchLabels: app: nginx strategy: {} # 定义 Pod 的模板,这是配置文件的重要部分 template: # metadata 定义 Pod 的元数据,至少要定义一个 label。label 的 key 和 value 可以任意指定 metadata: creationTimestamp: null labels: app: nginx # spec 描述 Pod 的规格,此部分定义 Pod 中每一个容器的属性,name 和 image 是必需的 spec: containers: - image: nginx name: nginx resources: {} status: {} -
创建一个service (svc)
# 创建一个新的service, 将流量从端口5000 映射到 pod 80 端口 kubectl create service clusterip new-nginx --tcp=5000:80 # 基于一个已存在的(名为new-nginx的)deployment 创建一个svc 网络模式为NodePort --port 是svc对外端口 kubectl expose deployment new-nginx --type=NodePort --port=81 --target-port=80 --dry-run=client -o yaml > nginx-svc.yamlapiVersion: v1 # <<<<<< v1 是 Service 的 apiVersion kind: Service # <<<<<< 指明当前资源的类型为 Service metadata: creationTimestamp: null labels: app: new-nginx name: new-nginx # <<<<<< Service 的名字为 nginx spec: ports: - port: 81 # <<<<<< 将 Service 的 80 端口映射到 Pod 的 80 端口,使用 TCP 协议 protocol: TCP targetPort: 80 selector: app: new-nginx # <<<<<< selector 指明挑选那些 label 为 run: nginx 的 Pod 作为 Service 的后端 status: loadBalancer: {} -
给命名空间添加tls证书
kubectl -n <namespace> create secret tls boge-com-tls(这相当于证书的名称) --key boge.key(私钥路径) --cert boge.csr(证书路径)
删
-
通用表达式
# 删除资源时 资源类型和名称必填 kubectl delete ${资源类型} ${资源名称}
删除命名空间时,命名空间一直terminating
deleteK8sNamespace() {
set -eo pipefail
die() { echo "$*" 1>&2 ; exit 1; }
need() {
which "$1" &>/dev/null || die "Binary '$1' is missing but required"
}
# checking pre-reqs
need "jq"
need "curl"
need "kubectl"
PROJECT="$1"
shift
test -n "$PROJECT" || die "Missing arguments: kill-ns <namespace>"
kubectl proxy &>/dev/null &
PROXY_PID=$!
killproxy () {
kill $PROXY_PID
}
trap killproxy EXIT
sleep 1 # give the proxy a second
kubectl get namespace "$PROJECT" -o json | jq 'del(.spec.finalizers[] | select("kubernetes"))' | curl -s -k -H "Content-Type: application/json" -X PUT -o /dev/null --data-binary @- http://localhost:8001/api/v1/namespaces/$PROJECT/finalize && echo "Killed namespace: $PROJECT"
}
deleteK8sNamespace 要被删除的命名空间
改
-
修改deployment pod 的副本数
kubectl scale deployment nginx --replicas=2 -
修改deployment 镜像地址
root@k8s-192-168-0-17:/home/node1# kubectl get deployment -o wide NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR nginx 2/2 2 2 11m nginx docker.io/library/nginx:1.25.1 app=nginx # ${deploymentName}值得是上面结果中NAME列 ${containerName}为CONTAINERS列的值 kubectl set image deployments/${deploymentName} ${containerName}=${镜像地址}:${镜像版本} # 所以本次修改镜像的命令为 # 原来 kubectl set image ...... --replicas (--replicas 标志在 Kubernetes v1.18.0 后已弃用) # 1. 先修改镜像 kubectl set image deployments/nginx nginx=nginx:1.21.6 # 2. 再添加注释 kubectl annotate deployment/nginx kubernetes.io/change-cause="image updated to 1.21.6" -
回滚
# 1. 先查询发布历史 kubectl rollout history deployment ${deploymentName} deployment.apps/nginx REVISION CHANGE-CAUSE 1 <none> 2 image updated to 1.25.1 3 image updated to 1.21.6 # 2. 根据历史索引进行回滚 kubectl rollout undo deployment ${deploymentName} --to-revision=2 -
修改svc的网络模式
kubectl patch svc ${svcName} -p '{"spec":{"type":"NodePort"}}' -
给节点打标签(label)
#kubectl label node 10.0.1.201 apps/nginx=true kubectl label node ${nodeName} ${labelName}=${labelValue} kubectl label ${资源名称} ${nodeName} ${labelName}=${labelValue} -
给节点删除一个标签(Label)
kubectl label node ${nodeName} ${labelName}-
查
-
返回一种资源类型列表
## 返回一种资源类型列表,资源名称选填 ## 除了查询命名空间意外,其他资源类型都可以添加 -n 参数指定命名空间。 kubectl (-n ${nsName}) get ${资源类型} (${资源名称}) -o wide -
返回多种资源类型列表
kubectl (-n ${nsName}) get ${资源类型},${资源类型} -o widekubectl describe ${资源类型} ${资源名称}
-
进入到某个pod容器内
kubectl -it exec ${podName} -- bash(一般用bash|sh,也可以执行其他命令) -
查看当前某种资源的yaml
sudo kubectl get ${资源类型} ${资源名称} -o yaml -
查看标签(label)
kubectl get node ${nodeName} --show-labels -
查看集群的证书
健康检查
当容器退出时返回码非0 则认为容器发生了故障,k8s会根据restartPolicy策略来执行后续操作
restartPolicy的美剧
Always:总是重启 OnFailure:容器退出时返回码非0,则重启 Never:不重启
k8s的pod可以通过 Liveness 和 Readiness 来检查pod是否健康
-
通过Liveness进行健康检查
apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness spec: restartPolicy: OnFailure containers: - name: liveness image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2 # 容器启动后立即创建/tmp/healthy 文件,30s后 删除 args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600 livenessProbe: exec: command: - cat - /tmp/healthy # 容器启动 10 秒后开始检测 initialDelaySeconds: 10 # 容器启动 10 秒之后开始检测 # 每5s检查执行一次 cat /tmp/healthy periodSeconds: 5 # 每隔 5 秒再检测一次 -
通过Readiness进行健康检查
我们可以通过Readiness检测来告诉K8s什么时候可以将pod加入到服务Service的负载均衡池中,对外提供服务,这个在生产场景服务发布新版本时非常重要,当我们上线的新版本发生程序错误时,Readiness会通过检测发布,从而不导入流量到pod内,将服务的故障控制在内部,在生产场景中,建议这个是必加的,Liveness不加都可以,因为有时候我们需要保留服务出错的现场来查询日志,定位问题,告之开发来修复程序。
Liveness 检测和 Readiness 检测是两种 Health Check 机制,如果不特意配置,Kubernetes 将对两种检测采取相同的默认行为,即通过判断容器启动进程的返回值是否为零来判断检测是否成功。
两种检测的配置方法完全一样,支持的配置参数也一样。
不同之处在于检测失败后的行为:Liveness 检测是重启容器;Readiness 检测则是将容器设置为不可用,不接收 Service 转发的请求。
Liveness 检测和 Readiness 检测是独立执行的,二者之间没有依赖,所以可以单独使用,也可以同时使用。
用 Liveness 检测判断容器是否需要重启以实现自愈;用 Readiness 检测判断容器是否已经准备好对外提供服务。
Readiness 检测的配置语法与 Liveness 检测完全一样
apiVersion: v1 kind: Pod metadata: labels: test: readiness name: readiness spec: restartPolicy: OnFailure containers: - name: readiness image: registry.cn-hangzhou.aliyuncs.com/acs/busybox:v1.29.2 args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600 readinessProbe: # 这里将livenessProbe换成readinessProbe即可,其它配置都一样 exec: command: - cat - /tmp/healthy #initialDelaySeconds: 10 # 容器启动 10 秒之后开始检测 periodSeconds: 5 # 每隔 5 秒再检测一次 startupProbe: # 启动探针,更灵活,完美代替initialDelaySeconds强制等待时间配置,启动时每3秒检测一次,一共检测100次 exec: command: - cat - /tmp/healthy failureThreshold: 100 periodSeconds: 3 timeoutSeconds: 1
部署一个生产环境下的Ingress-Nginx 控制器
必看:
-
在大规模生产集群上,ingree-nginx 独占一台节点,他就只跑 ingree-nginx 不要再跑其他pod了
-
kind: ConfigMap 段落的data.worker-processes = 实际服务器ingress-nginx-controller 所在的pod的那个节点的服务器的cpu核数(最好比实际核心数-1)
-
kind: ConfigMap 段落的data.worker-cpu-affinity 目前配置是空, 留空就行
-
kind: DaemonSet 如果是自建集群使用DaemonSet类型的控制器。 他会把容器端口映射到宿主机上这样就不用再使用NodePort映射了如果是是云上比如阿里云的ack 集群,使用Deployment类型的控制器,因为ack的pod使用的是云主机的弹性网卡他可以和你的云主机在同一个网络(网段)所以在这一段的内容中默认用了kind: DaemonSet 如果要用kind: Deployment 那么需要检查 “Deployment need” 和 “DaemonSet need"跟随的一些配置项
-
基于kind: DaemonSet|Deployment的resources(资源配置)如果limits分配的资源和requests分配的资源是一致的,那么这个pod在k8s集群中的优先级是最高的。当我们集群资源不够时, k8s会驱逐一些优先级低的pod。保证高优先级
-
如果日志报错提示 “mount: mounting rw on /proc/sys failed: Permission denied”, 那么就打开 privileged: true、procMount: Default、runAsUser: 0 这三条注释的内容,如果不报错就不用管他
-
给对应节点打标签
nodeSelector:
boge/ingress-controller-ready: "true"
打标签的方法 kubectl label node ${节点的hostname} boge/ingress-controller-ready=true
查看标签的方法 kubectl get node –show-labels
删除标签的方法 kubectl label node ${节点的hostname} boge/ingress-controller-ready-
- 基于ingress-nginx独立一台节点部署的情况。
给这个节点打上标签后。最好再给这个节点标记上污点
打污点的方法是 kubectl taint nodes xx.xx.xx.xx boge/ingress-controller-ready=“true”:NoExecute
去掉污点的方法是 kubectl taint nodes xx.xx.xx.xx boge/ingress-controller-ready:NoExecute-
如果给节点打上了污点需要把下面这段注释打开,
tolerations:
- effect: NoExecute # effect: NoExecute:表示节点污点的驱逐效果,会驱逐已运行但不耐受的Pod
key: boge/ingress-controller-ready
operator: Equal # 要求value必须完全匹配(若为Exists则只需key存在)
value: "true"
他的作用是Kubernetes中Pod的容忍度(Toleration)定义,用于控制Pod能否调度到带有特定污点(Taint)的节点上
所以上面这段的配置含义是
- 允许Pod被调度到带有boge/ingress-controller-ready=true:NoExecute污点的节点上,确保它们只运行在特定节点。
6 - Nginx
6.1 - 安装Nginx
apt安装(推荐)
一行命令: sudo apt install nginx
其他命令
sudo systemctl status nginx
sudo systemctl start nginx
sudo systemctl stop nginx
sudo systemctl restart nginx
sudo systemctl enable nginx
sudo systemctl disable nginx
源码安(不推荐)
github地址: https://github.com/nginx/nginx
我是一个菜鸟,本着能用就别折腾的原则。能用apt(yum) 就用apt(yum) 除非你是要处于一个学习的目的或者需要二次开发。
# 添加用户组和用户
groupadd nginx
useradd -r -g nginx nginx -s /sbin/nologin
# 源码安装三板斧
./configure --prefix=/usr/local/nginx --user=nginx --group=nginx --with-http_sub_module --with-http_dav_module --with-http_flv_module --with-http_mp4_module
make
make install
chown -R nginx.nginx /usr/local/nginx/
cd /usr/local/nginx/sbin/
# 启动
./nginx
7 - ThingsBoard
直接使用官方的云服务
https://thingsboard.io/docs/paas/
专业版相关链接(我们不配)
专业版服务端(Professional Edition 简称PE版): https://thingsboard.io/docs/pe/
PE Edge (专业版边缘): https://thingsboard.io/docs/pe/edge/
PE移动应用程序(专业版应用程序): https://thingsboard.io/docs/pe/mobile/
社区版相关链接
社区版服务端: https://thingsboard.io/docs/
边缘: https://thingsboard.io/docs/edge/
物联网网关: https://thingsboard.io/docs/iot-gateway/
移动应用程序: https://thingsboard.io/docs/mobile/
TBMQMQTT代理T): https://thingsboard.io/docs/mqtt-broker/
7.1 - 01快速入门
快速入门,文档相当于官网文档的翻译版本
docker compose 部署
cd workdir mkdir -p ./mytb-data ./mytb-logs
services:
thingsboard:
image: thingsboard/tb-postgres
container_name: thingsboard
restart: always
ports:
- "8080:9090"
- "7070:7070"
- "1883:1883"
- "5683-5688:5683-5688/udp"
volumes:
- ./mytb-data:/data
- ./mytb-logs:/var/log/thingsboard
docker compose pull docker compose up -d
浏览器访问 http://domain:8080 默认用户名: tenant@thingsboard.org 默认密码: tenant
源码部署
略
添加设备
单设备添加
单设备添加完全跟图操作即可
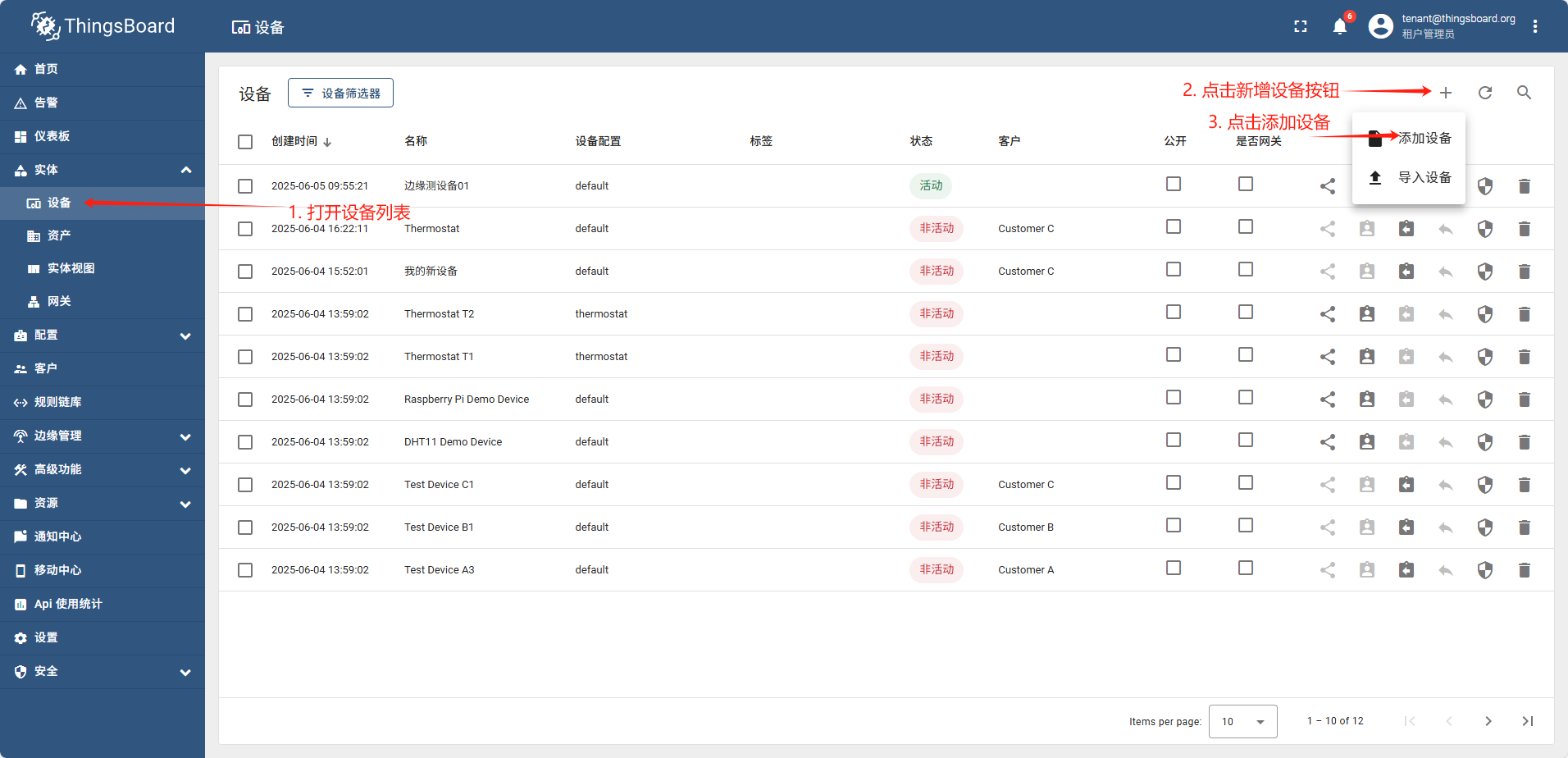
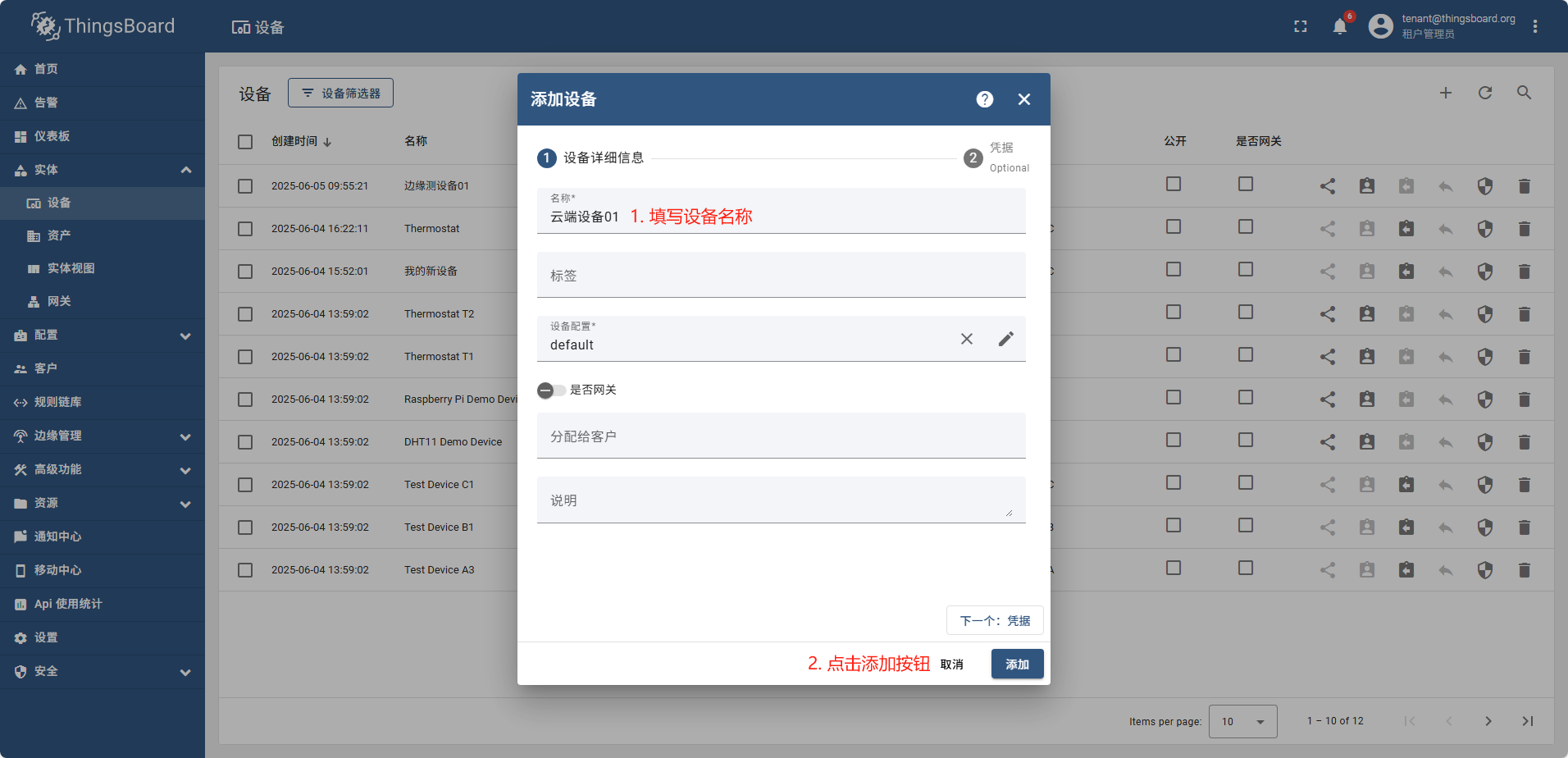
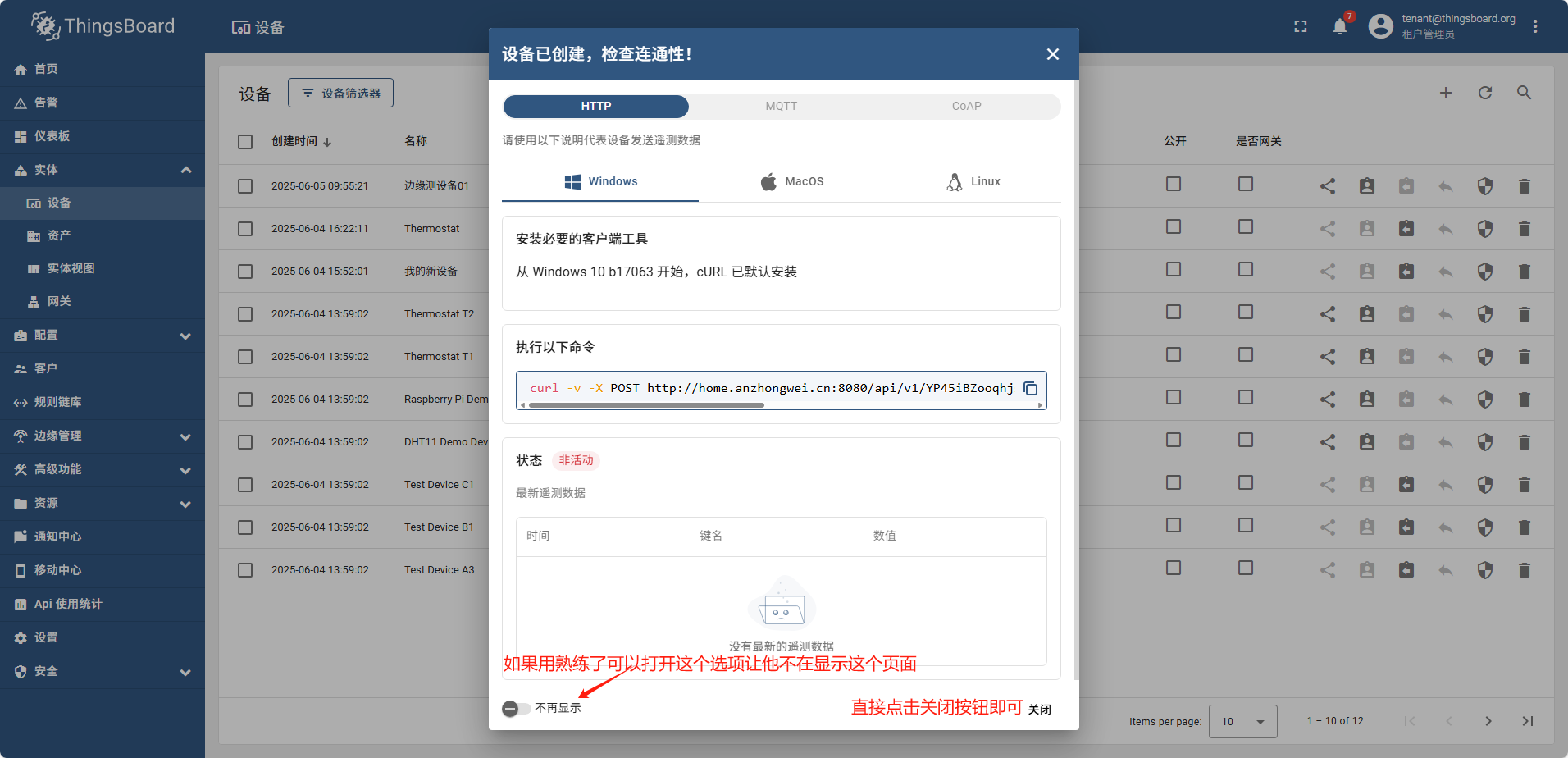
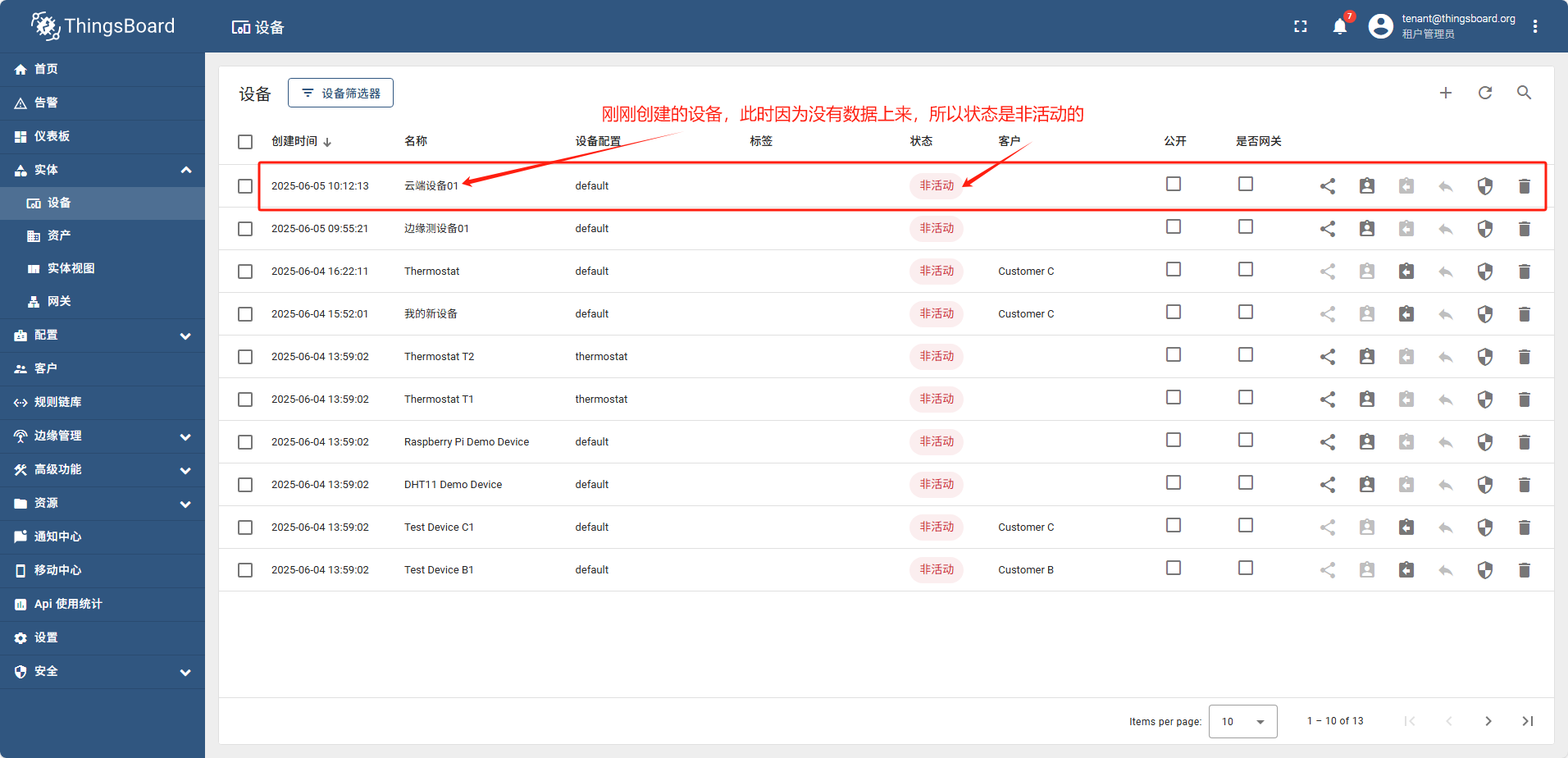
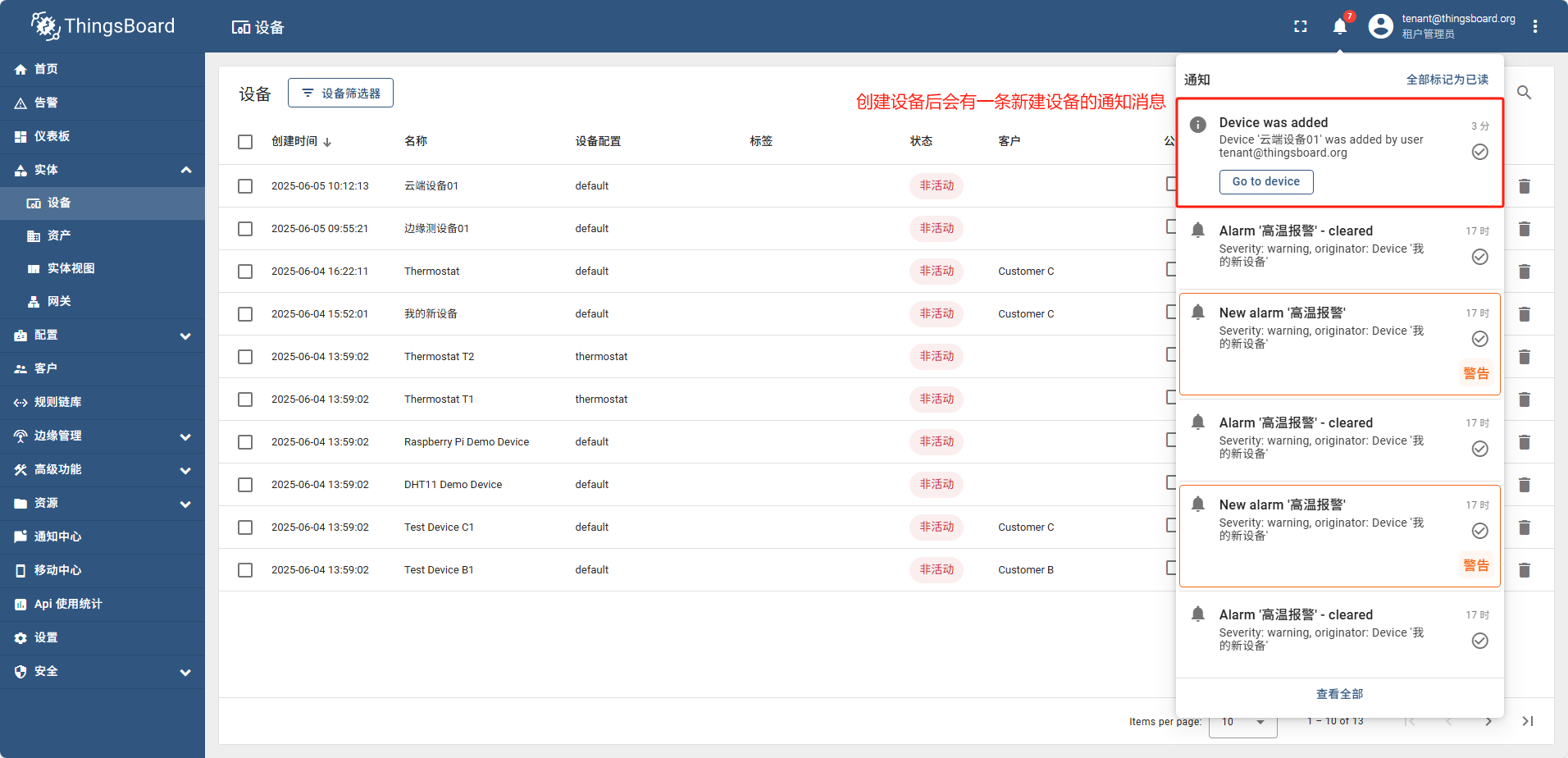
导入设备
准备测试数据: 新建csv文件,内容如下:
name,type,Data1,Data2,Data3,Data4,Data5,Data6,Data7,Data8,Data9,Data10
Device 1,testImport,123,test,TRUE,FALSE,123.55,test,test,test,test,AbfdgrRetGF45
Device 2,testImport,123,test,TRUE,FALSE,123.55,test,test,test,test,AbfdgrRetGF46
Device 3,testImport,123,test,TRUE,FALSE,123.55,test,test,test,test,AbfdgrRetGF47
Device 4,testImport,123,test,TRUE,FALSE,123.55,test,test,test,test,AbfdgrRetGF48
Device 5,testImport,123,,TRUE,FALSE,123.55,test,test,test,test,AbfdgrRetGF49
Device 6,testImport,123,test,TRUE,FALSE,123.55,test,test,test,test,AbfdgrRetGF50
Device 7,testImport,123,test,TRUE,FALSE,123.55,test,test,test,test,AbfdgrRetGF51
Device 8,testImport,123,test,TRUE,FALSE,123.55,test,test,test,test,AbfdgrRetGF52
Device 9,testImport,123,test,TRUE,FALSE,123.55,test,test,test,test,AbfdgrRetGF53
Device 10,testImport,123,test,TRUE,FALSE,123.55,test,test,test,test,AbfdgrRetGF54
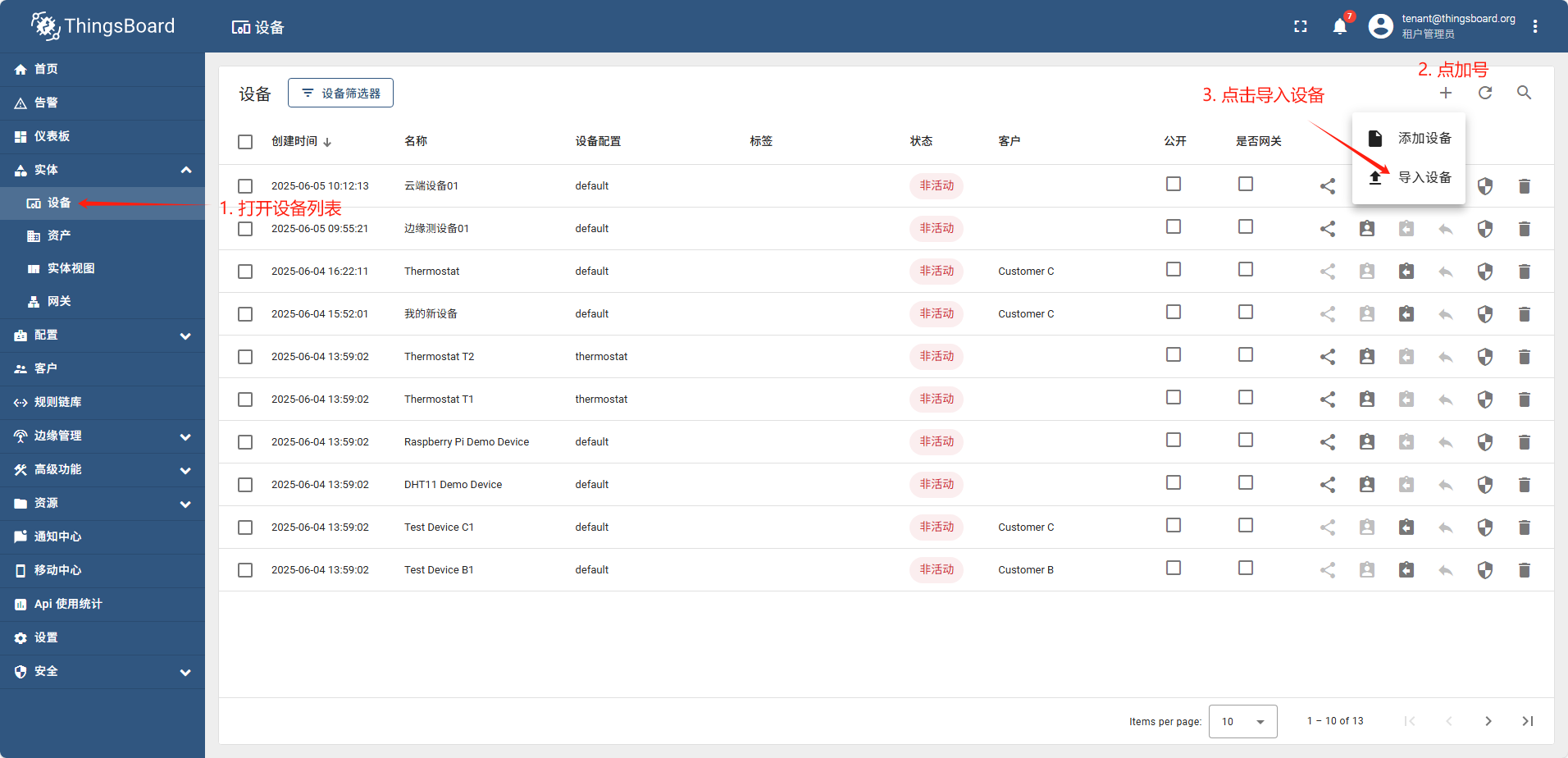
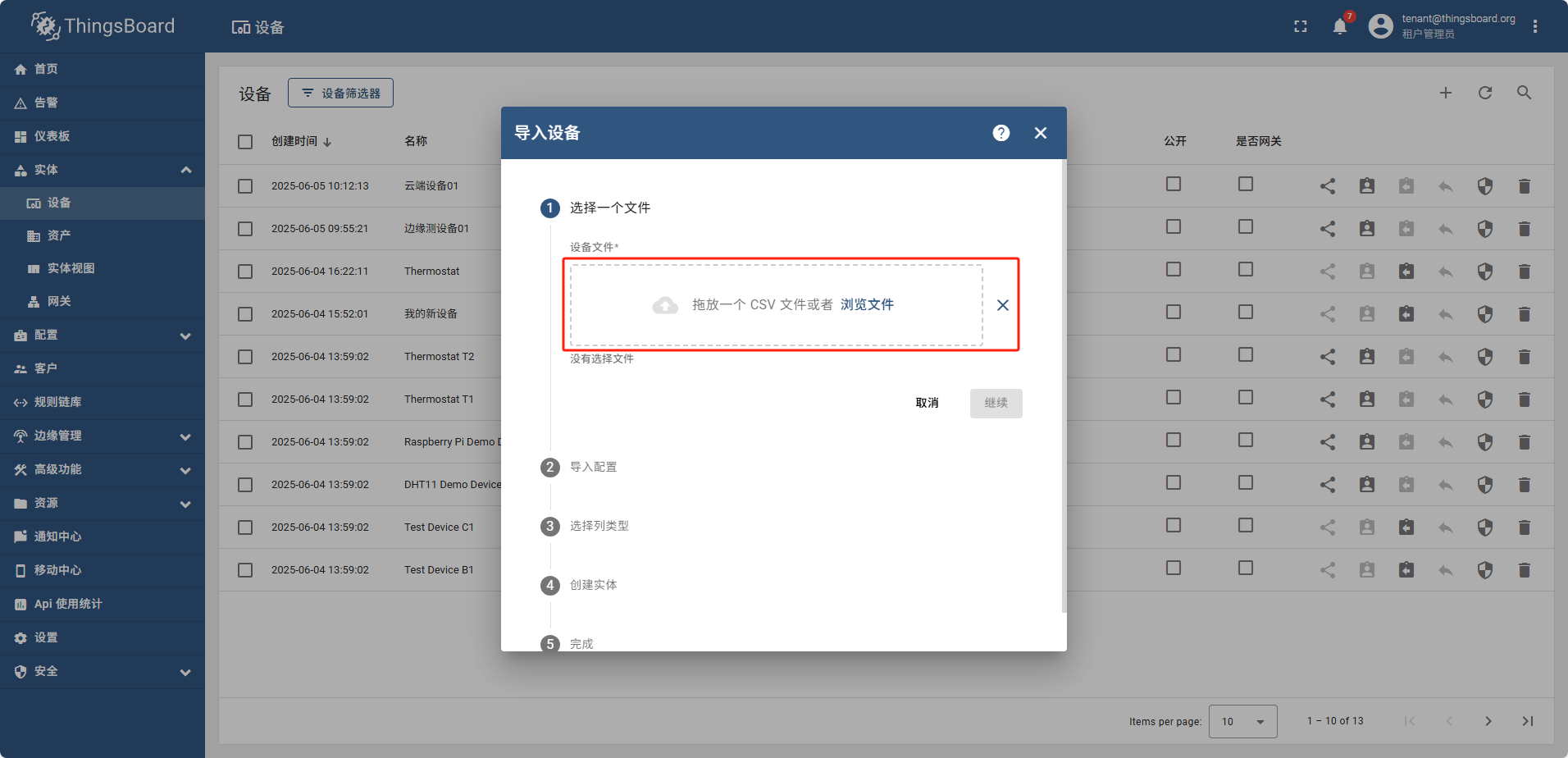
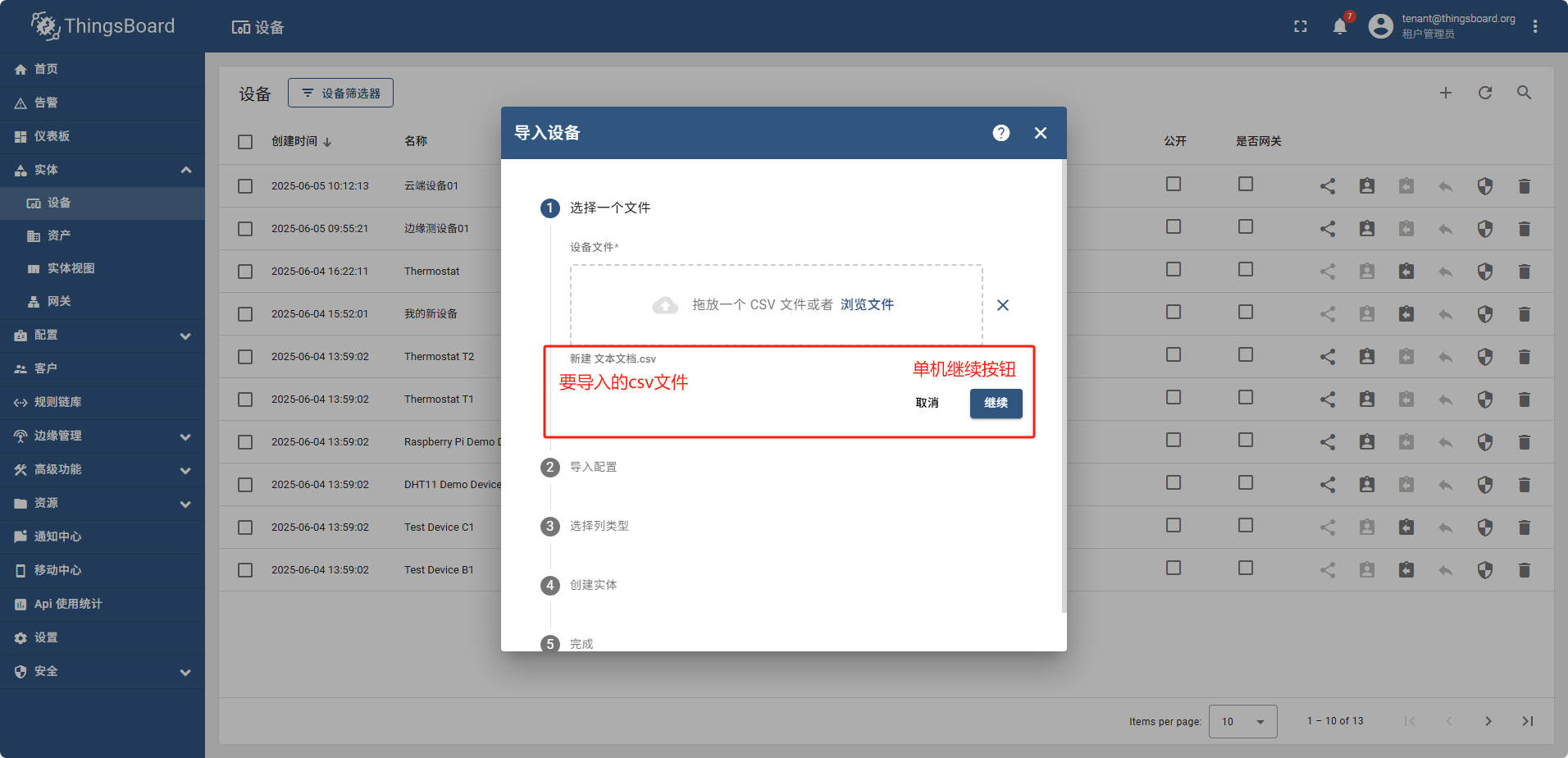
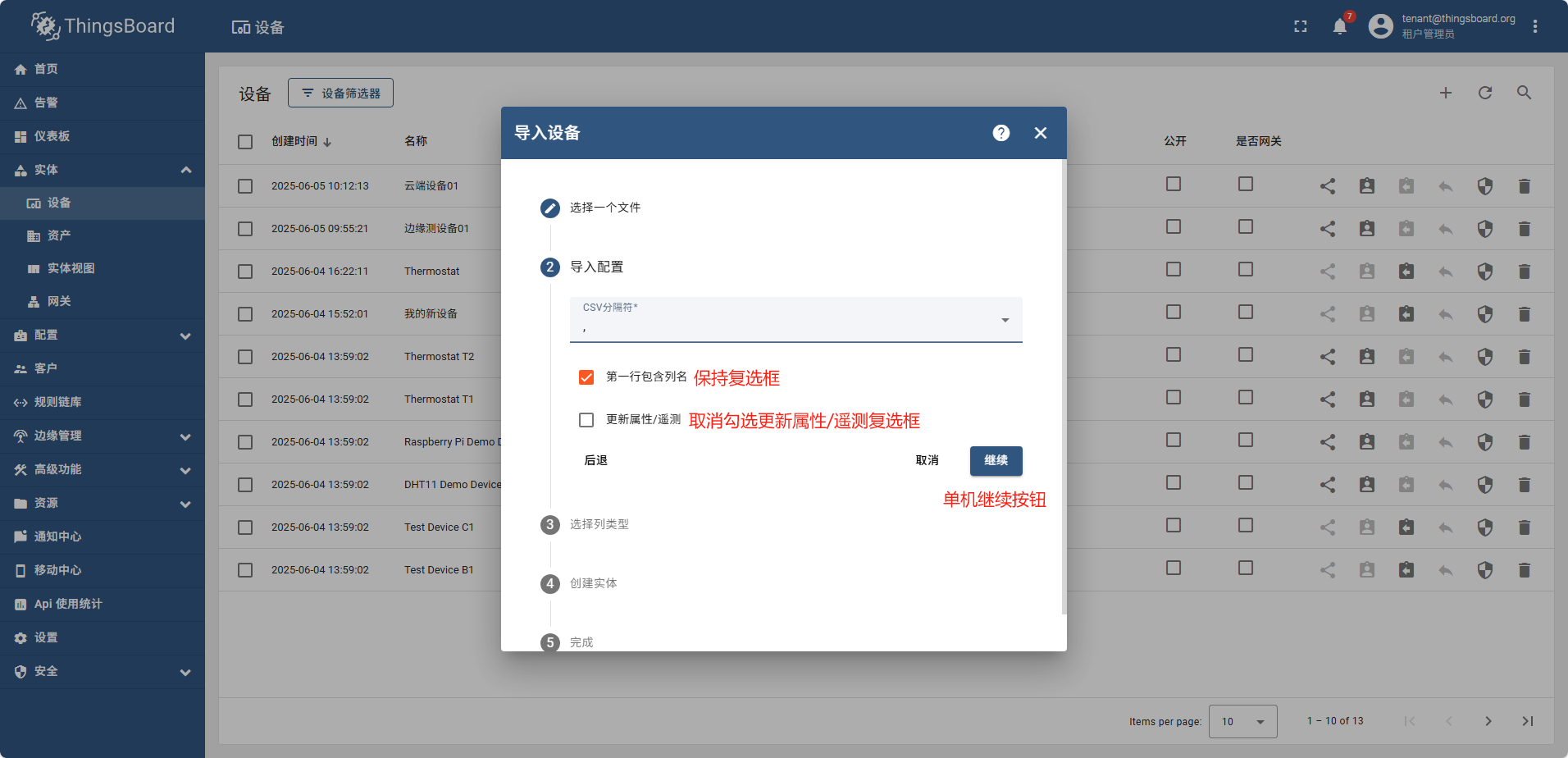
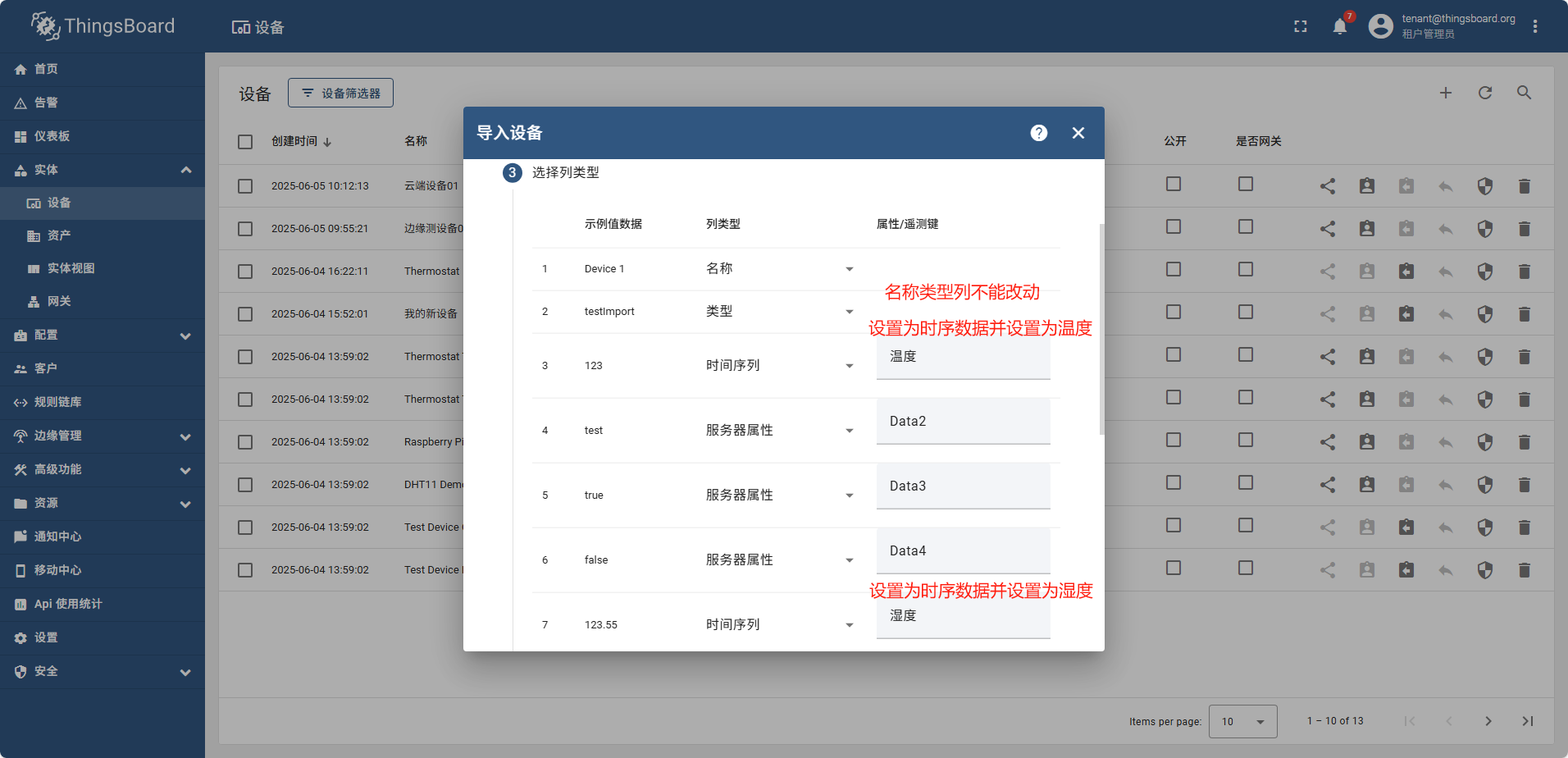
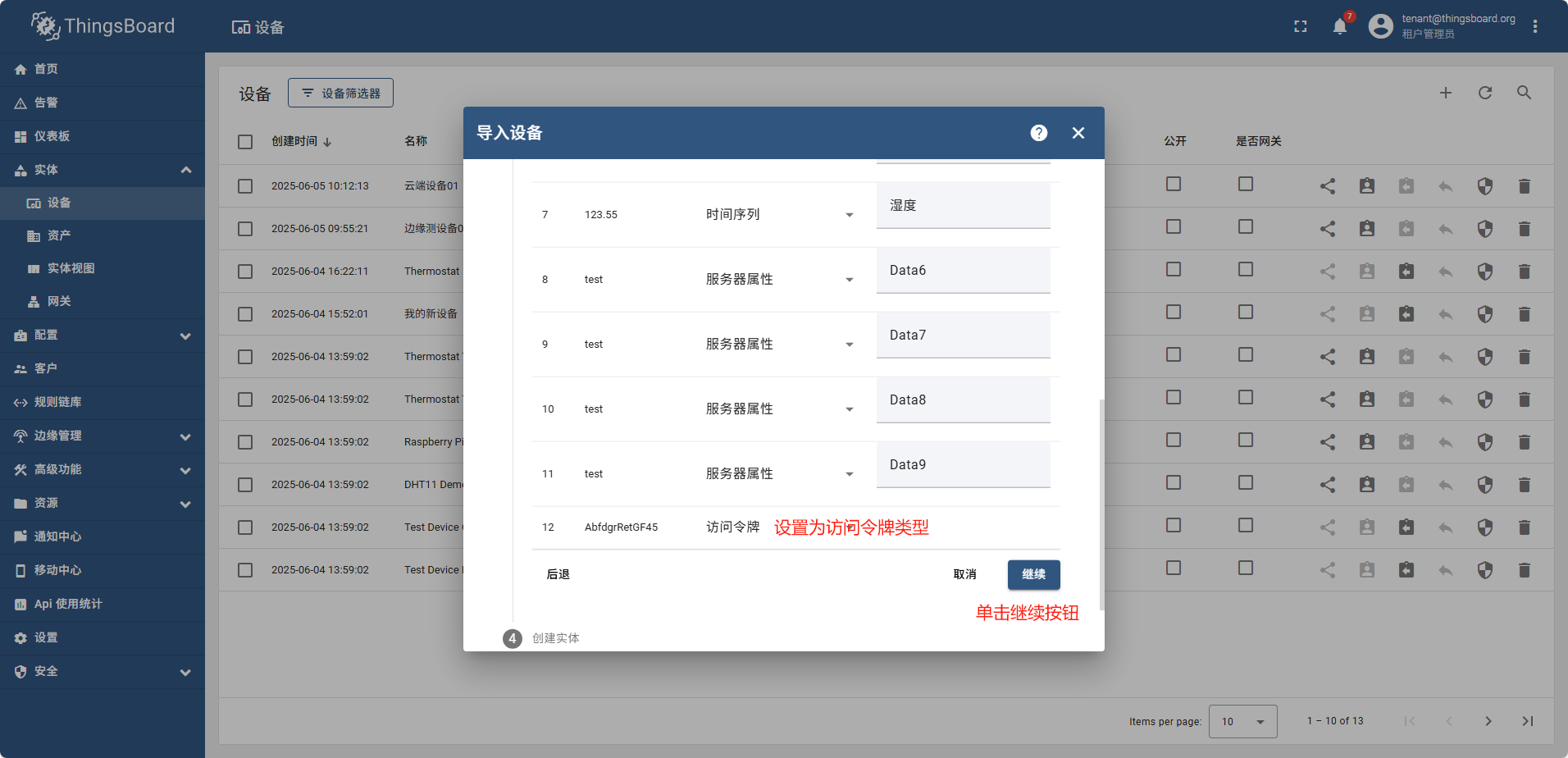
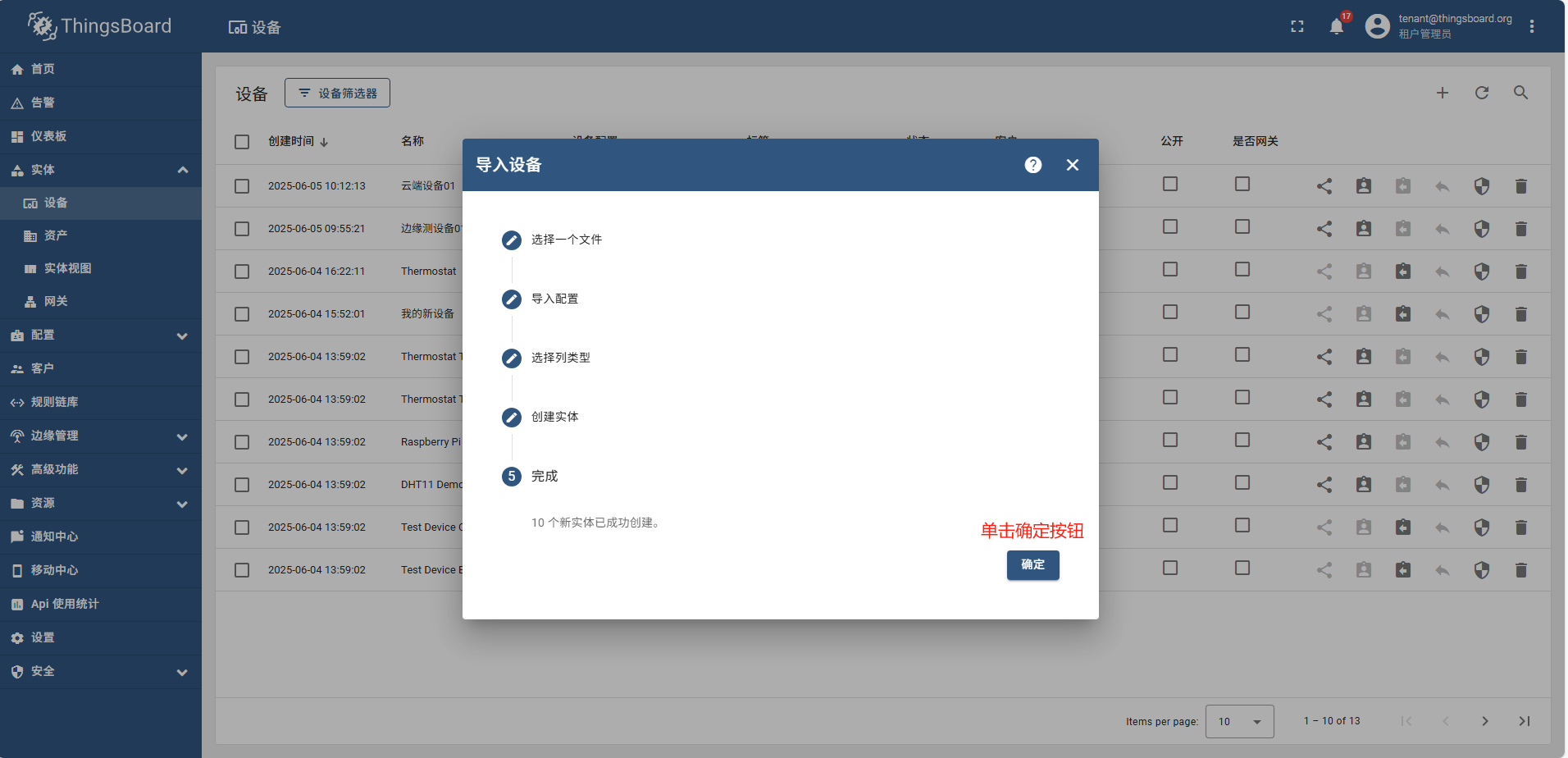
导入完成后,重新查看设备列表
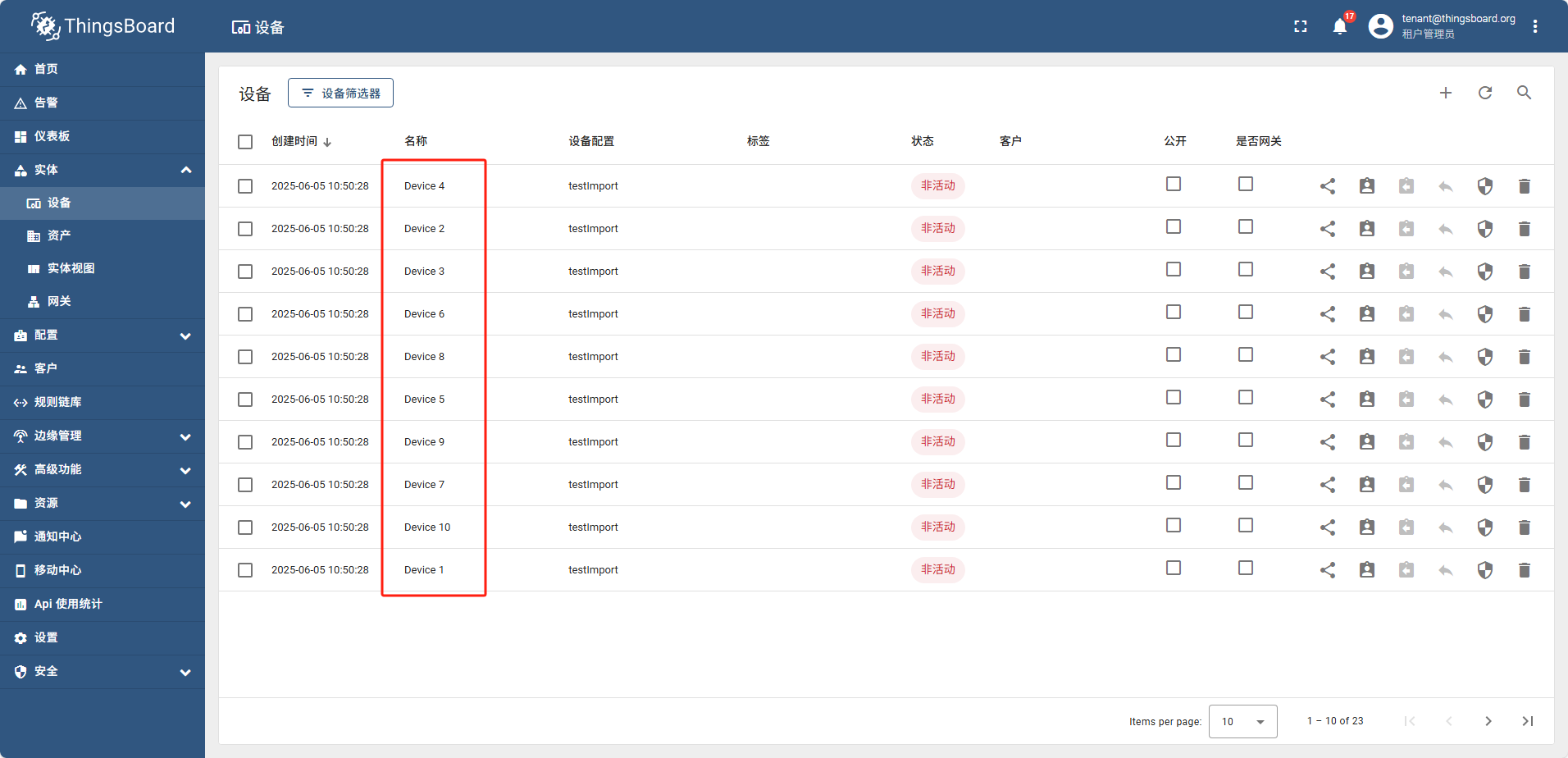
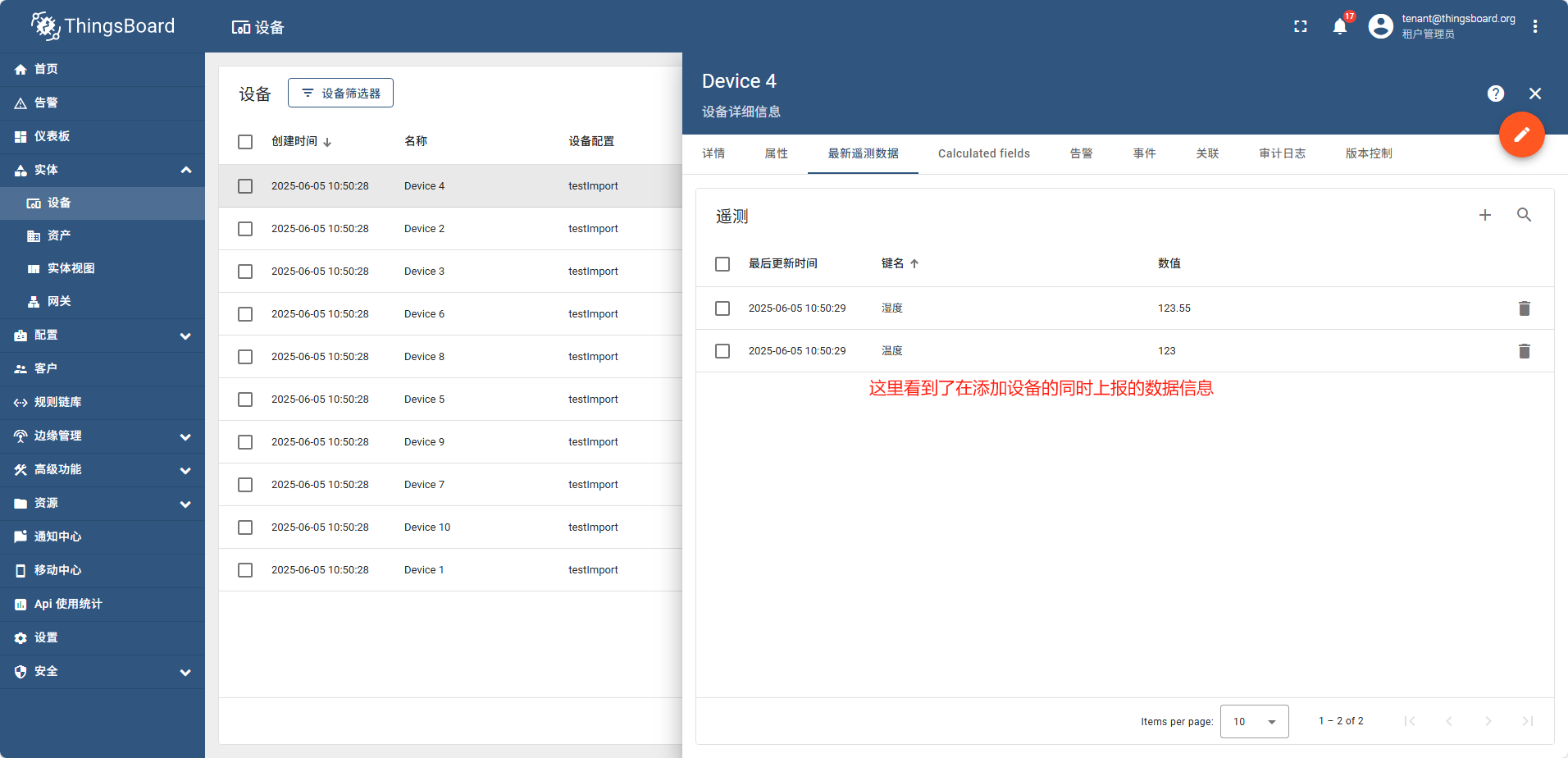
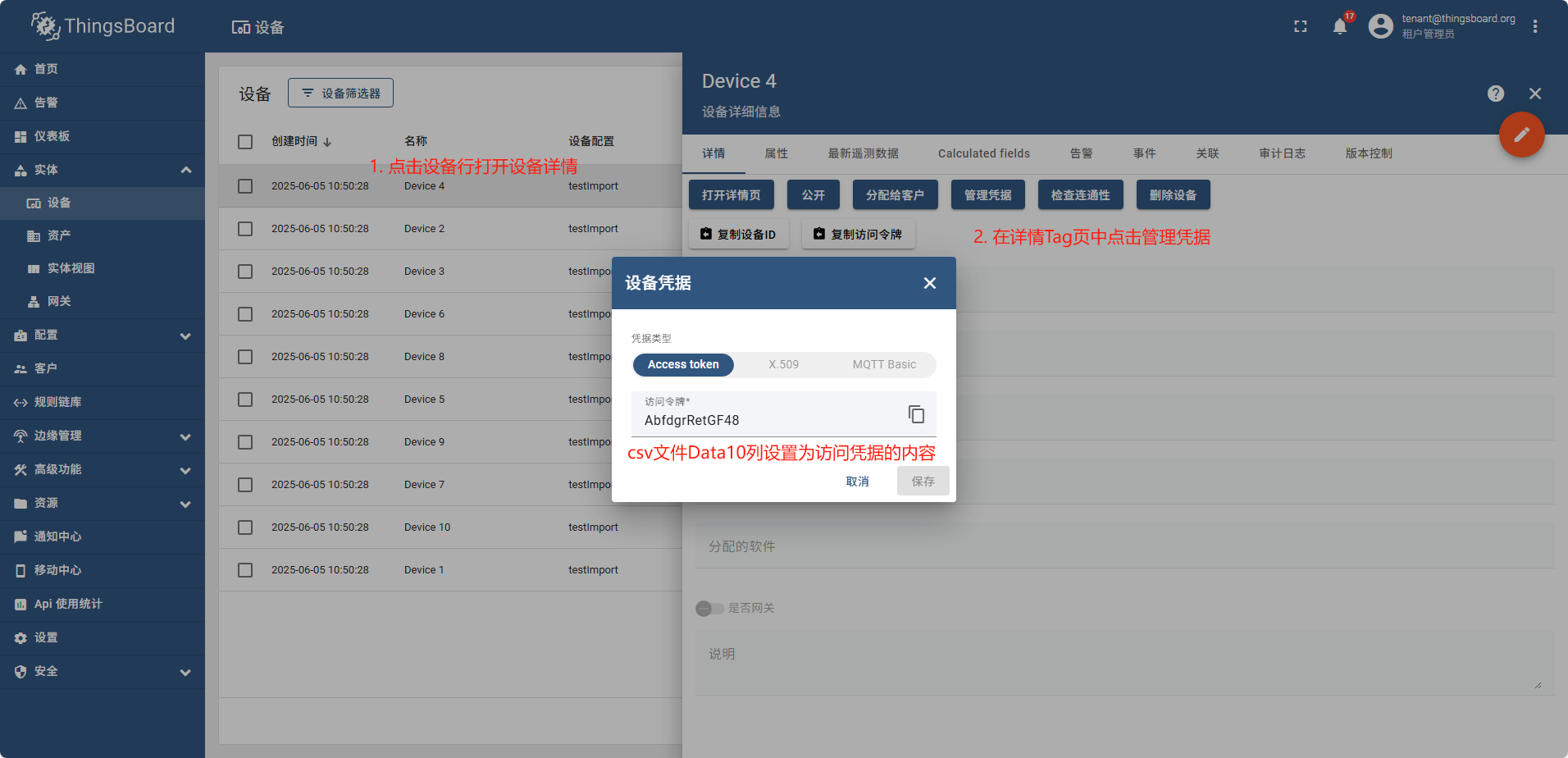
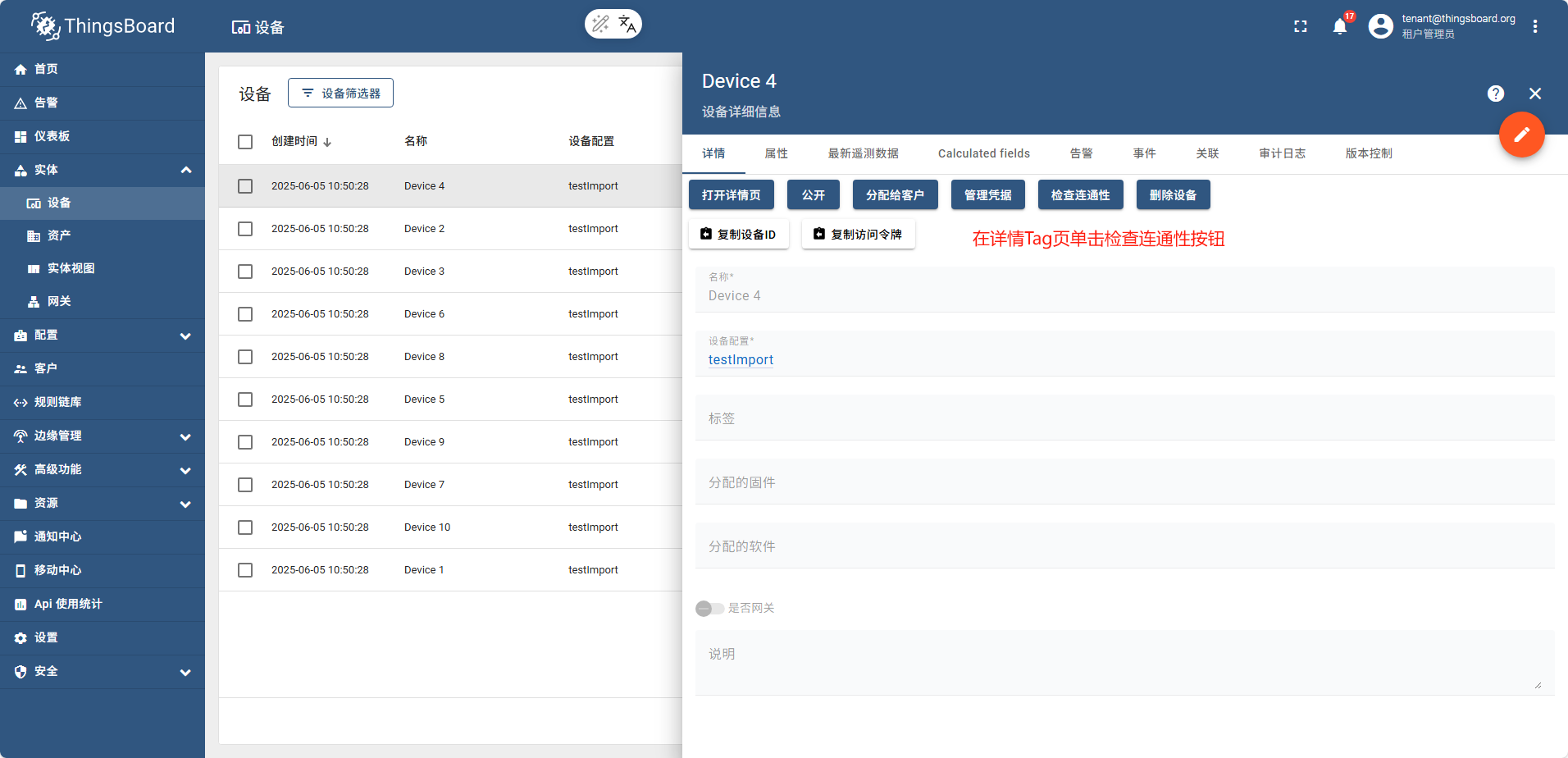
执行命令
# 注意这里我将json字符串的key改成了温度
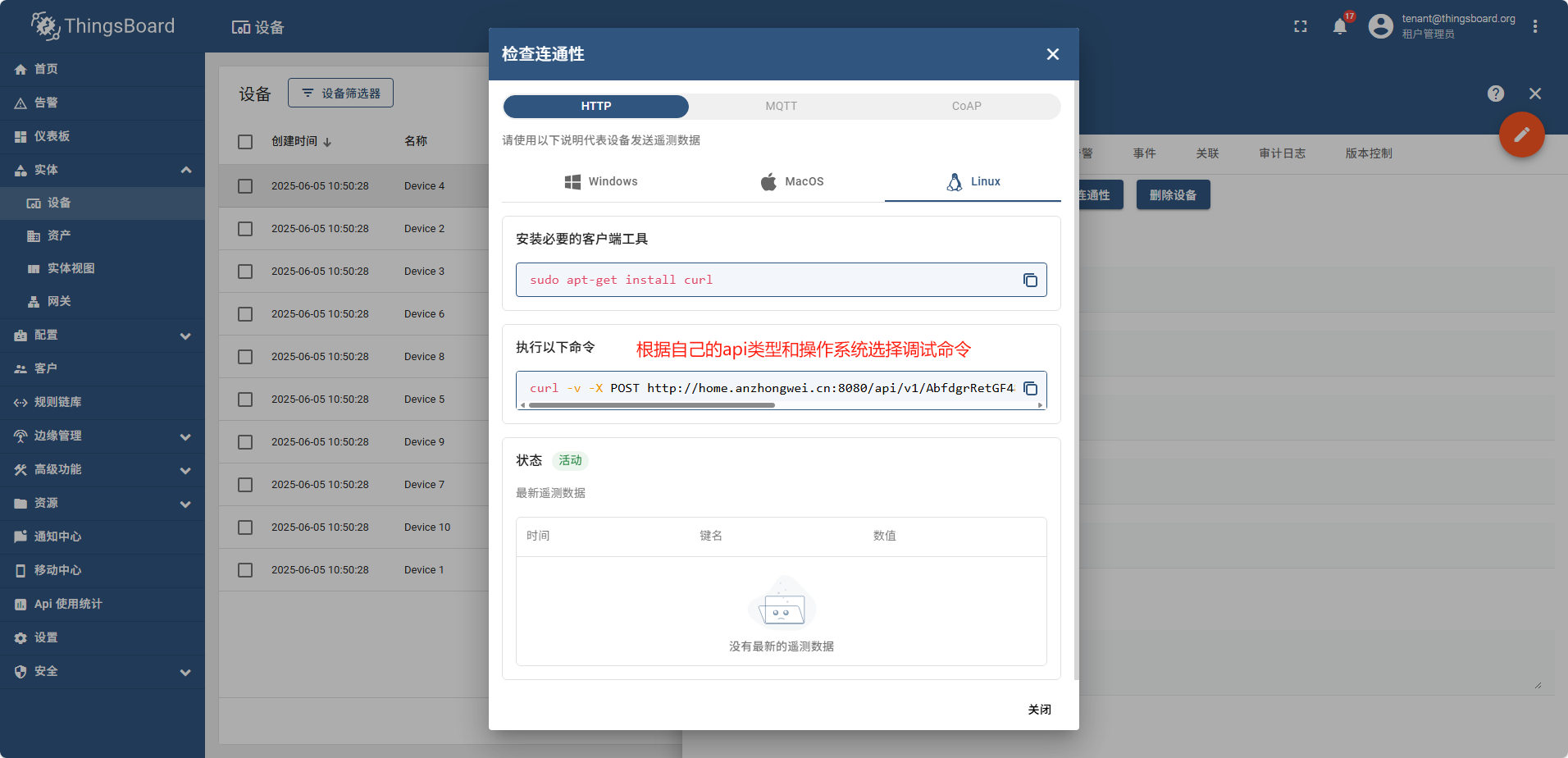
curl -v -X POST http://demain:8080/api/v1/AbfdgrRetGF48/telemetry --header Content-Type:application/json --data "{温度:25}"
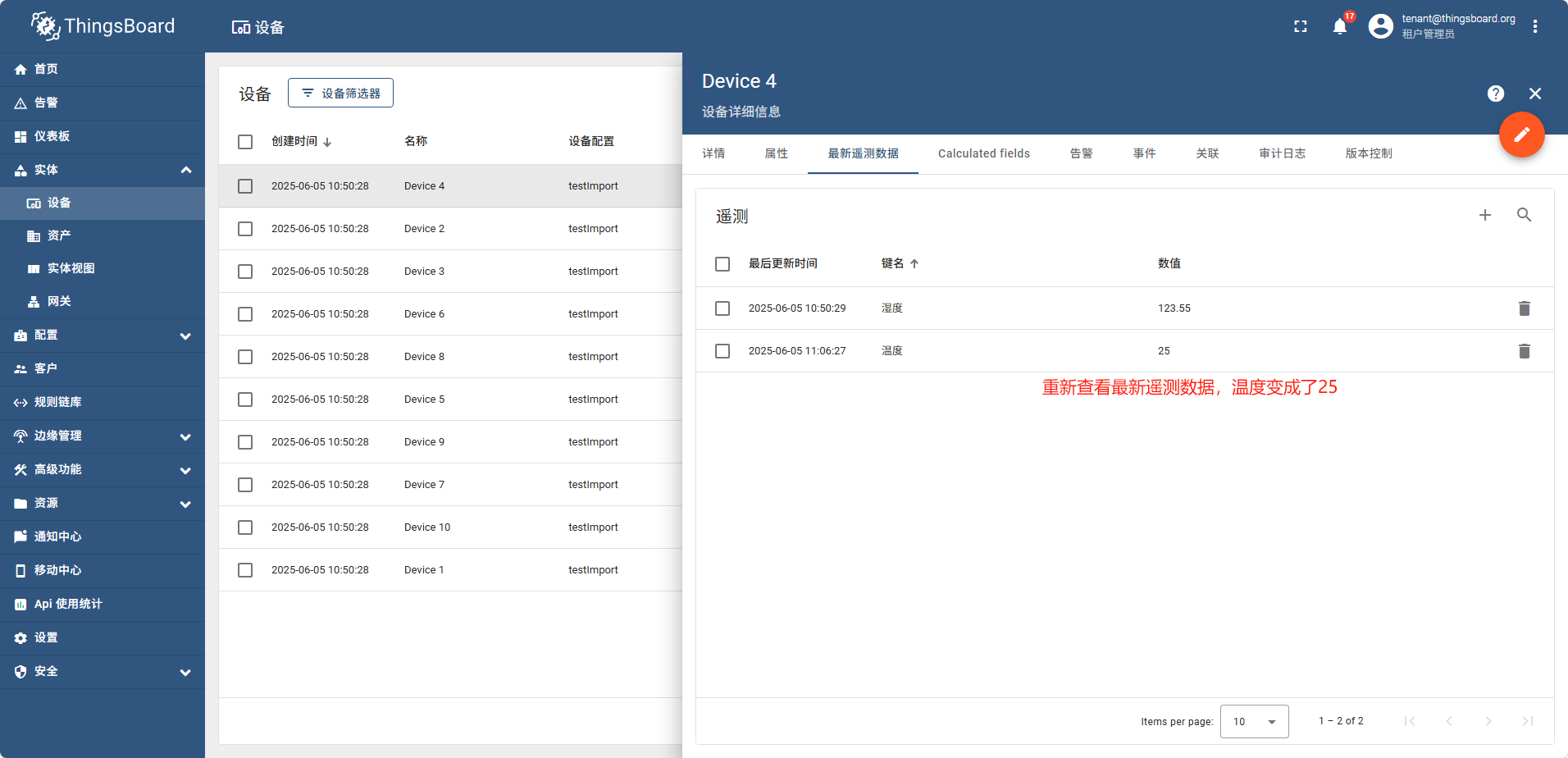
调用完成后,重新查看最新的遥测数据, 温度已经变成了我们api调用设置的值
7.2 - 02边缘测
https://thingsboard.io/docs/edge/getting-started/
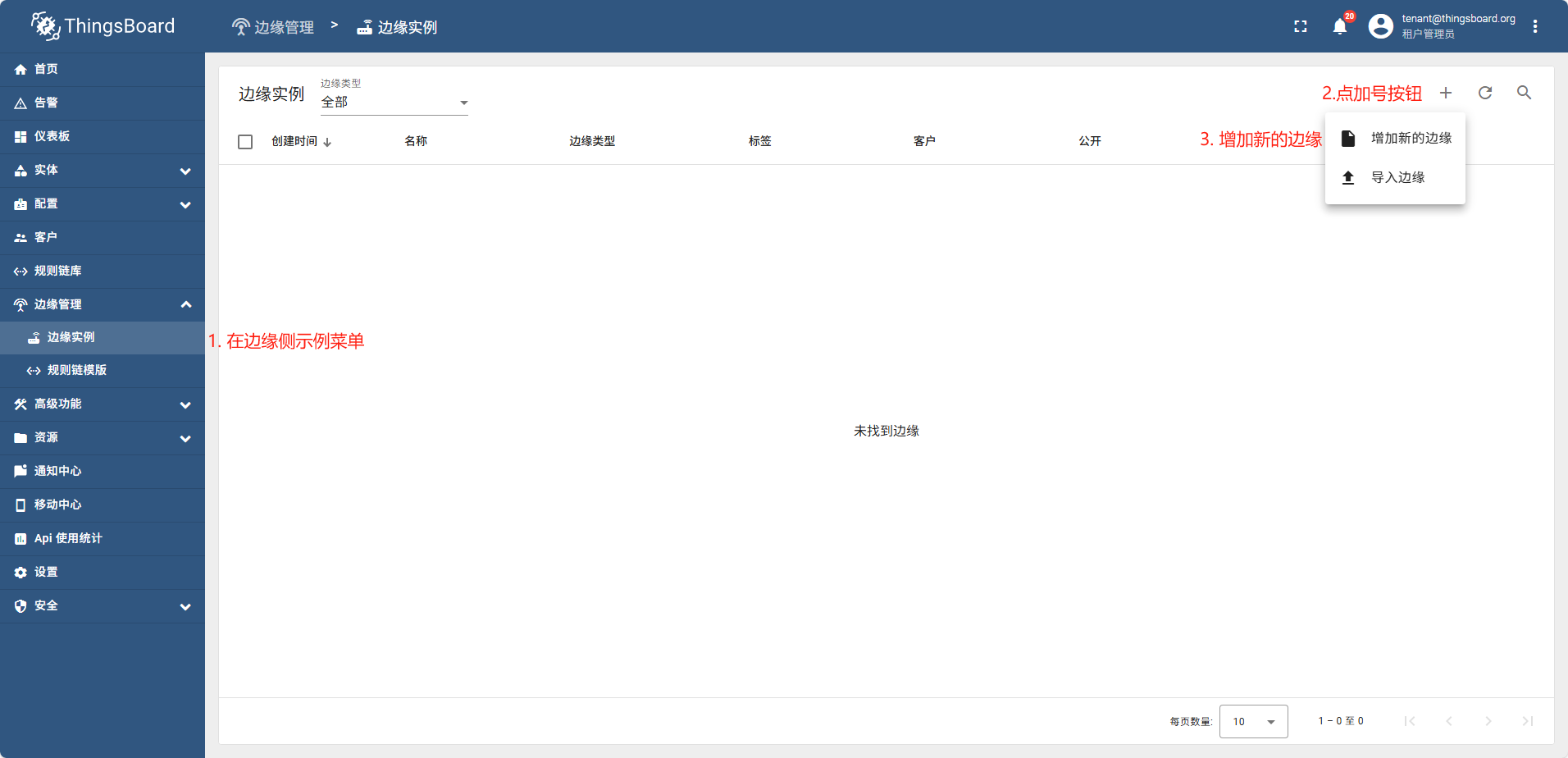
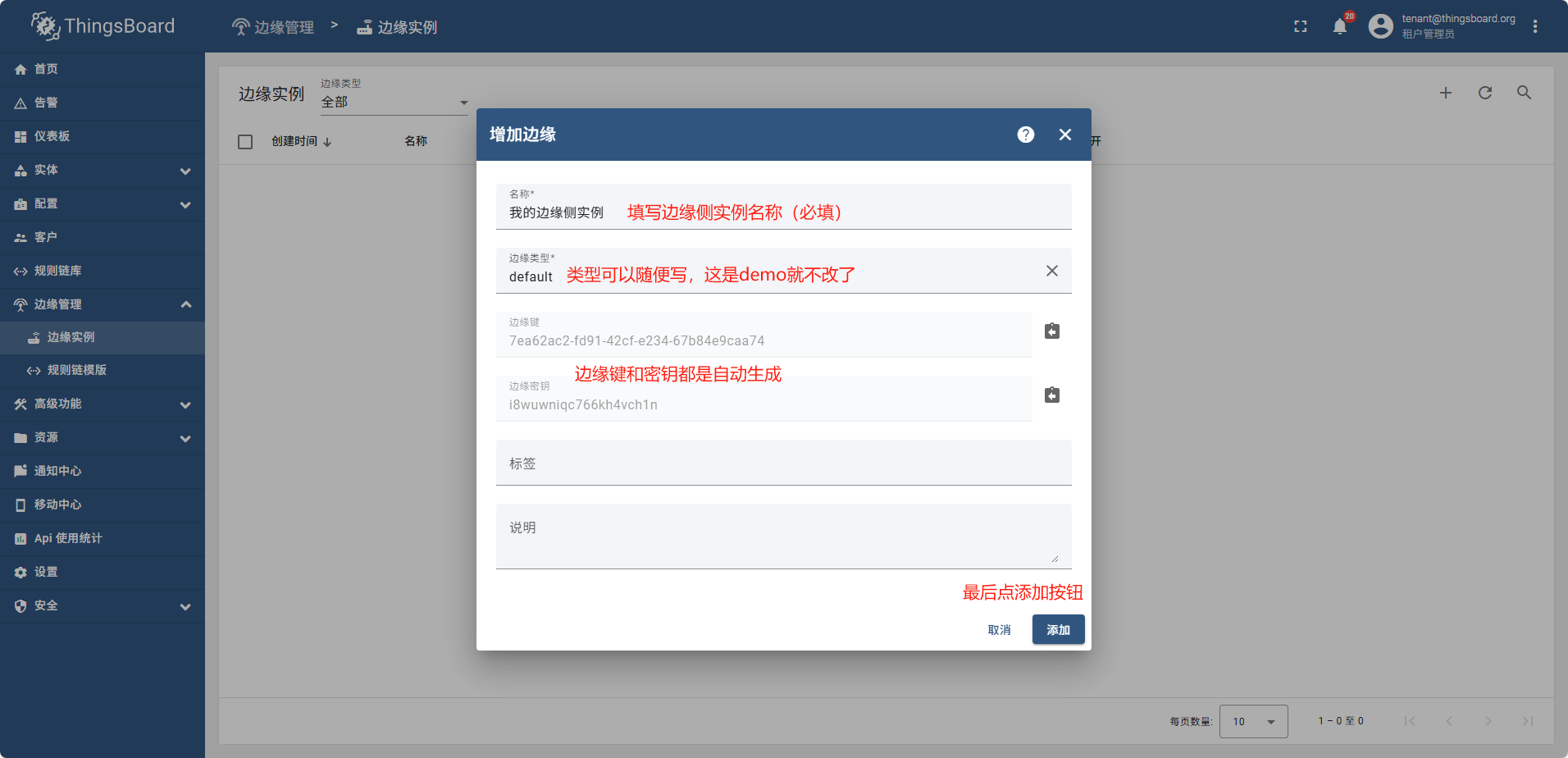
新增边缘实例
创建完成后弹出连接方式
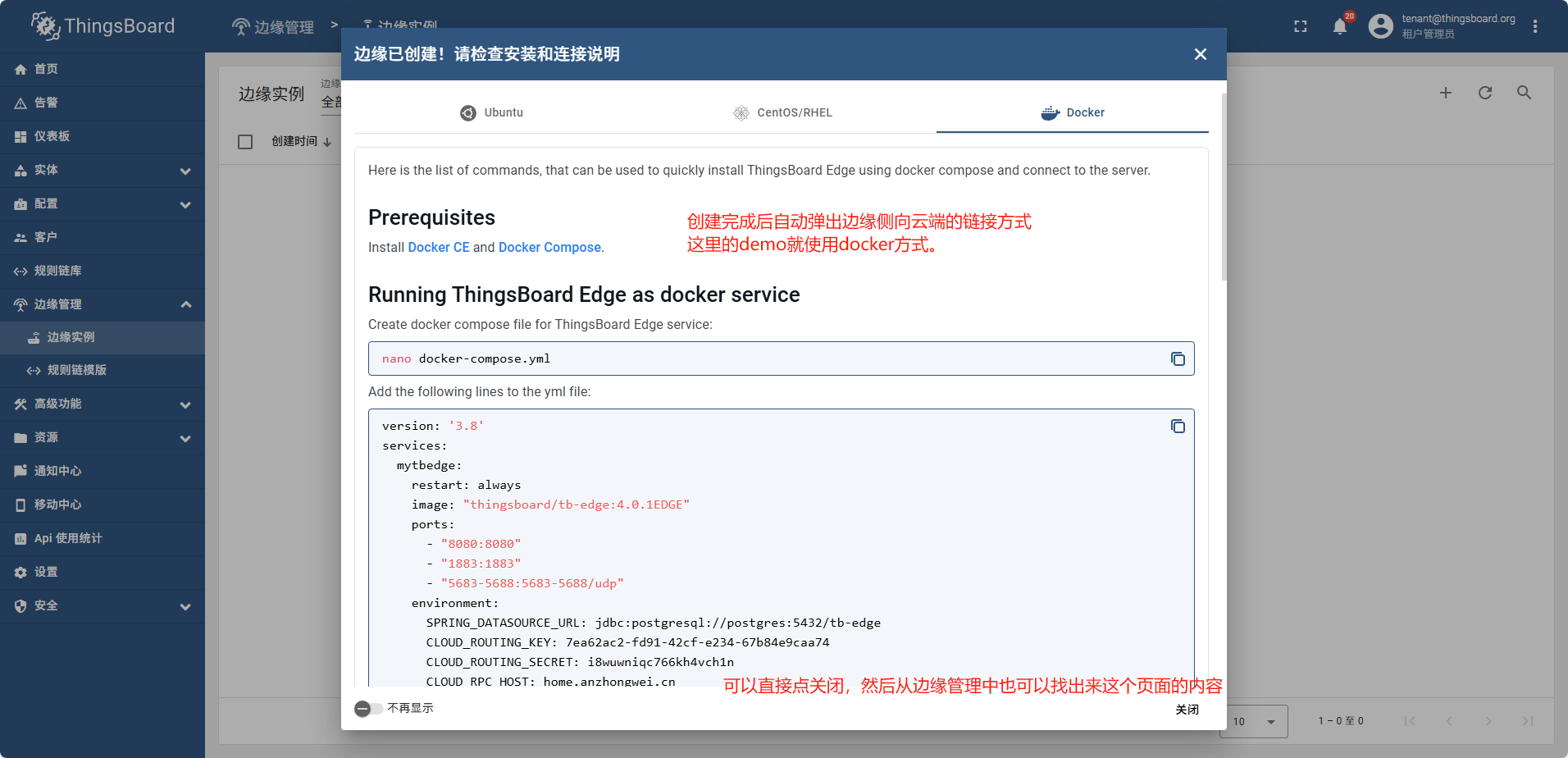
关闭连接方式弹窗后。再重新找到连接方式的弹窗
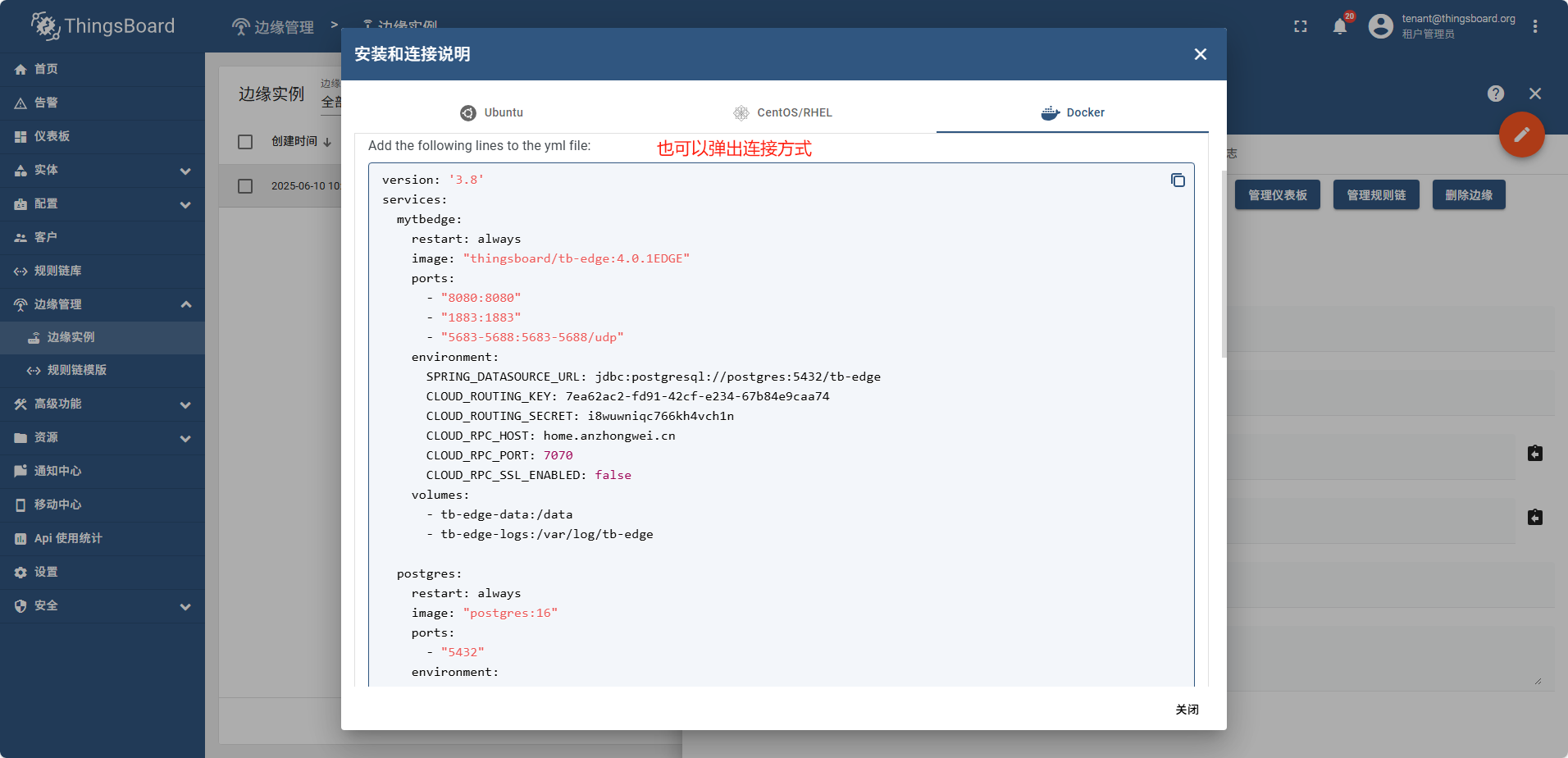
当边缘侧完成连接后,“安装和连接说明” 则变成了 “升级说明”
填写完表单后,此处以docker创建为例
- 复制docker tag中的docker-compose
services:
mytbedge:
restart: always
image: "thingsboard/tb-edge:4.0.1EDGE"
ports:
- "8080:8080"
- "1883:1883"
- "5683-5688:5683-5688/udp"
environment:
SPRING_DATASOURCE_URL: jdbc:postgresql://postgres:5432/tb-edge
CLOUD_ROUTING_KEY: 7ea62ac2-fd91-42cf-e234-67b84e9caa74
CLOUD_ROUTING_SECRET: i8wuwniqc766kh4vch1n
CLOUD_RPC_HOST: home.anzhongwei.cn
CLOUD_RPC_PORT: 57070
CLOUD_RPC_SSL_ENABLED: false
volumes:
- tb-edge-data:/data
- tb-edge-logs:/var/log/tb-edge
postgres:
restart: always
image: "postgres:16"
ports:
- "5432"
environment:
POSTGRES_DB: tb-edge
POSTGRES_PASSWORD: postgres
volumes:
- tb-edge-postgres-data:/var/lib/postgresql/data
volumes:
tb-edge-data:
name: tb-edge-data
tb-edge-logs:
name: tb-edge-logs
tb-edge-postgres-data:
name: tb-edge-postgres-data
使用docker运行起来
运行成功可以在本地浏览器通过 http:///127.0.0.1:8080 访问到页面
用户名:tenant@thingsboard.org
密码: tenant
登录成功后页面
在边缘侧创建设备并发送设备数据
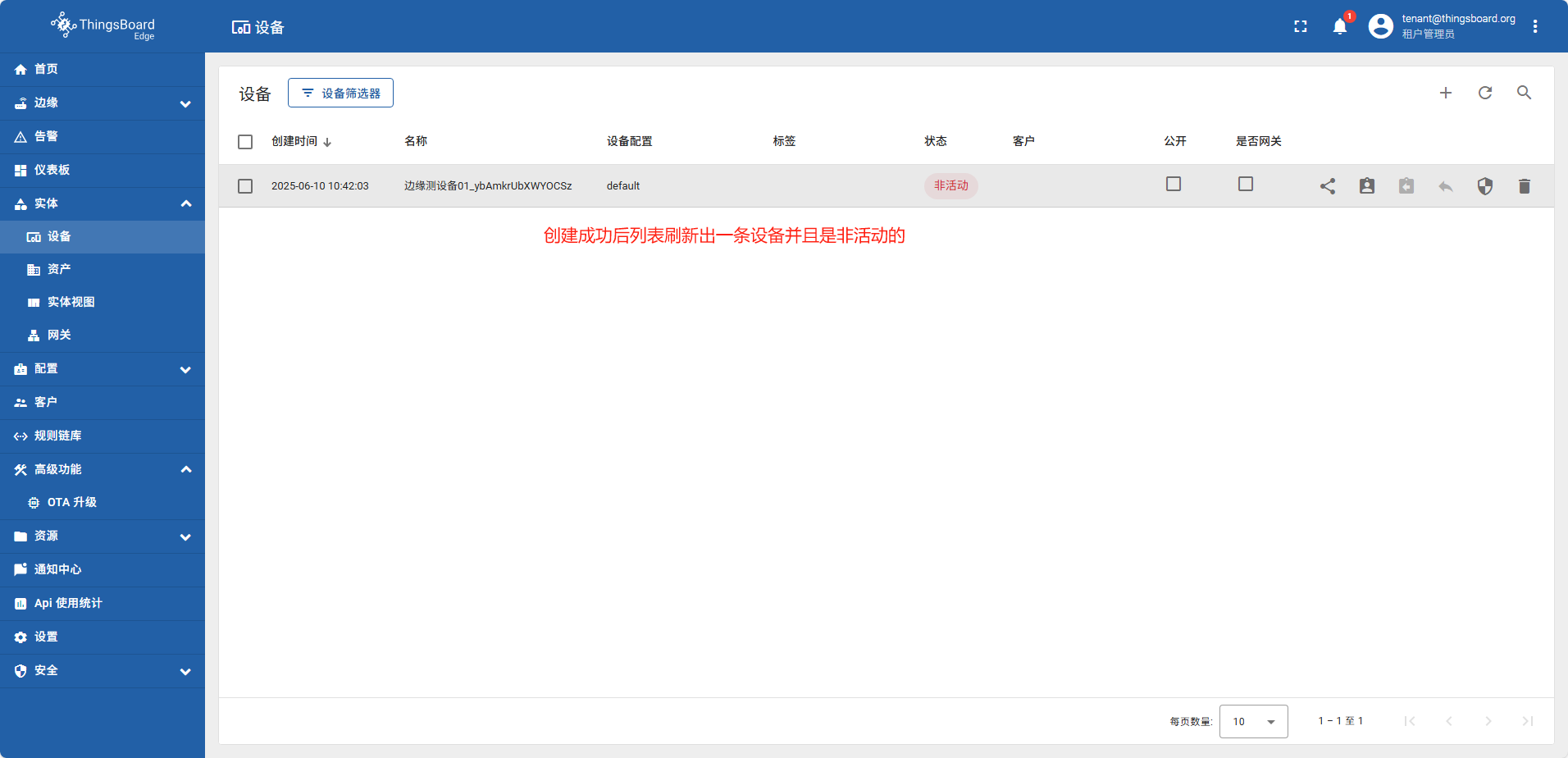
在边缘侧创建的设备,系统会自动同步给云端 设备名称 边缘测设备01。此实例由于在云端设备已经存在一个同名的设备,所以会自动添加随机字符串 边缘测设备01_ybAmkrUbXWYOCSz
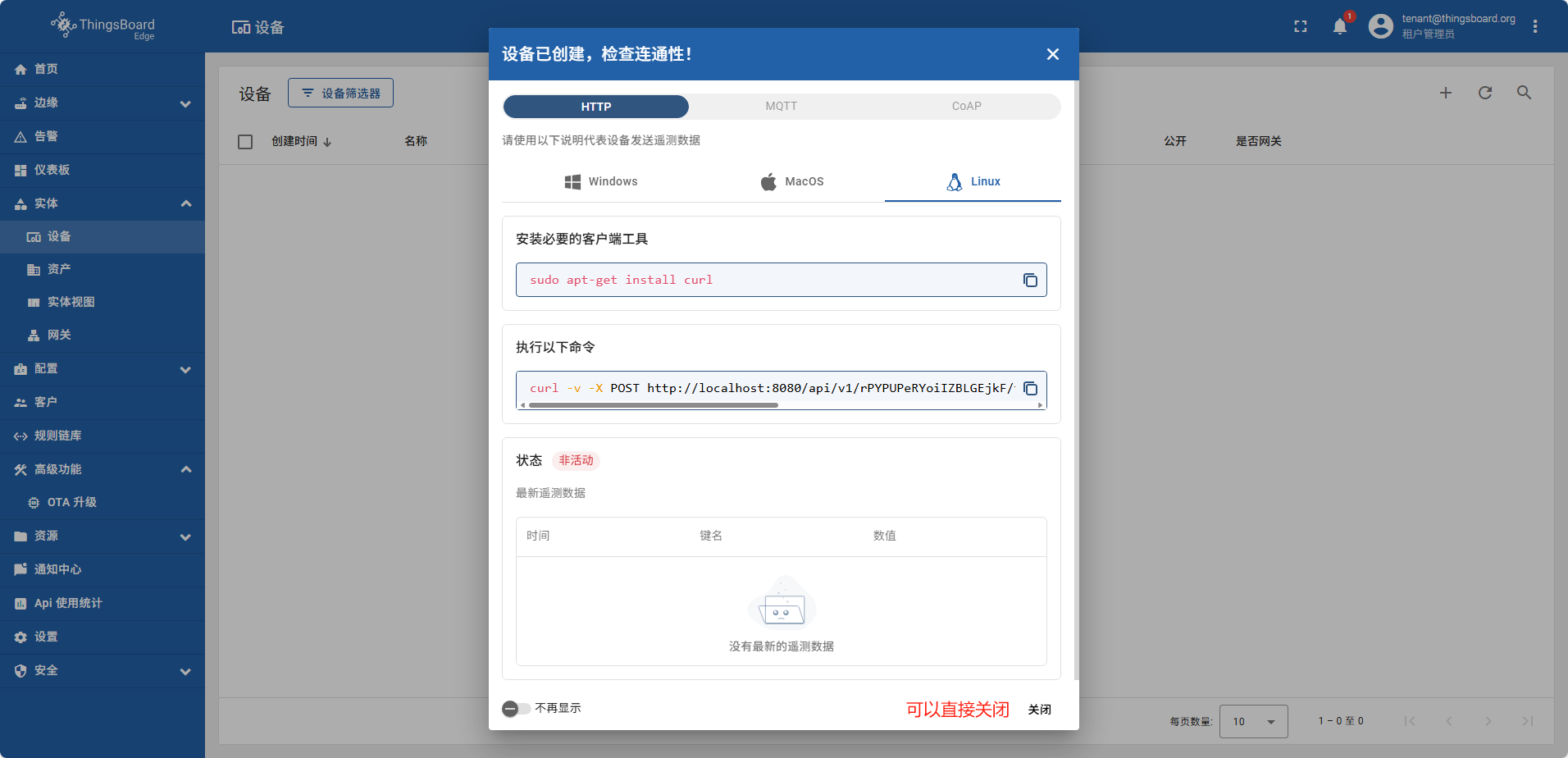
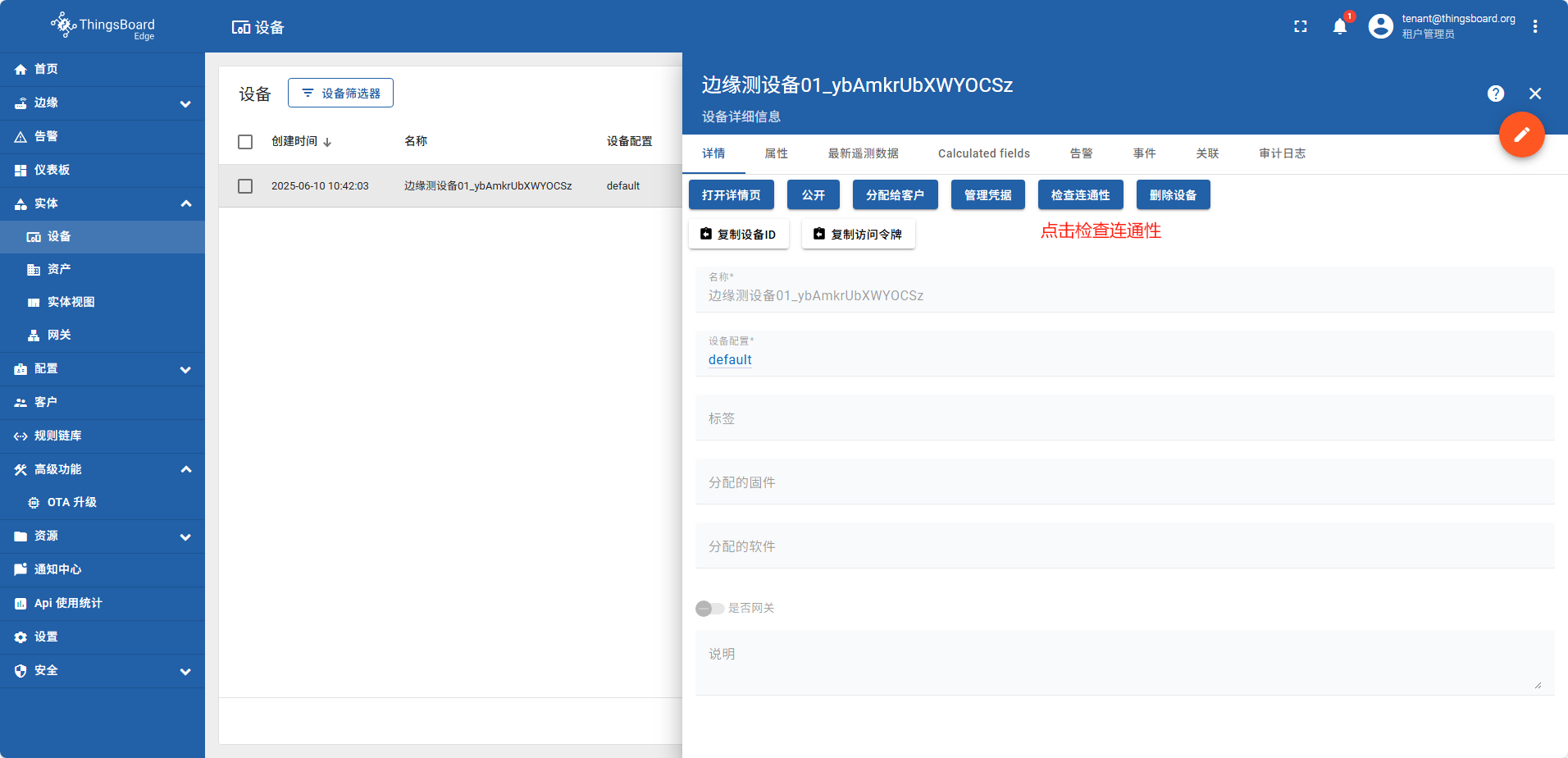
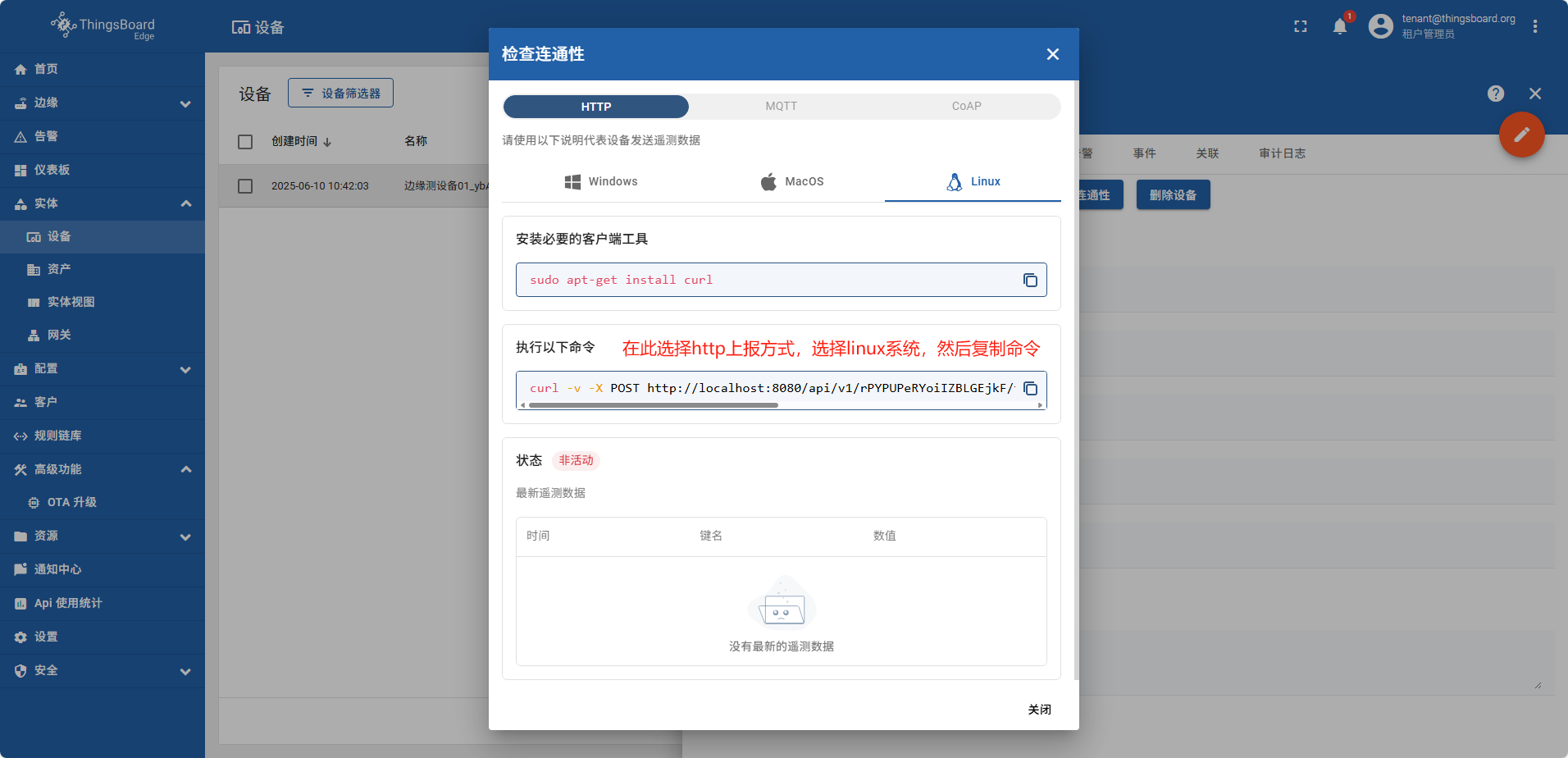
打开本地linux执行命令
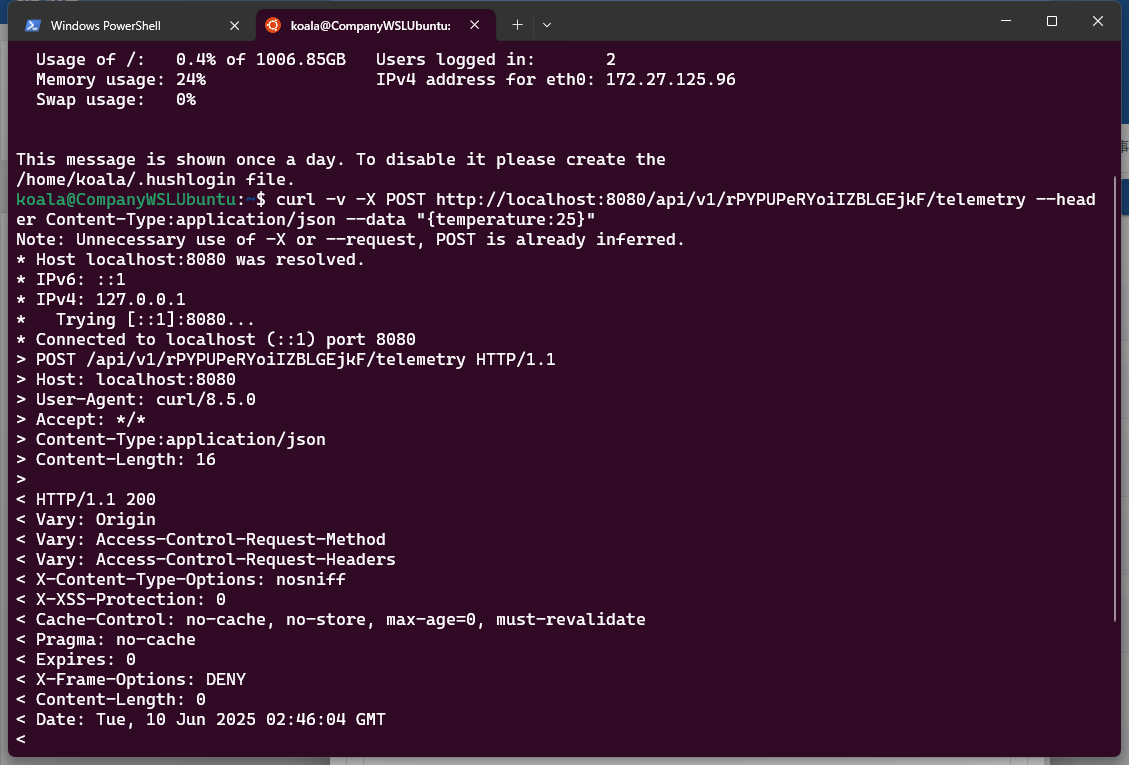
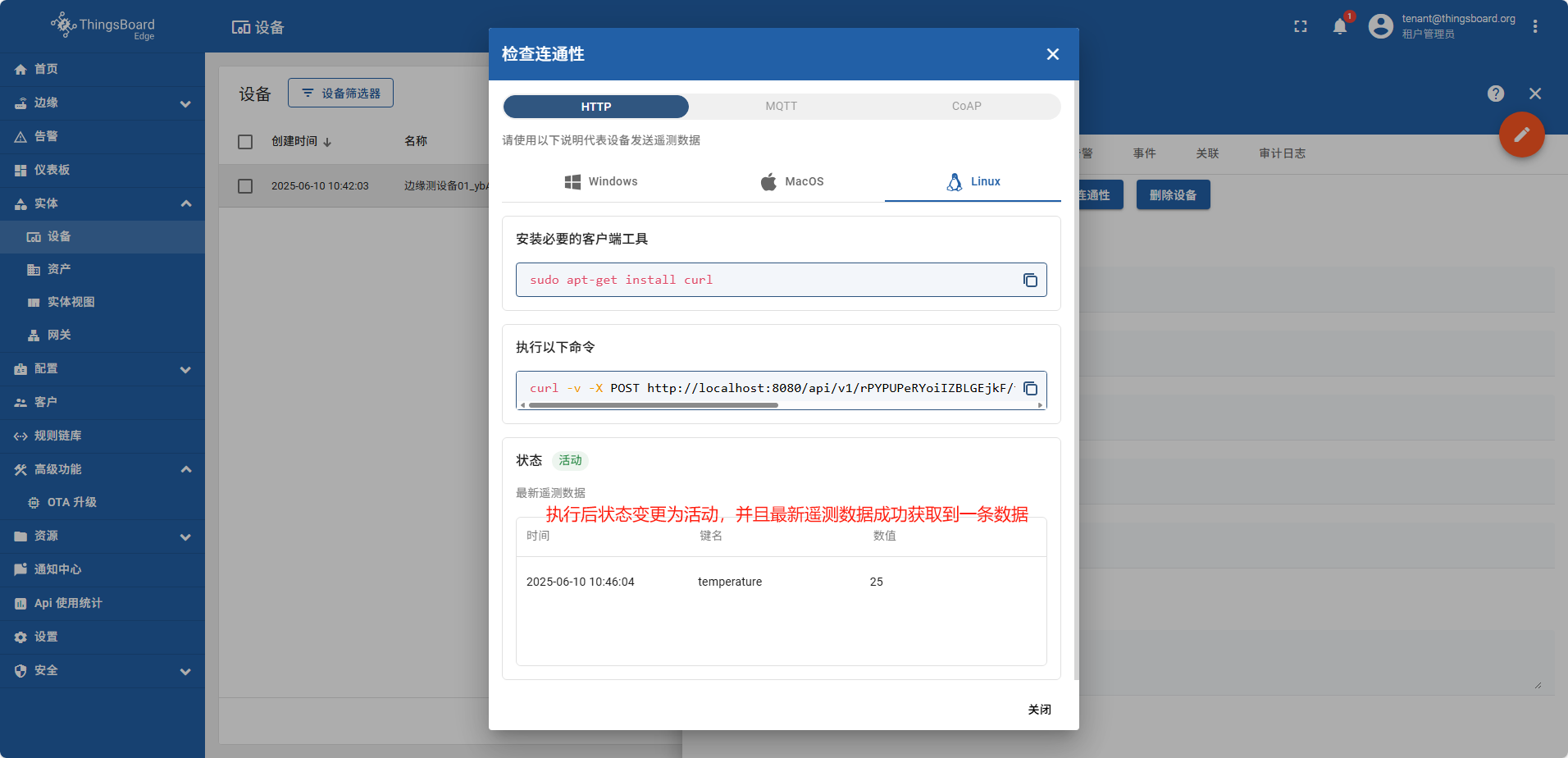
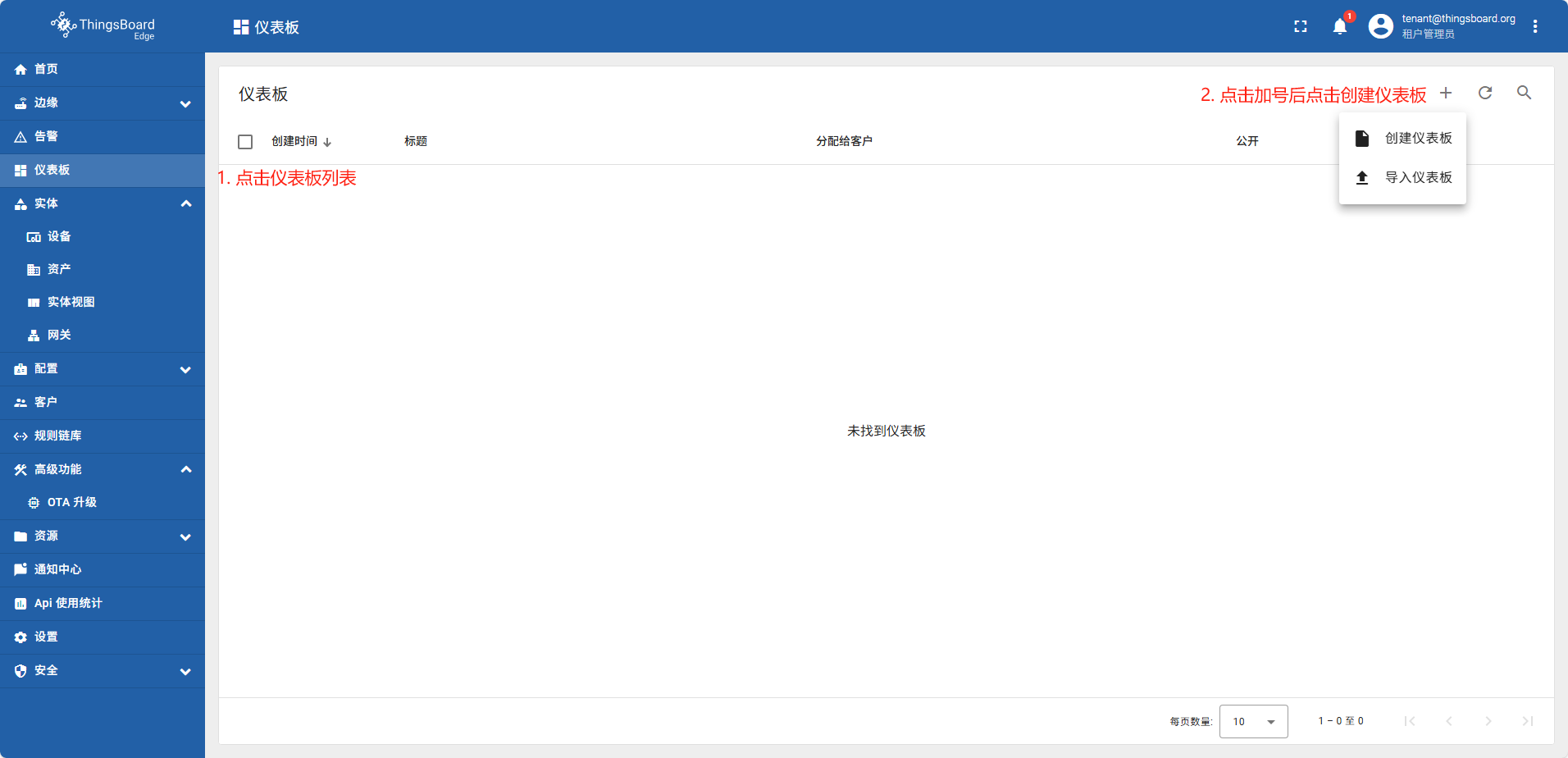
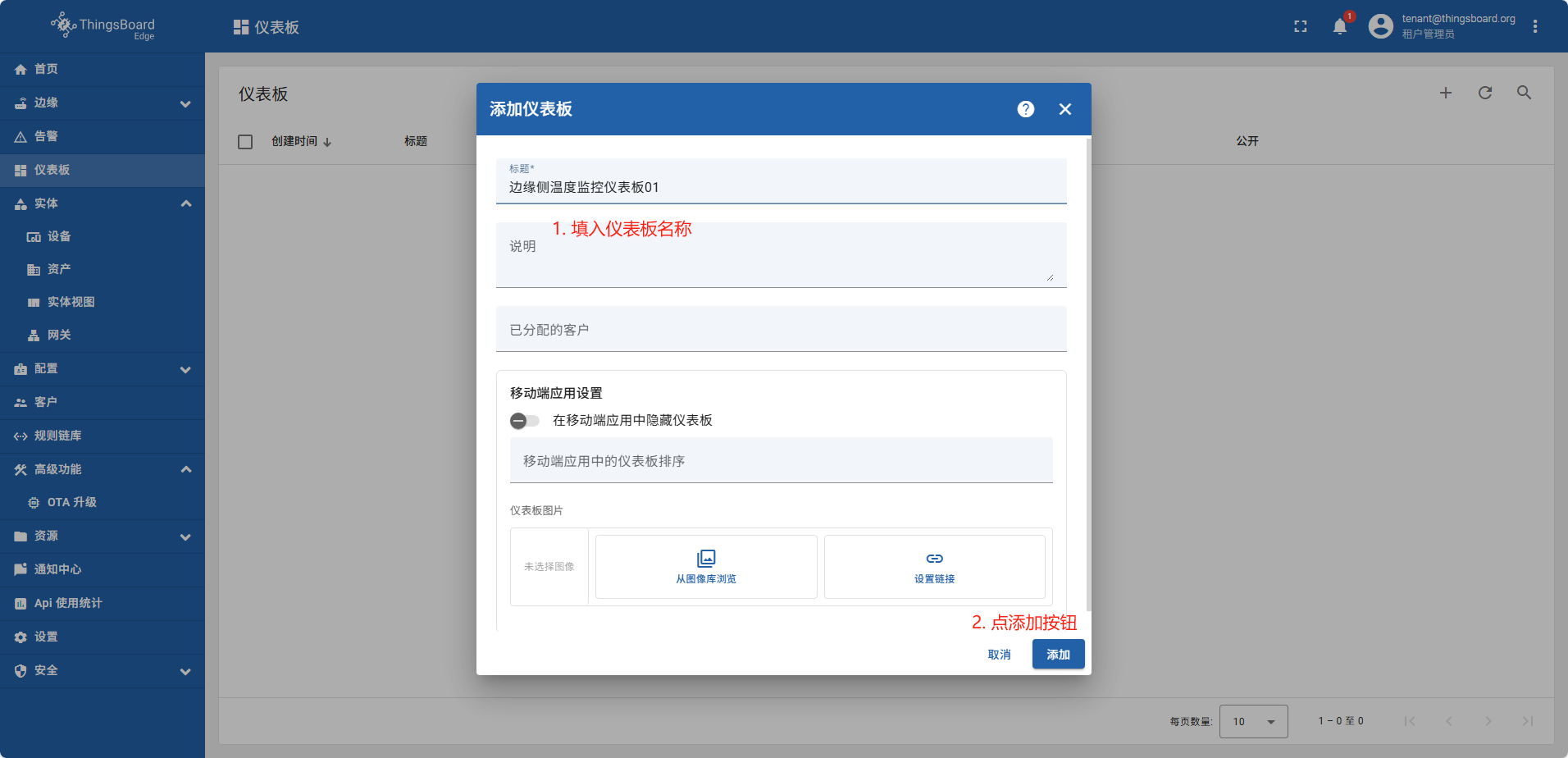
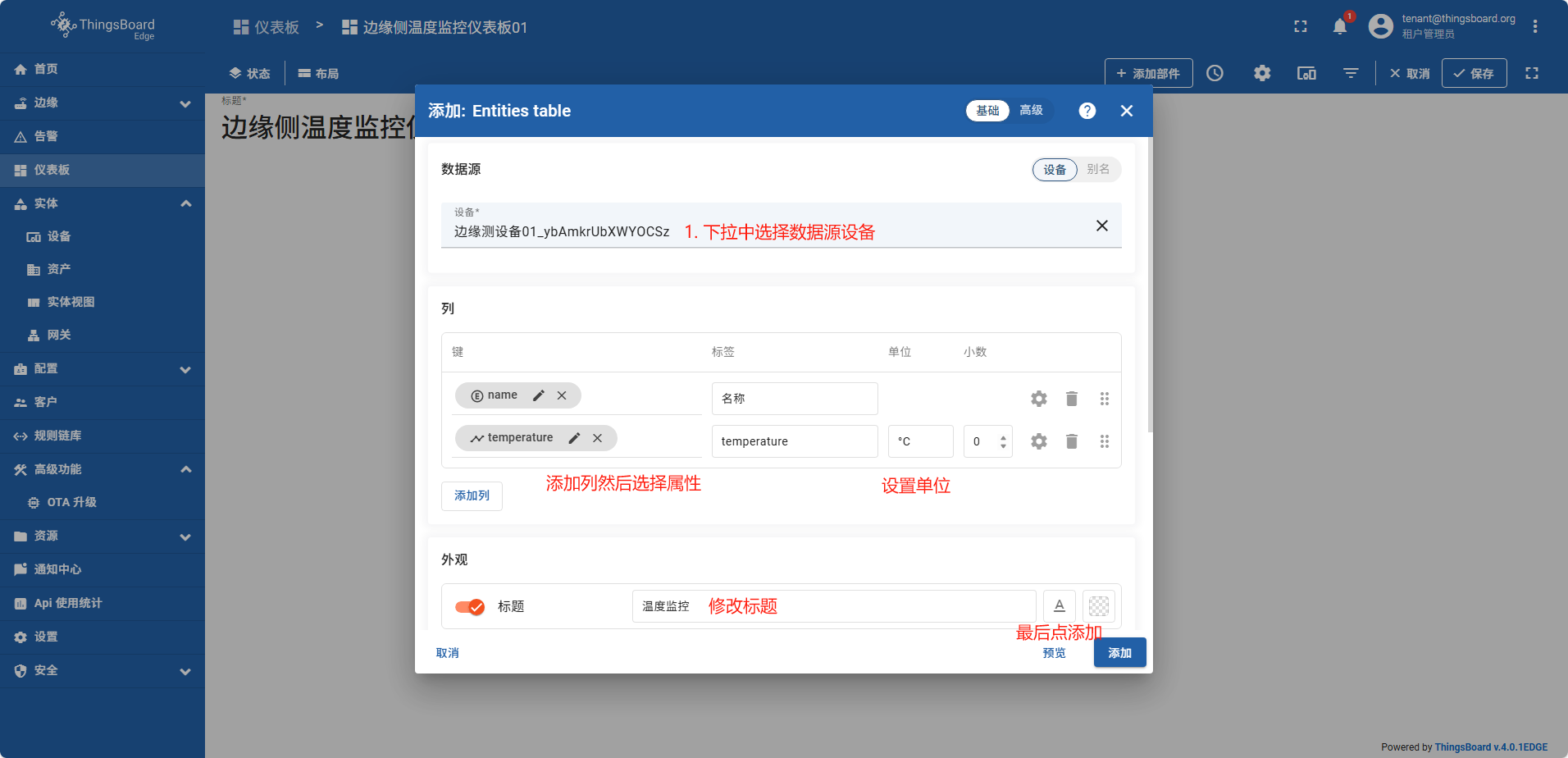
创建仪表板
在边缘侧创建的仪表板,系统会自动同步到云端
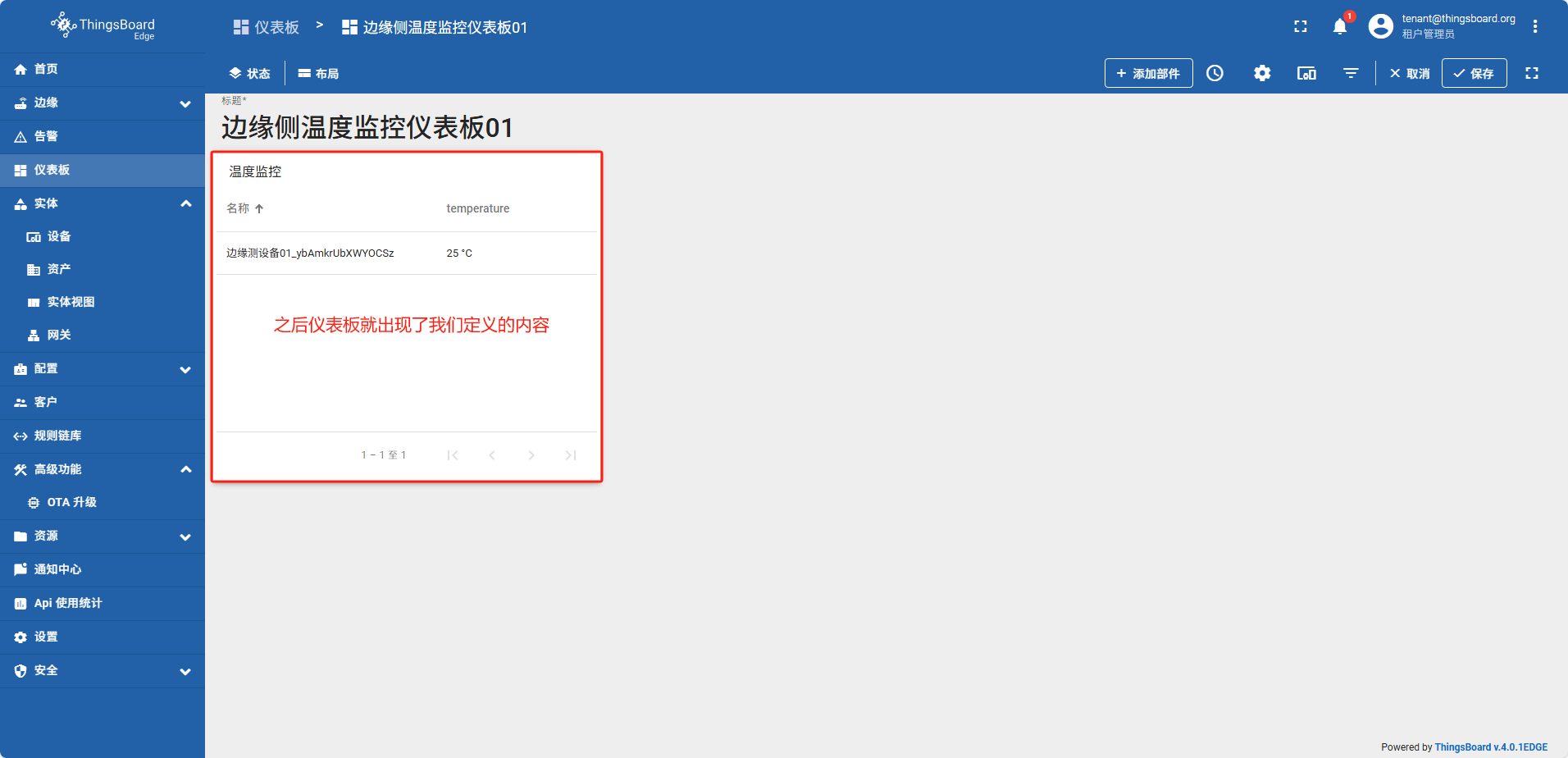
从边缘侧将数据推送到云端
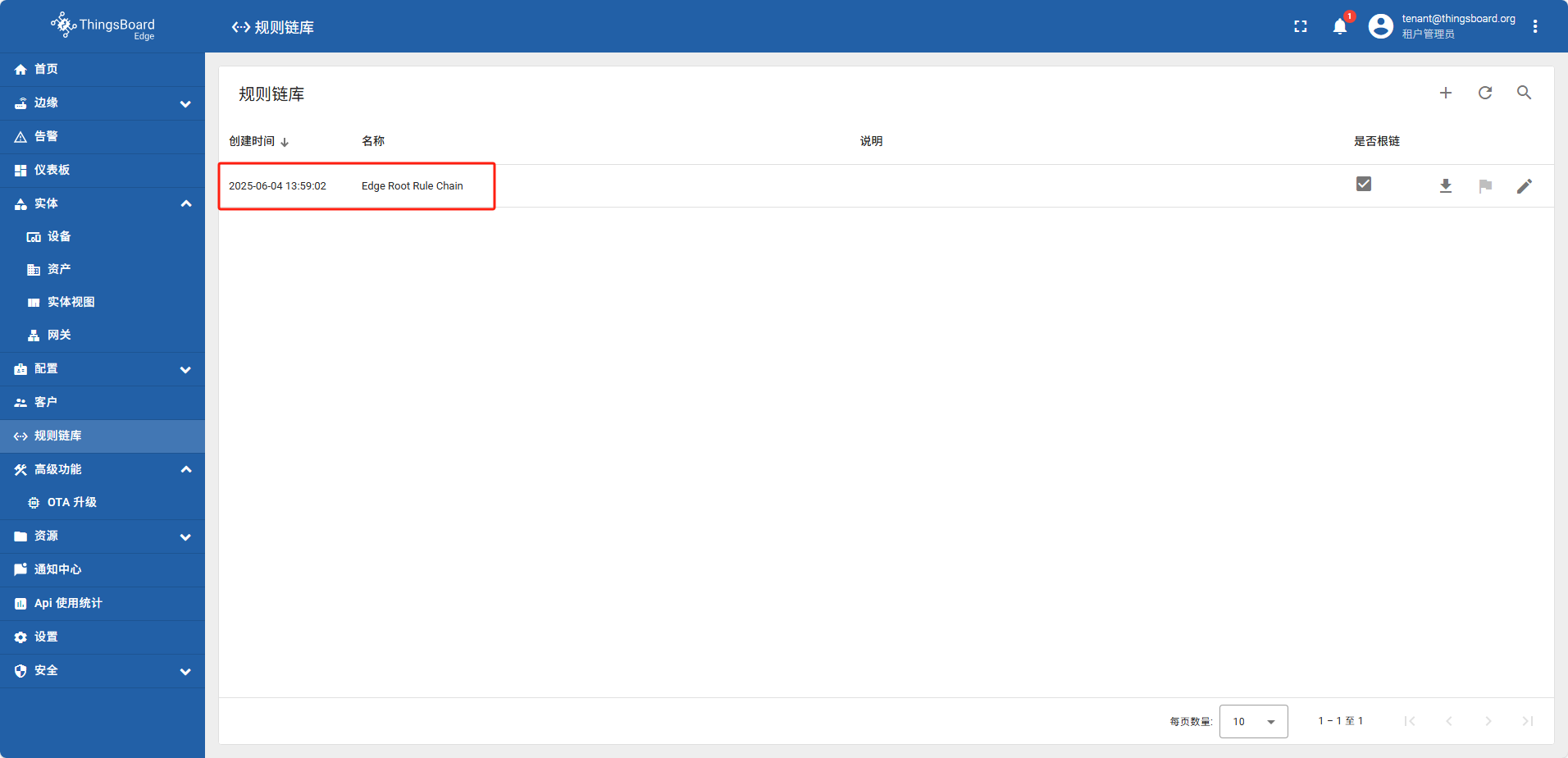
边缘侧数据推送到云使用的是规则链库中的默认模板规则 “Edge Root Rule Chain”
实体从边缘(Edge)到 云(Cloud、服务器)
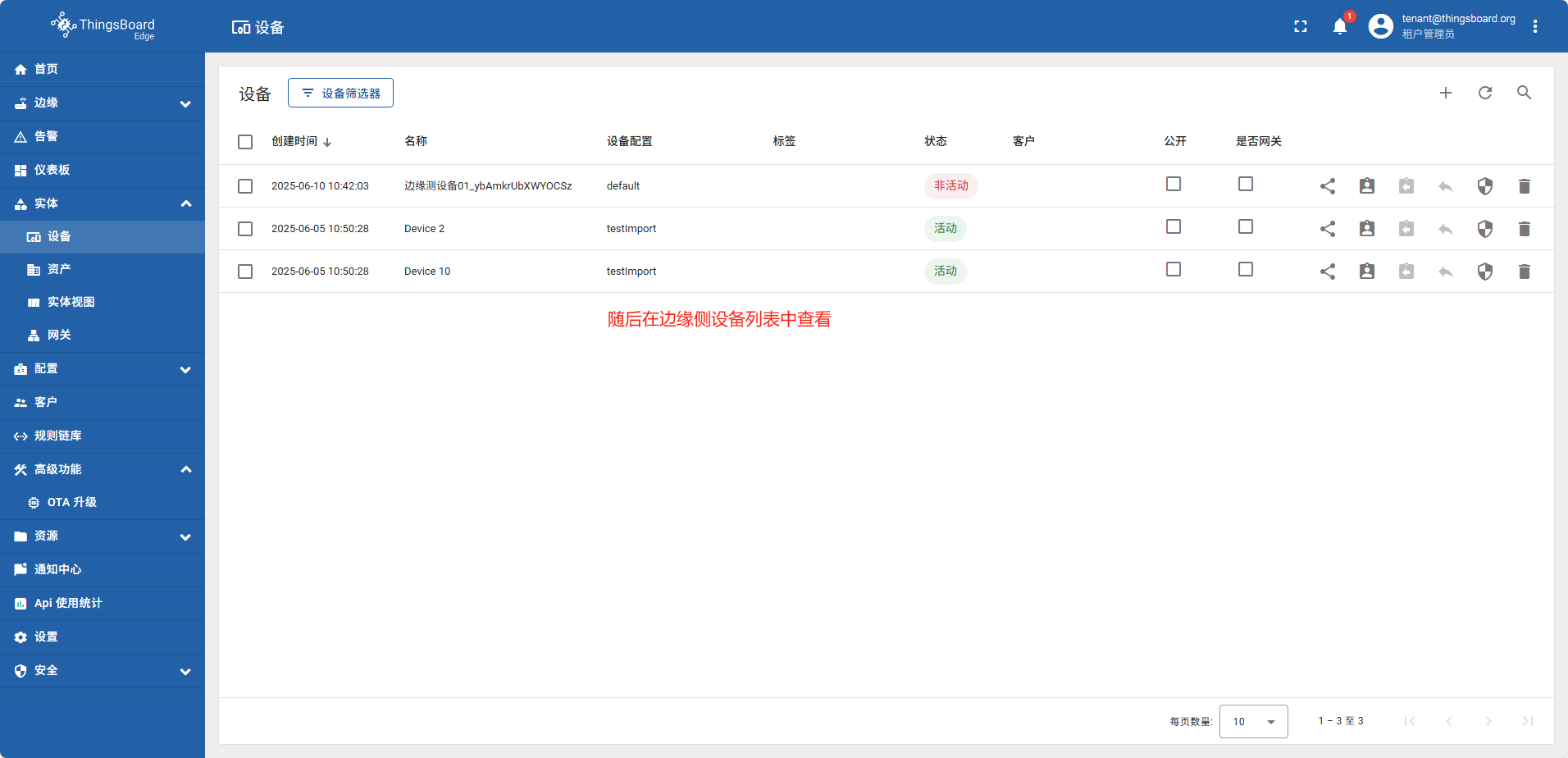
在边缘侧可以创建和云端相同类型的实体(设备、资产、网关),并且他们在边缘侧创建完成后会自动能发布到云端。 以刚创建的 边缘测设备01_ybAmkrUbXWYOCSz 为例
在云端打开这个设备详情点 关联tag,方向 下拉 由从 变更为 到
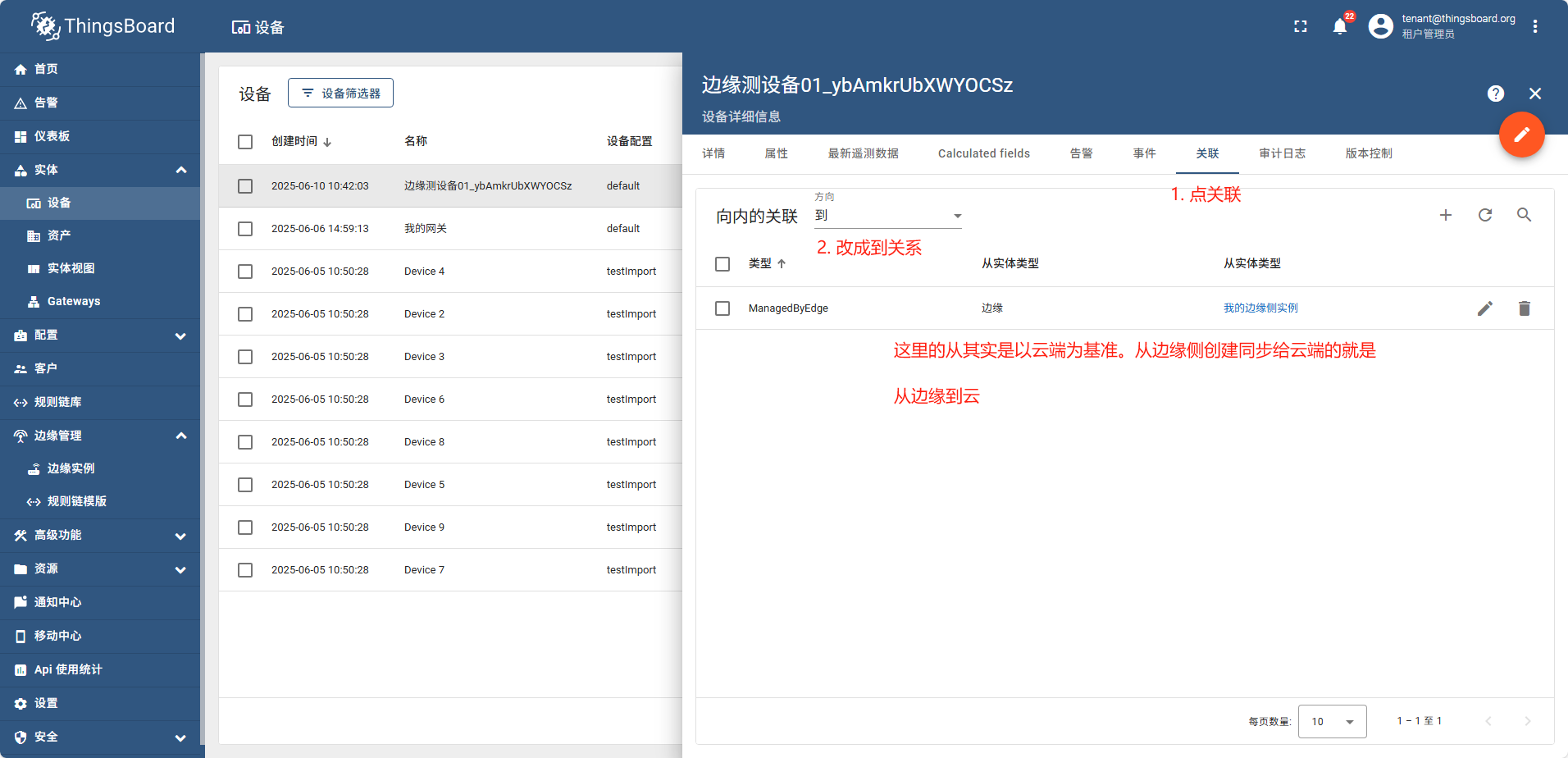
实体从云(Cloud)到边缘(Edge)
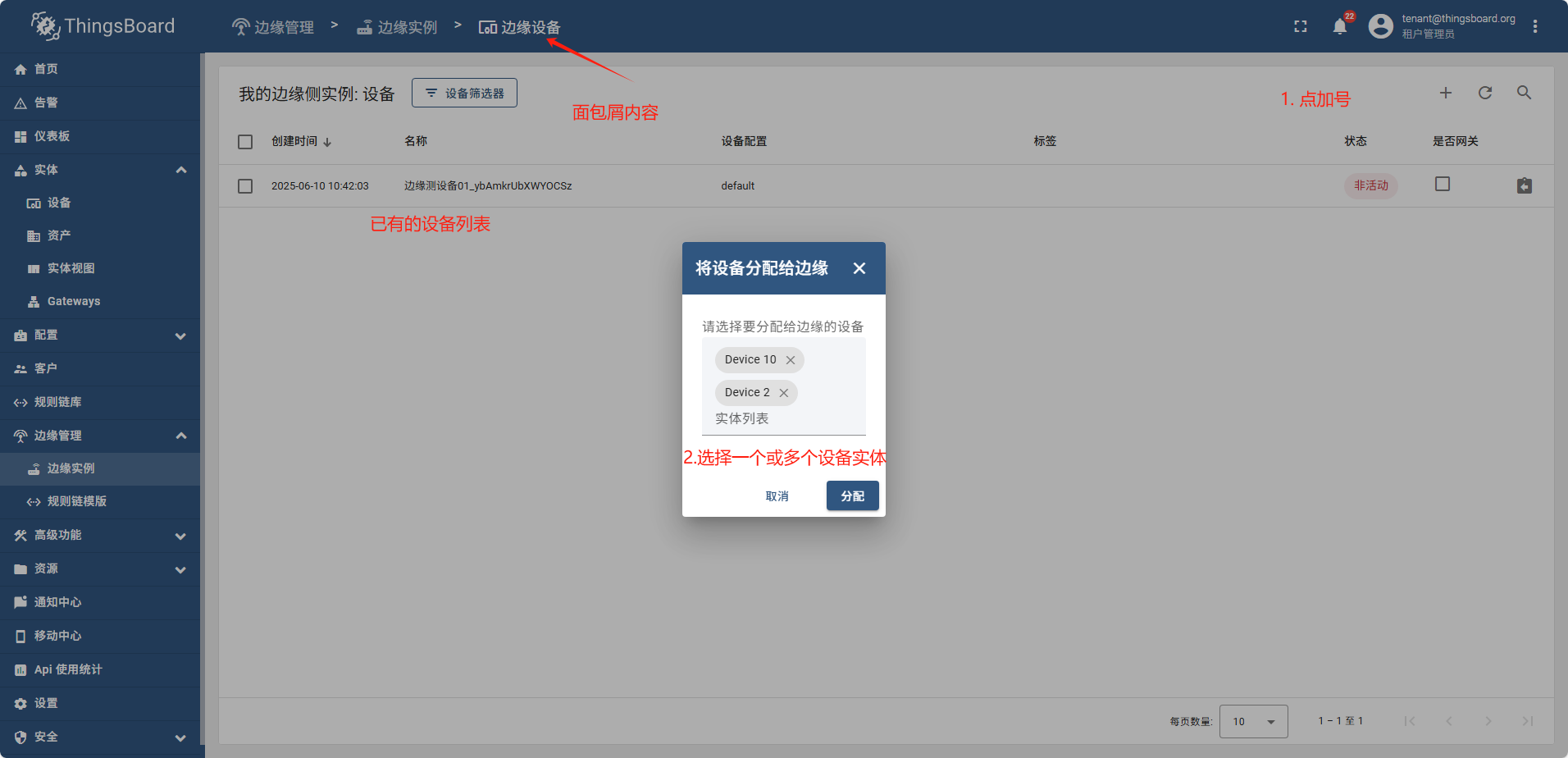
在边缘创建的实体可以自动的同步到云,也可以在云端创建实体后,然后分配给相关的实体
以下实体内容均可以从云端下发到边缘:资产 设备 实体视图 仪表板 规则链
方法为:
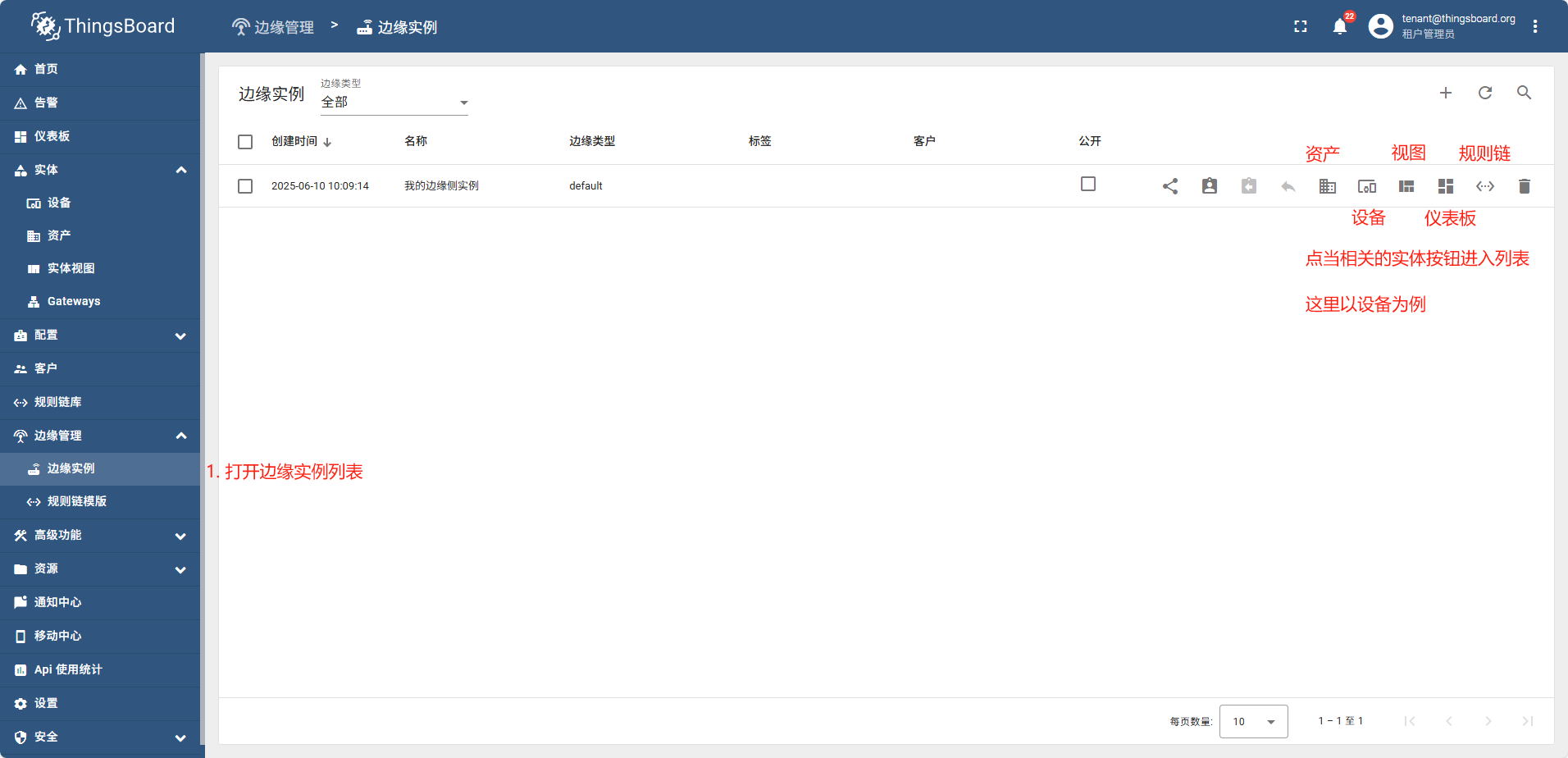
7.3 - 网关
网关存在的目的是将已有的IOT系统数据采集到ThingsBoard平台(包括云服务和边缘服务)中
新建网关(云端)
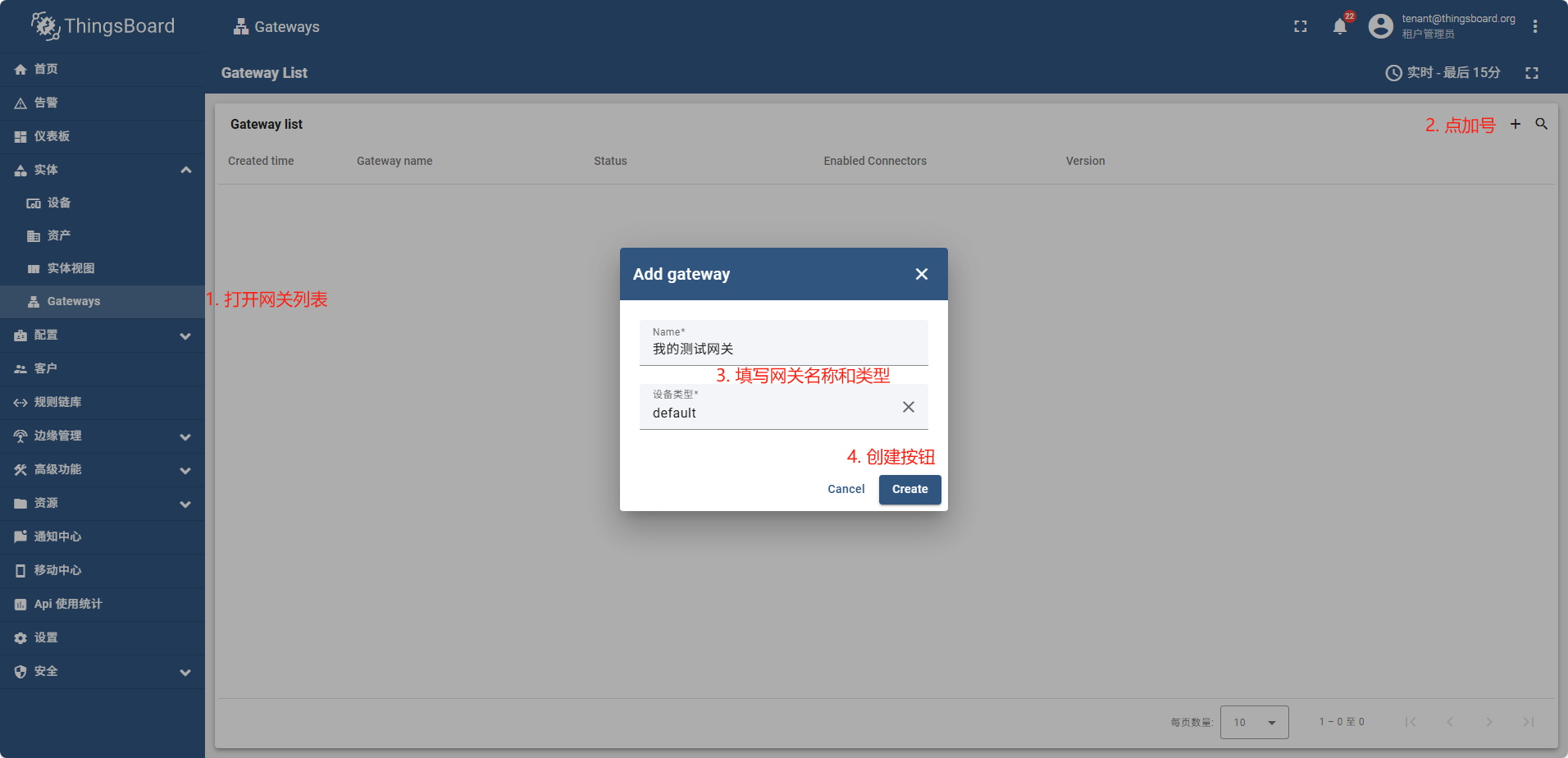
直接下载也可以,
关闭后也可以再找到这个页面进行下载
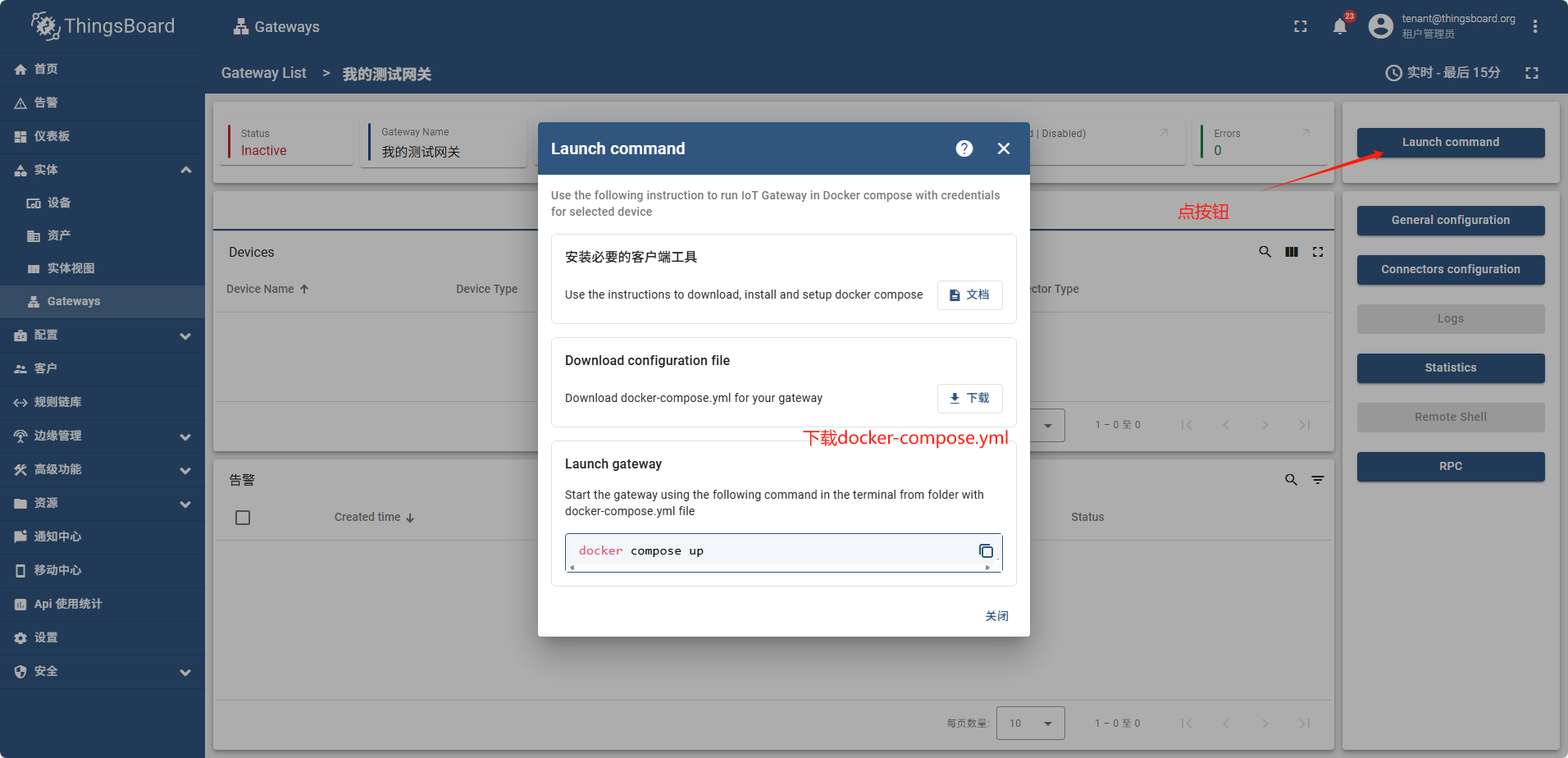
检查云端mqtt通信端口
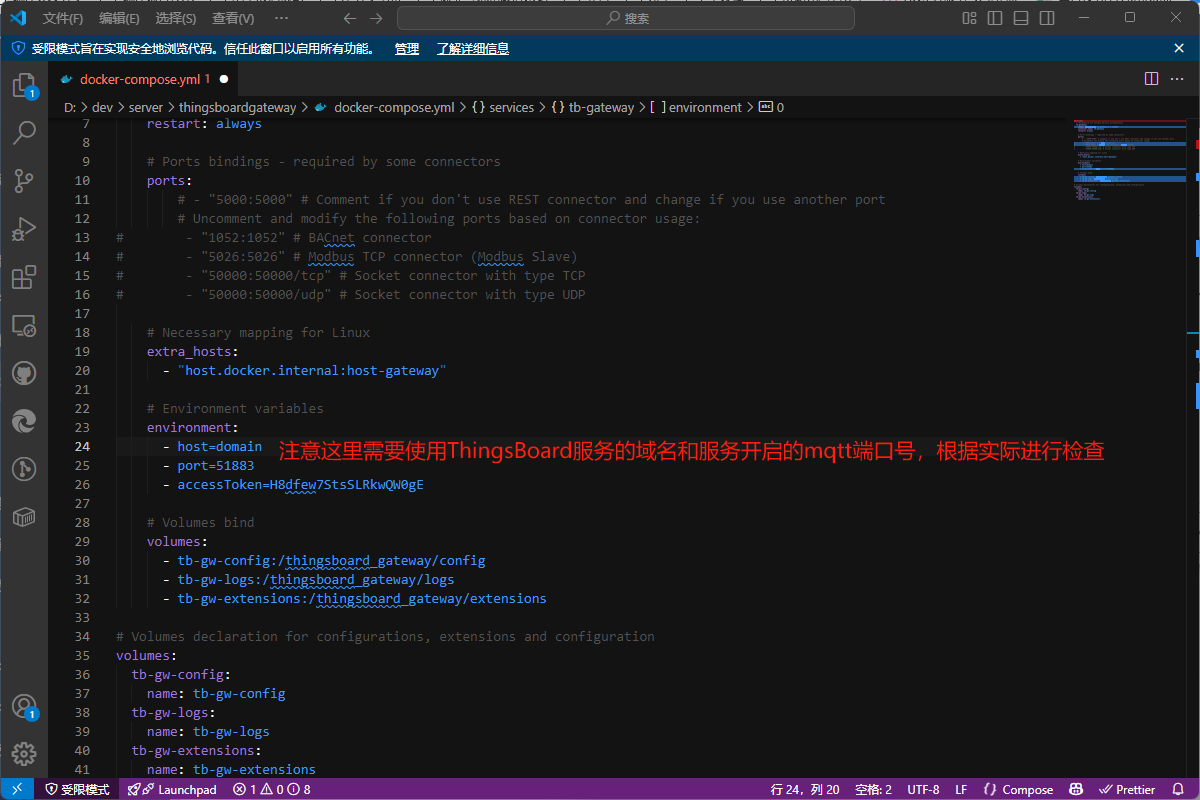
services:
# ThingsBoard IoT Gateway Service Configuration
tb-gateway:
image: thingsboard/tb-gateway:3.7-stable
container_name: tb-gateway
restart: always
# Ports bindings - required by some connectors
# ports:
# - "5000:5000" # Comment if you don't use REST connector and change if you use another port
# Uncomment and modify the following ports based on connector usage:
# - "1052:1052" # BACnet connector
# - "5026:5026" # Modbus TCP connector (Modbus Slave)
# - "50000:50000/tcp" # Socket connector with type TCP
# - "50000:50000/udp" # Socket connector with type UDP
# Necessary mapping for Linux
extra_hosts:
- "host.docker.internal:host-gateway"
# Environment variables
environment:
- host=home.anzhongwei.cn
- port=51883
- accessToken=H8dfew7StsSLRkwQW0gE
# Volumes bind
volumes:
- tb-gw-config:/thingsboard_gateway/config
- tb-gw-logs:/thingsboard_gateway/logs
- tb-gw-extensions:/thingsboard_gateway/extensions
# Volumes declaration for configurations, extensions and configuration
volumes:
tb-gw-config:
name: tb-gw-config
tb-gw-logs:
name: tb-gw-logs
tb-gw-extensions:
name: tb-gw-extensions
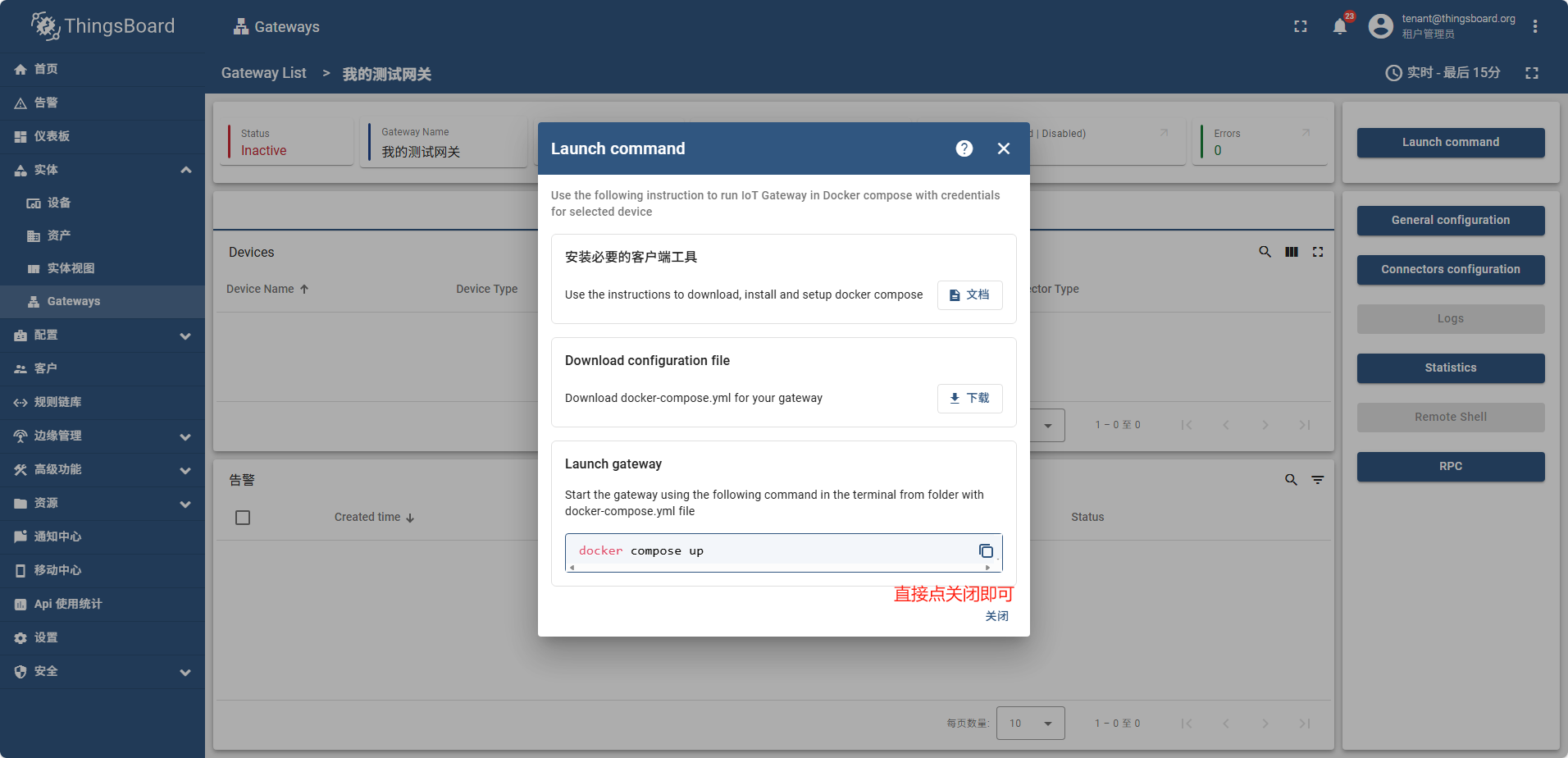
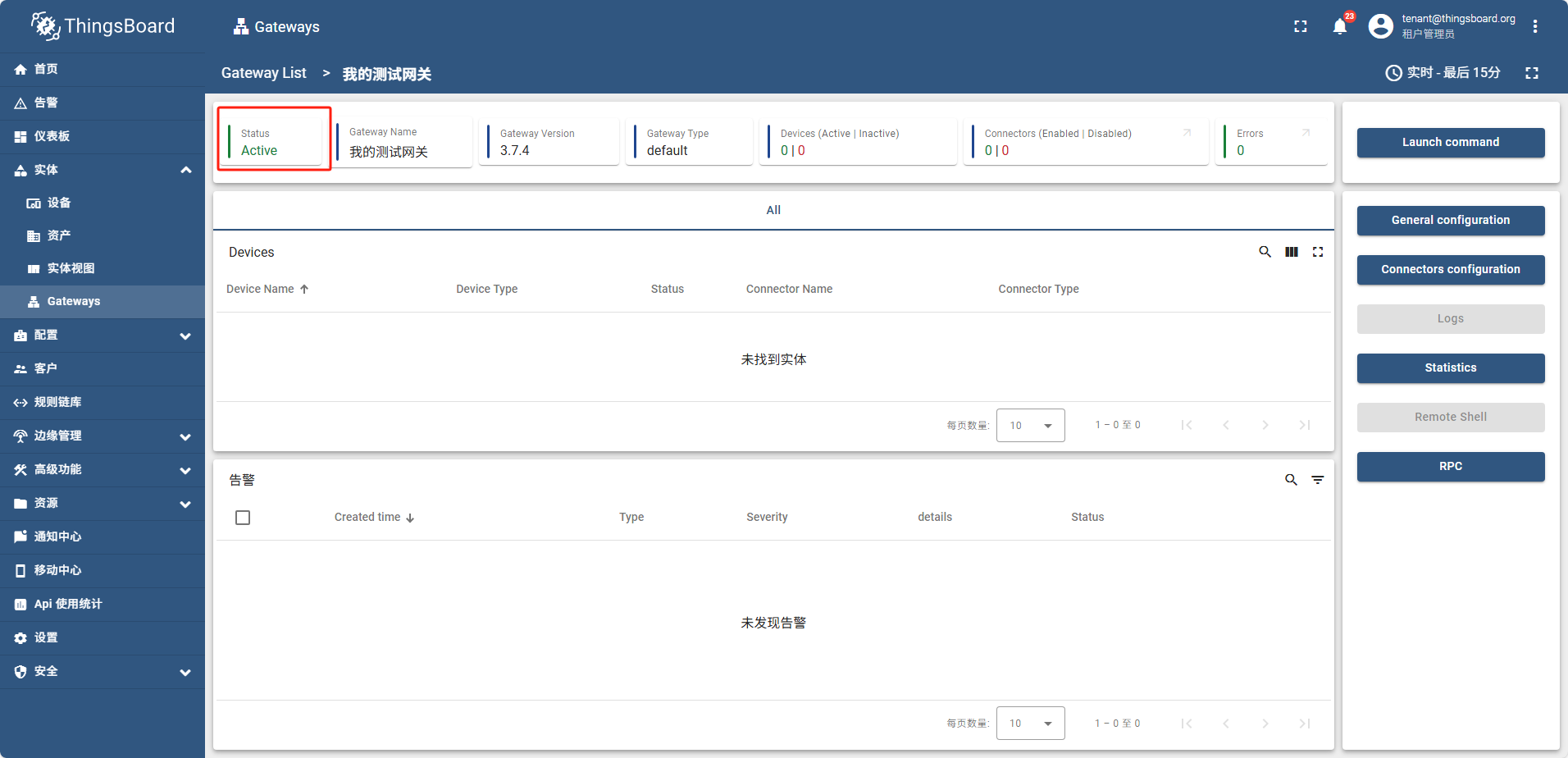
运行成功后,网关状态为 活动的(Active)
新建网关(边缘)
边缘侧网关创建操作和在云端完全一致,唯一区别是启动时连接的mqtt的host地址是边缘侧mqtt的ip地址
因为是在docker内启动, 即使是本机也需要使用宿主机的ip不能用localhost
version: '3.4'
services:
# ThingsBoard IoT Gateway Service Configuration
tb-gateway-edge:
image: thingsboard/tb-gateway:3.7-stable
container_name: tb-gateway-edge
restart: always
# Ports bindings - required by some connectors
# ports:
# - "5000:5000" # Comment if you don't use REST connector and change if you use another port
# Uncomment and modify the following ports based on connector usage:
# - "1052:1052" # BACnet connector
# - "5026:5026" # Modbus TCP connector (Modbus Slave)
# - "50000:50000/tcp" # Socket connector with type TCP
# - "50000:50000/udp" # Socket connector with type UDP
# Necessary mapping for Linux
extra_hosts:
- "host.docker.internal:host-gateway"
# Environment variables
environment:
- host=192.168.77.30 // 因为是在docker中启动,所以连接需要用ip,即使是本机也不能用localhost
- port=1883
- accessToken=opd2kpPHsS4EuChHe6zJ
# Volumes bind
volumes:
- tb-gw-edge-config:/thingsboard_gateway/config
- tb-gw-edge-logs:/thingsboard_gateway/logs
- tb-gw-edge-extensions:/thingsboard_gateway/extensions
# Volumes declaration for configurations, extensions and configuration
volumes:
tb-gw-edge-config:
name: tb-gw-edge-config
tb-gw-edge-logs:
name: tb-gw-edge-logs
tb-gw-edge-extensions:
name: tb-gw-edge-extensions
启用远程日记
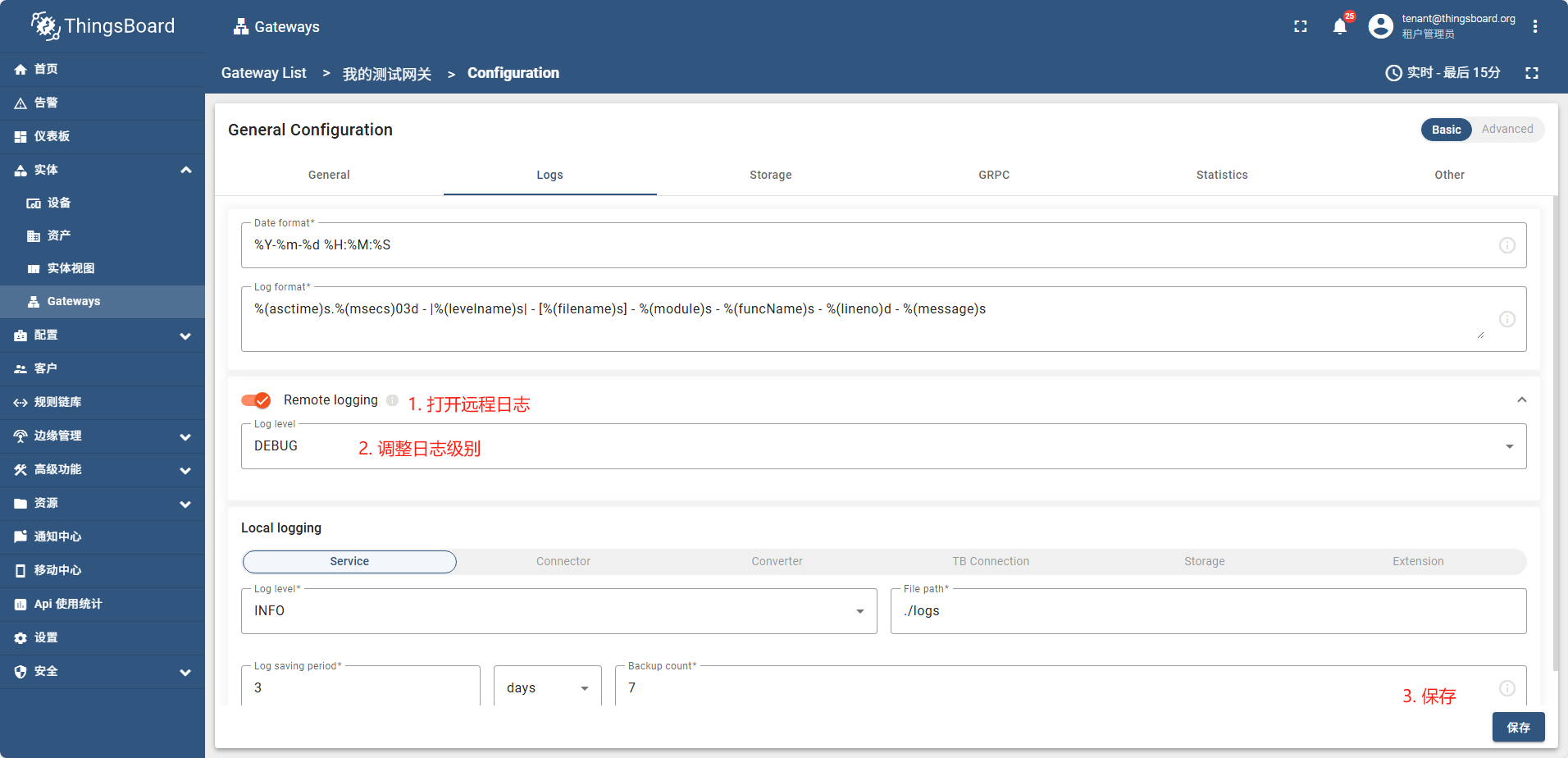
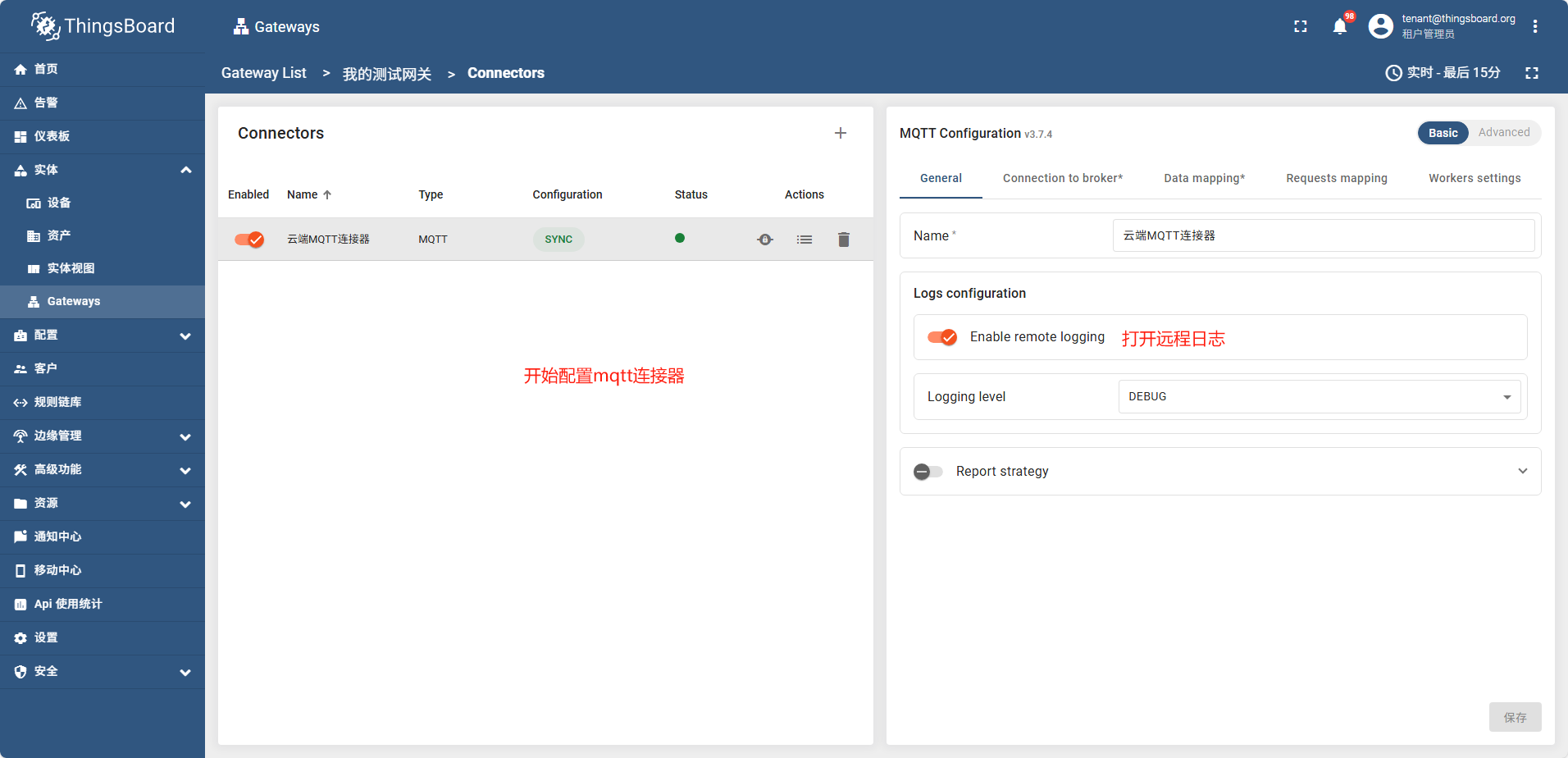
创建一个MQTT连接器
- 首先启动一个mqtt代理,模拟一个在运行的mqtt服务
docker run -it -p 1884:1884 thingsboard/tb-gw-mqtt-broker:latest
这个mqtt代理会不停的发送信息
- 创建一个连接器
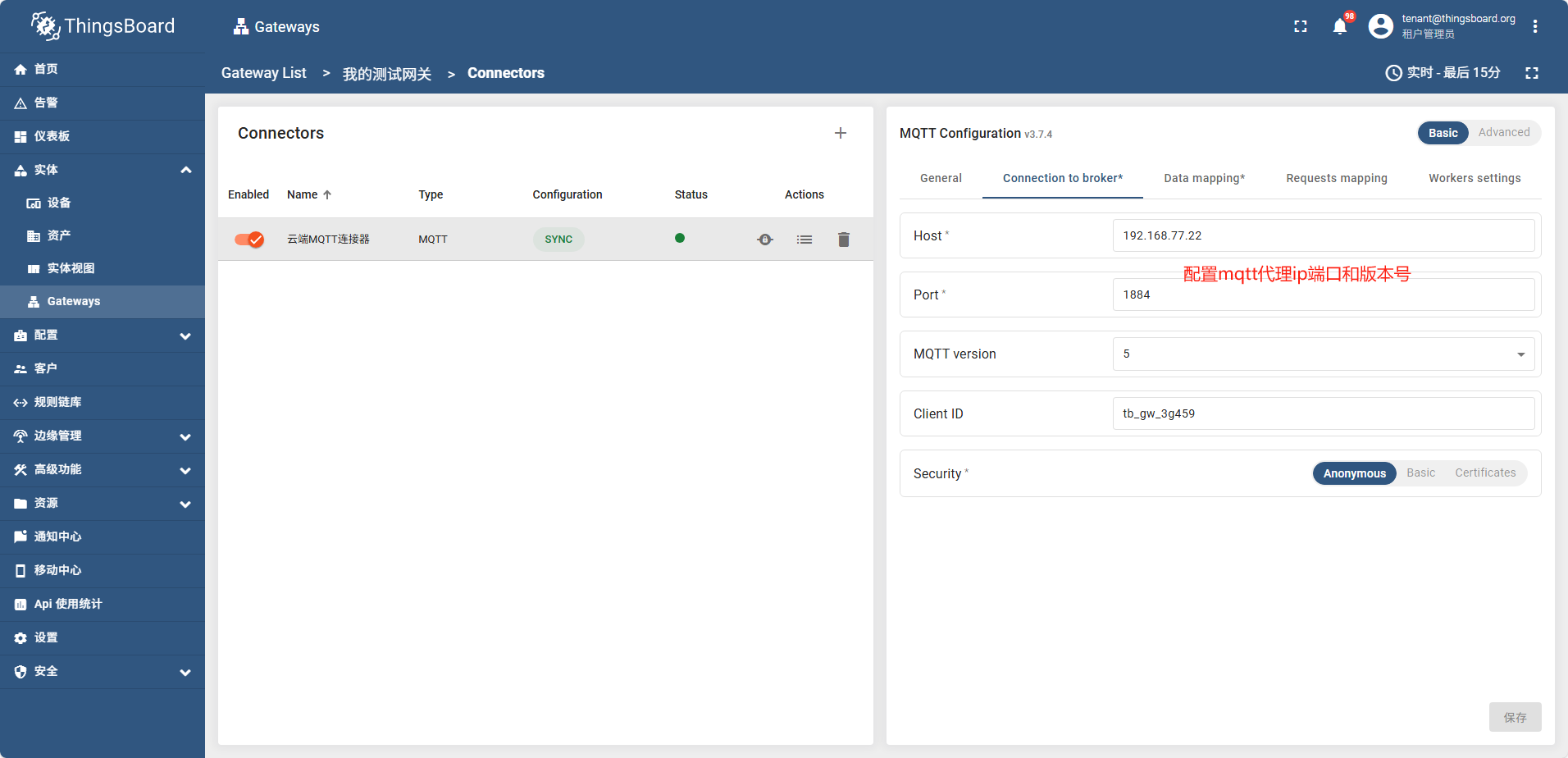
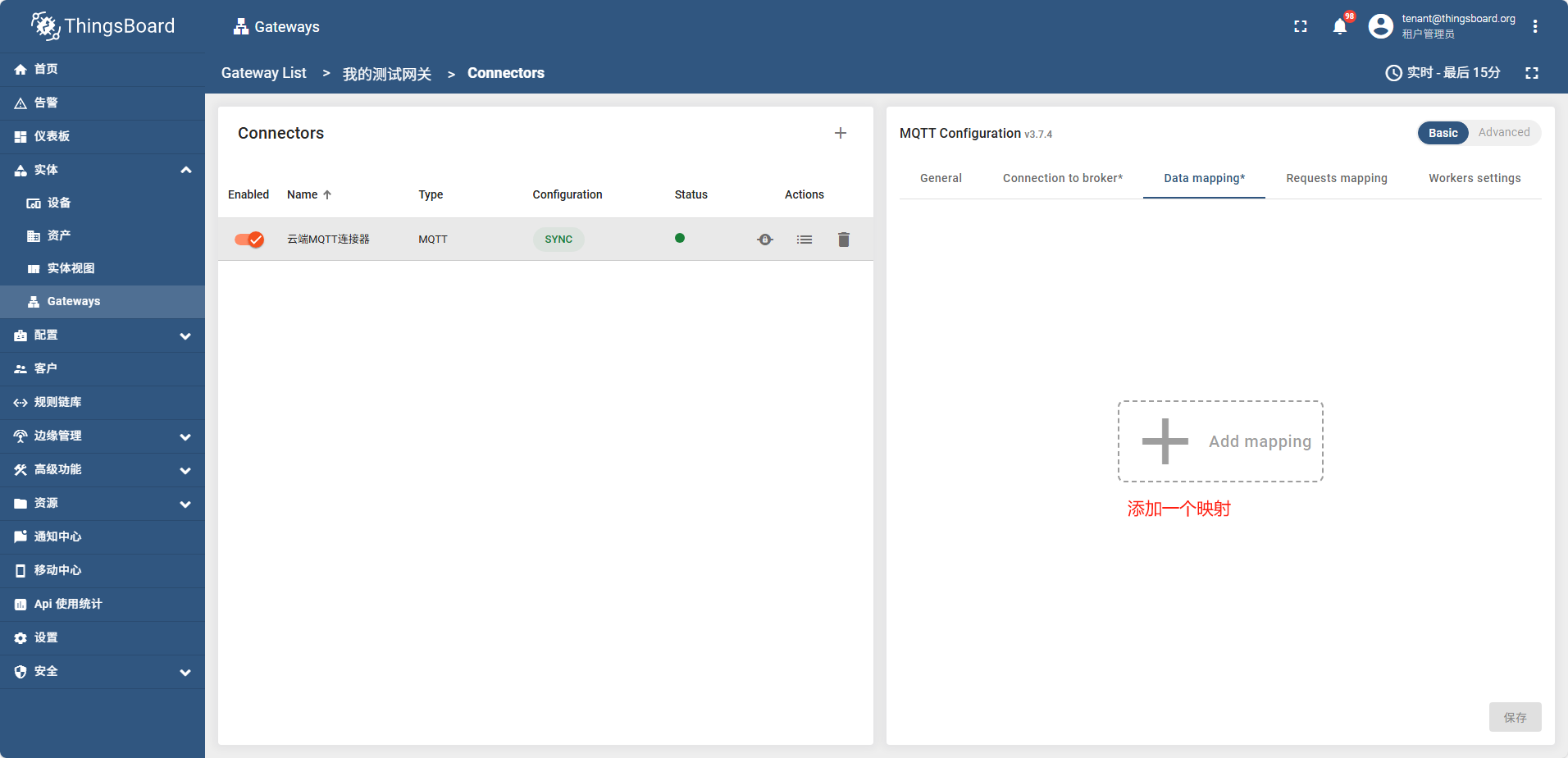
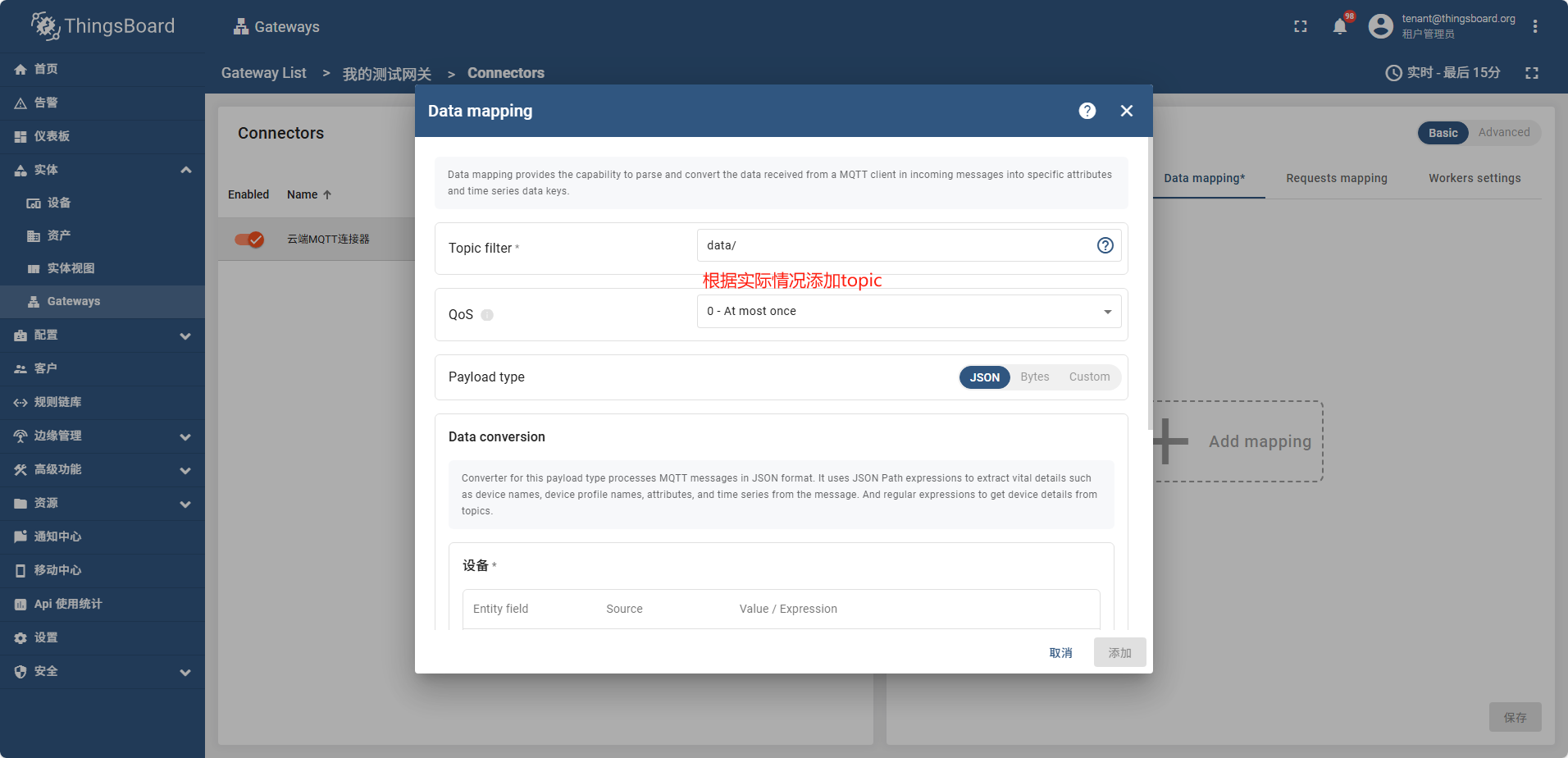
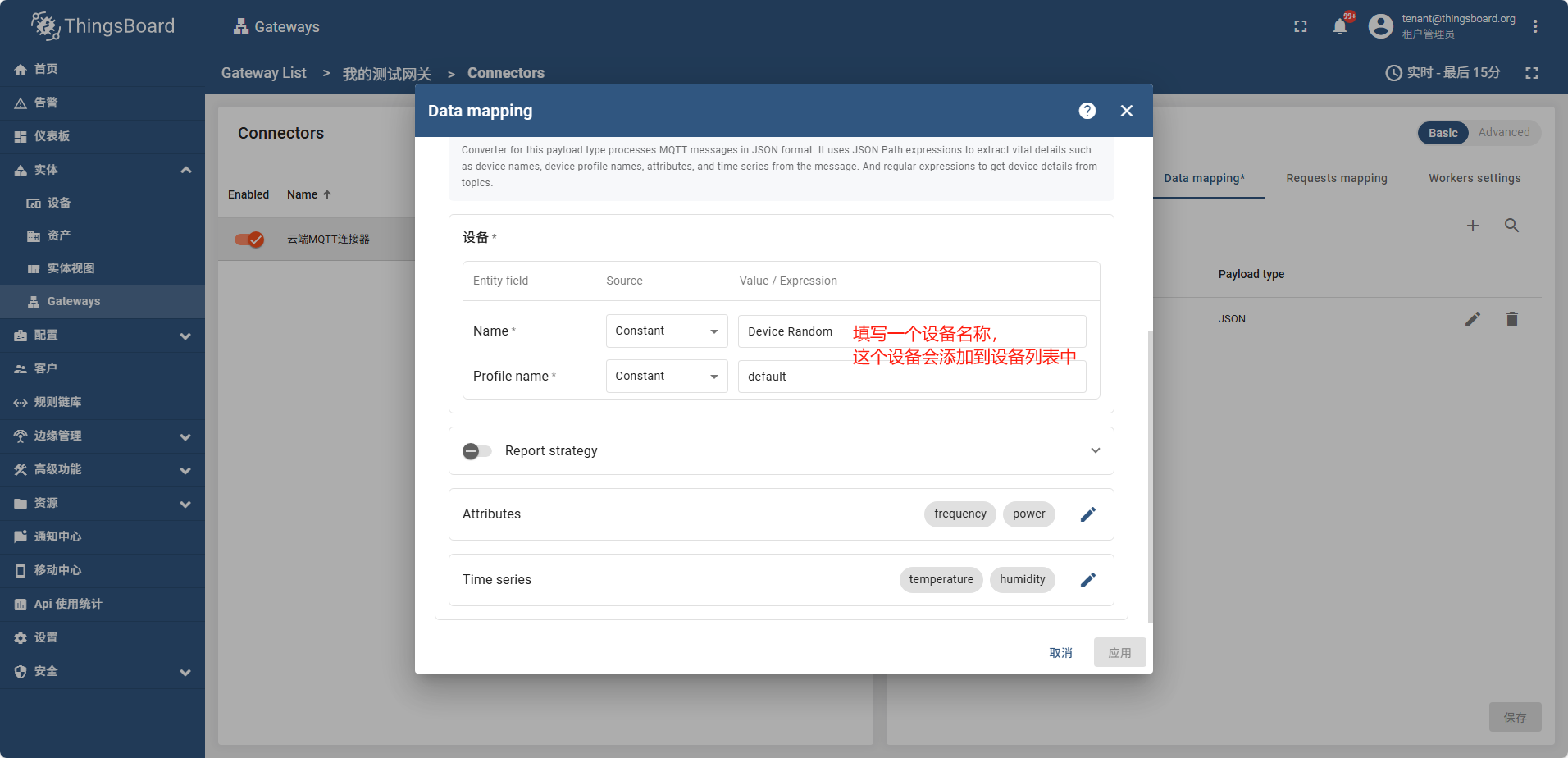
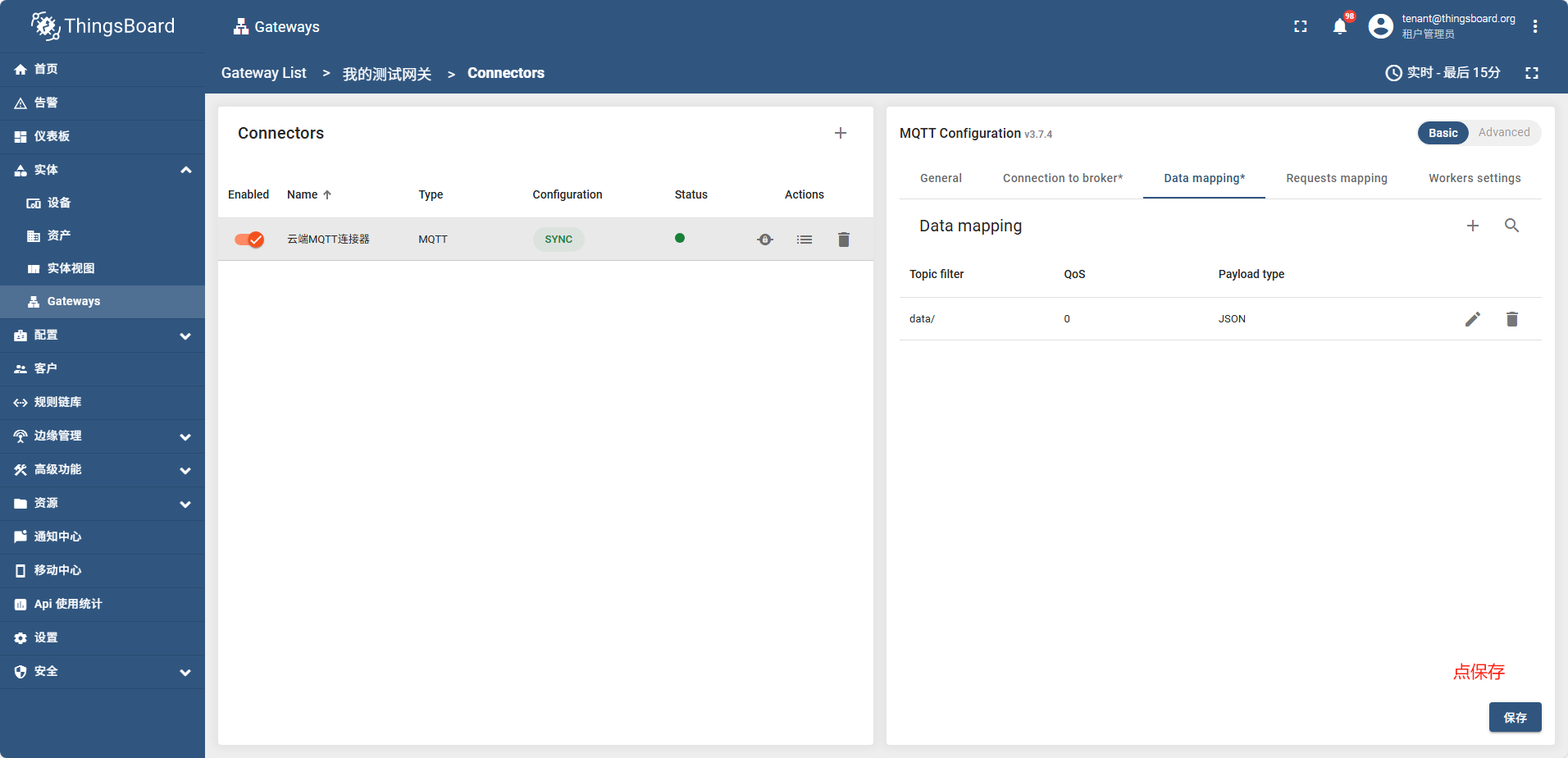
点保存后过一会,网关状态变成了绿色,说明网关成功连接了
mqtt代理控制台日志显示

之后配置 Attributes Time series 如图
frequency power
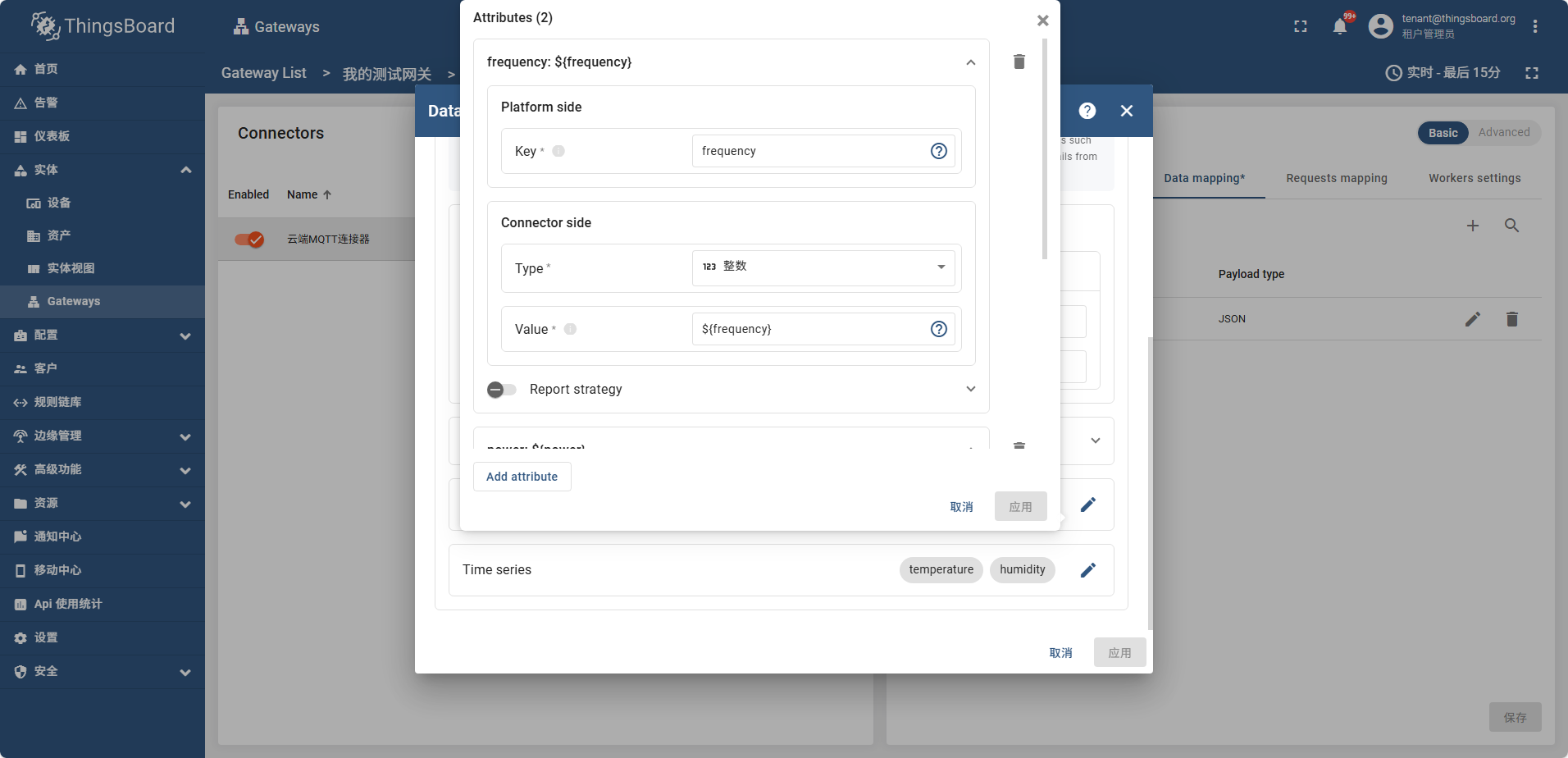
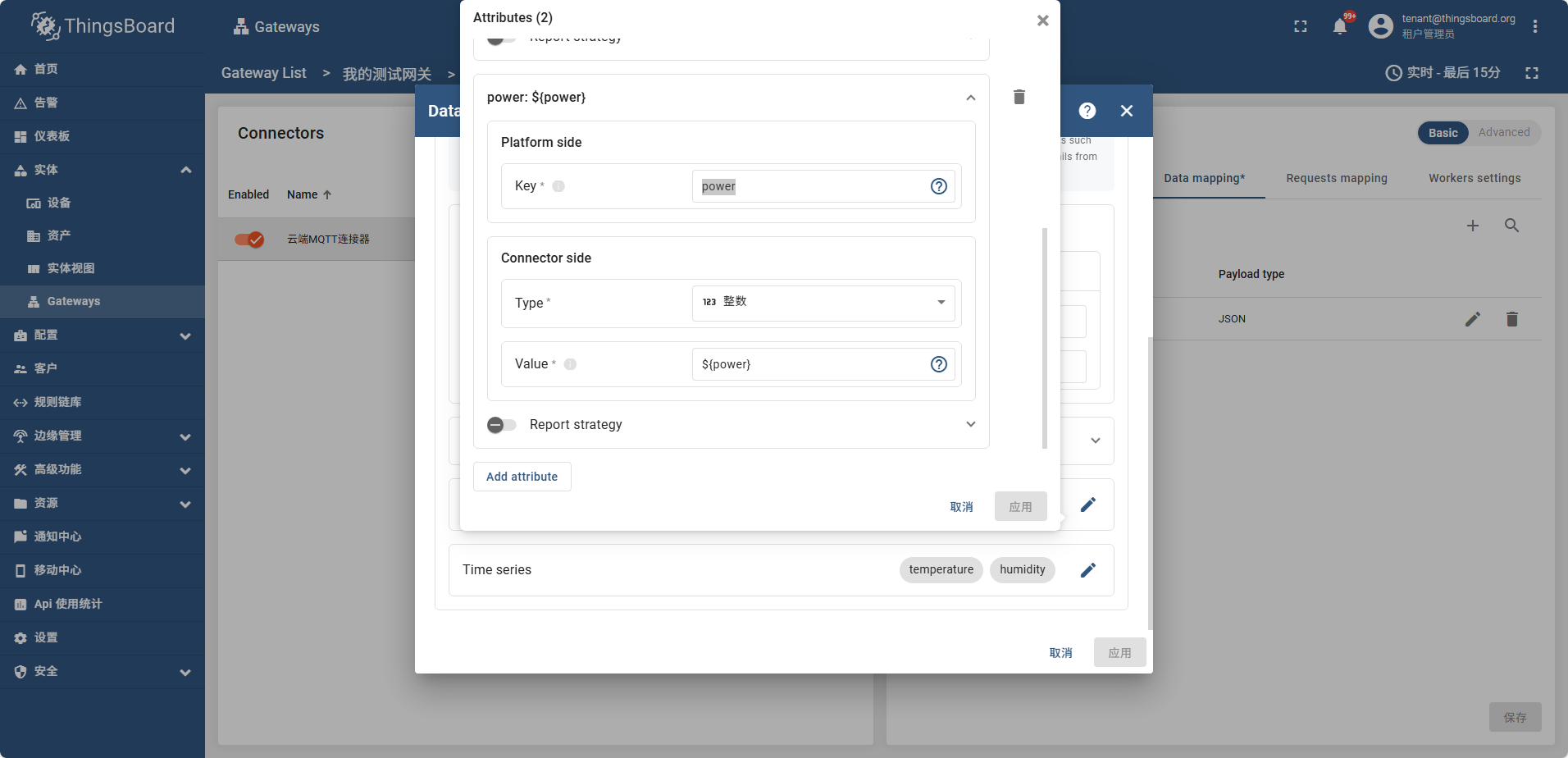
temperature humidity
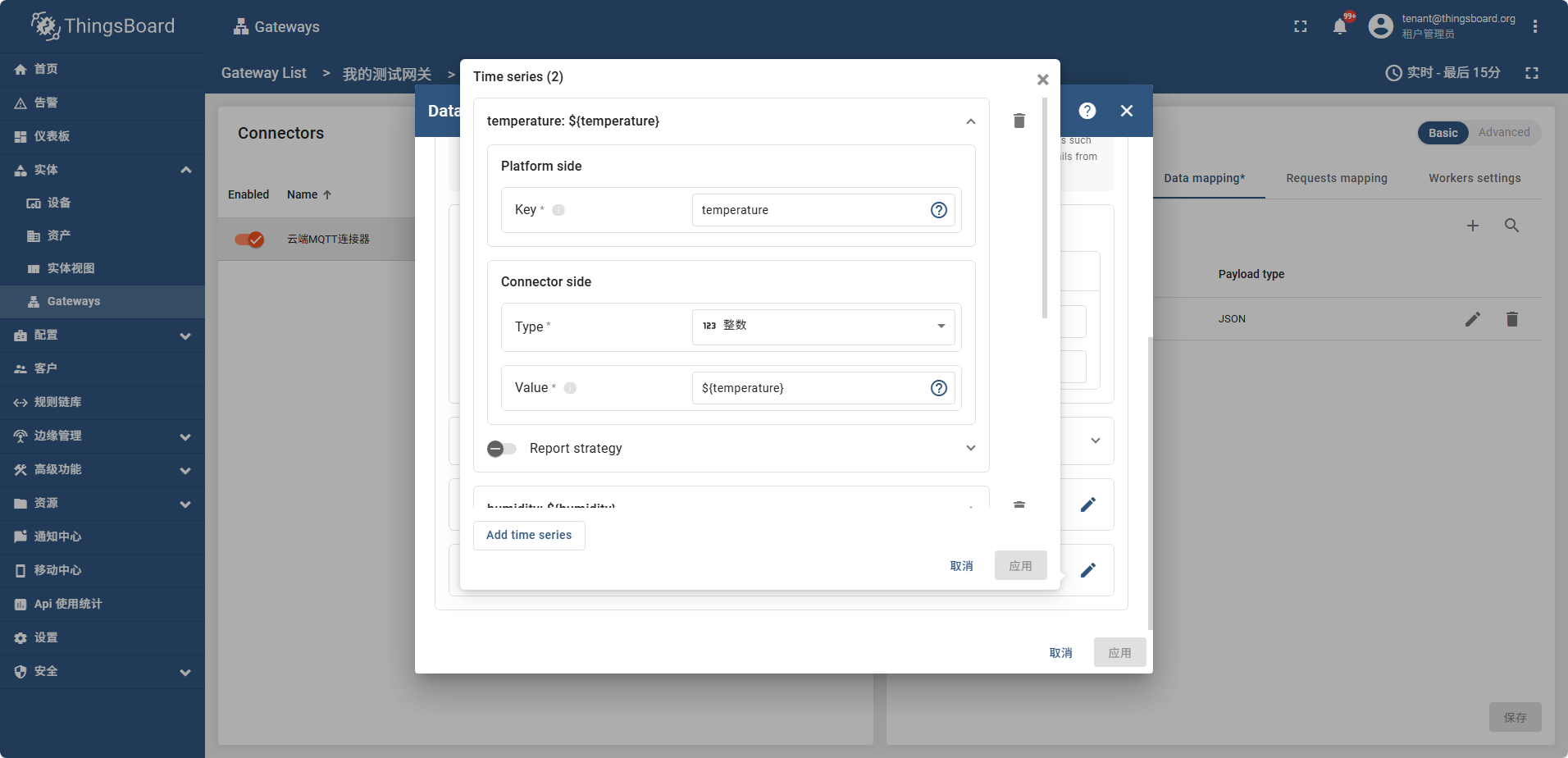
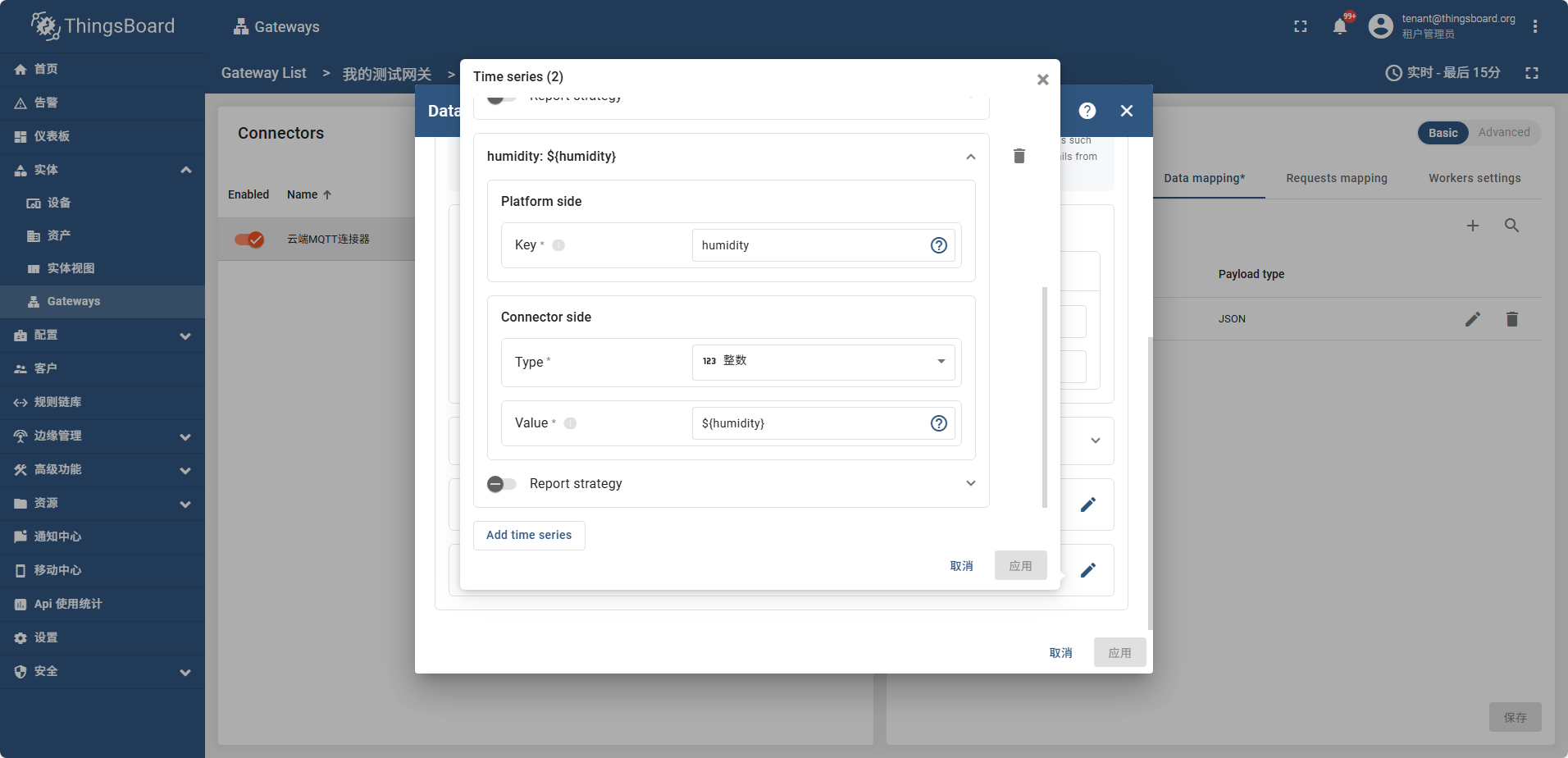
配置好属性后 打开网关信息页面
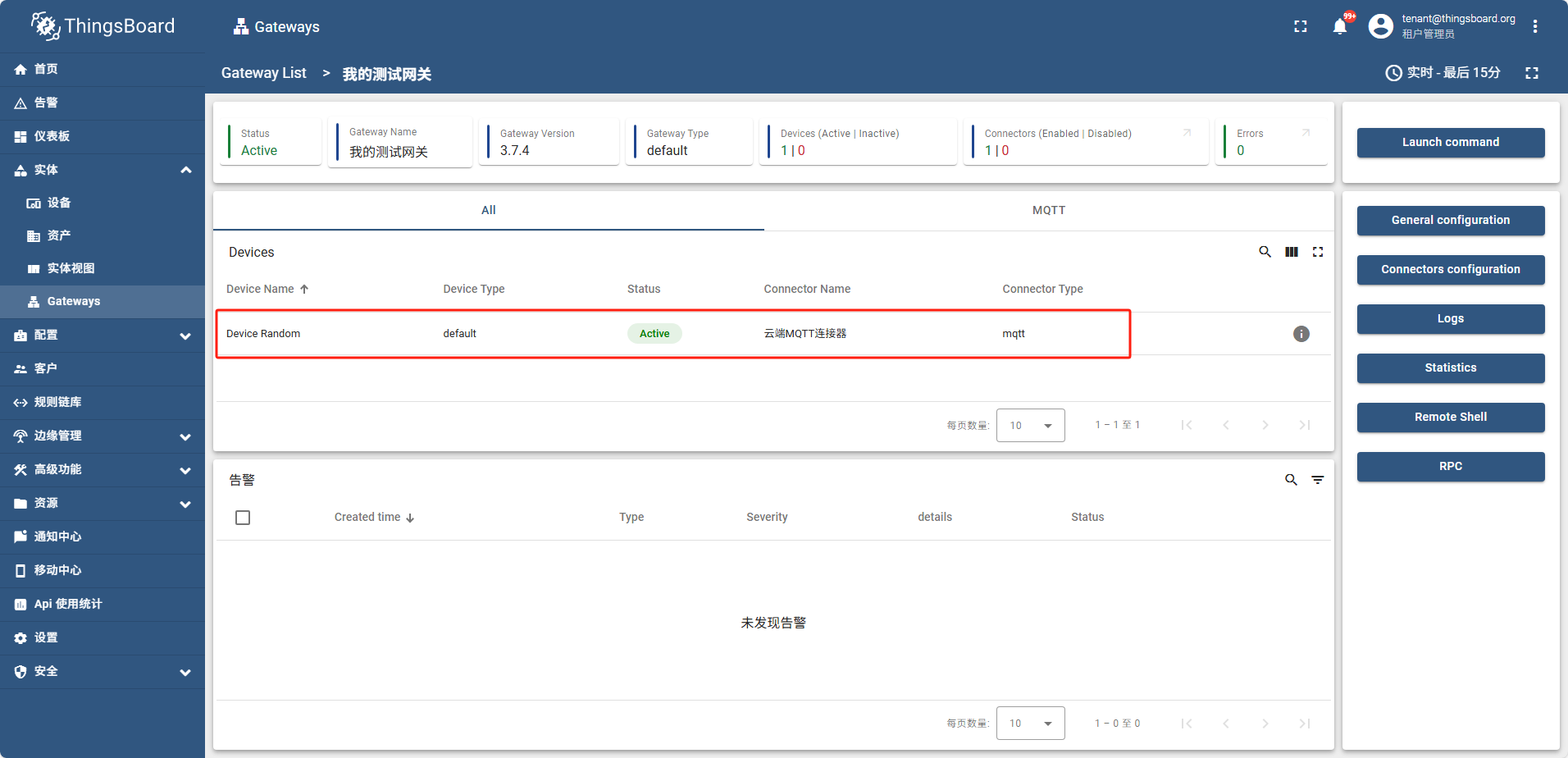
此时设备列表中也可以搜索到这个设备,并且属性tag页可以看到 temperature humidity
在遥测数据中可以看到
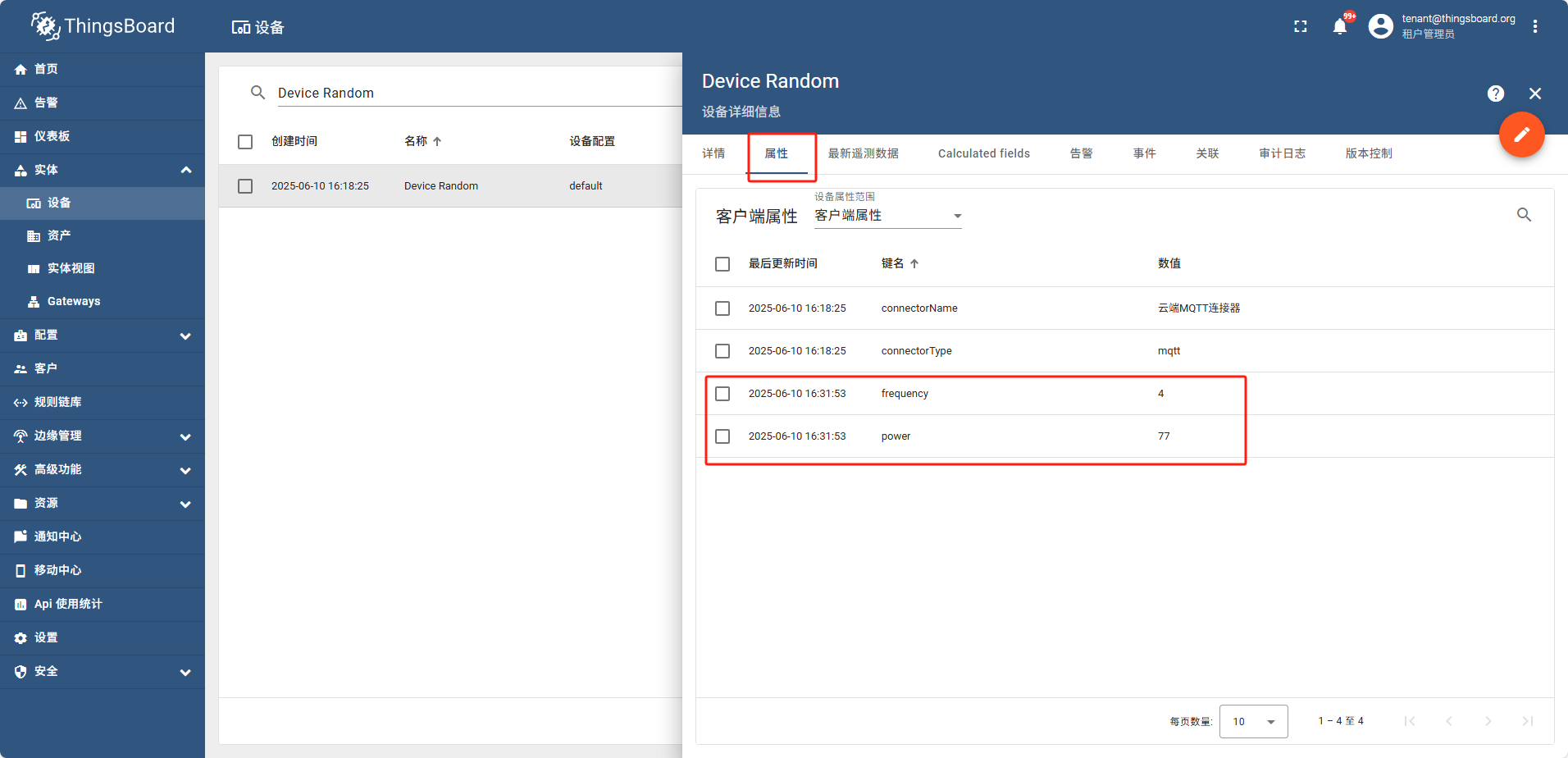
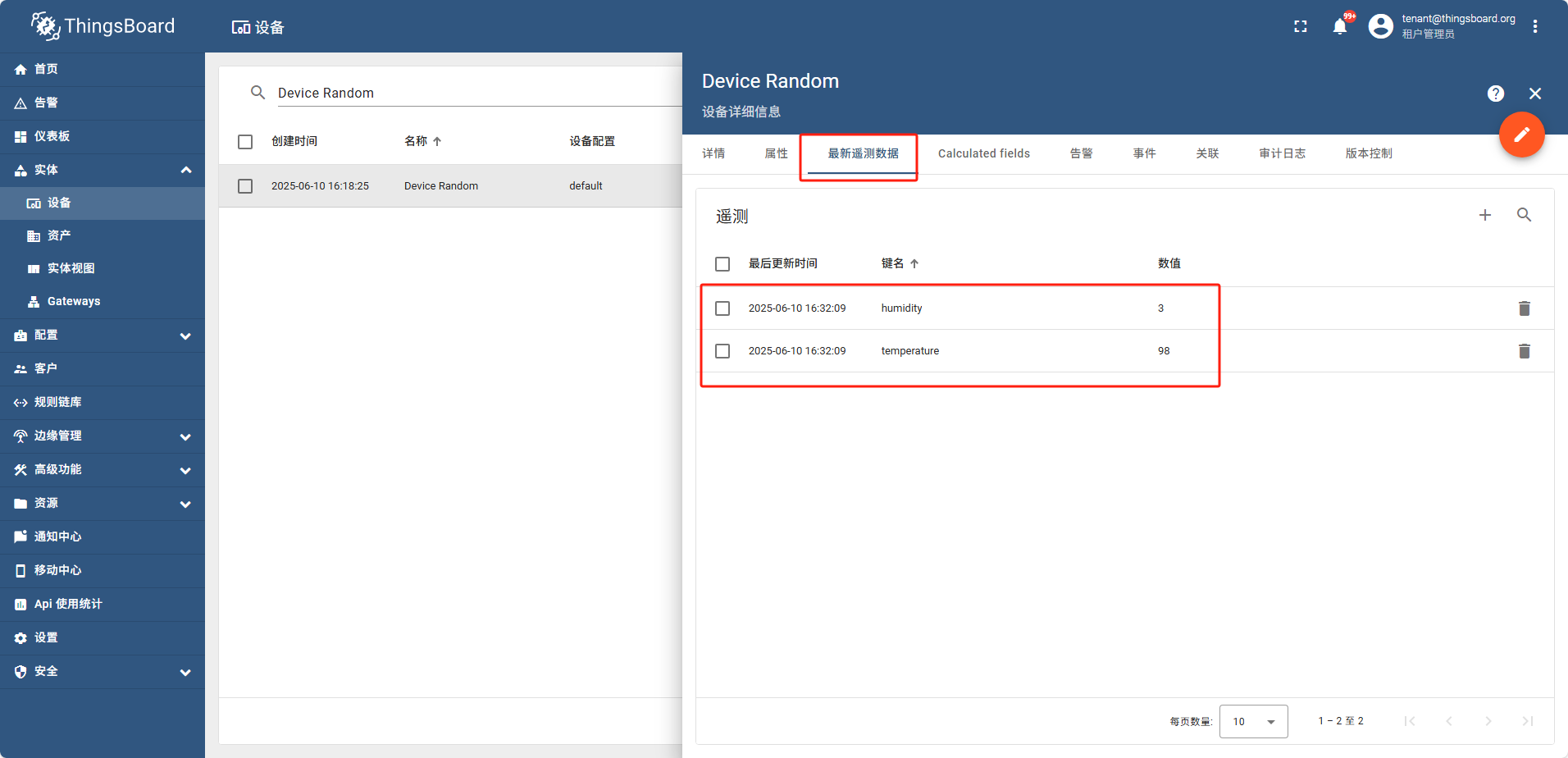
8 - JetBrains全家桶
windows idea配置文件位置: C:\Users\admin\AppData\Roaming\JetBrains
8.1 - CLion 控制台输出内容乱码问题的解决方法
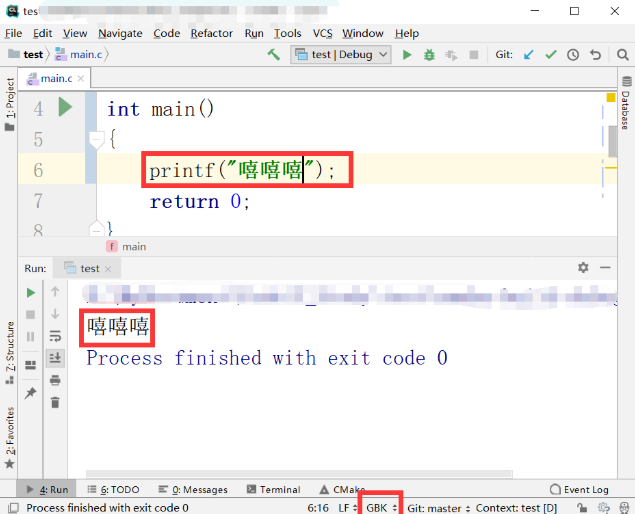
问题再现
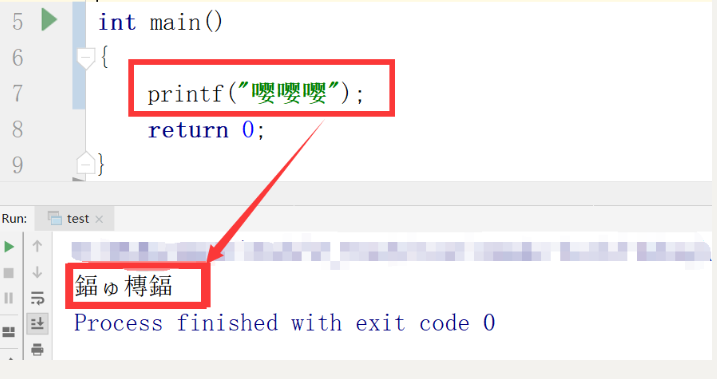
#include "stdio.h"
#include "stdlib.h"
int main()
{
printf("嘤嘤嘤");
return 0;
}
问题原因
现状
- 编译器没报错
- 字符出现乱码
推测
- 字符编码不一
- 控制台编码与文件编码不一样
解决办法
- 修改字符编码
解决步骤
进入设置界面
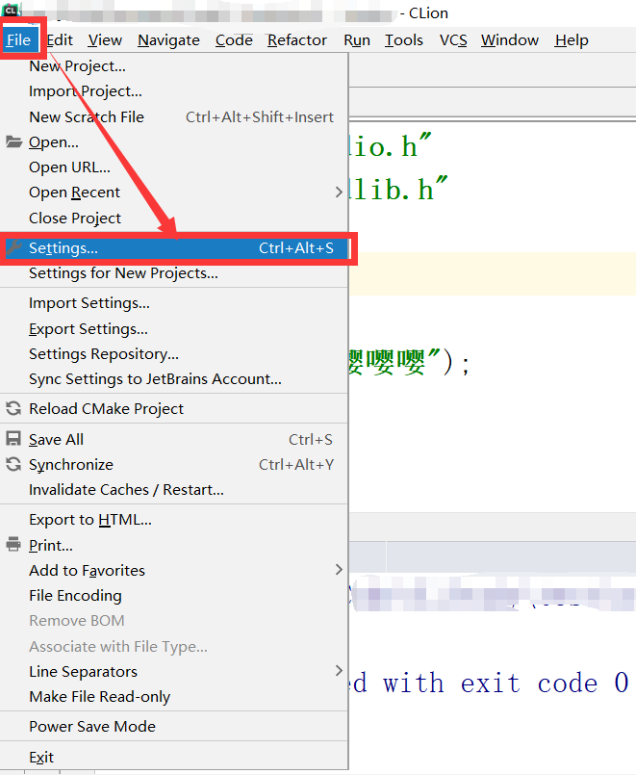
设置编码,这里为了方便,我们统一设置为UTF—8
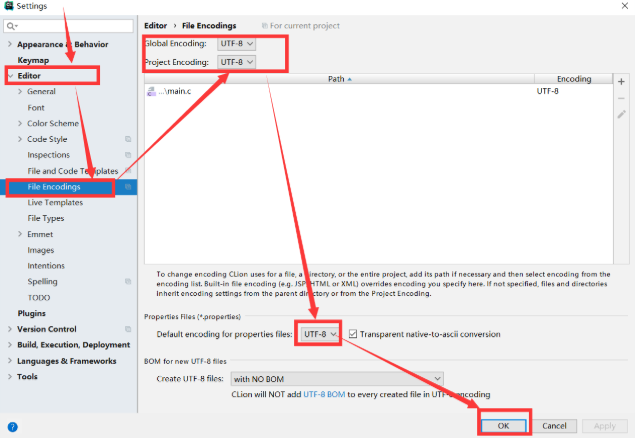
返回界面,更改输入字符块为GBK
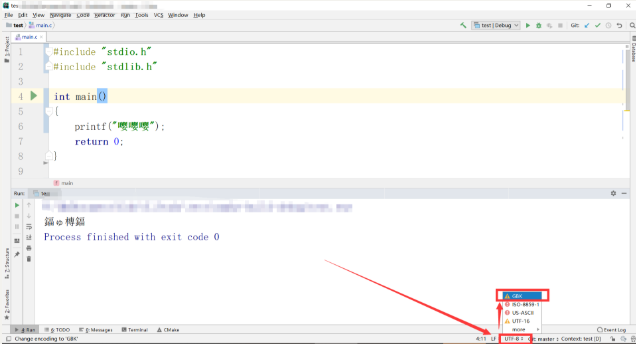
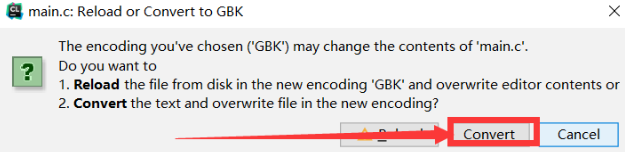
这里记得,会弹出一个对话框
使代码发生变动,重新编译并运行,这里我们把“嘤嘤嘤”换成“嘻嘻嘻”,然后编译,成功后运行
9 - certbot
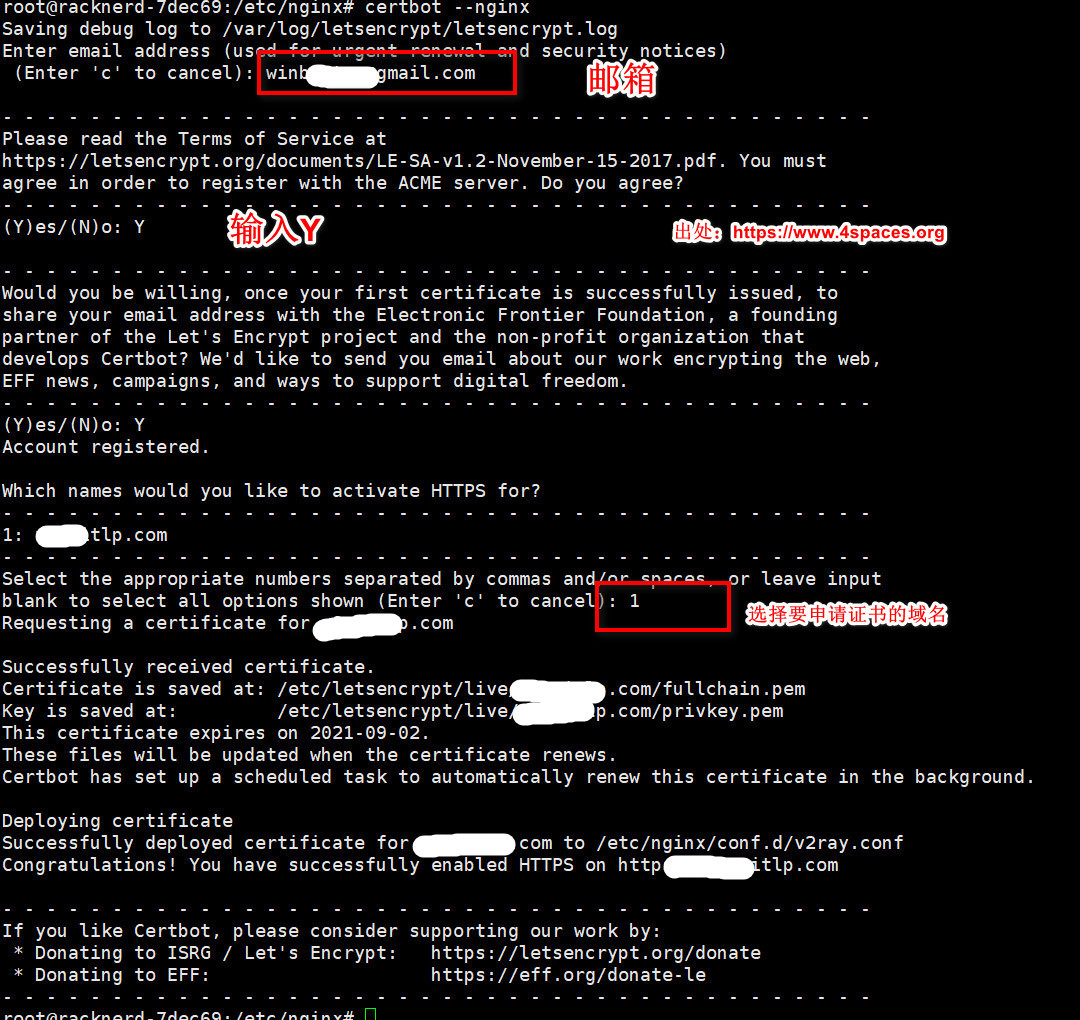
sudo apt install certbot
让 Certbot 自动编辑您的 nginx 配置以提供证书,只需一步即可打开 HTTPS 访问
sudo certbot –nginx
如果您感觉更保守,并希望手动更改 nginx 配置,请运行此命令
sudo certbot certonly –nginx
Let’s Encrypt 证书的有效期为 90 天,因此您需要设置自动续期以确保证书不会过期。
您可以使用 Certbot 的自动续期功能,或者设置一个定时任务来定期更新证书。您可以通过运行以下命令来测试证书的自动续期
sudo certbot renew –dry-run
这是一个 用 certbot 阿里云插件 申请阿里云免费证书的方式暂时没验证过
https://zhuanlan.zhihu.com/p/25571676513
10 - easytier
EasyTier 是一款简单、安全、去中心化的内网穿透和异地组网工具,适合远程办公、异地访问、游戏加速等多种场景。无需公网 IP,无需复杂配置,轻松实现不同地点设备间的安全互联。
官方文档地址:https://easytier.cn/
10.1 - 完全私有化部署
本说明出自非官方。是个人的搭建经验总结,仅代表个人见解, 有问题欢迎讨论
本说明环境基于 阿里云ECS ,linux发行版 ubuntu2204, easytier版本 v2.4.5
下载地址请移步官方网站
本说明从共有四个步骤
-
搭建web管理平台服务
-
启动私有共享节点
-
在需要组网的服务器或PC,以web的方式启动服务(Linux 和 Windows 分别进行配置说明)
-
其他组网工具演示
先下载对应的二进制包: https://github.com/EasyTier/EasyTier/releases
内部存在 easytier-core easytier-web-embed easytier-cli easytier-web(用不到)
1. 搭建web管理平台服务
前置预设:
我的域名假设为 easytier.mydomain.com
使用的可执行文件为 easytier-web-embed
配置参数示意
–config-server-port 22222
–web-server-port 11111
–api-server-port 11111
–api-host http://easytier.mydomain.com:11111
新建文件easytier-web-emdeb.service内容如下
[Unit]
Description=EasyTier Service
After=network.target syslog.target
Wants=network.target
[Service]
Type=simple
ExecStart=${path}/easytier-linux-x86_64/easytier-web-embed \
--db ${path}/easytier-linux-x86_64/web-embed/easytier-web-embed.db \
--file-log-level warn \
--file-log-dir ${path}/easytier-linux-x86_64/web-embed/easytier-web-embed-log \
--config-server-port ${port1} \
--config-server-protocol udp \
--api-server-port ${port2} \
--web-server-port ${port2} \
--api-host http://${domain}:${port2}
[Install]
WantedBy=multi-user.target
因为在配置项中使用到了 ${path}/easytier-linux-x86_64/web-embed
检查 ${path}/easytier-linux-x86_64/web-embed 目录是否存在
然后把easytier-web-emdeb.service文件复制到/etc/systemd/system/
启动服务: sudo systemctl start easytier-web-emdeb.service
根据自己服务器类型配置好防火墙访问:
http://easytier.mydomain.com:11111 即可获得web端登录效果
然后 注册 登录步骤略
API Host地址同样是 http://easytier.mydomain.com:11111
此处假设我注册的用户名是 abcdefg
步骤二:启动私有共享节点
当前环境中web服务和共享节点用的是同一台服务器
修改 easytier-share-center.service 中相关的变量内容
[Unit]
Description=EasyTier Service
After=network.target syslog.target
Wants=network.target
[Service]
Type=simple
ExecStart=${path}/easytier-linux-x86_64/easytier-core -c ${path}/easytier-linux-x86_64/custom-shard-center.toml
[Install]
WantedBy=multi-user.target
custom-shard-center.toml
# 主机名,用于标识此设备的名称
hostname = "改成你的内容"
# 虚拟局域网的 IPv4 地址,如果为空,则此节点将仅转发数据包,不会创建 TUN 设备
ipv4 = ""
# 是否自动分配虚拟局域网的 IPv4 地址
dhcp = false
# 监听器列表,用于接受连接
# 如果改了监听器端口, 请同步修改防火墙相关端口出入站规则
listeners = [
"tcp://0.0.0.0:11010",
]
# 用于管理的 RPC 门户地址
rpc_portal = "127.0.0.1:15888"
# 网络名称和密码
[network_identity]
network_name = "改成你的内容"
network_secret = "改成你的内容"
# 程序日志设置
[file_logger]
# 日志等级
# off:关闭所有日志记录
# fatal:指出每个严重的错误事件将会导致应用程序的退出
# error:指出虽然发生错误事件,但仍然不影响系统的继续运行
# warn:表明会出现潜在错误的情形,有些信息不是错误信息,但是也要给程序员的一些提示
# info:在粗粒度级别上突出强调应用程序的运行过程,能够用于生产环境中输出程序运行的一些重要信息程序
# debug:指出细粒度信息事件对调试应用程序是非常有帮助的,主要用于开发过程中打印一些运行信息
# trace:用于展现程序执行的轨迹,如函数间的相互调用,关系函数的参数和返回值等现场信息
# all:打开所有日志记录
level = "off"
# 日志文件名称前缀
file = "easytier"
# 日志文件存放目录
dir = "opt/easytier/logs/"
# 其它设置
[flags]
# 连接到对等节点使用的默认协议
default_protocol = "tcp"
# 是否开启对等节点通信的加密,必须与对等节点相同
enable_encryption = true
# 是否使用多线程运行
multi_thread = true
# 线程数
multi_thread_count = 2
# 是否启用 IPv6 支持
enable_ipv6 = true
# 延迟优先模式,将尝试使用最低延迟路径转发流量,默认使用最短路径
latency_first = true
# 仅转发白名单网络的流量,支持通配符字符串。多个网络名称间可以使用英文空格间隔。
# 如果本地网络(使用 network_name 分配)不在白名单中,如果没有其他路由路径可用,流量仍然可以转发。
# 如果该参数为空,则禁用转发。默认允许所有网络。
# 例如:'*'(所有网络),'def*'(以def为前缀的网络),'net1 net2'(只允许net1和net2)"
relay_network_whitelist = "*"
# 是否禁用 P2P (直连)
disable_p2p = false
# 是否禁用 UDP 打洞(直连)
disable-udp-hole-punching = true
# 是否转发所有对等节点的 RPC 数据包,即使对等节点不在转发网络白名单中
# 这可以帮助白名单外网络中的对等节点建立 P2P 连接。
relay_all_peer_rpc = true
# 对每个网络进行限速,单位bps
foreign_relay_bps_limit = 100000000000
# 关闭 KCP 输入
disable_kcp_input = true
# 关闭 QUIC 输入
disable_quic_input = true
# 是否中继 KCP 流量,共享节点时不开
disable_relay_kcp = true
# 是否中继 KCP 流量,共享节点时不开
enable_relay_foreign_network_kcp = false
同时修改启动命令中对应的配置文件中的自定义内容 custom-shard-center.toml
同样复制到/etc/systemd/system/
sudo systemctl start easytier-share-center.service
如需开机启动
sudo systemctl enable easytier-share-center.service
步骤三:在需要组网的服务器或PC, 以web管理的方式启动
linux启动
修改 easytier-node.service 对应的变量内容
[Unit]
Description=EasyTier Service
After=network.target syslog.target
Wants=network.target
[Service]
Type=simple
ExecStart=${path}/easytier-linux-x86_64/easytier-core \
--config-server udp://${mydomain}:${port1}/你web网页注册的用户名 \
--hostname aliyunserver
[Install]
WantedBy=multi-user.target
以本说明来说
ExecStart=${path}/easytier-linux-x86_64/easytier-core –config-server udp://easytier.mydomain.com:22222/abcdefg –hostname ${给你的组网节点起一个名字}
复制到/etc/systemd/system/
sudo systemctl start easytier-node.service
sudo systemctl enable easytier-node.service
windows启动
windows的部署方式我没有使用官方推荐的nssm,这个可以自己调, 我用的是winsw
下载easytier 的windows 发行包
其他使用 相关说明移步 https://github.com/winsw/winsw
拷贝 easytierNode.exe 和 easytierNode.xml 和easytier的可执行文件放在同一个目录
修改 easytierNode.xml 中的相关内容
<service>
<!-- ID of the service. It should be unique across the Windows system-->
<id>easytierNode</id>
<!-- Display name of the service -->
<name>easytierNode</name>
<!-- Service description -->
<description>easytier节点启动文件</description>
<!-- Path to the executable, which should be started -->
<executable>%BASE%\easytier-core.exe</executable>
<arguments> --config-server udp://easytier.mydomain.com:22222/abcdefg --hostname 当前组网的节点名称 </arguments>
</service>
例如
–config-server udp://easytier.mydomain.com:22222/abcdefg –hostname 当前组网的节点名称
在目录打开命令行,或命令行切换到easytier的可执行文件目录执行命令
easytierNode.exe install
easytierNode.exe start(也可以在系统服务中找到easytierNode 进行手动启动)
web页面配置
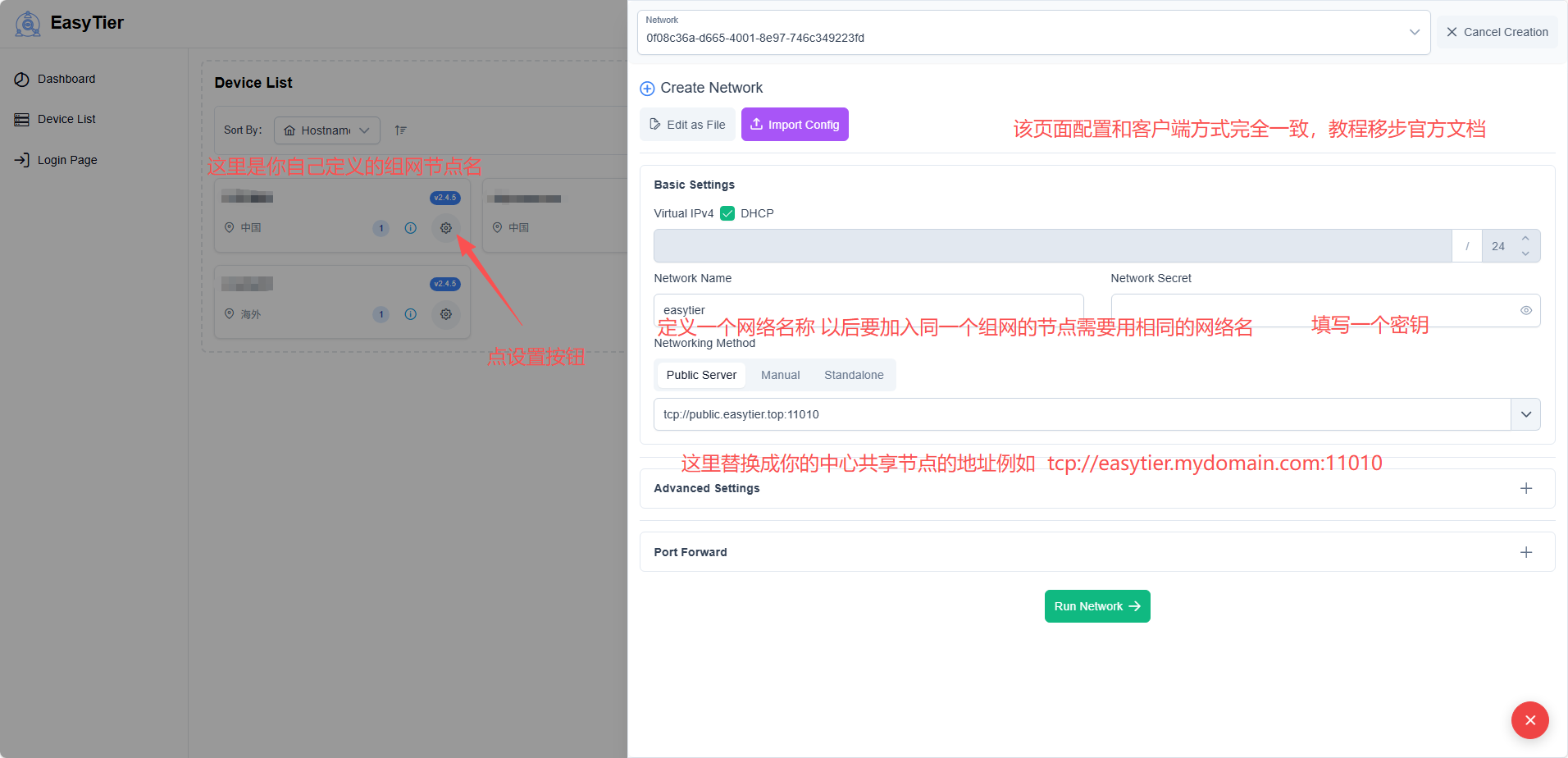
NetworkName 字段说明
此处需要的内容和共享节点配置
也就是启动共享节点时 custom-shard-center.toml 文件中以下部分的配置
[network_identity] network_name = “改成你的内容” network_secret = “改成你的内容”
这里的内容需要一致包括网络名称和密钥,能不能随便写可以自己试试, 我用的是一样的
11 - firebase
Firebase 是 Google 提供的移动和 Web 应用开发平台,旨在支持开发者从应用原型设计到部署运行的全生命周期。
Firebase Hosting 可为您的 Web 应用提供快速、安全的托管服务。
本站托管在Firebase Hosting , 在此感谢Firebase Hosting的服务
Firebase Hosting 是面向开发者的生产级 Web 内容托管服务。您只需运行一个命令,便可轻松快捷地将 Web 应用部署到全球级 CDN(内容分发网络)中。
Firebase: https://firebase.google.com/?hl=zh-cn
Firebase Hosting 文档: https://firebase.google.com/docs/hosting?hl=zh-cn
12 - Git
12.1 - 常见报错处理
server certificate verification failed. CAfile: none CRLfile: none
git config –global http.sslverify false
CRLF will be replaced by LF the next time Git touches it
git config –global core.autocrlf true git config –add core.filemode false
13 - Gitlab
13.1 - 安装
这里只提供docker的安装方式
13.2 - 关于如何定义一个流水线
在项目的根目录 定义文件 .gitlab-ci.yml
关于如何定义一个GitlabRunner
-
新建一个文件 .gitlab-ci.yml
-
runner的类型 这里只介绍shell类型和 docker类型
-
shell类型后续补充
-
docker类型
image: docker:latest services: - docker:dind // 这里定义了流水线的步骤, 理论上是可以随便写的, 他只要能和后面对应起来就行 // 这里定义的顺序决定了cicd的执行步骤 stages: - build - deploy build-job1://这个标签随便写 stage: build //这里和stages里面定义的要能对应起来 tags: - groupgorunner //此处是定义了执行器的tag - 其他具有相同指令的执行器。同理, 不同的执行器是具有多线程执行的 script: - docker build -t 192.168.77.22:10580/test/myapp:1.0.0 - 每一个元素都是一条命令 // 两个具有相同stage 内容的job 是多线程执行的, 当所有现成都执行完, 才会向下执行 build-job2://这个标签随便写 stage: build //这里和stages里面定义的要能对应起来 tags: - 其他执行器//此处是定义了执行器的tag script: - 其他命令 - deploy-job: //这个随便写 stage: deploy // 这里和stages里面定义的要能对应起来 -
所有的变量
CI_PROJECT_ID:项目的ID。
CI_PROJECT_NAME:项目的名称。
CI_PROJECT_NAMESPACE:项目的命名空间。
CI_COMMIT_REF_NAME:分支或标签的名称。
CI_COMMIT_SHA:提交的SHA。
CI_COMMIT_BEFORE_SHA:前一次提交的SHA。
CI_COMMIT_TAG:如果当前提交是标签,则为标签名。
CI_JOB_ID:作业的ID。
CI_JOB_NAME:作业的名称。
CI_JOB_STAGE:作业所处的阶段(例如 build, test)。
CI_JOB_URL:作业的URL。
CI_PIPELINE_ID:流水线的ID。
CI_SERVER_URL:GitLab服务器的URL。
CI_SERVER_HOST:GitLab服务器的主机名。
CI_SERVER_PROTOCOL:GitLab服务器的协议(http或https)。
CI_SERVER_PORT:GitLab服务器的端口。
CI_SERVER_VERSION:GitLab服务器的版本。
CI_REGISTRY:Docker Registry的URL。
CI_REGISTRY_USER:用于登录Docker Registry的用户名。
CI_REGISTRY_PASSWORD:用于登录Docker Registry的密码。
14 - infinityfree
文件快传 - P2P文件传输工具
传送门: https://github.com/MatrixSeven/file-transfer-go
InfinityFree 是什么?
1. 简介
InfinityFree 是一家提供永久免费虚拟主机服务的供应商。它实际上是 iFastNet 的免费分销商。与其他免费主机不同,InfinityFree 最大的卖点是:它不会在你的网站访客端强制投放广告。
2. 核心参数(官方宣称)
-
• 价格: $0.00 (永久免费)
-
• 存储空间: 5 GB (以前宣称无限,现已明确限制,但对小站足够)
-
• 带宽: 无限 (Unlimited Bandwidth)
-
• 域名: 提供免费二级域名(如
yoursite.rf.gd),也支持绑定顶级域名 -
• 数据库: 400 MySQL Databases
-
• 面板: 类似于 cPanel 的 VistaPanel
-
• 脚本安装: 内置 Softaculous,可一键安装 WordPress、Joomla 等 400+ 种程序
InfinityFree 建站保姆级教程
步骤一:注册账户
-
1. 访问官网:https://www.infinityfree.com
-
2. 点击 “Register” 或 “Sign Up Now”。
-
3. 输入你的邮箱地址、设置密码,勾选同意条款。
-
4. 关键步骤: 系统会发送一封验证邮件到你的邮箱,点击邮件中的验证链接激活账户。
步骤二:创建主机账户 (Hosting Account)
注册好“用户中心”后,你需要创建一个具体的“主机账户”(你可以拥有最多 3 个免费主机账户)。
-
1. 在后台点击 “Create Account” 按钮。
-
2. 选择域名:
-
• Subdomain (推荐新手): 在左侧输入你想要的前缀(如
myblog),在右侧下拉菜单选择后缀(如rf.gd,infinityfree.me等)。 -
• Custom Domain (自定义域名): 如果你已经购买了
.com域名,选这个。注意:你需要先去你的域名注册商那里,将 Nameservers (NS) 修改为ns1.epizy.com和ns2.epizy.com才能验证成功。
-
3. 点击 “Check Availability”(检查域名是否可用)。
-
4. 账户标签 (Account Label): 随便填,方便自己记。
-
5. 用户名/密码: 让系统自动生成即可。
-
6. 点击 “Create Account” 完成。
步骤三:进入控制面板 (Control Panel)
-
1. 创建成功后,点击 “Control Panel” 按钮。
-
2. 重要提示: 第一次进入面板时,会跳转到一个页面询问是否允许发送邮件通知(I approve…)。点击 “I Approve” 绿灯按钮即可进入 VistaPanel。
{kind=link}
步骤四:安装 WordPress (最常用的建站方式)
如果你不懂代码,只想快速建一个博客或网站,使用 Softaculous 自动安装是最快的方法。
-
1. 在 Control Panel 中向下滚动,找到 “Software” 版块。
-
2. 点击 “Softaculous App Installer”。
-
3. 鼠标悬停在 WordPress 图标上,点击 “Install”。
-
4. 填写安装信息:
-
• Choose Protocol: 建议选
http://(后期申请 SSL 后再改 https) 或直接选https://(如果你打算立刻搞定 SSL)。 -
• Choose Domain: 选择你刚才创建的域名。
-
• **In Directory:**留空! (不要填 wp,除非你想通过 yoursite.com/wp 访问)。
-
• Admin Account: 设置你的网站后台登录账号和密码(务必记下来)。
-
• Language: 选择 Chinese (Simplified)。
-
5. 向下滑到底部,点击 “Install”。
-
6. 等待进度条走完,你就可以通过
http://你的域名/wp-admin登录网站后台了。
{kind=link}
步骤五:上传文件 (进阶 - 使用 FTP)
如果你是自己写的 HTML/PHP 代码,或者需要修改系统文件,你需要使用 FTP。
-
1. 回到 InfinityFree 的 Hosting Accounts (托管帐户),点击你的账户。
-
2. 在详情页你会看到 FTP Details:
-
• FTP Host: (通常是 ftpupload.net)
-
• FTP User: (你的用户名,如 if0_12345678)
-
• FTP Password: (点击 Show/Hide 查看)
-
3. 下载并安装 FileZilla 客户端。
-
4. 将上述信息填入 FileZilla 并连接。
-
5. 核心注意: 所有网页文件必须上传到
htdocs文件夹内!上传到根目录是无法访问的。
-
• 删除
htdocs里默认的index2.html或default.php。 -
• 上传你自己的
index.html或index.php。
步骤六:配置免费 SSL (让网站变成 HTTPS)
InfinityFree 提供了一个很好用的免费 SSL 工具。
-
1. 在用户中心顶部菜单,点击 “SSL Certificates”。
-
2. 点击 “New SSL Certificate”。
-
3. 输入你的域名,点击 “Create Order”。
-
4. 验证域名: 系统会让你添加 CNAME 记录。如果是用 InfinityFree 的域名,通常点击 “Setup CNAME Records Automatically” 按钮即可(等待 10-60 分钟生效)。
-
5. 生效后,点击 “Request Certificate”。
-
6. 证书生成后,你需要手动安装(或者再次点击自动安装按钮,如果可用)。
- • 手动方法: 复制生成的
Private Key和Certificate代码,去 VistaPanel -> “SSL/TLS” -> 粘贴进去并保存。
14.1 - InfinityFree白嫖攻略
15 - MyBatis
关于操作系统模块的一些介绍
15.1 - mybatisSql语句拼装
16 - MySQL
关于操作系统模块的一些介绍
16.1 -
MySQL5.6.17编译安装
现在MySQL已经是8.x了, 这么老的版本应该不会再有人编译安装了。 再说单机版这个时代的背景下还是docker启动吧。 本文仅用于个人纪念
-
yum install -y gcc*
-
安装cmake
# mysql5.5之后需要cmake编译安装,因此,先下载cmake2.8.8
tar -zxvf cmake-2.8.8.tar.gz -C /usr/local/src
./configure --prefix=/usr/local/cmake
make
make install
- 安装mysql5.6.17
tar -zxvf mysql-5.6.17.tar.gz -C /usr/local/src
cmake \
#安装路径
-DCMAKE_INSTALL_PREFIX=/usr/local/mysql \
#数据文件存放位置
-DMYSQL_DATADIR=/usr/local/mysql/data \
#my.cnf路径
-DSYSCONFDIR=/etc \
#支持MyIASM引擎
-DWITH_MYISAM_STORAGE_ENGINE=1 \
#支持InnoDB引擎
-DWITH_INNOBASE_STORAGE_ENGINE=1 \
#支持Memory引擎
-DWITH_MEMORY_STORAGE_ENGINE=1 \
#快捷键功能(我没用过)
-DWITH_READLINE=1 \
#连接数据库socket路径
-DMYSQL_UNIX_ADDR=/tmp/mysqld.sock \
#端口
-DMYSQL_TCP_PORT=3306 \
#允许从本地导入数据
-DENABLED_LOCAL_INFILE=1 \
#安装支持数据库分区
-DWITH_PARTITION_STORAGE_ENGINE=1 \
#安装所有的字符集
-DEXTRA_CHARSETS=all \
#默认字符
-DDEFAULT_CHARSET=utf8 \
-DDEFAULT_COLLATION=utf8_general_ci
make
make install
- :配置MySQL
# 使用下面的命令查看是否有mysql用户及用户组
cat /etc/passwd 查看用户列表
cat /etc/group 查看用户组列表
#如果没有就创建
groupadd mysql
useradd -g mysql mysql
#修改/usr/local/mysql权限
chown -R mysql:mysql /usr/local/mysql
#修改/usr/local/mysql权限
#初始化配置
#进入安装路径,执行初始化配置脚本,创建系统自带的数据库和表
cd /usr/local/mysql
scripts/mysql_install_db --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data --user=mysql
注:在启动MySQL服务时,会按照一定次序搜索my.cnf,先在/etc目录下找,找不到则会搜索"$basedir/my.cnf",在本例中就是 /usr/local/mysql/my.cnf,这是新版MySQL的配置文件的默认位置!注意:在CentOS 6.4版操作系统的最小安装完成后,在/etc目录下会存在一个my.cnf,需要将此文件更名为其他的名字,如:/etc/my.cnf.bak,否则,该文件会干扰源码安装的MySQL的正确配置,造成无法启动。 启动MySQL
- 添加服务,拷贝服务脚本到init.d目录,并设置开机启动
cp support-files/mysql.server /etc/init.d/mysql
chkconfig mysql on
service mysql start --启动MySQL
- 配置环境变量
echo "export PATH=/usr/local/mysql/bin:$PATH" >> /etc/profile
# 使当前终端配置生效
source /etc/profile
- 配置用户
# 设置root密码
$ mysql -uroot
mysql> SET PASSWORD = PASSWORD('123456');
# root用户可以远程访问
# password为远程访问时,root用户的密码,可以和本地不同。
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'172.16.%' IDENTIFIED BY 'password' WITH GRANT OPTION;
# 配置防火墙
# 打开/etc/sysconfig/iptables
# 在“-A INPUT –m state --state NEW –m tcp –p –dport 22 –j ACCEPT”,下添加:
-A INPUT m state --state NEW m tcp p dport 3306 j ACCEPT
service iptables restart
16.2 -
MySQL5.6和5.7的二进制安装
5.6和5.7有略微的不同在 5步和7步请注意
- 获得二进制文件
# 5.6
wget http://mirrors.sohu.com/mysql/MySQL-5.6/mysql-5.6.28-linux-glibc2.5-x86_64.tar.gz
#
wget http://mirrors.sohu.com/mysql/MySQL-5.7/mysql-5.7.10-linux-glibc2.5-x86_64.tar.gz
- 加压到 /usr/local/mysql 目录(或者解压到当前目录然后做软链接到/usr/local/mysql)
mkdir /usr/local/mysql
tar -xvf mysql-5.6.28-linux-glibc2.5-x86_64.tar.gz
mv mysql-5.6.28-linux-glibc2.5-x86_64/* /usr/local/mysql/
mkdir /usr/local/mysql
tar -xvf mysql-5.7.10-linux-glibc2.5-x86_64.tar.gz
mv mysql-5.7.10-linux-glibc2.5-x86_64/* /usr/local/mysql/
- 创建 /usr/local/mysql/data 目录
# 5.6.28版本不需要
mkdir /usr/local/mysql/data
- 创建mysql用户和修改软件的权限
groupadd mysql
useradd -r -g mysql mysql -s /sbin/nologin (创建mysql用户并设置不可登录)
chown -R mysql.mysql /usr/local/mysql/
- 初始化数据(切换当前目录到/usr/local/mysql,在5.7中是bin目录下的mysql_install_db)
# 5.6
./scripts/mysql_install_db --user=mysql --basedir=/usr/local/mysql/ --datadir=/usr/local/mysql/data/
....此处省略一万字
# 5.7
bin/mysql_install_db --user=mysql --basedir=/usr/local/mysql/ --datadir=/usr/local/mysql/data/
2016-01-20 02:47:35 [WARNING] mysql_install_db is deprecated. Please consider switching to mysqld --initialize
2016-01-20 02:47:45 [WARNING] The bootstrap log isn't empty:
2016-01-20 02:47:45 [WARNING] 2016-01-19T18:47:36.732678Z 0 [Warning] --bootstrap is deprecated. Please consider using --initialize instead
2016-01-19T18:47:36.750527Z 0 [Warning] Changed limits: max_open_files: 1024 (requested 5000)
2016-01-19T18:47:36.750560Z 0 [Warning] Changed limits: table_open_cache: 431 (requested 2000)
- 复制配置文件到 /etc/my.cnf
cp -a ./support-files/my-default.cnf /etc/my.cnf (如果问是否替换选择Y)
- mysql的服务脚本放到系统服务中
# 5.6
cp -a ./support-files/mysql.server /etc/init.d/mysqld
service mysqld start
./bin/mysql -uroot -p(空密码)
# 5.7 版本开始系统会默认初始化一个root密码
cp -a ./support-files/mysql.server /etc/init.d/mysqld
service mysqld start
cat /root/.mysql_secret
# Password set for user 'root@localhost' at 2016-01-20 03:22:59
Tl:iRfEhRlQ6
bin/mysql -uroot -p(输入Tl:iRfEhRlQ6)
[root@c12 mysql57]# ./bin/mysqladmin -u root -p password
Enter password:
New password:
Confirm new password:
Warning: Since password will be sent to server in plain text, use ssl connection to ensure password safety.
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.8-rc |
+-----------+
1 row in set (0.00 sec)
16.3 - MySQL通用
MySQL基础
字段名称,数据类型,类型修饰(限制)
字符
CHAR(n)
VARCHAR(n)
BINARY(n)
VARBINARY(n)
TEXT(n)
BLOB(n)
数值
精确数值
整型
TINYINT
SMALLINT
MEDIUMINT
INT
BIGINT
修饰符:UNSIGNED,无符号
NOT NULL
十进制
DECIMAL
近似数值
浮点型
FLOAT
DOUBLE
日期时间
DATE
TIME
DATETIME
STAMP
布尔
内置:ENUM, SET
字段约束:限制
primary key 主键约束
foreign key 外键约束
not null 非空约束
null 空约束
check 检查约束
unique 唯一约束
default 默认值约束
auto_increment 自增长约束
drop、delete区别:
drop:删除库、删除表、删除字段
delete:
alter、update区别:
alter:修改表
update:修改记录
存储引擎(表的类型)
存储引擎分类
1、ISAM:查询速度快、支持全文索引、
不支持事务、不支持外键、不支持check约束
2、MyISAM:ISAM升级版
3、HEAP:速度快、数据驻留在内存
数据管理不稳定、计算机断电后所有数据全部丢失
4、InnoDB:速度较慢、支持事务、支持check约束、支持外键
不支持全文索引
常用的存储引擎:InnoDB、MyISAM
网站必须使用全文索引:MyISAM(大型网站)
不用非得使用全文索引:InnoDB(中小型网站)
数据库优化:修改数据库、表提高数据库运行效率
1、选择最合适的字段类型
char、varchar区别
字段的数据类型能用数字,就不用字符串
2、尽可能不使用子查询
1)用内连接代替子查询
2)子查询充当字段、delete语句出现子查询。只能用子查询
3、like查询尽可能用右侧%
1) like 'a%'
4、事务、保持数据的完整
1)避免数据库中出现大量的垃圾数据
5、尽可能的使用InnoDB引擎
1)事务:保持数据的完整性
2)外键:在业务层保证外键
6、给字段适当的添加索引
1)提高表的查询速度
7、每个表最好都有主键、而且主键还是数字类型
1)主键本身就是一个主键索引
8、避免数据库中出现NULL值
1)数据库对NULL值做了特殊处理
9、尽可能让相同类型的字段做比较
1)避免出现数据类型的转换
10、数据库设计是否合理
11、拆分表
12、主从数据库
13、负载均衡
14、服务器的硬件对数据库的影响
基础配置my.ini配置文件(/etc/my.cnf)
1、设置mysql端口号
port=3306
2、设置mysql编码
default-character-set=utf8
3、设置mysql的存储引擎
default-storage-engine=INNODB
4、设置mysql最大连接数
max_connections=100
5、设置数据库默认的存储引擎
default-storage-engine=MyISAM
控制台基础命令
# 登录 (在shell中执行)
mysql -h 主机地址 -u 用户名 -p密码
# 显示当前mysql版本和当前日期
select version(),current_date;
# 导出数据 (在shell中执行)
mysqldump -u 用户名 -p 数据库名 > FILE.sql
mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名
导出一个数据库结构
mysqldump -u wcnc -p -d -add-drop-table smgp_apps_wcnc >d:wcnc_db.sql
-d 没有数据 -add-drop-table 在每个create语句之前增加一个drop table
导出多个数据库
[root@localhost ~]# mysqldump -uroot -p -P3306 --databases course test > course.sql
导出所有数据库
[root@localhost ~]# mysqldump -uroot -p -P3306 --all-databases > all.sql
仅导出course数据库的数据,不包括表结构
[root@localhost ~]# mysqldump -uroot -p -P3306 --no-create-info course > course.sql
仅导出course数据库中的students和students_myisam两个表
[root@localhost ~]# mysqldump -uroot -p -P3306 --no-create-info course students students_myisam > students.sql
仅导出course数据库的表结构
[root@localhost ~]# mysqldump -uroot -p -P3306 --no-data course > course.sql
导出course数据库中除了teacher和score两个表的其他表结构和数据
[root@localhost ~]# mysqldump -uroot -p -P3306 --ignore-table=course.teacher --ignore-table=course.score course > course.sql
导出course数据库的表和存储过程和触发器
[root@localhost ~]# mysqldump -uroot -p -P3306 --routines --triggers course > course.sql
导出course数据库中符合条件的数据
[root@localhost ~]# mysqldump -uroot -p -P3306 --where="sid in (1,2)" course students students_myisam > course.sql
在主库备份
[root@codis-178 ~]# mysqldump -uroot -p -P3306 --master-data=2 --single-transctions course > course.sql
(在备份开始之初,在所有表上加一个只读锁(flush table with read lock),当成功获取该锁并开始备份之后,此锁就会立即释放,后续dump过程不会影响其他的读写操作)
在从库备份
[root@codis-178 ~]# mysqldump -uroot -p -P3306 --dump-slave --single-transctions test > test.sql
# 导入数据 (在shell中执行)
mysqldump -uUSER -p DATABASE < FILE.sql
mysql -u username -p -D dbname < filename.sql
mysql>source wcnc_db.sql
# 显示所有库
show databases;
查看当前使用的数据库
mysql> select database();
# 使用库
use 库名;
# 查看当前库中所有表
show tables;
# 查看表结构
desc 表名;
describe tablename;
# 显示当前mysql数据库所有的编码信息
show variables like 'character%';
# 查看表的存储引擎
use information_schema;
select table_schema,table_name,engine from tables;
select table_schema,table_name,engine from tables
where table_name='表名';
show create table 表名;
# mysql 新设置用户或更改密码后需用`flush privileges;`刷新MySQL的系统权限相关表,否则会出现拒绝访问,还有一种方法,就是重新启动mysql服务器,来使新设置生效。
# 命令行交互模式的一些控制命令 尤其是用windows的命令行连接数据库时很有用。不过说实话现在谁还用命令行连数据库呢
# mysql客户端窗口的编码
character_set_client utf8
# 连接数据库的编码
character_set_connection utf8
# 数据库的编码
character_set_database utf8
# 数据库的文件是哪种类型
character_set_filesystem binary
# 结果集的编码
character_set_results utf8
# mysql服务编码
character_set_server utf8
# mysql系统编码
character_set_system utf8
# mysql编码文件存储位置
character_sets_dir C:\Program Files\MySQL\MySQL Server 5.0\sharets
# 设置客户端编码
set names gbk;
数据库操作
create database name; 创建数据库
drop database name 直接删除数据库,不提醒
mysqladmin drop databasename 删除数据库前,有提示。
表操作和字段操作
create table 表名
(
字段名 数据类型 约束,
字段名 数据类型 约束,
字段名 数据类型 约束
)engine=存储引擎名;
修改表结构
1、修改表名
alter table 原名 rename to 新名;
2、添加字段
alter table 表名 add column 字段名 数据类型 约束;
alter table 表名 add 字段名 数据类型 约束;//使用这个即可
3、删除字段
alter table 表名 drop column 字段名;
alter table 表名 drop 字段名;//用这个即可
4、修改字段
alter table 表名 change 原字段名 新字段名 数据类型 约束;
alter table 表名 change userName userName varchar(20) not null;
切换clumon 顺序到最前
ALTER TABLE INFO MODIFY STAT TINYINT(4) FIRST;
切换到某clumon 后面
ALTER TABLE 表名 MODIFY clumonname AFTER clumonname;
复制表
1、整表复制(表结构、数据)
create table 新表 select * from 原表;
create table bbsInfo2 select * from bbsInfo;
create table bbsInfo2 select bbsId,clickTimes,bbsTime from bbsInfo;
2、复制表结构(表结构)
create table 新表 like 原表;
create table bbsInfo2 like bbsInfo;
索引操作
索引index
作用:提升数据库查询语句的速度
适合添加索引的字段:经常充当where条件的字段
索引的分类
1、主键索引:字段必须是主键、一张表最多只能有一个主键索引
2、普通索引:对字段没限制
3、唯一索引:字段里不能出现重复值
4、全文索引:对字段也没限制(建议:添加到中文字段)
各种索引适合添加到什么样字段
主键索引:主键
唯一索引:该字段没有重复值
全文索引:中文字段
普通索引:任意字段
创建索引的语法格式
1、主键索引
建表的同时指定主键
2、普通索引
create index 索引名 on 表名(字段名);
3、唯一索引
建表的同时指定唯一约束
create unique index 索引名 on 表名(字段名);
4、全文索引
create fulltext index 索引名 on 表名(字段名);
删除索引
drop index 索引名 on 表名;
索引的例子
1、普通索引
create index bbs_index on bbsInfo(title);
drop index bbs_index on bbsInfo;
2、唯一索引
create unique index bbs_index on bbsInfo(title);
drop index bbs_index on bbsInfo;
3、全文索引
create fulltext index bbs_index on bbsInfo(title);
drop index bbs_index on bbsInfo;
全文索引的例子
create table helloInfo
(
helloId int auto_increment primary key,
title varchar(100) not null,
content text not null,
helloTime timestamp default current_timestamp
)engine=MyISAM;
create fulltext index hello_index on helloInfo(title);
create fulltext index hello_c_index on helloInfo(content);
drop index hello_c_index on helloInfo;
索引注意:
1、经常充当where条件的字段必须要添加索引
2、全文索引对表的类型的限制
3、什么样的字段适合添加什么类型的索引
4、提升表的查询语句的速度
5、索引不是由用户来调用,而是执行查询时,自动提升查询速度
6、一个字段最多只能有一个索引
一张表可以有多个索引,但是索引不能同名
索引总结:
1、作用
2、分类
3、索引对字段的限制
4、什么样的字段适合添加什么样的索引
5、创建
6、删除索引
视图操作
创建视图语法格式
create view 视图名
as
select查询语句;
例子
create view myview
as
select claId,claName,schName from classInfo,schoolInfo;
create view bbsInfoView
as
select * from bbsInfo;
查看现存的所有视图
1、利用查看表的语句
show tables;
2、通过information_schema库--->views表 查看
select table_schema,table_name from views;
select table_schema,table_name from information_schema.views;
删除视图
1、删除库(视图所在的库)
drop database 库名;
2、删除视图
drop view 视图名;
修改视图
alter view 视图名
as
select语句;
例子
alter view myview
as
select claId,claName,schName from classInfo a,schoolInfo b
where a.schId=b.schId;
使用视图:把视图当表用
select * from 视图名;
例子
select * from myview;
select * from myview where claId=3;
select * from myview limit 0,2;
select * from myview order by claId;
使用视图的场合
1、一个多表查询语句在网站开发中使用的次数超3次
2、一个多表查询语句,添加分页功能
视图注意:
1、视图中只能存放select查询语句
2、把视图当表用
3、视图可以执行insert、update、delete操作
建议不要对视图执行insert、update、delete操作
视图总结:
1、视图作用
2、创建视图
3、查看视图
4、修改视图
5、使用视图
6、使用视图的场合
数据操作
增
添加记录
insert into 表名(字段,字段,字段...)values(值,值,值...);
insert into 表名 values(值,值,值...);//所有字段都要添加
复制数据到新表
1、假设两个表的表结构完全一样
insert into 新表 select * from 原表;
insert into bbsInfo2 select * from bbsInfo;
2、假设两个表的表结构不一样
insert into 新表(字段,字段...) select 字段,字段... from 原表;
insert into bbsInfo2 select bbsId,clickTimes,bbsTime from bbsInfo;
删
delete from 表名 where 条件;
# delete: 慢 可恢复 支持事务 不恢复id
# truncate: 快 不可恢复 不支持事务 恢复id
# 清空表
delete from 表名;//支持事务,进入日志文件
# 截段表
truncate table 表名;//不支持事务
改
update 表名 set 字段=值,字段=值... where 条件;
update 表名 set 字段=值,字段=值...;
查
运算符
逻辑运算符:and or not
比较运算符:< <= > >= = != <>
普通查询
select * from 表名;
select 字段,字段... from 表名;
//查询语句查询出来的结果:结果集、临时表
去掉重复值的查询
select distinct 字段,字段 from 表名;
条件查询
select * from 表名 where 条件;
select 字段... from 表名 where 条件;
排序
select * from 表名 order by 字段; #升序
select * from 表名 order by 字段 desc; #降序
select * from 表名 order by 字段,字段;
select * from 表名 order by 字段 desc,字段 desc;
select * from 表名 where 条件 order by 字段;
聚合函数(聚合查询):统计查询
聚集函数 意义
SUM ( ) 求和
AVG ( ) 平均值
COUNT ( ) 表达式中记录的数目
COUNT (* ) 计算记录的数目
MAX 最大值
MIN 最小值
VAR 方差
STDEV 标准误差
FIRST 第一个值
LAST 最后一个值
个数统计
select count(*) from 表名;
select count(字段) from 表名;
总和统计
select sum(字段) from 表名;
平均数统计
select avg(字段) from 表名;
最大值统计
select max(字段) from 表名;
最小值统计
select min(字段) from 表名;
一个语句包含多个聚合函数
select sum(字段),max(字段) from 表名;
注意:除了count以外,所有的聚合函数中的字段必须为数字类型
给字段起别名
select 字段 as 别名 from 表名;
select 字段,字段 as 别名,字段 from 表名;
select 聚合函数(字段) as 别名 from 表名;
给表起别名
select * from 表 as 别名;
select * from 表 别名;
分组
1、查看某一字段有多少个不同的值
select 字段1 from 表名 group by 字段1;
select 聚合函数(字段1) from 表名 group by 字段2;
分页
select * from 表名 limit 起始值,条数;
select * from 表名 where 条件 order by 字段 limit 起始值,条数;
模糊查询(站内搜索)
%:任意长度的任意字符串
_:任意一个字符
使用 \_ 代表 _ (如果要查询的字符是下划线的话) 除了可以转移_ 还可以转义 \0 \' \" \b(退格) \n(换行) \r(回车) \t(tab) \\ \%
select * from 表名 where 字段 like '%_内容';
select * from 表名 where 字段 like '%_内容' and|or 条件;
select * from 表名 where 字段 like '%_内容' order by 字段;
select * from 表名 where 字段 like '%_内容' limit 起始值,条数;
select * from 表名 where userName like '张%';
select * from 表名 where userName like '张_';
select * from 表名 where userName like '%三%';
多表查询
1、内连接:将多张表的字段合为一张表
查询两张表
select * from 表1 inner join 表2 on 关联的字段相等;
查询多张表
select * from 表1 inner join 表2 on 关联的字段相等
inner join 表3 on 关联的字段相等
inner join 表4 on 关联的字段相等
内连接另一种使用方式
select * from 表1,表2,表3... where 关联的字段相等;//使用这个比较方便
2、外连接:将多张表的字段合为一张表
左外连接:左表为主、右表为副//以left|right outer join为分界线分左表右表
select * from 表1 left outer join 表2 on 关联的字段相等;
右外连接:右表为主、左表为副
select * from 表1 right outer join 表2 on 关联的字段相等;
3、子查询(嵌套查询):在一个sql语句中包含另一个查询语句
在查询语句的条件中出现了另一个查询语句
select * from 表1
where 字段 in (select 字段 from 表2 where 条件);
在删除语句的条件中出现了另一个查询语句
delete from 表1
where 字段 in (select 字段 from 表2 where 条件);
在修改语句的条件中出现了另一个查询语句
update 表1 set 字段=值,字段=值...
where 字段 in (select 字段 from 表2 where 条件);
在查询语句的*位置出现了另一个查询语句
select 字段,字段,(select 字段 from 表2 where 条件) as 别名 from 表1;
4、联合查询union:将多张表的记录合为一张表//短期内用不到大型网站使用
将多张表的记录合为一张表,去掉了重复记录
select * from 表1 union select * from 表2;
将多张表的记录合为一张表,不去掉重复记录
select * from 表1 union all select * from 表2;
例:在'WA'地区的雇员表中按头衔分组后,找出具有同等头衔的雇员数目大于1人 group by Title having Count(Title)>1
的所有头衔。
Select Title ,Count(Title) as Total
FROM Employees
Where Region = 'WA'
GROUP BY Title
HAVING Count(Title)>1
//做例子要用
学院表
create table schoolInfo
(
schId int auto_increment primary key,
schName varchar(100) not null
);
insert into schoolInfo(schName)values('理工学院');
insert into schoolInfo(schName)values('自动化学院');
insert into schoolInfo(schName)values('网络学院');
#班级表
create table classInfo
(
claId int auto_increment primary key,
schId int,
claName varchar(100) not null,
foreign key (schId) references schoolInfo(schId)
);
insert into classInfo(schId,claName)values(1,'php1401');
insert into classInfo(schId,claName)values(3,'php1402');
insert into classInfo(schId,claName)values(2,'php1403');
insert into classInfo(schId,claName)values(3,'php1404');
#学生表
create table student
(
stuId int auto_increment primary key,
claId int,
stuName varchar(20) not null,
foreign key (claId) references classInfo(claId)
);
insert into student(claId,stuName)values(1,'张三');
insert into student(claId,stuName)values(2,'李四');
insert into student(claId,stuName)values(3,'王五');
insert into student(claId,stuName)values(4,'赵六');
insert into student(claId,stuName)values(3,'田七');
insert into student(claId,stuName)values(3,'张大三');
insert into student(claId,stuName)values(2,'李小五');
触发器Trigger:数据库中的事件
触发器Trigger:数据库里的事件
作用:当用户对表进行insert、update、delete同时,是否要执行其他的操作
触发器的调用:
当用户对表进行insert、update、delete操作时,由系统自动调用
触发器的类型:insert、update、delete
触发器执行的时间:before、after
创建触发器
delimiter // #修改mysql定界符
drop trigger if exists 触发器名// #如果该触发器己经存,删除
create trigger 触发器名
before|after insert|update|delete
on 表名
for each row
begin
sql语句; #注意:begin和end之间,不能出现无意义的查询语句
sql语句;
sql语句;
end //
delimiter ;//将mysql定界符改回系统默认
删除触发器
1、删除触发器所在的库
drop database 库名;
2、删除触发器所在的表
drop table 表名;
3、删除触发器
drop trigger 触发器名;
触发器注意:
1、触发器是由系统自动调用
2、触发器中不能出现无意义的查询语句
3、触发器没有参数
触发器总结
1、触发器作用
2、触发器的执行时间
3、触发器的类型
4、一张表最多能添加三个触发器
5、创建
6、删除
7、查看现存的所有触发器
查看现存的所有触发器
information_schema库--->triggers表
trigger_schema:库名
trigger_name:触发器名
EVENT_MANIPULATION:触发器类型
event_object_table:表名
select trigger_schema,trigger_name,EVENT_MANIPULATION,event_object_table from triggers;
select trigger_schema,trigger_name,EVENT_MANIPULATION,event_object_table from information_schema.triggers;
触发器例子
create table userInfo
(
userName varchar(20) primary key,
password varchar(20) not null,
sex char(3) check(sex='男' or sex='女')
);
create table newsInfo
(
newsId int auto_increment primary key,
title varchar(100) not null,
newsTime timestamp default current_timestamp
);
#统计信息表
create table msgInfo
(
userCount int default 0,
newsCount int default 0
);
insert into msgInfo values(0,0);
#给userInfo表添加一个insert触发器
delimiter //
drop trigger if exists addUserTrigger//
create trigger addUserTrigger
after insert
on userInfo
for each row
begin
#将msgInfo表的userCount字段值加一
update msgInfo set userCount=userCount+1;
end //
delimiter ;
#给userInfo添加一个delete触发器
delimiter //
drop trigger if exists delUserTrigger//
create trigger delUserTrigger
after delete
on userInfo
for each row
begin
update msgInfo set userCount=userCount-1;
end //
delimiter ;
insert into userInfo values('张三','123456','男');
insert into userInfo values('李四','123456','女');
delete from userInfo where userName='张三';
触发器注意:
1、触发器依赖于表
2、触发器类型:insert、update、delete
3、在触发器中不能出现无意义的查询语句
4、一个触发器只能监听一个表的一个操作
5、触发器由系统自动调用
6、触发器不能传参
触发器总结:
1、触发器作用、原理
2、触发器类型
3、触发器的执行时间
4、创建触发器
5、删除触发器
6、查看现存的所有触发器
7、触发器使用场合
存储过程Procedure:数据库中的自定义函数
创建存储过程
delimiter //
drop procedure if exists 存储过程名//
create procedure 存储过程名()
begin
sql语句;
sql语句;
sql语句;
end //
delimiter ;
删除存储过程
1、删除库
drop database 存储过程所在的库名;
2、删除存储过程
drop procedure 存储过程名;
查看现存的所有存储过程
mysql库--->proc表
select db,name from proc;
select db,name from mysql.proc;
调用存储过程
call 存储过程名();
call 存储过程名(值,值,值...);
call 存储过程名(值,值,@变量名,@变量名,@变量名);
select @变量名,@变量名...;
使用存储过程的场合: 操纵数据库时要执行多个sql语句
存储过程注意:
1、一次编写多次调用
2、参数:输入参数、输出参数
3、调用存储过程
存储过程总结:
1、作用
2、创建
3、删除
4、调用
5、参数
类拟于数据库中的输出语句
select '你好' as msg;
select 30 as age;
select current_timestamp as time;
例子:
delimiter //
drop procedure if exists hello//
create procedure hello()
begin
select current_timestamp as time;
end //
delimiter ;
call hello();
触发器(Trigger)与存储过程(Procedure)的区别
不同点 1、触发器由系统自动调用,存储过程必须由用户通过call来调用 2、触发器没有参数、存储过程可以有参数(输入、输出) 3、触发器依赖表、存储过程依赖于库 相同点 1、一次编写多次调用 2、都可以实现T-SQL编程
事务Transaction
事务特性:原子性、一致性、隔离性、持久性
开启一个事务
start transaction;
结束一个事务
commit;#事务成功
rollback;#事务失败
事务的最终状态:成功commit、失败rollback
回滚点
1、设置回滚点(你己经开启了事务)
savepoint 名;
2、回滚至某一个回滚点
rollback to 回滚点名;
注意:rollback to 仅仅只回滚到某一个回滚点,但并不会结束事务
例子:
start transaction;
delete from bbsInfo;
rollback;
select * from bbsInfo;
例子
start transaction;
delete from bbsInfo;
savepoint hello;
delete from userInfo;
rollback to hello;
select * from bbsInfo;#没有记录
select * from userInfo;#有记录
commit;或rollback;
事务的使用场合
1、调试客户的服务器上的数据库
2、存储过程(存储过程中包含了多个insert、update、delete语句)
不支持事务的sql语句
truncate table、create、alter、drop
只有InnoDB的存储引擎支持事务
事务总结
1、事务作用:保证数据的完整性
2、开启事务
3、结束事务
4、回滚点
5、不支持事务的语句
6、事务特性
Transaction-SQL编程 (事务编程)
Transaction-SQL编程 (Transaction:事务)
sql编程只能出现在:trigger、procedure
1、定义变量
declare 变量名 数据类型;
declare 变量名 数据类型 default 值;
注意:declare必须出现在procedure、trigger的最顶端
delimiter //
drop procedure if exists hello//
create procedure hello()
begin
declare a int;
declare b int default 30;
declare sex char(3) default '男';
declare userName varchar(20) default '张三';
select b,sex,userName;
end //
delimiter ;
2、给变量赋值
declare 变量名 数据类型 default 值;
set 变量名 = 值;
set 变量名 = (select语句);
select 字段 into 变量名 from 表名 where 条件;
delimiter //
drop procedure if exists hello//
create procedure hello()
begin
declare a int;
declare b varchar(50);
select count(*) into a from bbsInfo;
select title into b from bbsInfo where bbsId=3;
select a,b;
end //
delimiter ;
delimiter //
drop procedure if exists hello//
create procedure hello()
begin
declare a int;
declare b varchar(100);
set a = (select count(*) from bbsInfo);
set b = (select title from bbsInfo where bbsId=3);
select a,b;
end //
delimiter ;
delimiter //
drop procedure if exists hello//
create procedure hello()
begin
declare age int;
declare userName varchar(20);
set age = 100;
set userName = '田七';
select age,userName;
end //
delimiter ;
3、运算符
算术运算符:+ - * / %
比较运算符:< <= > >= = != <>
逻辑运算符:and or not
delimiter //
drop procedure if exists hello//
create procedure hello()
begin
declare a int default 10;
declare b float default 3.14;
declare c float;
set c = a*b;
select c;
end //
delimiter ;
delimiter //
drop procedure if exists hello//
create procedure hello()
begin
declare a int default 10;
declare b float;
declare c float;
#设置变量必须在全部变量声明完成后才能赋值
set b = 3.14;
set c = a*b;
select c;
end //
delimiter ;
4、判断语句
if 条件 then
sql语句;
elseif 条件 then
sql语句;
else
sql语句;
end if;
delimiter //
drop procedure if exists hello//
create procedure hello()
begin
declare age int default 40;
if age=1 then
select '出场亮相';
elseif age=10 then
select '天天向上';
elseif age=20 then
select '远大理想';
elseif age=30 then
select '基本定向';
elseif age=40 then
select '处处吃香';
else
select '不知道';
end if;
end //
delimiter ;
5、循环语句
while 条件 do
sql语句;
end while;
repeat
sql语句;
until 条件 end repeat;
别名:loop
sql语句;
if 条件 then
leave 别名;
end if;
end loop;
delimiter //
drop procedure if exists hello//
create procedure hello()
begin
declare i int default 0;
hello:loop
select i;
set i=i+1;
if i>5 then
leave hello;
end if;
end loop;
end //
delimiter ;
delimiter //
drop procedure if exists hello//
create procedure hello()
begin
declare i int default 0;
repeat
select i;
set i=i+1;
until i>5 end repeat;
end //
delimiter ;
delimiter //
drop procedure if exists hello//
create procedure hello()
begin
declare i int default 0;
while i<5 do
set i=i+1;
select i;
end while;
end //
delimiter ;
T-SQL编程总结:
1、sql编程可以出现的地方:trigger、procedure
2、定义变量
3、给变量赋值
4、运算
5、判断
6、循环(了解)
事务+存储过程的例子
#删除新闻分类
delimiter //
drop procedure if exists delNewsType//
create procedure delNewsType(tid int)
begin
declare a int;#存储受影响的行数
start transaction;#开启一个事务
delete from reviews
where articleId in (select articleId from newsArticles where typeId=tid);
delete from newsArticles where typeId=tid;
delete from newsTypes where typeId=tid;
set a = row_count();#获得上一个语句的受影响的行数
if a>0 then
commit;
else
rollback;
end if;
end //
delimiter ;
delimiter //
drop procedure if exists delNewsType//
create procedure delNewsType(tid int)
begin
declare a int;#存储一个变量值
start transaction;#开启一个事务
delete from reviews
where articleId in (select articleId from newsArticles where typeId=tid);
delete from newsArticles where typeId=tid;
delete from newsTypes where typeId=tid;
select count(*) into a from newsTypes where typeId=tid;
if a=0 then
commit;
else
rollback;
end if;
end //
delimiter ;
#通过articleId获得新闻的标题及内容
delimiter //
drop procedure if exists getNews//
create procedure getNews(aid int,out t varchar(100),out c text)
begin
set t = (select title from newsArticles where articleId=aid);
set c = (select content from newsArticles where articleId=aid);
end //
delimiter ;
17 - VPN
17.1 - v2ray
相关站点:
博客1
wget https://raw.githubusercontent.com/v2fly/fhs-install-v2ray/master/install-release.sh sudo bash install-release.sh sudo vim /usr/local/etc/v2ray/config.json /usr/local/etc/v2ray/config.json 中inbounds.settings.clients.id /usr/local/etc/v2ray/config.json 中inbounds.streamSettings.wsSettings.path
{
"log": {
"access": "/var/log/v2ray/access.log",
"error": "/var/log/v2ray/error.log",
"loglevel": "warning"
},
"inbounds": [{
"port": 11055,
"protocol": "vmess",
"settings": {
"clients": [{
"id": "27848739-7e62-4138-9fd3-098a63964b6b",
"level": 1,
"alterId": 0
}
]
},
"streamSettings": {
"network": "ws",
"wsSettings": {
"path": "/tech"
}
}
}
],
"outbounds": [{
"protocol": "freedom"
}
]
}
# 编辑完此脚本后需要重启 v2ray
启动v2ray
sudo systemctl start v2ray sudo systemctl enable v2ray
停止v2ray
systemctl stop v2ray
重启v2ray
systemctl restart v2ray
卸载v2ray
systemctl stop v2ray rm -rf /etc/v2ray/
安装nginx
sudo apt install curl gnupg2 ca-certificates lsb-release ubuntu-keyring
curl https://nginx.org/keys/nginx_signing.key | gpg –dearmor
| sudo tee /usr/share/keyrings/nginx-archive-keyring.gpg >/dev/null
gpg –dry-run –quiet –no-keyring –import –import-options import-show /usr/share/keyrings/nginx-archive-keyring.gpg
echo “deb [signed-by=/usr/share/keyrings/nginx-archive-keyring.gpg]
http://nginx.org/packages/ubuntu lsb_release -cs nginx”
| sudo tee /etc/apt/sources.list.d/nginx.list
sudo apt update
sudo apt install nginx
配置一个域名例如 v2ray.debug.xxx.com.conf cd /etc/nginx/conf.d sudo cp defult.conf v2ray.debug.xxx.com.conf sudo vim v2ray.debug.xxx.com.conf
把 server_name 配置为 v2ray.debug.xxx.com; location / { root /data/html/v2raytry; # 这个路径(其他路径也可以)下新建index.html 写入内容例如
Hello World!
index index.html index.htm; }此时重启nginx,并访问v2ray.debug.xxx.com 浏览器访问会回显 Hello World!
安装certbot并申请ssl证书
sudo apt install certbot python3-certbot-nginx sudo certbot –nginx 具体执行参考 certbot–nginx命令执行.jpg
等一会证书会自动安装好, 并自动修改选定域名的nginx配置 v2ray.debug.xxx.com.conf v2ray.debug.xxx.com.conf 类似于这样 server{ server_name v1.v2ray.debug.xxx.com; index index.html; root /root/www/;
listen 443 ssl; # managed by Certbot
ssl_certificate /etc/letsencrypt/live/v1.xxxx.com/fullchain.pem; # managed by Certbot
ssl_certificate_key /etc/letsencrypt/live/v1.xxxx.com/privkey.pem; # managed by Certbot
include /etc/letsencrypt/options-ssl-nginx.conf; # managed by Certbot
ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; # managed by Certbot
} server{ if ($host = v2ray.debug.xxx.com) { return 301 https://$host$request_uri; } # managed by Certbot
listen 80;
server_name v1.xxxx.com;
return 404; # managed by Certbot
}
修改v2ray.debug.xxx.com.conf 并添加
添加这部分内容, 11055 对应/usr/local/etc/v2ray/config.json 里面inbounds端口
/tech客户端配置的时候需要,对应/usr/local/etc/v2ray/config.json streamSettings里的path
location /tech { proxy_redirect off; proxy_pass http://127.0.0.1:11055; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection “upgrade”; proxy_set_header Host $http_host; } 最终配置文件为 server { server_name v2ray.debug.xxx.com;
#access_log /var/log/nginx/host.access.log main;
location / {
root /data/html/v2raytry;
index index.html index.htm;
}
## 添加这部分内容,22055对应/usr/local/etc/v2ray/config.json 里面inbounds端口
## /tech客户端配置的时候需要,对应/usr/local/etc/v2ray/config.json streamSettings里的path
location /tech {
proxy_redirect off;
proxy_pass http://127.0.0.1:11055;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $http_host;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
listen 443 ssl; # managed by Certbot
ssl_certificate /etc/letsencrypt/live/v2ray.debug.xxx.com/fullchain.pem; # managed by Certbot
ssl_certificate_key /etc/letsencrypt/live/v2ray.debug.xxx.com/privkey.pem; # managed by Certbot
include /etc/letsencrypt/options-ssl-nginx.conf; # managed by Certbot
ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; # managed by Certbot
}
server { if ($host = v2ray.debug.xxx.com) { return 301 https://$host$request_uri; } # managed by Certbot
listen 80;
server_name v2ray.debug.xxx.com;
return 404; # managed by Certbot
}
配置好后重启nginx,并访问v2ray.debug.xxx.com 浏览器访问会回显 Hello World!但此时已经事https访问了
v2ray客户端配置, 这里以windows为例 在6.27,版本中, 新建一个订阅分组,这里新建订阅分组的目的是, 如果你有其他机场,那么建议每个机场都单独定义一个订阅分组,所以这里是我们自己搭建的机场, 就新建一个v2ray.debug的分组
订阅分组–》订阅分组设置–》添加–》 设置一个别名 v2ray.debug 后确定 回到主界面, 选择刚才新建的分组 v2ray.debug 点一下, 服务器–》添加[VMess]服务器
服务器:v2fly 别名: v2ray.debu 这个可以随便鞋 地址: v2ray.debug.xxx.com 用户ID: /usr/local/etc/v2ray/config.json 中inbounds.settings.clients.id 这里是 27848739-7e62-4138-9fd3-098a63964b6b 加密方式: 默认 auto 传输协议: 默认tcp, 这里改成ws 伪装类型: none 伪装域名: v2ray.debug.xxx.com 路径(path): /usr/local/etc/v2ray/config.json 中inbounds.streamSettings.wsSettings.path 这里是 /tech 传输层安全(TLS): 选择tls SNI: 留空 Fingerprint:留空 Alpn: 留空 跳过证书验证(allowInsecure):选择false
最后确定保存, 之后就可以试试访问google.com youtube.com
18 - zerotier
原地址: https://github.com/xubiaolin/docker-zerotier-planet
我的克隆地址:https://gitee.com/azhw/docker-zerotier-planet
19 - 通用数据库语言
DBMS: 数据管理独立性; 有效地完成数据存取; 数据完整性和安全性; 数据集中管理; 并发存储与故障恢复; 减少应用程序开发时间;
RDBMS:
- 数据库创建、删除除
- 创建表、删除表、修改表
- 索引的创建、删除
- 用户和权限
- 数据增、删、改
- 查询
DML:Data Manapulate Language: 数据操作语言 INSERT, REPLACE, UPDATE, DELETE DDL:Data Defination Lanuage: 数据定义语言 CREATE, ALTER, DROP DCL:Data Control Language: 数据控制语言 GRANT, REVOKE