关于操作系统模块的一些介绍
操作系统
- 1: Linux
- 1.1: Linux通用
- 1.1.1: apt包管理器
- 1.1.2: Linux基础
- 1.1.3: Linux知识体系
- 1.1.4: rpm包管理器
- 1.1.5: SAR命令
- 1.1.6: shell编程
- 1.1.7: ssh管理
- 1.1.8: Vim编辑器
- 1.1.9: 磁盘管理
- 1.1.10: 定时任务
- 1.1.11: 脚本和示例
- 1.1.12: 进程管理
- 1.1.13: 权限
- 1.1.14: 时间日期
- 1.1.15: 网络管理
- 1.1.16: 文本操作
- 1.1.17: 文件和目录
- 1.1.18: 压缩解压缩
- 1.1.19: 用户管理
- 1.2: Ubuntu
- 1.2.1: gdm3和lightdm切换
- 1.2.2: netplan
- 1.2.3: Ubuntu桌面版设置随机Mac地址
- 1.2.4: 报错处理
- 1.2.5: 替换清华源
- 1.3: 报错处理
- 2: Windows
1 - Linux
1.1 - Linux通用
1.1.1 - apt包管理器
dpkg
***************************************************
dpkg -l 查看当前系统中的已经安装软件包的信息 相当于:rpm -qa
dpkg -L 查询系统中已经安装的软件包的文件详细列表 相当于: rpm -ql
dpkg -s 查询已安装的指定软件包的详细信息 相当于: rpm -qi
dpkg -S 查询系统中的某个文件属于哪个软件包 rpm -qf
dpkg -i 安装deb软件包
卸载deb软件包
dpkg -r
dpkg -P 彻底的卸载 包括软件的配置文件等等
查看没有安装的deb包命令
dpkg -c 查询deb包文件中所包含的文件 rpm -qlp
dpkg -I 查询deb包的详细信息-
***************************************************
1.1.2 - Linux基础
Linux 启动
******************************************************************
1.bios找到磁盘上的mbr主引导扇区
2.进入grub界面选择相应的启动内核
3.读取kernel内核文件-/boot/vmlinuz-*
4.读取init的镜像文件-/boot/initrd-*
5.init去读取/etc/inittab
设置运行级别 0关机 3字符界面 5图形界面 6重启
6.读取启动级(id:3:initdefault)
7.读取/etc/rc.d/rc.sysinit,
读取系统主机名 识别加载硬件驱动
读取selinux防火墙 设置系统字体
进入一个简单的小欢迎页面 设置系统时钟
设置文件和目录权限 加载映射分区
8.读取/etc/rc.d/rc脚本,通过该脚本吸收3级别,然后启动/etc/rc.d/rc3.d下所有以S开头的服务,不启动该目录下以K开头的服务
9.进入登录界面
*****************************************************************
/***********************************************************************************
一.BIOS 加电自检
当你按电源开关开机时,电脑会首先去启动BIOS(基本输入输出系统),BIOS一般是集成在主板上的.
BIOS 的工作
1.检测连接硬件,比如显卡,内存,磁盘等等,检测的目的是以后把这些设备信息提供给操作系统
2.寻找启动磁盘,每一种BIOS都会有开机启动菜单,可以在菜单里设置以哪个设备启动系统
比如:光驱,硬盘,网络等等,这个菜单可以设置多个选项,依照设置次序在设备上寻找启动信息
3.找到了启动硬盘,接着BIOS就会在磁盘上寻找第一个启动扇区,也就是主引导记录MBR(Master Boot Record)
但是MBR中,存储操作系统的空间只有446字节;MBR总共是512字节(=stage1)(其中引导程序占446字节+分区表占64字节,每16个字节记录一个分区,标识符占2个字节,以55.aa结尾)
如果没有在MBR中找到操作系统的内核,那么BIOS就无法继续启动工作.
而我们的内核往往会大于446个字节,存放在磁盘的其他位置上,既然446装不下内核,又为了能顺利的找到放在其他位置上的内核,人们想出了一个办法就在446字节里写了一个小程序,当BIOS试着启动操作系统时就会执行这个小程序,然后再由小程序来载入位于其他位置的内核.这个小程序就是启动载入器(boot loader)
二.BOOT Loader
linux的boot loader(上文提到的小程序) 常见的有两种:lilo grub
因为lilo存在着一个1024柱面的限制,并且更改了磁盘上的启动信息文件后需要重新启动系统才能同步446字节的内容,因为lilo的缺陷,已经被grub所取代.现在的绝大多数类linux系统都采用grub做boot loader;
grub则没有了lilo各种限制,而且方便到能修改系统文件的启动内容就可以立刻与446内容同步.
那么我们就看看grub的内容 它存在于 /boot/grub中
GRUB有几个重要的文件,STAGE1、STAGE1.5、STAGE2
STAGE1:它只有512字节,通常放在MBR中,它的作用很简单,就是在系统启动时用于装载STAGE2并将控制权交给它。
STAGE2:GRUB的核心,所有的功能都是由它实现。
STAGE1.5:介于STAGE1和STAGE2之间,是它们的桥梁,因为STAGE2较大,通常都是放在一个文件系统当中的,但是STAGE1并不能识别文件系统格式,所以才需要STAGE1.5来引导位于某个文件系统当中的STAGE2。根据文件系统格式的不同,STAGE1.5也需要相应的文件,如:e2fs_stage1_5,fat_stage1_5,分别用于识别ext和fat的文件系统格式。它存放于1-63的柱面之间.
引导顺序如下:STAGE1->;STAGE1.5->;STAGE2,
主要的配置文件时 grub.conf
里面选项含义:
title:一个操作系统引动的标头,可以使多个
root :指明所需文件存在于哪个磁盘哪个分区上 (hd0,0)表示第一个硬盘,第一个分区
kernel:内核文件的名字,并且会有一些加载内核时的参数
initrd:包含一些附加的驱动程序
_____________________
#cat /boot/grub/grub.conf grub配置文件
default=0 默认启动项,选择启动条目第一个为0号
timeout=5 默认超时时间
splashimage=(hd0,0)/grub/splash.xpm.gz 登陆时默认图片
hiddenmenu 隐藏菜单
title CentOS (2.6.32-220.el6.x86_64) 启动菜单名字
root (hd0,0) hd0代表第一块硬盘,0代表第一个分区
kernel /vmlinuz-2.6.32-220.el6.x86_64 内核文件名
initrd /initramfs-2.6.32-220.el6.x86_64.img
三.内核启动
内核启动后会向bios查询电脑的所有硬件信息,然后自己接手下来管理这些设备,以便提供给linux使用
内核会试着驱动这些设备,这些设备的驱动一部分包含在内核中,叫做静态驱动,一部分以模块的方式(动态)存放文件系统中,由于此时还未挂载任何文件系统,因此还不能使用文件系统中的模块,这里只能驱动在内核中存在的硬件驱动程序的对应设备.想驱动内核中未包含的硬件驱动就需要加载文件系统.
四.启动INIT服务
顺利的挂载了根文件系统后,就会启动init服务,init内核启动的第一个用户级进程
内核会按 /sbin/init /etc/init /bin/init 顺序寻找init程序,
如果找不到则内核报错
启动init的目的就是为了初始化系统环境,启动了init就证明了内核已经顺利启动,接下来就由init服务来建立linux使用环境
init做了什么?它会读取 /etc/inittab 文件,根据这个文件的信息来进行初始化工作.
会执行三个脚本 /etc/rc.d/rc.sysinit /etc/rc.d/rc[0-6]/* /etc/rc.d/rc.local(万能配置文件,系统启动完毕后,最后运行此文件内的命令)
rc.sysinit 主要的功能用来建立系统的基本环境,比如:
启动udev selinux子系统
udev负责产生 /dev中的文件,selinux负责增强系统的安全性
设定核心参数 sysctl -p 加载 /etc/sysctl.conf
设定系统时间 将硬件时间设定为系统时间
加载键盘和交换分区 swapon -a -e
设置主机名,挂载文件系统,并将根重新挂载为可读写的.
加载动态驱动模块
USB设备与RAID & LVM
rc 脚本设置启动级别 linux中有许多不同的启动级别,不同的启动级别会制定不同的服务
根据指定rc的参数会对应执行 /etc/rc.d/rc[0-6].d/ 中的连接脚本文件 以S开头的则启动,K开头的不随机自启动
rc.local 前两个脚本都是系统至关重要的脚本,如果我们想在启动过程中放置一些其他程序
应该使用rc.local脚本中
三个RC脚本执行完毕后,就会建立虚拟主控制台 执行 /bin/login 就提供了用户登陆界面了
如果是图形 L5级别的话,会启动X window登录界面
所有的启动就都已经完毕
初始化/sbin/init
#vime/etc/inittab 初始化配置文件
# Default runlevel. The runlevels used by RHS are:
# 0 - halt (Do NOT set initdefault to this) 关机
# 1 - Single user mode 单用户模式
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking) 多用户模式,无网络模式,也就是不能远程登录
# 3 - Full multiuser mode 全部都用户模式
# 4 - unused 保留参数
# 5 - X11 图形界面模式
# 6 - reboot (Do NOT set initdefault to this) 重起模式
#
id:3:initdefault: 定义默认启动级别
#ls /etc/rc.d
init.d rc0.d rc2.d rc4.d rc6.d rc.sysinit(启动初始化)
rc rc1.d rc3.d rc5.d rc.local (rc0~6为运行级别脚本,启动或关闭的控制文件,S启动,K关闭,启动或关闭顺序S后面的数字越小、优先级越高)
五.登陆,加载用户环境变量
输入用户名和密码系统验证,然后会执行
/etc/profile
/etc/bashrc
$HOME/.bash_profile
$HOME/.bashrc
查看当前启动级别
# runlevel
N 5
N是上次的级别,5是当前级别 也就是说64机器开机就是5级别
************************************************************************************************/
运行级别
0表示关机,
1表示单用户,
2表示没有网络的命令行级别,
3命令行级别(大多服务器都用这个级别),
4为保留级别,
5为图形化级别,
6为重启。
1.1.3 - Linux知识体系
1.1.4 - rpm包管理器
软件安装命令
***************************************************
rpm(redhat package management)软件安装
1. 查看系统中安装的所有rpm包
rpm -qa
2. 查看rpm是否被安装
rpm -qa|grep httpd
3. 安装rpm包
rpm -ivh httpd-0.0.0.conetos.i386.rpm
4. 强制卸载rpm包
rpm -e httpd-0.0.0.conetos.i386.rpm --force --nodeps(nodeps可以截断rpm包的依赖性)
5.查看rpm安装了一些什么(主要为了查看依赖包)
rpm -qpl httpd-0.0.0.conetos.i386.rpm |more
6. yum查看已经安装的rpm包河yum源中的rpm包
yum list
7. yum 安装rpm包
yun -y install rpm包名称(或者httpd*)
8. yum卸载rpm包(会卸载依赖包)
yum -y remove httpd*
#谨慎使用,请使用 rpm -e
9. rpm安装软件的三个重要目录
1) 应用程序目录 /usr/sbin/httpd(应用程序名称)
2) 配置文件 /etc/应用程序名称的目录/.......
3) 服务脚本 /etc/init.d/应用程序名的文件
10. 只下载,并指定下载路径
yum reinstall vim-enhanced --downloadonly --downloaddir=/tmp/
11. yum设置源优先级
1) 安装 yum-priorities
yum install yum-priorities
2) priorities的配置文件是/etc/yum/pluginconf.d/priorities.conf,确认其是否存在。
其内容为:
[main]
enabled=1 # 0禁用 1启用
3)编辑 /etc/yum.repos.d/目录下的*.repo 文件来设置优先级。
参数为:
priority=N # N的值为1-99
推荐的设置为:
[base], [addons], [updates], [extras] … priority=1
[centosplus],[contrib] … priority=2
Third Party Repos such as rpmforge … priority=N (where N is > 10 and based on your preference)
数字越大,优先级越低
根据需要查看要安装的包
yum whatprovides libstdc++.so.6
***************************************************
配置yum默认为光盘
***************************************************
1. cd /etc/yum.repos.d/
2. mv CentOS-Base.repo CentOS-Base
3. vi CentOS-Media.repo
baseurl=file:///media/ -----这里要填写具体挂在目录
#光盘挂在目的地
gpgcheck=0 #关闭gpg签名
enabled=1 #开启本光盘yum源
配置光盘默认加载到/media(就是修改挂载表文件)
vi /etc/fstab
/dev/cdrom /media iso9660 defaults 0 0
挂载源 目标地址 执行标准
配置计算机开机即执行的程序或者命令(例如默认开机启动httpd程序)
vi /etc/rc.d/rc.local (/etc/rc.local 是一个快捷方式)
添加 service httpd start
***************************************************
1.1.5 - SAR命令
sar -u cpu使用率 -r 内存使用率 -d 磁盘使用率 -n net 网络流量
CPU使用率
sar -u(-p) 间隔 次数
czhn@czhn:~/download$ sar -u 1 3
Linux 5.15.0-136-generic (czhn) 05/21/2025 _x86_64_ (8 CPU)
02:07:11 AM CPU %user %nice %system %iowait %steal %idle
02:07:12 AM all 1.13 0.00 0.00 0.00 0.00 98.87
02:07:13 AM all 0.62 0.00 0.38 0.00 0.00 99.00
02:07:14 AM all 2.62 0.00 0.50 0.00 0.00 96.88
Average: all 1.46 0.00 0.29 0.00 0.00 98.25
| 输出项 | 详细说明 |
|---|---|
| CPU | all 表示统计信息为所有 CPU 的平均值。 |
| %user | 显示在用户级别(application)运行使用 CPU 总时间的百分比。 |
| %nice | 显示在用户级别,用于nice操作,所占用 CPU 总时间的百分比。 |
| %system | 在核心级别(kernel)运行所使用 CPU 总时间的百分比。 |
| %iowait | 显示用于等待I/O操作占用 CPU 总时间的百分比。 |
| %steal | 管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比。 |
| %idle | 显示 CPU 空闲时间占用 CPU 总时间的百分比。 |
内存使用率
sar -r 间隔 次数
czhn@czhn:~/download$ sar -r 1 3
Linux 5.15.0-136-generic (czhn) 05/21/2025 _x86_64_ (8 CPU)
02:13:42 AM kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
02:13:43 AM 1646212 13599448 17816136 54.40 1897468 8814492 36291744 54.73 5682364 22453216 984
02:13:44 AM 1642788 13596052 17819540 54.41 1897472 8814508 36291744 54.73 5682368 22452176 968
02:13:45 AM 1638028 13591344 17824232 54.42 1897472 8814576 36314100 54.77 5682368 22463168 1128
Average: 1642343 13595615 17819969 54.41 1897471 8814525 36299196 54.75 5682367 22456187 1027
| 输出项 | 详细说明 |
|---|---|
| kbmemfree | 这个值和free命令中的free值基本一致,所以它不包括buffer和cache的空间。 |
| kbmemused | 这个值和free命令中的used值基本一致,所以它包括buffer和cache的空间。 |
| %memused | 这个值是kbmemused和内存总量(不包括swap)的一个百分比。 |
| kbbuffers和kbcached | 这两个值就是free命令中的buffer和cache。 |
| kbcommit | 保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap)。 |
| %commit | 这个值是kbcommit与内存总量(包括swap)的一个百分比。 |
磁盘I/O
sar -d 间隔 次数
每次都是把全部磁盘输出一遍, 所以会比较多
czhn@czhn:~/download$ sar -d 1 3
Linux 5.15.0-136-generic (czhn) 05/21/2025 _x86_64_ (8 CPU)
02:16:31 AM DEV tps rkB/s wkB/s dkB/s areq-sz aqu-sz await %util
02:16:32 AM nvme0n1 3.00 0.00 12.00 0.00 4.00 0.00 0.67 0.80
02:16:32 AM sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:16:32 AM sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:16:32 AM DEV tps rkB/s wkB/s dkB/s areq-sz aqu-sz await %util
02:16:33 AM nvme0n1 7.00 0.00 192.00 0.00 27.43 0.00 0.14 0.80
02:16:33 AM sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:16:33 AM sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:16:33 AM DEV tps rkB/s wkB/s dkB/s areq-sz aqu-sz await %util
02:16:34 AM nvme0n1 6.00 0.00 132.00 0.00 22.00 0.00 0.33 0.40
02:16:34 AM sda 3.00 0.00 88.00 0.00 29.33 0.00 0.33 0.80
02:16:34 AM sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: DEV tps rkB/s wkB/s dkB/s areq-sz aqu-sz await %util
Average: nvme0n1 5.33 0.00 112.00 0.00 21.00 0.00 0.31 0.67
Average: sda 1.00 0.00 29.33 0.00 29.33 0.00 0.33 0.27
Average: sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
| 输出项 | 详细说明 |
|---|---|
| await | 表示平均每次设备I/O操作的等待时间(以毫秒为单位)。 |
| svctm | 表示平均每次设备I/O操作的服务时间(以毫秒为单位)。 |
| %util | 表示一秒中有百分之几的时间用于I/O操作。 |
网络流量
sar -n DEV 间隔 次数
czhn@czhn:~/download$ sar -n DEV 1 3
Linux 5.15.0-136-generic (czhn) 05/21/2025 _x86_64_ (8 CPU)
02:19:45 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
02:19:46 AM lo 64.00 64.00 31.33 31.33 0.00 0.00 0.00 0.00
02:19:46 AM enp2s0 5.00 2.00 0.52 0.21 0.00 0.00 0.00 0.00
02:19:46 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
02:19:47 AM lo 14.00 14.00 3.64 3.64 0.00 0.00 0.00 0.00
02:19:47 AM enp2s0 11.00 37.00 0.85 18.49 0.00 0.00 5.00 0.15
02:19:47 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
02:19:48 AM lo 37.00 37.00 10.98 10.98 0.00 0.00 0.00 0.00
02:19:48 AM enp2s0 8.00 23.00 0.66 17.84 0.00 0.00 0.00 0.15
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
Average: lo 38.33 38.33 15.32 15.32 0.00 0.00 0.00 0.00
Average: enp2s0 8.00 20.67 0.68 12.18 0.00 0.00 1.67 0.10
| 输出项 | 详细说明 |
|---|---|
| IFACE | 就是网络设备的名称。 |
| rxpck/s | 每秒钟接收到的包数目。 |
| txpck/s | 每秒钟发送出去的包数目。 |
| rxkB/s | 每秒钟接收到的字节数。 |
| txkB/s | 每秒钟发送出去的字节数。 | | rxcmp/s | 每秒钟接收到的压缩包数目。 | | txcmp/s | 每秒钟发送出去的压缩包数目。 | | rxmcst/s | 每秒钟接收到的多播包的包数目。 |
1.1.6 - shell编程
ssh
- 免密登录
# 先生成私钥 公钥
ssh-keygen
ssh-copy-id [-p 端口号] user@host
- 配置服务器别名
# 1. 编辑 ~/.ssh/config
# 输入内容
Host server-alias # server-alias为SSH链接的服务器别名
HostName server-ip # 服务器地址
Port 22
User username # 目标服务器端用户名
PreferredAuthentications publickey
# 私钥地址,默认为 ~/.ssh/id_rsa
IdentityFile ~/.ssh/id_rsa
ssh server-alias 进行连接
shell脚本编程
- 变量
# 执行器定义
# 在脚本的第一行定义 #!/bin/bash # 定义脚本执行器,表示使用bash来执行当前脚本
# 变量
# 1. 变量的 k=v 之间不能有空格
# 2. 变量名只能由英、数字以及下划线组成,而且不能以数字开头
# 3. 变量名区分大小写
# 4. 单引号和双引号都可以表示一个字符串。但是双引号可以引用变 "${VARNAME}其他内容"
# 但是单引号的优势是不论什么字符,都不会被转义,除了单引号自己
# 5. 用反引号表示命令执行结果,`ls` `pwd` `date` `echo $?` 可以赋值给一个变量 lsres=`ls`
# 本地变量:作用域为整个bash进程
set VARNAME="value"
# 局部变量: 作用域为当前代码段
local VARNAME="value"
# 环境变量: 作用域为当前shell进程及子进程
export VARNAME="value"
# 位置变量:$1, $2
# 当前脚本或者函数的位置参数 按顺序
# 特殊变量 , $#, $?, $!
$0: 当前脚本名
$#: 参数个数
#?: 退出状态
$!: 最后一个后台进程的进程号
$RANDOM: 随机数,系统内置的
# declare 定义
# 定义一个数字类型的变量
declare -i a=1
# 定义一个只读变量
declare -r b=1
# 显示变量定义
declare -p a b
# 定义一个数组
declare -a arr=("a" "b" "c")
# 声明一个环境变量 和 export 一样
declare -x PATH="/usr/local/bin:$PATH"
# 将变量值存储到目标变量(引用变量)
# declare -n 用于创建引用变量 ref_var,它将指向 var。修改 var 的值,ref_var 会自动反映这个变化。
declare -n ref_var=var
var="This is a reference"
echo $ref_var # 输出 'This is a reference'
# 显示或设置函数属性。
function my_function() {
echo "This is a function"
}
# 他会把这个函数的全部内容打印出来
declare -f my_function
# 这个东西多少年也没用过了
file=/dir1/dir2/dir3/my.file.txt
${file#*/}:删掉第一个 / 及其左边的字符串:dir1/dir2/dir3/my.file.txt
${file##*/}:删掉最后一个 / 及其左边的字符串:my.file.txt
${file#*.}:删掉第一个 . 及其左边的字符串:file.txt
${file##*.}:删掉最后一个 . 及其左边的字符串:txt
${file%/*}:删掉最后一个 / 及其右边的字符串:/dir1/dir2/dir3
${file%%/*}:删掉第一个 / 及其右边的字符串:(空值)
${file%.*}:删掉最后一个 . 及其右边的字符串:/dir1/dir2/dir3/my.file
${file%%.*}:删掉第一个 . 及其右边的字符串:/dir1/dir2/dir3/my
记忆的方法
# 是 去掉左边(键盘上#在 $ 的左边)
%是去掉右边(键盘上% 在$ 的右边)
单一符号是最小匹配;两个符号是最大匹配
${file:5}:删除最左边的 5 个字节:/dir2/dir3/my.file.txt
${file:0:5}:提取最左边的 5 个字节:/dir1
${file:5:5}:提取第 5 个字节右边的连续5个字节:/dir2
也可以对变量值里的字符串作替换
${file/dir/path}:将第一个dir 替换为path:/path1/dir2/dir3/my.file.txt
${file//dir/path}:将全部dir 替换为 path:/path1/path2/path3/my.file.txt
${parameter:-word}:如果parameter为空或未定义,则变量展开为“word”;否则,展开为parameter的值;
${parameter:+word}:如果parameter为空或未定义,不做任何操作;否则,则展开为“word”值;
${parameter:=word}:如果parameter为空或未定义,则变量展开为“word”,并将展开后的值赋值给parameter;
- 数据类型
数值、
num=1
字符串、
str="hello"
布尔、
bool=true
数组、
arr=(1 2 3)
字典
declare -A dict=([name]=zhangsan [age]=18)
遍历数组
for i in ${arr[@]}
do
echo $i
done
遍历字典
for key in "${!dict[@]}"; do
echo "$key = ${dict[$key]}"
done
- 代码块
# 函数 先声明后使用
function func_name(args) {
}
# 函数调用
func_name(args)
# 对于无参的函数可以不用加括号 直接写函数名
# {}代码块 实际上是一个匿名函数。其内部的变量会提升作用域到当前shell进程
# ()代码块,将作为一个子进程来执行,所以其内部的变量只在()内部有效
- 条件测试
整数测试
-eq: 测试两个整数是否相等;比如 $A -eq $B
-ne: 测试两个整数是否不等;不等,为真;相等,为假;
-gt: 测试一个数是否大于另一个数;大于,为真;否则,为假;
-lt: 测试一个数是否小于另一个数;小于,为真;否则,为假;
-ge: 大于或等于
-le:小于或等于
字符测试
==
!=
>
<
-n:字符串非空
-z:字符串为空
文件测试
-e: 文件存在
-f: 是文件
-d: 是目录
-r: 是可读文件
-w: 是可写文件
-x: 是可执行文件
-a: 与关系
-o: 或关系
!: 非关系 -not
判断java命令是否存在
hasjava=`command -v java &> /dev/null`
if [ $? -eq 0 ]; then
echo "java 信息"
java -version
else
echo "java command has found"
fi
判断 hostname 为空或者等于'(none)' 就赋值为 localhost
这个功能有点类似于c语言定义常量的 检查后赋值的语法
[ -z "$hostname" -o "hostname" == '(none)' ] && hsotname=localhost
- 分支
# while循环
declare -i I=1
declare -i SUM=0
while [ 判断 ]; do
循环体
done
# for循环
for 变量 in 列表; do
循环体
done
for (( expr1 ; expr2 ; expr3 )); do
循环体
done
支持 break continue
case "$varname" in
[a-z]) echo "abc";;
[0-9]) echo "123";;
esac
case $1 in
'status')
echo "`basename $0` stats" ;;
'start')
echo "`basename $0` start..." ;;
'stop')
echo "`basename $0` stop ..." ;;
*)
echo "Unkonw options" ;;
esac
#表示把第n+1个参数移到第1个参数, 即命令结束后$1的值等于$n+1的值 #
#有点像二进制的左移指令。把第n+1 移动n个位置到最左侧。
# 不写n 默认为1
shift n
# shift 应用的一个案例
function main(){
# arg parsing
while [ $# -gt 0 ]; do
echo '当前参数1='$1
case $1 in
-h|--help)
echo './bootstrap [-r|--region <region>] [-p|--path <pkg>] [-y|--yes] [-d|--debug]'
exit 0;;
# 通过 -d 或 --debug 开启 DEBUG 模式 这个不要删 是此模板的默认参数
-d|--debug)
DEBUG=1
;;
# 以下两个位置参数自己随便改
# 接收 "-r 值" 或 "--region 值" 赋值给变量 REGION
-r|--region)
REGION="$2"
shift 1
;;
# 接收 "-p 值" 或 "--path 值" 赋值给变量 PKG_PATH
-p|--path)
PKG_PATH="$2"
shift 1
;; #同上
(--) shift; break;;
(-*) echo "$0: error - unrecognized option $1" 1>&2; exit 1;;
(*) break;;
esac
shift
done
echo ${DEBUG}
echo ${REGION}
echo ${PKG_PATH}
}
- shell expect
Expect是一个基于Tcl语言的工具,主要用于自动化控制那些需要交互的命令行程序。它通过模拟标准输入来与程序进行交互,从而自动化执行那些通常需要人工干预的任务。Expect的主要功能包括:
spawn:启动一个进程。
expect:等待特定的输出(字符串)出现。
send:发送响应或输入到进程中。
interact:允许用户与进程交互。
timeout:设置超时时间。
expect一般需要单独安装 sudo apt-get install expect sudo yum install expect
它存在的意义
expect可以让我们实现自动登录远程机器,并且可以实现自动远程执行命令。当然若是使用不带密码的密钥验证同样可以实现自动登录和自动远程执行命令。
但当不能使用密钥验证的时候,我们就没有办法了。所以,这时候只要知道对方机器的账号和密码就可以通过expect脚本实现登录和远程命令。
例如脚本 expect_command.sh
使用方法 chmod +x expect_command.sh
expect_command.sh 用户名 密码 目标主机ip 要执行的命令
#!/usr/bin/expect
set user [lindex $argv 0]
set password [lindex $argv 0]
set host [lindex $argv 1]
set cmd [lindex $argv 2]
spawn ssh $user@$host
expect {
"*yes/no" { send "yes\r"; exp_continue }
"password:" { send "$password\r" }
}
expect "]*"
send "$cmd\r"
expect "]*"
send "exit\r"
其他示例参考脚本和示例.md
控制台操作和一些命令
清空历史命令 ----- history -c
强制正在执行的程序中断 ----- ctrl+c
清空当前屏幕 ----- clear
清空当前命令行 ----- ctrl+u
命令补全 ----- tab
列出可补全的全部 ----- 双击tab
调用历史命令中离你最近一次的以ser开头的命令 ----- !ser
给命令起别名 ----- alias ddd='df -Th'
取消命令别名 ----- unalias ddd
查看当前系统中所有的别名 ----- alias
查找某个命令的绝对路径 -----
[root@localhost ~]# which rmdir
/bin/rmdir
[root@localhost ~]# command -v rmdir
/bin/rmdir
[root@localhost ~]# whereis rmdir
rmdir: /usr/bin/rmdir /usr/share/man/man1/rmdir.1.gz
查看用户所在的终端 ----- w 或者 who 命令 (本地终端一般是ttyn,ssh连接的终端是pts/n)
踢出pts/4用户 ----- pkill -kill -t pts/4
远程同步目录 ----- rsync -avP '-e ssh -p 1024' root@155.254.33.138:/data/admin /data
rsync 也可以用于同步本地目录 用法和cp差不多
ssh免密码登录 ----- ssh-copy-id -i id_rsa.pub "-p 1024 root@155.254.33.138"
密码交互重定向 ----- echo "密码" | passwd --stdin 用户名 (设置用户名的密码)
将运行的脚本 变成父进程 ----- exec
查看当前目录下一级子目录的大小 du -h --max-depth=1
使用(;): 可以在一行运行多个命令。
使用(&&): 可以在一行运行多个命令,并且只有前面命令执行成功,后面命令才会执行
使用(||): 可以在一行运行多个命令,并且只有前面命令执行失败,后面命令才会执行。它和 && 刚好相反
使用(&): 命令后添加& ,可以让命令到后台执行。一个正在运行的命令可以用 ctrl+z 将其放入到后台。
然后使用 jobs 查看这些后台进程。系统会为每个后台进程分配一个编号。使用 fg 编号,可以将 后台命令调到前台
czhn@czhn:~/download$ vim 123 &
[1] 97676
czhn@czhn:~/download$ jobs
[1]+ Stopped vim 123
czhn@czhn:~/download$ fg 1 # 将vim 123激活到前台进入vim窗口进行编辑
花括号的使用{}
{a,b} 代表a和b
{a..b} 代表a到b
{a..b..c} a到b,步长为c
[root@arthur test]# echo {1,10} 输出1和10
[root@arthur test]# mkdir -p /data/{1..10} # 则创建 /data/1 /data/2 ... /data/10 一共10个目录
启动|重启|停止名称为aaa的系统服务 ----- service aaa start|restart|stop
systemctl start|stop|restart aaa
查看系统当前时间 ----- date
按照固定格式0000-00-00 00:00显示系统时间 ----- date "%Y-%m-%d %H:%M:%S"
设置系统时间 ----- date -s "2010-10-10 10:10:10"
显示2008年的日历表 ----- cal 2008 (需要安装ncal)
将时间修改保存到 BIOS ----- clock -w
查看当前主机名称 ----- hostname
临时修改主机名称为myPc ----- hostname myPc
永久修改主机名称 ----- vi /etc/sysconfig/network
查看当前运行级别 ----- runlevel
修改当前运行级别 ----- telinit 3 或 init 3
0表示关机,
1表示单用户,
2表示没有网络的命令行级别,
3命令行级别(大多服务器都用这个级别),
4为保留级别,
5为图形化级别,
6为重启。
查看计算机ip信息 ifconfig -a(-a可以显示所有网卡地址)
临时修改计算机eth0网卡ip地址 ifconfig eth0 192.168.100.136
实时查看系统详细信息 ----- top
htop (需要单独安装)
查看系统一分钟,五分钟,十五分钟平均负载 ----- uptime
查看在线用户 ----- who
查看最近一段时间谁操作过系统重要命令,并有ip信息 ----- last
查看系统内存使用情况 ----- free -m -- (-m参数显示以兆为单位)
查看环境变量 ----- echo $PATH #这个环境变量决定了你能在那些路径下直接找到执行程序
向屏幕输出 hello word ----- echo "hello word"
查看httpd相关进程表 ----- ps -ef |grep httpd
查看进程树 ----- pstree |grep httpd
查看pid号(进程号) ----- pstree -p |grep httpd
查看80端口是否开放 ----- netstat -tunpl |grep :80
查看httpd程序占用端口号 ----- netstat -tunpl |grep httpd*
强制杀掉一个pid ----- kill -9 pid
一次性杀掉所有httpd进程 ----- pkill httpd
kelladd httpd
关机 -----
shutdown -h now 关闭系统(1)
init 0 关闭系统(2)
telinit 0 关闭系统(3)
shutdown -h hours:minutes & 按预定时间关闭系统
shutdown -c 取消按预定时间关闭系统
shutdown -r now 重启(1)
reboot 重启(2)
logout 注销
显示机器的处理器架构 ----- uname -m
显示正在使用的内核版本 ----- uname -r
罗列一个磁盘的架构特性 ----- hdparm -i /dev/hda
在磁盘上执行测试性读取操作系统信息 ----- hdparm -tT /dev/sda
显示机器的处理器架构 ----- arch
显示硬件系统部件 ----- dmidecode -q
显示CPU info的信息 ----- cat /proc/cpuinfo
显示中断 ----- cat /proc/interrupts
校验内存使用 ----- cat /proc/meminfo
显示哪些swap被使用 ----- cat /proc/swaps
显示内核的版本 ----- cat /proc/version
显示网络适配器及统计 ----- cat /proc/net/dev
显示已加载的文件系统 ----- cat /proc/mounts
罗列 PCI 设备 ----- lspci -tv
显示 USB 设备 ----- lsusb -tv
显示PID进程占用得文件句柄 ----- lsof – p PID
bash中设置PS1(是数字1而不是字母l)
每个版本bash的PS1变量内的特殊符号可能有些小的差异,你可以先man bash 一下。下面是FC4环境下默认的特殊符号所代表的意义:
\d :代表日期,格式为weekday month date,例如:"Mon Aug 1"
\H :完整的主机名称。例如:我的机器名称为:fc4.linux,则这个名称就是fc4.linux
\h :仅取主机的第一个名字,如上例,则为fc4,.linux则被省略
\t :显示时间为24小时格式,如:HH:MM:SS
\T :显示时间为12小时格式
\A :显示时间为24小时格式:HH:MM
\u :当前用户的账号名称
\v :BASH的版本信息
\w :完整的工作目录名称。家目录会以 ~代替
\W :利用basename取得工作目录名称,所以只会列出最后一个目录
\# :下达的第几个命令
\$ :提示字符,如果是root时,提示符为:# ,普通用户则为:$
默认的PS1内容为: '[\u@\h \W]\$ ' ,所以默认的提示符就是: [root@localhost ~]# 。
但设置PS1的时候需要稍微处理一下
PS1="[\\u@\\h \\W]\\$ " 这样显示的结果才是正确的。
设置颜色
颜色表
前景(F) 背景(B) 颜色
---------------------------------------
30 40 黑色
31 41 红色
32 42 绿色
33 43 黄色
34 44 蓝色
35 45 紫红色
36 46 青蓝色
37 47 白色
模式(M) 意义
-------------------------
0 OFF
1 高亮显示
4 underline
5 闪烁
7 反白显示
8 不可见
使用前缀 "\e[M;F;Bm" 可更改其后的所有内容,MFB非必填
M的默认值是0,则原始样式为\e[m
1.1.7 - ssh管理
白名单形式
要求: 只允许 192.168.0.1 和 192.168.0.10 登陆 其他全部禁止
实现:
- vim /etc/hosts.allow //增加如下内容
sshd: 192.168.0.1, 192.168.0.10
- vim /etc/hosts.deny //增加如下内容
sshd: ALL
黑名单形式
要求: 只限制192.168.0.1登陆上来,其他全部放行
实现:
vim /etc/hosts.deny //增加如下内容
sshd: 192.168.0.1
保存配置文件后就可以啦,不用重启。 不用再去编辑 /etc/hosts.allow 了
我们可以这样理解这两个文件工作原理:
当客户端的IP登陆服务器的时候,先去匹配hosts.allow,
如果这里面有这个IP,则直接放行,如果没有这个IP,则看hosts.deny,
如果这里面有该IP(ALL包括一切IP)则拒绝,如果deny中也没有匹配,则也会放行。
也就是说,如果这两个文件中都没有限定的IP,则会放行!
请思考:
如果两个文件中都是 sshd: ALL 会出现什么情况?
免密登录
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.1.10
生成私钥
ssh-keygen -t rsa -b 4096 -C “your_email@example.com”
1.1.8 - Vim编辑器
vimtutor vim自带的联系教程
获取帮助: :help :help subject
中文版快捷键

Linux编辑器的种类
行编辑器: sed 全屏编辑器: nano,vi vi: Visual Interface vim:是VI Improved 他是一个高级的实现
Vim模式介绍
正常模式:可以使用快捷键命令。
插入模式(输入模式):可以输入文本,在正常模式下,按i、a、o等都可以进入插入模式。
可视模式:正常模式下按v可以进入可视模式, 在可视模式下,移动光标可以选择文本。按V进入可视行模式, 总是整行整行的选中。ctrl+v进入可视块模式。
替换模式:正常模式下,按R进入。
末行模式:正常模式下,按:进入末行模式。
所有模式按esc退出到正常模式
打开关闭另存为
1. 从命令行启动
vim -c cmd file: 在打开文件前,先执行指定的命令。
vim -r file: 恢复上次异常退出的文件。
vim -R file: 以只读的方式打开文件,但可以强制保存。
vim -M file: 以只读的方式打开文件,不可以强制保存。
vim -y num file: 将编辑窗口的大小设为num行。
vim + file: 从文件的末尾开始。
vim +num file: 从第num行开始。
vim +/string file: 打开file,并将光标停留在第一个找到的string上。
vim --remote file: 用已有的vim进程打开指定的文件。 如果你不想启用多个vim会话,这个很有用。但要注意, 如果你用vim,会寻找名叫VIM的服务器。如果你已经有一个gvim在运行了, 你可以用gvim --remote file在已有的gvim中打开文件。
2. 从vim退出
1. 在正常模式中
ZZ
2. 在末行模式
:x -- 保存并退出。
:q ——退出当前窗口。
:q! -- 退出当前窗口,不保存修改。
:wq -- 保存并退出。
3. 在当前窗口操作
:e file --关闭当前编辑的文件,并开启新的文件。 如果对当前文件的修改未保存,vi会警告。
:e! file --放弃对当前文件的修改,编辑新的文件。
:e+file -- 开始新的文件,并从文件尾开始编辑。
:e+n file -- 开始新的文件,并从第n行开始编辑。
:enew --编译一个未命名的新文档。(CTRL-W n)
:e -- 重新加载当前文档。
:e! -- 重新加载当前文档,并丢弃已做的改动。
:e#或ctrl+^ -- 回到刚才编辑的文件,很实用。
:f或ctrl+g -- 显示文档名,是否修改,和光标位置。
:f filename -- 改变编辑的文件名,这时再保存相当于另存为。
gf -- 打开以光标所在字符串为文件名的文件。(这个就是没有冒号)
:n1,n2w filename -- 选择性保存从某n1行到另n2行的内容。
:w -- 保存修改。
:w /PATH/TO/FILE -->写入到文件(另存为)
:saveas newfilename -- 另存为
:browse e -- 会打开一个文件浏览器让你选择要编辑的文件。 如果是终端中,则会打开netrw的文件浏览窗口。 如果是gvim,则会打开一个图形界面的浏览窗口。 实际上:browse后可以跟任何编辑文档的命令,如sp等。 用browse打开的起始目录可以由browsedir来设置:
:set browsedir=last -- 用上次访问过的目录(默认)。
:set browsedir=buffer -- 用当前文件所在目录。
:set browsedir=current -- 用当前工作目录。
:Sex -- 水平分割一个窗口,浏览文件系统。
:Vex -- 垂直分割一个窗口,浏览文件系统。
正常模式
基本移动
1. 字符跳转
数字 (h|j|k|l), 对应数字的左下上右
j: 下。
k: 上。
h或退格: 左。
l或空格: 右。
2. 单词跳转
w: 前移一个单词,光标停在下一个单词开头。
W: 移动下一个单词开头,但忽略一些标点。
e: 前移一个单词,光标停在下一个单词末尾。
E: 移动到下一个单词末尾,如果词尾有标点,则移动到标点。
b: 后移一个单词,光标停在上一个单词开头。
B: 移动到上一个单词开头,忽略一些标点。
上面的操作都可以配合n(表示一个数字)使用,比如在正常模式(下面会讲到)下输入3h, 则光标向左移动3个字符。
3. 行跳转
+或Enter: 把光标移至下一行第一个非空白字符。
-: 把光标移至上一行第一个非空白字符。
0: 移动到行首。
^: 移动到本行第一个非空白字符。
$: 移动到行尾。
4. 行间跳转
:n 回车: 移动到第n行。
nG: 到文件第n行。(n表示一个数字)
5. 屏幕跳转
g0: 移到光标所在屏幕行行首。
H: 把光标移到屏幕最顶端一行。
M: 把光标移到屏幕中间一行。
L: 把光标移到屏幕最底端一行。
6. 列跳转
n|: 把光标移到递n列(字符L)上。(n表示一个数字)
7.文档跳转
gg: 到文件头部。
G: 到文件尾部。
:$ 回车: 到文件尾部。
): 后一句
(: 前一句
{: 前一个段落
}: 后一个段落
翻屏
ctrl+f: 下翻一屏。
ctrl+b: 上翻一屏。
ctrl+d: 下翻半屏。
ctrl+u: 上翻半屏。
ctrl+e: 向下滚动一行。
ctrl+y: 向上滚动一行。
n%: 到文件n%的位置。
zz: 将当前行移动到屏幕中央。
zt: 将当前行移动到屏幕顶端。
zb: 将当前行移动到屏幕底端。
标记
使用标记可以快速移动。到达标记后,可以用Ctrl+o返回原来的位置。 Ctrl+o和Ctrl+i 很像浏览器上的 后退 和 前进 。
m{a-z}: 标记光标所在位置,局部标记,只用于当前文件。
m{A-Z}: 标记光标所在位置,全局标记。标记之后,退出Vim, 重新启动,标记仍然有效。
`{a-z}: 移动到标记位置。
'{a-z}: 移动到标记行的行首。
`{0-9}:回到上[2-10]次关闭vim时最后离开的位置。
``: 移动到上次编辑的位置。''也可以,不过``精确到列,而''精确到行 。如果想跳转到更老的位置,可以按Ctrl+o,跳转到更新的位置用Ctrl+i。
`": 移动到上次离开的地方。
`.: 移动到最后改动的地方。
:marks 显示所有标记。
:delmarks a b -- 删除标记a和b。
:delmarks a-c -- 删除标记a、b和c。
:delmarks a c-f -- 删除标记a、c、d、e、f。
:delmarks! -- 删除当前缓冲区的所有标记。
:help mark-motions 查看更多关于mark的知识。
正常模式切换输入模式(插入模式)
i: 在光标前插入。一个小技巧:按8,再按i,进入插入模式,输入=, 按esc进入命令模式,就会出现8个=。 这在插入分割线时非常有用,如30i+<esc>就插入了36个+组成的分割线。
I: 在当前行第一个非空字符前插入。
gI: 在当前行第一列插入。
a: 在光标后插入。
A: 在当前行最后插入。
o: 在下面新建一行插入。
O: 在上面新建一行插入。
插入文本
:r filename在当前位置插入另一个文件的内容。
:[n]r filename在第n行插入另一个文件的内容。
:r !date 在光标处插入当前日期与时间。同理,:r !command可以将其它shell命令的输出插入当前文档。
5.2 改写插入
c[n]w: 改写光标后1(n)个词。
c[n]l: 改写光标后n个字母。
c[n]h: 改写光标前n个字母。
[n]cc: 修改当前[n]行。
[n]s: 以输入的文本替代光标之后1(n)个字符,相当于c[n]l。
[n]S: 删除指定数目的行,并以所输入文本代替之。
注意,类似cnw,dnw,ynw的形式同样可以写为ncw,ndw,nyw。
剪切复制和寄存器
剪切和复制、粘贴
[n]x: 剪切光标右边n个字符,相当于d[n]l。
[n]X: 剪切光标左边n个字符,相当于d[n]h。
y: 复制在可视模式下选中的文本。
yy or Y: 复制整行文本。
y[n]w: 复制一(n)个词。
y[n]l: 复制光标右边1(n)个字符。
y[n]h: 复制光标左边1(n)个字符。
y$: 从光标当前位置复制到行尾。
y0: 从光标当前位置复制到行首。
:m,ny<cr> 复制m行到n行的内容。
y1G或ygg: 复制光标以上的所有行。
yG: 复制光标以下的所有行。
yaw和yas:复制一个词和复制一个句子,即使光标不在词首和句首也没关系。
d: 删除(剪切)在可视模式下选中的文本。
d$ or D: 删除(剪切)当前位置到行尾的内容。
d[n]w: 删除(剪切)1(n)个单词
d[n]l: 删除(剪切)光标右边1(n)个字符。
d[n]h: 删除(剪切)光标左边1(n)个字符。
d0: 删除(剪切)当前位置到行首的内容
[n] dd: 删除(剪切)1(n)行。
:m,nd<cr> 剪切m行到n行的内容。
d1G或dgg: 剪切光标以上的所有行。
dG: 剪切光标以下的所有行。
daw和das:剪切一个词和剪切一个句子,即使光标不在词首和句首也没关系。
d/f<cr>:这是一个比较高级的组合命令,它将删除当前位置 到下一个f之间的内容。
p: 在光标之后粘贴。
P: 在光标之前粘贴。
文本对象
aw:一个词
as:一句。
ap:一段。
ab:一块(包含在圆括号中的)。
y, d, c, v都可以跟文本对象。
寄存器
a-z:都可以用作寄存器名。"ayy把当前行的内容放入a寄存器。
A-Z:用大写字母索引寄存器,可以在寄存器中追加内容。 如"Ayy把当前行的内容追加到a寄存器中。
:reg 显示所有寄存器的内容。
"":不加寄存器索引时,默认使用的寄存器。
"*:当前选择缓冲区,"*yy把当前行的内容放入当前选择缓冲区。
"+:系统剪贴板。"+yy把当前行的内容放入系统剪贴板。
查找与替换
查找
/something: 在后面的文本中查找something。
?something: 在前面的文本中查找something。
/pattern/+number: 将光标停在包含pattern的行后面第number行上。
/pattern/-number: 将光标停在包含pattern的行前面第number行上。
n: 向后查找下一个。
N: 向前查找下一个。
可以用grep或vimgrep查找一个模式都在哪些地方出现过,
其中:grep是调用外部的grep程序,而:vimgrep是vim自己的查找算法。
用法为: :vim[grep]/pattern/[g] [j] files
g的含义是如果一个模式在一行中多次出现,则这一行也在结果中多次出现。
j的含义是grep结束后,结果停在第j项,默认是停在第一项。
vimgrep前面可以加数字限定搜索结果的上限,如
:1vim/pattern/ % 只查找那个模式在本文件中的第一个出现。
其实vimgrep在读纯文本电子书时特别有用,可以生成导航的目录。
比如电子书中每一节的标题形式为:n. xxxx。你就可以这样:
:vim/^d{1,}./ %
然后用:cw或:copen查看结果,可以用C-w H把quickfix窗口移到左侧,
就更像个目录了。
替换
g 全局替换 i 忽略大小写
s跟随的字符,就是分隔符 s@要查找@替换@修饰 那么@就是分隔符 常用s@@@或s###
格式 s/old/new/修饰符(ig) - 用new替换当前行所有old。
old 可以使用正则表达式进行搜索
:s/old/new - 用new替换当前行第一个old。
:s/old/new/g - 用new替换当前行所有的old。
:n1,n2s/old/new/g - 用new替换文件n1行到n2行所有的old。
:%s/old/new/g - 用new替换文件中所有的old。
:%s/^/xxx/g - 在每一行的行首插入xxx,^表示行首。
:%s/$/xxx/g - 在每一行的行尾插入xxx,$表示行尾。
所有替换命令末尾加上c,每个替换都将需要用户确认。 如:%s/old/new/gc,加上i则忽略大小写(ignore)。
还有一种比替换更灵活的方式,它是匹配到某个模式后执行某种命令,
语法为 :[range]g/pattern/command
例如 :%g/^ xyz/normal dd。
表示对于以一个空格和xyz开头的行执行normal模式下的dd命令。
关于range的规定为:
如果不指定range,则表示当前行。
m,n: 从m行到n行。
0: 最开始一行(可能是这样)。
$: 最后一行
.: 当前行
%: 所有行
实例:
把所有t开头的单词,把开头的t换成大写
:%s@\<t\([[:alpha:]]\+\)\>@T\1@gi
在所有t开头的单词后面添加er
:%s@\<t[[:alpha:]]\+\>@&er@g
练习:
1. (复制/etc/grub2.cfg)查找替换命令删除/temp/grub2.cfg文件中以空白字符开头的行的行首的空白字符
%s@^[[:space:]]\+@@
2. (复制/etc/init.d/functions)查找替换命令为/tmp/function文件的每个以空白字符开头的行的行首加上#号
%s@^[[:space:]]\+[^[:space:]]@#&@g
3. 为/tmp/grub2.cfg文件的前三行行首加上#号
4. 将/etc/yum.repos.d/CentOS-Base.repo文件中所有的enabled=0替换为enabled1=1,所有gpgcheck=0 替换为gpgcheck=1
%s@\(enabled\|gpgcheck
\)=0@\1=1@g
正则表达式
高级的查找替换就要用到正则表达式。
\d: 表示十进制数(我猜的)
\s: 表示空格
\S: 非空字符
\a: 英文字母
\|: 表示 或
\.: 表示.
{m,n}: 表示m到n个字符。这要和 \s与\a等连用,如 \a\{m,n} 表示m 到n个英文字母。
{m,}: 表示m到无限多个字符。
**: 当前目录下的所有子目录。
:help pattern得到更多帮助。
排版
基本排版
<< 向左缩进一个shiftwidth
>> 向右缩进一个shiftwidth
:ce(nter) 本行文字居中
:le(ft) 本行文字靠左
:ri(ght) 本行文字靠右
gq 对选中的文字重排,即对过长的文字进行断行
gqq 重排当前行
gqnq 重排n行
gqap 重排当前段
gqnap 重排n段
gqnj 重排当前行和下面n行
gqQ 重排当前段对文章末尾
J 拼接当前行和下一行
gJ 同 J ,不过合并后不留空格。
拼写检查
:set spell-开启拼写检查功能
:set nospell-关闭拼写检查功能
]s-移到下一个拼写错误的单词
[s-作用与上一命令类似,但它是从相反方向进行搜索
z=-显示一个有关拼写错误单词的列表,可从中选择
zg-告诉拼写检查器该单词是拼写正确的
zw-与上一命令相反,告诉拼写检查器该单词是拼写错误的
8.3 统计字数
g ^g可以统计文档字符数,行数。 将光标放在最后一个字符上,用字符数减去行数可以粗略统计中文文档的字数。 以上对 Mac 或 Unix 的文件格式适用。 如果是 Windows 文件格式(即换行符有两个字节),字数的统计方法为: 字符数 - 行数 * 2。
编辑多个文件
一次编辑多个文件
我们可以一次打开多个文件,如
vi a.txt b.txt c.txt
文件间切换
:next 下一个
:prev 上一个
:frist 第一个
:last 最后一个
退出
:wqall 保存所有文件并退出
:wall 保存所有文件
:qall 退出所有文件
使用:next(:n)编辑下一个文件。
:2n 编辑下2个文件。
:next 下一个
:prev 上一个
:frist 第一个
:last 最后一个
使用:previous或:N编辑上一个文件。
使用:wnext,保存当前文件,并编辑下一个文件。
使用:wprevious,保存当前文件,并编辑上一个文件。
使用:args 显示文件列表。
:n filenames或:args filenames 指定新的文件列表。
vi -o filenames 在水平分割的多个窗口中编辑多个文件。
vi -O filenames 在垂直分割的多个窗口中编辑多个文件。
多标签编辑
vim -p files: 打开多个文件,每个文件占用一个标签页。
:tabe, tabnew -- 如果加文件名,就在新的标签中打开这个文件, 否则打开一个空缓冲区。
^w gf -- 在新的标签页里打开光标下路径指定的文件。
:tabn -- 切换到下一个标签。Control + PageDown,也可以。
:tabp -- 切换到上一个标签。Control + PageUp,也可以。
[n] gt -- 切换到下一个标签。如果前面加了 n , 就切换到第n个标签。第一个标签的序号就是1。
:tab split -- 将当前缓冲区的内容在新页签中打开。
:tabc[lose] -- 关闭当前的标签页。
:tabo[nly] -- 关闭其它的标签页。
:tabs -- 列出所有的标签页和它们包含的窗口。
:tabm[ove] [N] -- 移动标签页,移动到第N个标签页之后。 如 tabm 0 当前标签页,就会变成第一个标签页。
缓冲区
:buffers或:ls或:files 显示缓冲区列表。
ctrl+^:在最近两个缓冲区间切换。
:bn -- 下一个缓冲区。
:bp -- 上一个缓冲区。
:bl -- 最后一个缓冲区。
:b[n]或:[n]b -- 切换到第n个缓冲区。
:nbw(ipeout) -- 彻底删除第n个缓冲区。
:nbd(elete) -- 删除第n个缓冲区,并未真正删除,还在unlisted列表中。
:ba[ll] -- 把所有的缓冲区在当前页中打开,每个缓冲区占一个窗口。
分屏编辑
vim -o file1 file2:水平分割窗口,同时打开file1和file2
vim -O file1 file2:垂直分割窗口,同时打开file1和file2
水平分割
:split(:sp) -- 把当前窗水平分割成两个窗口。(CTRL-W s 或 CTRL-W CTRL-S) 注意如果在终端下,CTRL-S可能会冻结终端,请按CTRL-Q继续。
:split filename -- 水平分割窗口,并在新窗口中显示另一个文件。
:nsplit(:nsp) -- 水平分割出一个n行高的窗口。
:[N]new -- 水平分割出一个N行高的窗口,并编辑一个新文件。 (CTRL-W n或 CTRL-W CTRL-N)
ctrl+w f --水平分割出一个窗口,并在新窗口打开名称为光标所在词的文件 。
C-w C-^ -- 水平分割一个窗口,打开刚才编辑的文件。
Ctrl+w 后按s 当前窗口水平分割
Ctrl+w 后按v 当前窗口垂直分割
垂直分割
:vsplit(:vsp) -- 把当前窗口分割成水平分布的两个窗口。 (CTRL-W v或CTRL CTRL-V)
:[N]vne[w] -- 垂直分割出一个新窗口。
:vertical 水平分割的命令: 相应的垂直分割。
关闭子窗口
:qall -- 关闭所有窗口,退出vim。
:wall -- 保存所有修改过的窗口。
:only -- 只保留当前窗口,关闭其它窗口。(CTRL-W o)
:close -- 关闭当前窗口,CTRL-W c能实现同样的功能。 (象 :q :x同样工作 )
调整窗口大小
ctrl+w + --当前窗口增高一行。也可以用n增高n行。
ctrl+w - --当前窗口减小一行。也可以用n减小n行。
ctrl+w _ --当前窗口扩展到尽可能的大。也可以用n设定行数。
:resize n -- 当前窗口n行高。
ctrl+w = -- 所有窗口同样高度。
n ctrl+w _ -- 当前窗口的高度设定为n行。
ctrl+w < --当前窗口减少一列。也可以用n减少n列。
ctrl+w > --当前窗口增宽一列。也可以用n增宽n列。
ctrl+w | --当前窗口尽可能的宽。也可以用n设定列数。
切换和移动窗口
如果支持鼠标,切换和调整子窗口的大小就简单了。
ctrl+w ctrl+w: 切换到下一个窗口。或者是ctrl+w w。
ctrl+w p: 切换到前一个窗口。
ctrl+w h(l,j,k):切换到左(右,下,上)的窗口。
ctrl+w t(b):切换到最上(下)面的窗口。<BR>
ctrl+w H(L,K,J): 将当前窗口移动到最左(右、上、下)面。
ctrl+w r:旋转窗口的位置。
ctrl+w T: 将当前的窗口移动到新的标签页上。
快速编辑
1 改变大小写
~: 反转光标所在字符的大小写。
可视模式下的U或u:把选中的文本变为大写或小写。
gu(U)接范围(如$,或G),可以把从光标当前位置到指定位置之间字母全部 转换成小写或大写。如ggguG,就是把开头到最后一行之间的字母全部变为小 写。再如gu5j,把当前行和下面四行全部变成小写。
2 替换(normal模式)
r: 替换光标处的字符,同样支持汉字。
R: 进入替换模式,按esc回到正常模式。
3 撤消与重做(normal模式)
[n] u: 取消一(n)个改动。
:undo 5 -- 撤销5个改变。
:undolist -- 你的撤销历史。
ctrl + r: 重做最后的改动。
U: 取消当前行中所有的改动。
:earlier 4m -- 回到4分钟前
:later 55s -- 前进55秒
4 宏
. --重复上一个编辑动作
qa:开始录制宏a(键盘操作记录)
q:停止录制
@a:播放宏a
编辑特殊文件
1 文件加解密
vim -x file: 开始编辑一个加密的文件。
:X -- 为当前文件设置密码。
:set key= -- 去除文件的密码。
这里是 滇狐总结的比较高级的vi技巧。
2 文件的编码
:e ++enc=utf8 filename, 让vim用utf-8的编码打开这个文件。
:w ++enc=gbk,不管当前文件什么编码,把它转存成gbk编码。
:set fenc或:set fileencoding,查看当前文件的编码。
在vimrc中添加set fileencoding=ucs-bom,utf-8,cp936,vim会根据要打开的文件选择合适的编码。 注意:编码之间不要留空格。 cp936对应于gbk编码。 ucs-bom对应于windows下的文件格式。
让vim 正确处理文件格式和文件编码,有赖于 ~/.vimrc的正确配置
3 文件格式
大致有三种文件格式:unix, dos, mac. 三种格式的区别主要在于回车键的编码:dos 下是回车加换行,unix 下只有 换行符,mac 下只有回车符。
:e ++ff=dos filename, 让vim用dos格式打开这个文件。
:w ++ff=mac filename, 以mac格式存储这个文件。
:set ff,显示当前文件的格式。
在vimrc中添加set fileformats=unix,dos,mac,让vim自动识别文件格式。
编程辅助
1 一些按键
gd: 跳转到局部变量的定义处。
gD: 跳转到全局变量的定义处,从当前文件开头开始搜索。
g;: 上一个修改过的地方。
g,: 下一个修改过的地方。
[[: 跳转到上一个函数块开始,需要有单独一行的{。
]]: 跳转到下一个函数块开始,需要有单独一行的{。
[]: 跳转到上一个函数块结束,需要有单独一行的}。
][: 跳转到下一个函数块结束,需要有单独一行的}。
[{: 跳转到当前块开始处。
]}: 跳转到当前块结束处。
[/: 跳转到当前注释块开始处。
]/: 跳转到当前注释块结束处。
%: 不仅能移动到匹配的(),{}或[]上,而且能在#if,#else, #endif之间跳跃。
下面的括号匹配对编程很实用的。
ci', di', yi':修改、剪切或复制'之间的内容。
ca', da', ya':修改、剪切或复制'之间的内容,包含'。
ci", di", yi":修改、剪切或复制"之间的内容。
ca", da", ya":修改、剪切或复制"之间的内容,包含"。
ci(, di(, yi(:修改、剪切或复制()之间的内容。
ca(, da(, ya(:修改、剪切或复制()之间的内容,包含()。
ci[, di[, yi[:修改、剪切或复制[]之间的内容。
ca[, da[, ya[:修改、剪切或复制[]之间的内容,包含[]。
ci{, di{, yi{:修改、剪切或复制{}之间的内容。
ca{, da{, ya{:修改、剪切或复制{}之间的内容,包含{}。
ci<, di<, yi<:修改、剪切或复制<>之间的内容。
ca<, da<, ya<:修改、剪切或复制<>之间的内容,包含<>。
2 ctags
ctags -R: 生成tag文件,-R表示也为子目录中的文件生成tags
:set tags=path/tags -- 告诉ctags使用哪个tag文件
:tag xyz -- 跳到xyz的定义处,或者将光标放在xyz上按C-],返回用C-t
:stag xyz -- 用分割的窗口显示xyz的定义,或者C-w ], 如果用C-w n ],就会打开一个n行高的窗口
:ptag xyz -- 在预览窗口中打开xyz的定义,热键是C-w }。
:pclose -- 关闭预览窗口。热键是C-w z。
:pedit abc.h -- 在预览窗口中编辑abc.h
:psearch abc -- 搜索当前文件和当前文件include的文件,显示包含abc的行。
有时一个tag可能有多个匹配,如函数重载,一个函数名就会有多个匹配。 这种情况会先跳转到第一个匹配处。
:[n]tnext -- 下一[n]个匹配。
:[n]tprev -- 上一[n]个匹配。
:tfirst -- 第一个匹配
:tlast -- 最后一个匹配
:tselect tagname -- 打开选择列表
tab键补齐
:tag xyz<tab> -- 补齐以xyz开头的tag名,继续按tab键,会显示其他的。
:tag /xyz<tab> -- 会用名字中含有xyz的tag名补全。
3 cscope
cscope -Rbq: 生成cscope.out文件
:cs add /path/to/cscope.out /your/work/dir
:cs find c func -- 查找func在哪些地方被调用
:cw -- 打开quickfix窗口查看结果
4 gtags
Gtags综合了ctags和cscope的功能。 使用Gtags之前,你需要安装GNU Gtags。 然后在工程目录运行 gtags 。
:Gtags funcname 定位到 funcname 的定义处。
:Gtags -r funcname 查询 funcname被引用的地方。
:Gtags -s symbol 定位 symbol 出现的地方。
:Gtags -g string Goto string 出现的地方。 :Gtags -gi string 忽略大小写。
:Gtags -f filename 显示 filename 中的函数列表。 你可以用 :Gtags -f % 显示当前文件。
:Gtags -P pattern 显示路径中包含特定模式的文件。 如 :Gtags -P .h$ 显示所有头文件, :Gtags -P /vm/ 显示vm目录下的文件。
5 编译
vim提供了:make来编译程序,默认调用的是make, 如果你当前目录下有makefile,简单地:make即可。
如果你没有make程序,你可以通过配置makeprg选项来更改make调用的程序。 如果你只有一个abc.Java文件,你可以这样设置:
set makeprg=javac\ abc.java
然后:make即可。如果程序有错,可以通过quickfix窗口查看错误。 不过如果要正确定位错误,需要设置好errorformat,让vim识别错误信息。 如:
:setl efm=%A%f:%l:\ %m,%-Z%p^,%-C%.%#
%f表示文件名,%l表示行号, %m表示错误信息,其它的还不能理解。 请参考 :help errorformat。
6 快速修改窗口
其实是quickfix插件提供的功能, 对编译调试程序非常有用 :)
:copen -- 打开快速修改窗口。
:cclose -- 关闭快速修改窗口。
快速修改窗口在make程序时非常有用,当make之后:
:cl -- 在快速修改窗口中列出错误。
:cn -- 定位到下一个错误。
:cp -- 定位到上一个错误。
:cr -- 定位到第一个错误。
7 自动补全
C-x C-s -- 拼写建议。
C-x C-v -- 补全vim选项和命令。
C-x C-l -- 整行补全。
C-x C-f -- 自动补全文件路径。弹出菜单后,按C-f循环选择,当然也可以按 C-n和C-p。
C-x C-p 和C-x C-n -- 用文档中出现过的单词补全当前的词。 直接按C-p和C-n也可以。
C-x C-o -- 编程时可以补全关键字和函数名啊。
C-x C-i -- 根据头文件内关键字补全。
C-x C-d -- 补全宏定义。
C-x C-n -- 按缓冲区中出现过的关键字补全。 直接按C-n或C-p即可。
当弹出补全菜单后:
C-p 向前切换成员。
C-n 向后切换成员。
C-e 退出下拉菜单,并退回到原来录入的文字。
C-y 退出下拉菜单,并接受当前选项。
8 多行缩进缩出
正常模式下,按两下>;光标所在行会缩进。
如果先按了n,再按两下>;,光标以下的n行会缩进。
对应的,按两下<;,光标所在行会缩出。
如果在编辑代码文件,可以用=进行调整。
在可视模式下,选择要调整的代码块,按=,代码会按书写规则缩排好。
或者n =,调整n行代码的缩排。
9 折叠
zf -- 创建折叠的命令,可以在一个可视区域上使用该命令。
zd -- 删除当前行的折叠。
zD -- 删除当前行的折叠。
zfap -- 折叠光标所在的段。
zo -- 打开折叠的文本。
zc -- 收起折叠。
za -- 打开/关闭当前折叠。
zr -- 打开嵌套的折行。
zm -- 收起嵌套的折行。
zR (zO) -- 打开所有折行。
zM (zC) -- 收起所有折行。
zj -- 跳到下一个折叠处。
zk -- 跳到上一个折叠处。
zi -- enable/disable fold;
命令行
normal模式下按:进入命令行模式
1 命令行模式下的快捷键:
上下方向键:上一条或者下一条命令。如果已经输入了部分命令,则找上一 条或者下一条匹配的命令。
左右方向键:左/右移一个字符。
C-w: 向前删除一个单词。
C-h: 向前删除一个字符,等同于Backspace。
C-u: 从当前位置移动到命令行开头。
C-b: 移动到命令行开头。
C-e: 移动到命令行末尾。
Shift-Left: 左移一个单词。
Shift-Right: 右移一个单词。
@: 重复上一次的冒号命令。
q: 正常模式下,q然后按':',打开命令行历史缓冲区, 可以像编辑文件一样编辑命令。
q/和q? 可以打开查找历史记录。
2 执行外部命令
:! cmd 执行外部命令。
:!! 执行上一次的外部命令。
:sh 调用shell,用exit返回vim。
:r !cmd 将命令的返回结果插入文件当前位置。
:m,nw !cmd 将文件的m行到n行之间的内容做为命令输入执行命令。
定制vim
编辑 ~/.vimrc 文件(个人有效)。或 /etc/vimrc 文件(全局有效)。
1.行号
显示: set number 或 set nu
取消显示: set nonumber 或 set nonu
2.自动缩进
set ai
set noai
3.搜索高亮显示
set hlsearch
set nohlsearch
4.语法高亮
syntax on
syntax off
5.忽略字符大小写
set ic
set noic
6.设置tab为4个空格
set ts=4 (注:ts是tabstop的缩写,设TAB宽4个空格)
set expandtab(把制表符换成空格)
其它
1 工作目录
:pwd 显示vim的工作目录。
:cd path 改变vim的工作目录。
:set autochdir 可以让vim 根据编辑的文件自动切换工作目录。
2 一些快捷键(收集中)
K: 打开光标所在词的manpage。
*: 向下搜索光标所在词。
g*: 同上,但部分符合即可。
#: 向上搜索光标所在词。
g#: 同上,但部分符合即可。
g C-g: 统计全文或统计部分的字数。
3 在线帮助
:h(elp)或F1 打开总的帮助。
:help user-manual 打开用户手册。
命令帮助的格式为:第一行指明怎么使用那个命令。 然后是缩进的一段解释这个命令的作用,然后是进一步的信息。
:helptags somepath 为somepath中的文档生成索引。
:helpgrep 可以搜索整个帮助文档,匹配的列表显示在quickfix窗口中。
Ctrl+] 跳转到tag主题,Ctrl+t 跳回。
:ver 显示版本信息。
4 一些小功能
简单计算器: 在插入模式下,输入C-r =,然后输入表达式,就能在 光标处得到计算结果。

1.1.9 - 磁盘管理
LVM概念简述
LVM(Logical Volume Manager)是Linux环境下对磁盘分区进行管理的一种机制,它通过在硬盘和分区之上建立一个逻辑层,提高了磁盘分区管理的灵活性。
LVM的主要目的是通过逻辑卷的方式对磁盘进行动态管理,使得磁盘空间的分配和管理更加灵活和高效。
LVM的基本概念和组成部分
- 物理卷(PV):物理卷是LVM管理的最底层存储单元,可以是实际的物理硬盘或硬盘分区。每个物理卷被划分为多个物理范围(PE),PE是LVM寻址的最小单位。
- 卷组(VG):卷组由一个或多个物理卷组成,相当于一个存储池。卷组中的空间可以被划分为多个逻辑范围(LE),用于创建逻辑卷。
- 逻辑卷(LV):逻辑卷建立在卷组之上,用于存储数据。逻辑卷的大小可以动态调整,而不会丢失数据。
LVM的工作原理
LVM通过将底层的物理硬盘封装起来,以逻辑卷的方式呈现给上层应用。这种方式使得磁盘管理更加灵活,例如可以动态地增加或减少逻辑卷的空间,而不需要重新格式化或移动数据。LVM的最大特点是其动态管理能力,允许在不丢失数据的情况下调整逻辑卷的大小,并且可以方便地添加新的物理硬盘到系统中。
LVM的优点和应用场景
-
灵活的存储管理:LVM允许动态调整逻辑卷的大小,无需重新格式化或移动数据。
-
高效的存储利用:通过将多个物理硬盘整合为一个卷组,LVM可以提高存储资源的利用率和管理的便捷性。
-
易于扩展:当需要增加存储容量时,只需向卷组中添加新的物理硬盘,而不需要改变现有的逻辑卷
Raid详细解说
奇偶校验信息和相对应的数据分别存储于不同的磁盘上,其中任意N-1块磁盘上都存储完整的数据, 也就是说有相当于一块磁盘容量的空间用于存储奇偶校验信息。 因此当RAID5的一个磁盘发生损坏后,不会影响数据的完整性,从而保证了数据安全。 当损坏的磁盘被替换后,RAID还会自动利用剩下奇偶校验信息去重建此磁盘上的数据,来保持RAID5的高可靠性。 做raid 5阵列所有磁盘容量必须一样大,当容量不同时,会以最小的容量为准。 最好硬盘转速一样,否则会影响性能,而且可用空间=磁盘数n-1,其中有一块是专门用来校验的, 在存储数据的时候,校验盘里面是不会被存入数据的 RAID 0 条带化,增加速度(最少2块盘) RAID 1 镜像,增加数据安全(最少2块盘) RAID 5 奇偶校验 既增加速度,又增加安全性(最少3块盘)
磁盘相关命令速查
- 查看磁盘和磁盘分区: sudo fdisk -l [设备名]
# -l 后不加设备, 会列出所有磁盘和分区信息
[root@localhost ~]# fdisk -l
Disk /dev/sda: 17.2 GB, 17179869184 bytes
255 heads, 63 sectors/track, 2088 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00018d63
Device Boot Start End Blocks Id System
/dev/sda1 * 1 13 102400 83 Linux
Partition 1 does not end on cylinder boundary.
/dev/sda2 13 274 2097152 82 Linux swap / Solaris
Partition 2 does not end on cylinder boundary.
/dev/sda3 274 2089 14576640 83 Linux
Disk /dev/sdb: 8589 MB, 8589934592 bytes
255 heads, 63 sectors/track, 1044 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
# 指定设备
[root@localhost ~]# fdisk -l /dev/sda
Disk /dev/sda: 17.2 GB, 17179869184 bytes
255 heads, 63 sectors/track, 2088 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00018d63
Device Boot Start End Blocks Id System
/dev/sda1 * 1 13 102400 83 Linux
Partition 1 does not end on cylinder boundary.
/dev/sda2 13 274 2097152 82 Linux swap / Solaris
Partition 2 does not end on cylinder boundary.
/dev/sda3 274 2089 14576640 83 Linux可以看到刚才阿铭加的一块磁盘 /dev/sdb 的信息。
- 分区工具工作台 sudo fdisk 设备名
czhn@czhn:~$ sudo fdisk /dev/nvme0n1
Welcome to fdisk (util-linux 2.37.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
This disk is currently in use - repartitioning is probably a bad idea.
It's recommended to umount all file systems, and swapoff all swap
partitions on this disk.
# 控制台帮助, 列出了所有的操作
Command (m for help): m
Help:
GPT
M enter protective/hybrid MBR
Generic
d delete a partition 删除一个分区
F list free unpartitioned space 列出未分区的空间
l list known partition types 列出已知的分区类型
n add a new partition 添加一个新的分区
p print the partition table 打印分区表(也就是查看已分区的信息)
t change a partition type 修改分区类型
v verify the partition table 验证分区表
i print information about a partition 查看分区信息
Misc
m print this menu
x extra functionality (experts only)
Script
I load disk layout from sfdisk script file
O dump disk layout to sfdisk script file
Save & Exit
w write table to disk and exit
q quit without saving changes
Create a new label
g create a new empty GPT partition table
G create a new empty SGI (IRIX) partition table
o create a new empty DOS partition table
s create a new empty Sun partition table
- 查看文件系统挂载详情: df -hT
czhn@czhn:~$ df -hT # 加T参数会添加Type列
Filesystem Type Size Used Avail Use% Mounted on
tmpfs tmpfs 3.2G 3.6M 3.2G 1% /run
/dev/sda4 ext4 75G 22G 50G 31% /
tmpfs tmpfs 16G 1.2M 16G 1% /dev/shm
tmpfs tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/sda3 ext4 2.0G 246M 1.6G 14% /boot
/dev/sda1 vfat 1.1G 6.1M 1.1G 1% /boot/efi
/dev/nvme0n1p1 ext4 458G 88G 347G 21% /data
tmpfs tmpfs 3.2G 4.0K 3.2G 1% /run/user/1000
- 临时挂载和卸载
umask 000 # 临时设置umask为000 让用户可写
iocharset=gb2312 codepage=936 # 临时设置编码为gb2312 如果挂载后里面乱码
mount –o umask=000, iocharset=gb2312 codepage=936 /dev/sda4 /data
umount /data
- 查看目录大小 du
如果不加参数, 他会便利所有的目录文件然后输出出来,目录小还好, 如果目录大没法看
du -sh /data # 所有文件大小加起来 显示 /data 这个目录已使用的空间
du -sh /data/* # 所有文件大小加起来 显示 /data 下的每个目录已使用的空间
案例实践
- 查看、分区、格式化、挂载一块磁盘到/data
# 1. 查看所有硬盘
czhn@czhn:~$ sudo fdisk -l|grep /dev/
Disk /dev/loop0: 63.95 MiB, 67051520 bytes, 130960 sectors
Disk /dev/loop1: 87.04 MiB, 91267072 bytes, 178256 sectors
Disk /dev/loop2: 38.83 MiB, 40714240 bytes, 79520 sectors
Disk /dev/loop3: 44.45 MiB, 46604288 bytes, 91024 sectors
Disk /dev/loop4: 89.4 MiB, 93745152 bytes, 183096 sectors
Disk /dev/loop5: 63.75 MiB, 66842624 bytes, 130552 sectors
# 目标分区
Disk /dev/nvme0n1: 465.76 GiB, 500107862016 bytes, 976773168 sectors
Disk /dev/sda: 111.79 GiB, 120034123776 bytes, 234441648 sectors
/dev/sda1 2048 2203647 2201600 1G EFI System
/dev/sda2 2203648 69312511 67108864 32G Linux swap
/dev/sda3 69312512 73506815 4194304 2G Linux filesystem
/dev/sda4 73506816 234438655 160931840 76.7G Linux filesystem
Disk /dev/sdb: 931.51 GiB, 1000204886016 bytes, 1953525168 sectors
# 2. 进入fdisk 工作台 进行分区
# 2.1 nvme协议硬盘分区
czhn@czhn:~$ sudo fdisk /dev/nvme0n1
Welcome to fdisk (util-linux 2.37.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): n
Partition number (1-128, default 1): # 默认直接回车
First sector (34-976773134, default 2048): # 默认直接回车
Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048-976773134, default 976773134): # 默认直接回车
Created a new partition 1 of type 'Linux filesystem' and of size 465.8 GiB.
Partition #1 contains a vfat signature.
Do you want to remove the signature? [Y]es/[N]o: Y # 必须输入大写Y
The signature will be removed by a write command.
# 2.2 机械硬盘或固态硬盘分区 sdx 硬盘的分区
czhn@czhn:~$ sudo fdisk /dev/sdb
Welcome to fdisk (util-linux 2.37.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): n
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
# 这里选p主分区, 要注意主分区只能创建4个,如果要创建更多的分区 最多创建3个主分区, 然后创建扩展分区
Select (default p):
# 这里默认就行了
Partition number (1-4, default 1):
# # 这里是起始扇区,默认2048, 如果你输入其他值那么无非就是浪费一些空间。
First sector (2048-1953525167, default 2048):
# 这个加号很重要没有这个加号会报错“Value out of range.”
Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048-1953525167, default 1953525167): +500G
Created a new partition 1 of type 'Linux' and of size 500 GiB.
Command (m for help): p # 用p命令查看分区信息
Disk /dev/sdb: 931.51 GiB, 1000204886016 bytes, 1953525168 sectors
Disk model: WDC WD10EZEX-21W
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: dos
Disk identifier: 0xd8c6d598
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 1048578047 1048576000 500G 83 Linux
# 这是用i命令查看分区信息
Command (m for help): i
Selected partition 1
Device: /dev/sdb1
Start: 2048
End: 1048578047
Sectors: 1048576000
Cylinders: 65271
Size: 500G
Id: 83
Type: Linux
Start-C/H/S: 0/32/33
End-C/H/S: 758/245/63
# 3. w 命令写入保存
Command (m for help): w # 这里用w命令进行写入保存
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
# 4. 重新查看分区信息
czhn@czhn:~$ sudo fdisk -l|grep /dev/
Disk /dev/loop0: 63.95 MiB, 67051520 bytes, 130960 sectors
Disk /dev/loop1: 87.04 MiB, 91267072 bytes, 178256 sectors
Disk /dev/loop2: 38.83 MiB, 40714240 bytes, 79520 sectors
Disk /dev/loop3: 44.45 MiB, 46604288 bytes, 91024 sectors
Disk /dev/loop4: 89.4 MiB, 93745152 bytes, 183096 sectors
Disk /dev/loop5: 63.75 MiB, 66842624 bytes, 130552 sectors
Disk /dev/nvme0n1: 465.76 GiB, 500107862016 bytes, 976773168 sectors
# 已分区 这里对比 第一步的时 Disk /dev/nvme0n1: 465.76 GiB, 500107862016 bytes, 976773168 sectors
# 可以看到在 /dev/nvme0n1 后面添加了一个p1 分区
/dev/nvme0n1p1 2048 976773134 976771087 465.8G Linux filesystem
Disk /dev/sda: 111.79 GiB, 120034123776 bytes, 234441648 sectors
/dev/sda1 2048 2203647 2201600 1G EFI System
/dev/sda2 2203648 69312511 67108864 32G Linux swap
/dev/sda3 69312512 73506815 4194304 2G Linux filesystem
/dev/sda4 73506816 234438655 160931840 76.7G Linux filesystem
Disk /dev/sdb: 931.51 GiB, 1000204886016 bytes, 1953525168 sectors
# 5. 格式化分区 格式化成ext4格式的分区
czhn@czhn:~$ sudo mkfs.ext4 /dev/nvme0n1p1
mke2fs 1.46.5 (30-Dec-2021)
Discarding device blocks: done
Creating filesystem with 122096385 4k blocks and 30531584 inodes
Filesystem UUID: f0cfe08c-65f3-4af3-b03a-3f7fb8efd43b
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968,
102400000
Allocating group tables: done
Writing inode tables: done
Creating journal (262144 blocks): done
Writing superblocks and filesystem accounting information: done
# 6. 创建目标挂载目录 /data
czhn@czhn:~$ sudo mkdir /data
# 7. 挂载分区
# 写入到 fstab 文件
czhn@czhn:~$ sudo sh -c "echo '/dev/nvme0n1p1 /data ext4 defaults 0 2' >> /etc/fstab"
# 验证文件
czhn@czhn:~$ sudo cat /etc/fstab |grep /data
/dev/nvme0n1p1 /data ext4 defaults 0 2
# 挂载所有
czhn@czhn:~$ sudo mount -a
# 验证挂载结果
czhn@czhn:~$ df -hT
Filesystem Type Size Used Avail Use% Mounted on
tmpfs tmpfs 3.2G 1.5M 3.2G 1% /run
/dev/sda4 ext4 75G 3.3G 68G 5% /
tmpfs tmpfs 16G 0 16G 0% /dev/shm
tmpfs tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/sda3 ext4 2.0G 127M 1.7G 7% /boot
/dev/sda1 vfat 1.1G 6.1M 1.1G 1% /boot/efi
tmpfs tmpfs 3.2G 4.0K 3.2G 1% /run/user/1000
/dev/nvme0n1p1 ext4 458G 28K 435G 1% /data # 挂载成功
# 重启测试挂载
- 制作iso镜像
把/dev/cdrom目录制作为镜像,名字为/root/rh1.iso
方法1:dd if=/dev/cdrom of=/root/rh1.iso
方法2:cat /dev/cdrom >;/root/1.iso
方法3:mkisofs -r -o myiso.iso /dev/cdrom
方法4:cp -r /home/user name.iso
- 把 dir1 dir2 file1 file2 一同打包成 xxx.iso
mkisodfs -o xxx.iso dir1 dir2 file1 file2
1.1.10 - 定时任务
at
一次性计划任务
安装: apt install at
一次性计划任务AT
at队列
用来存储尚未执行的任务,一旦执行了就从队列中将任务删除
队列的保存位置/var/spool/at/
at服务
用来检测和执行任务,每间隔1一分钟就会检查队列中是否有到时的任务.
at工具
用来添加,查看,删除定时任务的工具
at服务的启动和停止
service atd status
at 参数 echo 00000 > /var/spool/at/.SEQ 清除任务id
-l 查看任务列队
-d 删除任务
建立任务
[root@gw ~]# date
2009年 05月 29日 星期五 20:23:36 CST
[root@gw ~]# at 20:26(一个时间)
at> touch /root/zuihouyiye.log
at> <EOT> (ctrl+d)
job 1 at 2013-12-20 20:26
查看一次性计划任务 atq
at -l
删除一次性计划任务 atrm job号(atq可以看到job号)
at -dq
周期性计划任务cron
cron格式 (man 5 crontab)
min hour day mon week commands
min: 分 00-59
hour: 时 00-23
day: 日 1-31
mon: 月 1-12
week: 周 0-7 0和7都是周日
command:要执行的任务--计划任务的命令要写清楚命令完整路径
添加计划任务
创建计划任务:crontab -e
查看计划任务:crontab -l
删除计划任务:crontab -r
示例:
使用方法
分 时 日 月 周
1. 00 03 * * * cmd ----- 单一时间,每天3点
2. 30 23 *** cmd ----- 每天23:30
3. 00 9,12,22 * * * cmd ----- 多个时间
4. 00 9-12 * * * cmd ----- 9-12点,连续时间
59 23 ** 1-5 cmd ----- 周一到周五
6. * * * * * cmd ----- 所有时间
7. */5 * * * * cmd ----- 每间隔5分钟
8. 59 23 ** 1,3,5 cmd ----- 每个周一,周三,周五的23:59
1. 每隔两分钟向/mnt/error.log中写入一行aaa
*/2 **** /bin/echo "aaa">>/mnt/error.log
2. 每天19:20重启服务器
20 19 *** /sbin/init 6
3. 每周一,周三,周五晚上23:00重启服务器
00 23 ** 1,3,5 /sbin/init 6
4. 周一到周五每天00:00重启服务器
59 23 ** 1-5 /sbin/init 6
5.每天凌晨3:00把网站制作一个压缩包,并且拷贝到/mnt下,而且压缩包的名字中必须要有日期
{
思路:考虑基本命令
具体操作方法
创建一个执行脚本 vi web.sh
内容如下
#!/bin/bash
DATE=`date +%Y-%m-%d`
file=web-${DATE}.tar.gz
tar czf /tmp/$file /var/www/html
mv -a /tmp/$file /mnt
}
00 03 * * 0 web.sh 计划任务执行这个脚本
1.1.11 - 脚本和示例
shell使用其他用户执行命令
echo "密码" | su - 用户名 -c "ls /"
更新当前目录下所有的git
#!/bin/bash
dir_list=$(ls)
current_dir=$(cd $(dirname $0); pwd)
for dir in ${dir_list[@]}; do
if [ -d ${current_dir}/${dir} ]; then
if [ -d ${current_dir}/${dir}/.git ]; then
cd ${current_dir}/${dir}
echo "正在更新目录${current_dir}/${dir}"
git config --add core.filemode false
git pull
fi
fi
done
shell expect 传参方式 远程执行命令后退出
path/脚本 koala abc123 192.168.10.10 ls
#!/usr/bin/expect
set user [lindex $argv 0]
set password [lindex $argv 1]
set host [lindex $argv 2]
set cmd [lindex $argv 3]
spawn ssh $user@$host
expect {
"*yes/no" { send "yes\r"; exp_continue }
"password:" { send "$password\r" }
}
expect "]*"
send "$cmd\r"
expect "]*"
send "exit\r"
shell expect 传参方式 远程执行命令后保持登录状态
#!/usr/bin/expect
set timeout -1
set user [lindex $argv 0]
set password [lindex $argv 1]
set host [lindex $argv 2]
spawn ssh $user@$host
expect {
"*yes/no" { send "yes\r"; exp_continue }
"password:" { send "$password\r" }
}
expect "]*"
interact
shell expect 结合 rsync 进行远程同步文件或目录
#!/usr/bin/expect
set user [lindex $argv 0]
set password [lindex $argv 1]
set host [lindex $argv 2]
set cmd [lindex $argv 3]
# 把远程的/tmp/12.txt 同步到本地的当前目录下
spawn rsync $user@$host:/tmp/12.txt ./
expect {
"*yes/no" { send "yes\r"; exp_continue }
"password:" { send "$password\r" }
}
expect eof
shell脚本模板
yum和apt搭建私有仓库
一个Java的纯shell构建启动脚本
安装ssh服务并开启root登录
#!/bin/bash
sudo apt install -y openssh-server
sudo sed -i 's/^#Port.*/Port 22/g' /etc/ssh/sshd_config
sudo sed -i 's/^#AddressFamily.*/AddressFamily any/g' /etc/ssh/sshd_config
sudo sed -i 's/^#ListenAddress.*/ListenAddress 0.0.0.0/g' /etc/ssh/sshd_config
sudo sed -i 's/^#PermitRootLogin.*/PermitRootLogin yes/g' /etc/ssh/sshd_config
sudo systemctl restart sshd.service
在文件中追加内容
sudo cat >> /etc/hosts <<EOF
192.168.44.11 ubuntu1
192.168.44.12 ubuntu1
192.168.44.13 ubuntu1
EOF
直接覆盖某个文件内容
cat <<EOF | sudo tee 文件名 > /dev/null
#文件的全部内容
EOF
清华源安装docker和cri
#!/bin/bash
# https://kubernetes.io/zh-cn/docs/setup/production-environment/container-runtimes/#containerd-systemd
# 1. 在你的每个节点上,遵循安装 Docker Engine 指南为你的 Linux 发行版安装 Docker
sudo apt-get remove docker-doc docker-compose docker-compose-v2 podman-docker ;
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
# 国内装docker用清华的源
curl -fsSL https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# Add the repository to Apt sources:
# 国内装docker用清华的源
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"https://hub-mirror.c.163.com",
"https://reg-mirror.qiniu.com",
"https://registry.docker-cn.com"
],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
# 2. 按照源代码仓库中的说明安装 cri-dockerd
# 对于 cri-dockerd,默认情况下,CRI 套接字是 /run/cri-dockerd.sock
git clone https://github.com/Mirantis/cri-dockerd.git
cd cri-dockerd
make cri-dockerd
#1. 安装cri-dockerd
sudo dpkg -i cri-dockerd_0.3.7.3-0.ubuntu-jammy_amd64.deb
#2. 调整启动参数
sudo sed -i -e 's#ExecStart=.*#ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.7#g' /lib/systemd/system/cri-docker.service
#3. 设置开机自启动和查看cri-docker状态
sudo systemctl daemon-reload
sudo systemctl enable cri-docker
sudo systemctl status cri-docker
扫描网段下所有空闲的ip地址
#!/bin/bash
# 扫描指定网段的活跃IP
active_ips=$(nmap -sn 192.168.77.0/24 | grep "Nmap scan report for" | awk '{print $5}')
# 生成全IP列表
all_ips=$(seq 1 254 | awk -v net="192.168.77." '{print net$1}')
# 比较找出非活跃IP
inactive_ips=$(comm -13 <(printf "%s\n" "${active_ips[@]}" | sort) <(printf "%s\n" "${all_ips[@]}" | sort))
# 对非活跃IP排序
sorted_inactive_ips=$(echo "$inactive_ips" | sort -V)
# 输出结果
echo "非活跃IP地址:"
echo "$sorted_inactive_ips"
1.1.12 - 进程管理
Linux在执行每一个程序时,就会在内存中为这个程序建立一个进程,以便让内核可以管理这个运行中的进程,进程是系统分配各种资源,进程调度的基本单位。
怎么查看进程
一.ps 命令
# ps aux|head -n 2
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.2 2064 624 ? Ss 10:28 0:00 init [3]
USER:程序的执行者
PID:进程的ID号
%CPU:占用CPU的百分比
%MEM:占用内存的百分比
VSZ:预分配的内存量,也就是程序所能使用的内存数量 KB单位
RSS:真实内存占用大小;在预分配的范围中已经使用的大小 单位KB
TTY:控制台打开的位置 (?)为没有打开
STAT:进程运行的状态
R 进程正在运行
T 进程的暂停状态,一般都是由运行状态状态转换而来,等待某种特殊处理,如调试跟踪的程序,每执行到一个断点,就转入暂停状态,等待新的输入信号.
S 进程可中断的睡眠模式 (可中断,就是程序接收到一种信号后可以改变到另一种状态)
Z 代表改进程目前为 zombie 状态.(僵尸状态)
D 进程进入无法中断的睡眠模式.(不可中断,是因为硬件资源无法满足,不能被信号唤醒.必须等到所等 到等待的资源得到之后才能被唤醒) IO引起的
< 代表为高优先级
N 代表为低优先级
l 多线程
L 锁在内存中,防止和虚拟内存交换
s 会话,后台进程组
+ 前台进程组
START:进程启动时间
TIME:进程占用CPU的时间
COMMAND:进程名字
init:内核启动的第一个用户级进程
二.pstree
查询进程的层次关系
三.top 时时监视进程状态
PRI 内核调度的优先级(不可随意调整)
NI nice值(我们管理员用调整NI的值来影响PRI的值)
怎么管理进程
# kill -l
查看信号量
1) SIGHUP 9) SIGKILL 15) SIGTERM
1.重新开始运行该进程
9.强制杀死
15.正常退出,正常结束
kill PID kill后接的是进程id
killall mysqld killall后接的是进程名字
sudo fuser -k 80/tcp 关闭占用80端口的程序
进程的前后台切换
sleep 500 & 把进程放到后台
jobs 查看后台有哪些进程
CTRL+Z 暂停前台进程放到后台
bg %1 启动后台进程
fg %1 将后台进程切换到前台
1是后台进程顺序号 可以用jobs查看
kill %1 杀死后台任务号为1的进程
1.1.13 - 权限
chmod
权限常用人群代替字母
u 用户
g 组内其他用户
o 其他用户
a 所有人群
单独指定某一类用户权限例如
chmod u+x,o+x file1 给用户添加执行权限,给用户同组用户添加执行权限
+x表示添加执行权限
-x表示删除执行权限
a+x 表示 u g o 都添加执行权限
r: 4
w: 2
x: 1
chmod rwxrwxrwx file2 = chmod 777 file3 给所有人设置777权限
推荐前面的方式,不用算数字避免出错
acl权限
1.设置权限
setfacl -m u:user1:rwx feil1
给用户--user1分配读写执行权限
setfacl -m o:user1:rwx file1
给user1组成员设置rwx权限
实际的一个例子
Setfacl –m u:mysql:rwx –R /usr/local/mysql
Setfacl –m d:u:mysql:rwx –R /usr/local/mysql
用acl来让mysql用户对/usr/local/mysql目录具有所有权限
因为mysql目录是数据库来操作只需要让这个目录的执行者具有权限即可
2.获得指定文件权限
getfacl -e file 或者(getfacl 文件名/目录名)
3.删除某一个acl权限
setfacl -x u:user1 file1--对user1用户删除当前目录下file1文件的权限
4.删除所有acl权限
setfacl -b file
5.设置acl的默认权限
setfacl -m d:u:user1:rwx test
#当前目录的子目录会集成目录的acl权限
特殊权限
前面我们学习过linux的基本权限,但如果只有基本权限,可能无法满足各式各样的要求
例如:建立一个公共目录 任何人都可以在目录里建立自己的文件,但只能删除自己的文件,此时基本权限就无能为力了.
如果你想要完成这种需求就必须要借助linux的特殊权限;
这类特殊权限共有三种; suid=4 sgid=2 sticky=1
| suid | sgid | sticky | 模式值 |
|---|---|---|---|
| on | on | on | 7 |
| on | on | off | 6 |
| on | off | on | 5 |
| on | off | off | 4 |
| off | on | on | 3 |
| off | on | off | 2 |
| off | off | on | 1 |
| off | off | off | 0 |
设置方法
chmod u+s filename # 对应suid
chmod g+s filename # 对应sgid
chmod o+t filename # 对应sticky
chmod 4755 filename 其中第一位的4 作用和 chmod u+s 一样
那现在来看下第一个特殊权限 SUID=4
限定:只能设置在二进制可执行程序上,对目录无效和文本无效
功能:不管谁来执行程序,linux都以程序的拥有者身份进入权限获取流程中从而决定存取权限,相当于权限下发
特征:在uesr位的x显示为S或s,s代表包含了x权限,S代表未包含x权限
试验演示:
试验一: 用户修改密码借助root身份
# ll /usr/bin/passwd
-rwsr-xr-x 1 root root /usr/bin/passwd
# chmod u-s /usr/bin/passwd
# ll /usr/bin/passwd
-rwxr-xr-x 1 root root /usr/bin/passwd
# su - aming
$ passwd
Changing password for user seker.
Changing password for seker
(current) UNIX password:
passwd: Authentication token manipulation error
$
试验二:用户无法读取/etc/shadow,借用root身份使用cat命令则可
# ll /etc/shadow
---------- 1 root root /etc/shadow
# su - aming
$ cat /etc/shadow
cat: /etc/shadow: 权限不够
$ exit
logout
# chmod u+s /bin/cat
# su - aming
$ cat /etc/shadow
root:$1$EV/a2BnK$pRN0qjwqLf8zvpK8w1MFT.:14360:0:99999:7:::
了解了SUID,我们再来看看SGID=2
限定:SGID既可以作用于二进制文件又可以作用于目录,但两者的意义却截然不同
功能:
先说在二进制文件上,与前面讲的SUID类似:不管是谁来执行,都以文件的所属组身份来决定权限
大家自己测试,跟suid一样
再说作用于目录上:默认情况下用户建立文件时,文件的所属组是用户的主组,如果在设置了SGID目录下建立文件,则文件的所属组是继承目录的属组,并且新建立的目录也继承g+s权限
特征:在group位的x显示为S或s,s代表包含了x权限,S代表未包含x权
试验一:
# mkdir /public
# chmod 777 /public
# chmod g+s /public
# su - lishiming
$ cd /public
$ mkdir lishiming
$ ls -l lishiming -d
-rwxr-xr-x 1 lishiming root lishiming
$ touch sgid_yes
$ ll sgid_yes
-rw-rw-r-- 1 lishiming root sgid_yes
sticky 冒险位(黏贴位)=1
限定:只作用于目录
功能:任何人都可以在一个目录下建立文件,却只有root和建立者本人才可以删除文件
特征:在other位的x显示为T或t,t代表包含了x权限,T代表未包含x权限
# chmod o+t /public
drwxrwxrwt 5 root root /public
# su - lishiming
$ cd /public
-rw-r--r-- 1 leiqin leiqin test-file
$ rm -rf test-file
rm: 无法删除 “test-file”: 不允许的操作 (充分说明lishiming这个账户在/public目录下无法删除leiqin这个用户的文件,虽然/public的目录权限是777)
试验一: 请童鞋们自己去创建一个目录/opt/public,让任何人都能在这个目录下创建文件和目录,但只有创建者本人和root可以删除,其他人没有权限
设定方法:
chmod u+s file
chmod g+s dir/file
chmod o+t dir
修改文件的特殊属性
命令 : chattr
语法: chattr [+-=][ASaci [文件或者目录名]
‘+-=’ : 分别为增加、减少、设定
‘A’ : 增加该属性后,文件或目录的atime将不可被修改;
‘S’ : 增加该属性后,会将数据同步写入磁盘中;
‘a’ : 增加该属性后,只能追加不能删除,非root用户不能设定该属性;
‘c’ : 自动压缩该文件,读取时会自动解压;
‘i’ : 增加后,使文件不能被删除、重命名、设定链接接、写入、新增数据;
lsattr
该命令用来读取文件或者目录的特殊权限,语法为 lsattr [-aR] [文件/目录名]
‘-a’ : 类似与ls 的-a 选项,即连同隐藏文件一同列出;
‘-R’ : 连同子目录的数据一同列出
[root@localhost ~]# lsattr test2
-----a-------e- test2/test1
----i--------e- test2/test3
-------------e- test2/test4
[root@localhost ~]# lsattr -aR test2
----i--------e- test2/.
-----a-------e- test2/test1
-------------e- test2/..
----i--------e- test2/test3
-------------e- test2/test4
1.1.14 - 时间日期
查看时间
timedatectl status
date (只查看本地事件)
设置时区
找到相应的时区文件 /usr/share/zoneinfo/Asia/Shanghai,用这个文件替换当前的/etc/localtime文件。
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
或
timedatectl set-timezone Asia/Shanghai (立即生效)
日期设定成2007年6月28日
date -s 06/28/2007
系统时间设定成下午4点40分0秒
date -s 16:40:00
日期时间设置到 2007年6月28日 下午4点40分0秒
date -s “2007-06-28 16:40:00”
同步BIOS时钟,强制把系统时间写入CMOS,没试过
命令:#clock -w
本地时间写入硬件时间(立即生效)
timedatectl set-local-rtc 1
同步时间服务器
ntpdate time.windows.com
NTP时间服务器:
#最常见、熟知的就是,www.pool.ntp.org/zone/cn
cn.ntp.org.cn #中国
edu.ntp.org.cn #中国教育网
ntp1.aliyun.com #阿里云
ntp2.aliyun.com #阿里云
cn.pool.ntp.org #最常用的国内NTP服务器
查看硬件时间(好像centos有效,ubuntu无效)
hwclock –show
1.1.15 - 网络管理
- 下载
wget -P path http://url
- 流量监控 nload
# 会监控所有网卡, 下一页 右方向、pageDown、回车 上一页 左方向、pageUp
sudo nload
# 只监控单个网卡
sudo nload 网卡名称
- 防火墙
- 关闭selinux
sudo vi /etc/selinux/config
SELINUX=disabled
# 重启
2. iptables
```shell
查看状态 ----- iptables -L
清空防火墙策略 ----- iptables -F
保存防火墙策略 ----- service iptables save
开放docker0网卡的所有访问? ----- firewall-cmd --permanent --zone=trusted --change-interface=docker0
开放端口 ----- firewall-cmd --zone=public --add-port=8888/tcp --permanent
- 配置静态ip Ubuntu netplan
#!/bin/bash
# ip 地址示例 192.168.44.10/24
IPADDR=192.168.44.11/24
# 网关示例 192.168.44.2
GATEWAY=192.168.11.2
# 网卡名称
ETH=ens33
# 配置网络
sudo tee /etc/netplan/00-installer-config.yaml << EOF
network:
ethernets:
${ETH}:
addresses:
- ${IPADDR}
nameservers:
addresses:
- 114.114.114.114
- 8.8.8.8
search: []
routes:
- to: default
via: ${GATEWAY}
version: 2
renderer: networkd
EOF
sudo netplan apply
1.1.16 - 文本操作
sed、awk、grep,这也是linux命令过滤转换输出最精华的三条命令
三剑客之一 grep/egrep
语法: grep [-cinvABC] ‘word’ filename
-c :打印符合要求的行数
-n :在输出符合要求的行的同时连同行号一起输出
-v :打印不符合要求的行(就相当于取反输出)
-A :后跟一个数字(有无空格都可以),例如 –A2则表示打印符合要求的行以及下面两行
-B :后跟一个数字,例如 –B2 则表示打印符合要求的行以及上面两行
-C :后跟一个数字,例如 –C2 则表示打印符合要求的行以及上下各两行
-r : 会把目录下面所有的文件全部遍历
-w : 精确匹配
例子介绍
# 过滤出带有某个关键词的行并输出行号 -----
grep -n 'root' 1.txt
# 过滤出不带有某个关键词的行并输出行号 -----
grep -n -v 'root' 1.txt
# 过滤出所有包含数字的行 -----
grep '[0-9]' 1.txt
# 过滤出所有不包含数字的行 -----
grep -v '[0-9]' 1.txt
# 去除所有以'#'开头的行
grep ----- -v '^#' 1.txt
# 去除所有空行和以'#'开头的行 -----
grep -v '^$' 1.txt|grep -v '^#'
# 过滤出以英文字母开头的行 -----
grep '^[a-zA-Z]' 1.txt
# 过滤出以非数字开头的行 -----
grep '^[^0-9]' 1.txt
# 过滤任意一个或多个字符 -----
# . 表示任意一个字符;
# *表示零个或多个前面的字符 ;
# .*表示零个或多个任意字符,空行也包含在内
grep 'r.o' 1.txt; grep 'r*t' 1.txt; grep 'r.*t' 1.txt
# 指定过滤字符次数 -----
grep 'o\{2\}' 1.txt
# 过滤域名 -----
grep -o '(http://|https://)(\w+\.){2}\w+' 文件名
# 同时过滤单双引号 -----
grep "\<src\>" index.html |grep -o "\<src=['|\"]([^[:space:]])*[^[:space:]]['|\"]"
# 精确匹配 -----
grep filename -w root
grep filename \<root\>
文件内容如下
root
file1
file2
root2
root3
egrep
egrep工具 是grep工具的扩展 egrep ‘o+’ 1.txt 表示1个或1个以上前面字符 egrep ‘o?’ 1.txt 表示0个或者1个前面字符 egrep ‘roo|body’ 1.txt 匹配roo或者匹配body egrep ‘r(oo)|(at)o’ 1.txt 用括号表示一个整体 egrep ‘(oo)+’ 1.txt 表示1个或者多个 ‘oo’
. * + ? 总结
. 表示任意一个字符(包括特殊字符) * 表示零个或多个*前面的字符 .* 表示任意个任意字符(包含空行) + 表示1个或多个+前面的字符 ? 表示0个或1个?前面的字符 其中,+ ? grep不支持,egrep才支持。
grep -q 用于if 逻辑判断很好用。
-q 参数,本意是 Quiet; do not write anything to standard output. Exit immediately with zero status if any match is found, even if an error was detected. 中文意思为,安静模式,不打印任何标准输出。 如果有匹配的内容则立即返回状态值0。
小应用
cat a.txt
nihao
nihaooo
hello
# 输出 yes
if grep -q hello a.txt ; then
echo yes;
else
echo no;
fi
# 输出 no
if grep -q word a.txt; then
echo yes;
else
echo no;
fi
三剑客之二 sed
案例
# 01. 打印指定行 -----
sed '10'p -n 1.txt; sed '1,4'p -n 1.txt; sed '5,$'p -n 1.txt
# 02. 打印包含某个字符串的行 -----
sed -n '/root/'p 1.txt 可以使用 ^ . * $等特殊符号
# 03. -e 可以实现同时进行多个任务 -----
sed -e '/root/p' -e '/body/p' -n 1.txt 也可以用;实现
sed '/root/p; /body/p' -n 1.txt
# 04. 删除行 -----
sed '/root/d' 1.txt; sed '1d' 1.txt; sed '1,10d' 1.txt
# 05. 替换 -----
sed '1,2s/ot/to/g' 1.txt, 其中s就是替换的意思,g为全局替换,否则只替换第一次的,/也可以为 #, @ 等
# 06. 删除所有数字 -----
sed 's/[0-9]//g' 1.txt
# 07. 删除所有非数字 -----
sed 's/[^0-9]//g' 1.txt
# 08. 调换两个字符串位置 -----
head -n2 1.txt |sed 's/\(root\)\(.*\)\(bash\)/\3\2\1/'
# 09. 直接修改文件内容 -----
sed -i 's/ot/to/g' 1.txt
# 10. 把文件中没一行都复制一行 -----
sed 's/.*/&\n&/' 文件名
# 11. 把每两行的第一行开头添加'"' 结尾添加'_R:channel",'
sed 's/.*/"&_R:channel",\n"&_W:channel",/' rw1(文件名)
文件内容如下
Dalitek/JINGKONG/-2F DONG CHEWEI+DONG CHEDAOZHONGJIAN
Dalitek/JINGKONG/-2F DONG CHEDAO
Dalitek/JINGKONG/-2F BEI CHEDAO
Dalitek/JINGKONG/-2F -3PODAO
Dalitek/JINGKONG/-2F CHEWEIDENG NEI 1
Dalitek/JINGKONG/-2F CHEDAODENG
Dalitek/JINGKONG/-2F CHEWEIDENG NEI 2
Dalitek/JINGKONG/-2F ZHONGJIAN CHEWEIDENG
Dalitek/JINGKONG/-2F NAN PODAO DAO-3
Dalitek/JINGKONG/-2F SHANGYE DIANTI DENGDAI
练习
把/etc/passwd 复制到/root/test.txt,用sed打印所有行
打印test.txt的3到10行
打印test.txt 中包含 'root' 的行
删除test.txt 的15行以及以后所有行
删除test.txt中包含 'bash' 的行
替换test.txt 中 'root' 为 'toor'
替换test.txt中 '/sbin/nologin' 为 '/bin/login'
删除test.txt中5到10行中所有的数字
删除test.txt 中所有特殊字符(除了数字以及大小写字母)
把test.txt中第一个单词和最后一个单词调换位置
把test.txt中出现的第一个数字和最后一个单词替换位置
把test.txt 中第一个数字移动到行末尾
在test.txt 20行到末行最前面加 'aaa:'
三剑客之二 awk
案例
# 截取文档中的某段
awk -F ':' '{print $1}' 1.txt
# 也可以使用自定义字符连接每个段
awk -F':' '{print $1"#"$2"#"$3"#"$4}' 1.txt
# 匹配字符或字符串
awk '/oo/' 1.txt
# 针对某个段匹配
awk -F ':' '$1 ~/oo/' 1.txt
# 多次匹配
awk -F ':' '/root/ {print $1,$3}; $1 ~/test/; $3 ~/20/' 1.txt
# 条件操作符==, >,<,!=,>=;<=
awk -F ':' '$3=="0"' 1.txt;
awk -F ':' '$3>="500"' 1.txt;
awk -F ':' '$7!="/sbin/nologin"' 1.txt;
awk -F ':' '$3<$4' 1.txt ;
awk -F ':' '$3>"5" && $3<"7"' 1.txt
awk -F ':' '$3>"5" || $7=="/bin/bash"' 1.txt
# awk内置变量 NF(段数) NR(行数)
head -n3 1.txt | awk -F ':' '{print NF}'
head -n3 1.txt | awk -F ':' '{print $NF}'
head -n3 1.txt | awk -F ':' '{print NR}'
# 打印20行以后的行awk 'NR>20' 1.txt
awk -F ':' 'NR>20 && $1 ~ /ssh/' 1.txt
# 更改某个段的值
awk -F ':' '$1="root"' 1.txt
# 数学计算, 把第三段和第四段值相加,并赋予第七段
awk -F ':' '{$7=$3+$4; print $0}' 1.txt
# 计算第三段的总和
awk -F ':' '{(tot=tot+$3)}; END {print tot}' 1.txt
# awk中也可以使用if关键词
awk -F ':' '{if ($1=="root") print $0}' 1.txt
双引号:
awk '{print "\""}' #放大:awk '{print " \" "}'
使用""双引号把一个双引号括起来,然后用转义字符\对双引号进行转义,输出双引号。
单引号:
awk '{print "'\''"}' # 放大: awk '{print " ' \ ' ' " }'
使用一个双引号"",然后在双引号里面加入两个单引号'',接着在两个单引号里面加入一个转义的单引号\',输出单引号。
awk练习题
用awk 打印整个test.txt (以下操作都是用awk工具实现,针对test.txt)
查找所有包含 'bash' 的行
用 ':' 作为分隔符,查找第三段等于0的行
用 ':' 作为分隔符,查找第一段为 'root' 的行,并把该段的 'root' 换成 'toor' (可以连同sed一起使用)
用 ':' 作为分隔符,打印最后一段
打印行数大于20的所有行
用 ':' 作为分隔符,打印所有第三段小于第四段的行
用 ':' 作为分隔符,打印第一段以及最后一段,并且中间用 '@' 连接 (例如,第一行应该是这样的形式 'root@/bin/bash' )
用 ':' 作为分隔符,把整个文档的第四段相加,求和
1.1.17 - 文件和目录
查:(ls,cat,more,less,head,tail,rev,tac,find, stat)
ls -a 查看目录中所有的文件,包括隐藏文件(以.开头的)
ls -l 查看目录中文件的详细信息
ls -t 以时间先后顺序显示结果
ls -h 显示文件大小
ls -d 查看目录信息
ls -i 显示inode节点
cat 查看文件文件,只显示最后一页,例如cat /etc/passwd
more 分屏显示,按空格键翻页,无法前翻
less 可上下滚动查看文件内容
head 默认只显示前10行
head -20 /etc/passwd 显示前20行
tail 默认显示最后10行
tail -20 /etc/passwd 显示最后20行
rev 使文件内容左右颠倒
tac 使文件内容前后颠倒
ls -l /bin/bash
-rwxr-xr-x 1 root wheel 430540 Dec 23 18:27 /bin/bash
第一部分需要拆开 这里只讲第一个 短横线, 后面的九个字符查看权限部分 - rwx r-x r-x
-: 文件类型
d: 目录
l:链接文件
c: 专门设备文件
b: 块设备文件
p: 先进先出
s: 套接字文件
查找find
查找文件或目录 ----- find 目标目录 -name 文件名
一次查找多个文件(添加-o参数) ----- find / -name 1.txt -o -name 2.txt -o -name 3.txt ...
查找指定类型 ----- find /tmp/ -type d(f, b, c, d, l, s)
查找指定大小 ----- find /root/ -size 1M 注意文件要大写
+1M 显示大于1M
-1M 显示小于1M
查找指定拥有者|组 ----- find /root/ -user jingwang 查找jingwang的文件
find /root/ -group 运行维护 查找运行维护组的文件
访问或执行时间大于/小于n天的文件 ----- find 目标目录 -atime +n/-n
写入、更改inode属性(例如更改所有者、权限或者链接)时间大于/小于n天的文件
----- find 目标目录 -ctime +n/-n
写入时间大于/小于n天的文件 ----- find 目标目录 -mtime +n/-n
/var/ 目录下,最近一天内变更的文件 ----- find /var/ -type f -mtime -1
/root/ 目录下一小时内变更的文件 改变了的是默认天time为分min(还有 -maxdepth -mindepth -mmin -mount -mtime)
----- find /root/ -type f -mmin -60 同样是m修改 改变了的是默认天time为分min
搜索以 '.rpm' 结尾的文件,忽略光驱、捷盘等可移动设备 ----- find / -xdev -name \*.rpm
查找结果执行指令连用
find /path/ -name "param" -exec rm -f {} \; 注意这里的是反斜杠
find /path/ -name "param" -ok rm -f {} \; 更有好的交互方式
查看文件|目录属性 ----- stat 目录|文件
文件的 Access time也就是 ‘atime’ 是在读取文件或者执行文件时更改的。
文件的 Modified time也就是 ‘mtime’ 是在写入文件时随文件内容的更改而更改的。
文件的 Create time也就是 ‘ctime’ 是在写入文件、更改所有者、权限或链接设置时随inode的内容更改而更改的。
因此,更改文件的内容即会更改mtime和ctime,但是文件的ctime可能会在 mtime 未发生任何变化时更改,
例如,更改了文件的权限,但是文件内容没有变化。
增:(mkdir ,touch,vim)
mkdir aminglinux 创建一个aminglinux目录
mkdir a b c 依次在当前目录下创建a b c 同级目录
mkdir -p aa/bb/cc 递推创建aa bb cc目录,aa目录包含bb,bb目录包含cc
touch a.txt 创建一个a.txt文件
删:(cp, mv,rm)
cp a b 将文件a复制一份成b
cp -r 复制目录,默认不加-r只能复制文件
mv 移动或改名
rm 删除文件
rm -r 删除目录,默认不加-r只能删除文件
rm -f 强制删除,不提示
改(查看权限部分):(chown)
语法: chown [ -R ] 账户名 文件名 chown [ -R ] 账户名:组名 文件名
链接
## 硬链接
ln 源文件或目录 目标文件或目标目录
linux会在文件的存放目录中(data_block)添加一个新的文件名
而指向的inode编号与原始文件的inode编号相同.
原始数据始终都是只有一份,只是两个文件名同时引用了一个inode编号
## 软连接
ln -s 源文件或目录 目标文件或目标目录
linux会在文件的存放目录中(data_block)添加一个新的文件名
同时inode编号也全新的,只是新的inode中记录的是原始文件的路径名称
硬链接和软连接的差别
1. inode 硬链接不产生新的inode,软链接则会使用一个新的inode
2. 限制 硬链接只能作用于文件,且不能跨分区;软链接即可作用于目录又可以是文件,可跨分区
3. 删除 删除源文件后,硬链接依然可以使用,而软连接则见血
标准linux 目录
/ 根目录
/boot 用于存放系统的启动文件
/var 用于存放系统中经常需要变化的一些文件,例如日志
/home 普通用户的家目录
/root 超级用户的家目录
/bin 用户存放普通用户可执行的命令
/sbin 用户存放超级用户可执行的命令
/etc 用于存放配置文件
/tmp 临时目录
/mnt 挂载目录
/dev 设备文件的目录
/opt 第三方应用软件的安装目录
1.1.18 - 压缩解压缩
压缩和解压
.gz
压缩:gzip FileName
解压缩:gunzip FileName.gz
.bz2
压缩:bzip2 FileName
解压缩:bunzip2 FileName.bz2
.zip
压缩:zip file.zip FileName | 针对目录 zip -r tmp.zip /tmp
解压缩: unzip FileName.zip
tar
压缩: tar -cvf lei.tar passwd fstab shadow
解包: tar -xvf lei.tar
解压到指定目录: tar -xvf lei.tar -C /tmp
查看打包文件中的内容 tar tvf lei.tar
tar已经集成了gzip bzip2 的压缩格式
打包 xxx.tar.gz 的命令 tar -zcvf xxx.tar.gz /etc/init.d/
打包 xxx.tar.bz2 的命令 tar -jcvf xxx.tar.bz2 /etc/init.d/
但是也可以直接 简单的用 程序会自己判断后缀使用相应的方式
tar -cvf xxx.tar.gz /etc/init.d/
tar -cvf xxx.tar.bz2 /etc/init.d/
zip
压缩: zip -r xxx.zip /etc/init.d/
解压缩: unzip xxx.zip
查看压缩包: unzip -l xxx.zip
1.1.19 - 用户管理
用户和用户组分类
用户分为三种以UID来区分
超级用户 UID = 0 在系统中拥有至高无上的权限.
系统用户 UID 1-499 bin,ftp,mail等,不具备登录系统的权利,却是系统运行不可缺少的.
普通用户 UID 500以上 管理员建立的用户.密码和权限都由管理员制定.
超级组 GID = 0
系统组 GID = 1-499
普通组 GID = 500以上
用户相关文件文件位置
- 用户信息 /etc/passwd
早起的linux 在密码列会存储一个加密后的密码,但是现在只是一个标记列了,实际的密码不放在这里了
用户名 密码控位键 用户UID 组GID 用户描述信息 用户家目录 用户默认shell root :x :0 :0 :root :/root :/bin/bash man :x :6 :12 :man :/var/cache/man:/usr/sbin/nologin czhn :x :1000 :1000 :czhn :/home/czhn :/bin/bash
-
用户组信息 /etc/group 用户名 密码密码空位 组id 附属组(加入的其他组) koala :x :1000 : infra :x :1002 :prometheus,grafana,loki,pigstyuser,dba
-
真正的密码 /etc/shadow 用户 密码 加密方式 加密盐 加密迭代次数 密码过期时间 密码锁定时间 密码创建时间 密码修改时间 user1 :$6$ZWqoztNi$8DZaXNASfMPUvK8q8WlgvlaXOqEfQxkEOO/NZSQ.hq3LPGZMyj61aqxwiP02W3BcZ.eJvlZWoaYUg8RJsdg4m1:16352:0:99999:7::: user2 :!! (说明没有密码) user3 :! (用户被禁用)
用户管理命令
添加用户
-
useradd 用户名 useradd 是一个低级命令,更底层。适合精细控制的场景 相关参数 -u UID -d 家目录目录 一般用-d 就不用-m了 两个用一个就行 -m 自动创建家目录 -g GID -c 用户描述信息 -s 默认shell -p 密码
-
adduser 用户名 adduser 是一个高级命令,适合一般场景
在centos中这两个命令差不多, 在Ubuntu中 adduser 命令是一个交互命令
-
将用户名添加到sudo组中,使他具有sudo 权限,现代的发行版中大多数使用这个方式进行sudo赋权 sudo usermod -aG sudo 新用户名
-
免密执行sudu
在 /etc/sudoers.d 目录添加文件
这个文件最好和用户名一致
例如用户名叫 user1 那么文件名就是 user1写入
%user1 ALL=(ALL) NOPASSWD:ALL
修改用户密码
passwd user1
修改用户属性
usermod 修改用户属性命令 -u UID -d 家目录 -g GID -s 指定用户shell -L 禁用用户user1 -U 启用用户user1
删除用户
userdel -r 删除用户及用户家目录
切换用户
su - user1 会修改到user1的环境变量
su user1 不会修改环境变量
sudo su 不需要密码切换到root用户
登录后的检查
whoami 查看当前用户身份 who 查看登录本机用户及来源ip w 查看登录用户在做什么 id 查看用户和查看用户所属的组 users 都有哪些登录用户
koala@HomeName:/path$ id koala
uid=1000(koala) gid=1000(koala) groups=1000(koala),4(adm),20(dialout),24(cdrom),25(floppy),27(sudo),29(audio),30(dip),44(video),46(plugdev),100(users),107(netdev),1001(docker)
koala@HomeName:/path$ users
koala
koala@HomeName:/path$ w
15:09:06 up 15:07, 2 users, load average: 0.01, 0.04, 0.00
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
koala 10.0.8.24 08:54 15:48m 0.00s 0.02s sshd: koala [priv]
koala pts/1 - Mon23 15:48m 0.01s 0.01s -bash
koala@HomeName:/path$ who
koala pts/1 2025-05-19 23:21
koala@HomeName:/path$ whoami
koala
组管理命令
组添加
groupadd 组名称
groupadd -g 组编号 组名称
删除组
groupdel 组名称
管理组
用法:gpasswd[-a user][-d user][-A user,...][-M user,...][-r][-R]groupname
参数:
-a:添加用户到组
-d:从组删除用户
-A:指定管理员
-M:指定组成员和-A的用途差不多
-r:删除密码
-R:限制用户登入组,只有组中的成员才可以用newgrp加入该组
把user1用户加入到用户组group1 ----- gpasswd -a user1 group1
把user1用户从group1组中删除 ----- gpasswd -d user1 group1
物理机 忘记root密码
可以进单用户模式,方法为:
重启Linux系统,出现"5秒之内要按一下回车"的界面,然后输入字母"e",
选择第二行按字母"e"进入编辑模式,将光标移动到末尾输入"single"或数字"1"或字母"s",回车,
最后按字母"b"来启动.进入单用户模式,然后输入修改root密码的命令:passwd,修改好后重启系统就ok了
直接设置root密码, 不需要控制台交互
-
这个应该是红帽能用,不过没试过 echo “redhat” | passwd –stdin root
-
在ubuntu22.04实战使用过 echo “root:soft01”|chpasswd
1.2 - Ubuntu
1.2.1 - gdm3和lightdm切换
# 切换 gdm3
sudo dpkg-reconfigure gdm3
# 切换 lightdm
sudo dpkg-reconfigure lightdm
1.2.2 - netplan
-
在 Ubuntu20.04 版本中使用 netplan 管理网络
-
在安装好的 Ubuntu20.04 中没有 networking 和 NetworkManage 服务
-
netplan 配置文件:/etc/netplan/*.yaml ,文件名每个不一样
-
netplan 说明文件: /usr/share/doc/netplan/example/ 目录下,在该目录下有各种样例文件,可以提供帮助
1.2.3 - Ubuntu桌面版设置随机Mac地址
-
首先右键单击network-manager管理工具,点左键 Edit Connections
-
点选要配置的连接,点下面的齿轮
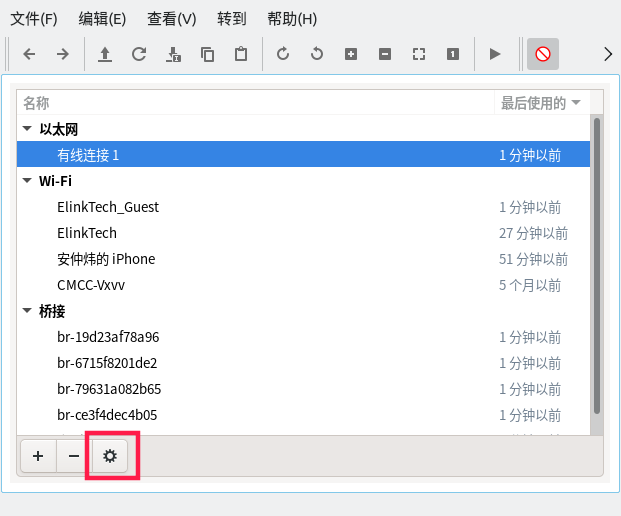
-
红框位置选随机, 保存即可
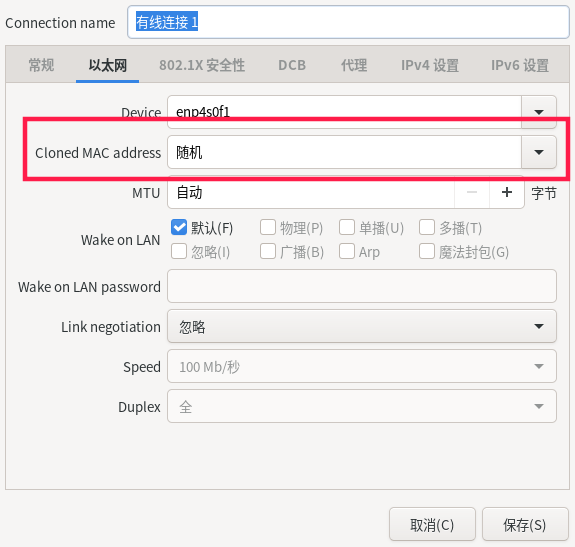
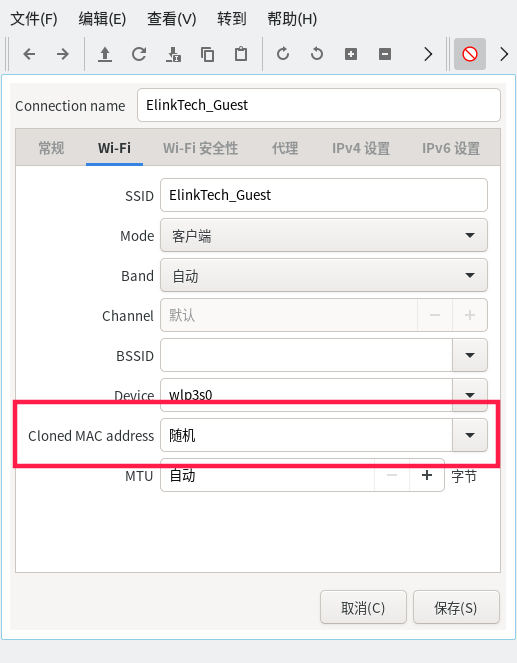
1.2.4 - 报错处理
由于没有公钥,无法验证下列签名
W: GPG 错误:http://ppa.launchpad.net precise Release: 由于没有公钥,无法验证下列签名: NO_PUBKEY 6AF0E1940624A220
W: 无法下载 bzip2:/var/lib/apt/lists/partial/mirrors.163.com_ubuntu_dists_precise_main_binary-i386_Packages Hash 校验和不符
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 6AF0E1940624A220 #此处6AF0E1940624A220需要是错误提示的key
ssh无法连接到外网Linux主机
场景描述:
内网Linux主机ssh连接正常,不能ssh连接外网Linux
telnet 外网IP 22 通,ping命令通
此时可以试试以下方法
koala@koala:~$ ssh root@domain.com
(等待很久)Connection closed by xx.xx.xx.xx port 22
koala@koala:~$ ssh -v root@domain.com
OpenSSH_8.4p1, OpenSSL 1.1.1f 31 Mar 2020
debug1: Reading configuration data /usr/local/etc/ssh_config
debug1: Authenticator provider $SSH_SK_PROVIDER did not resolve; disabling
debug1: Connecting to domain.com [xx.xx.xx.xx] port 22.
debug1: Connection established.
debug1: identity file /home/koala/.ssh/id_rsa type 0
debug1: identity file /home/koala/.ssh/id_rsa-cert type -1
debug1: identity file /home/koala/.ssh/id_dsa type -1
debug1: identity file /home/koala/.ssh/id_dsa-cert type -1
debug1: identity file /home/koala/.ssh/id_ecdsa type -1
debug1: identity file /home/koala/.ssh/id_ecdsa-cert type -1
debug1: identity file /home/koala/.ssh/id_ecdsa_sk type -1
debug1: identity file /home/koala/.ssh/id_ecdsa_sk-cert type -1
debug1: identity file /home/koala/.ssh/id_ed25519 type -1
debug1: identity file /home/koala/.ssh/id_ed25519-cert type -1
debug1: identity file /home/koala/.ssh/id_ed25519_sk type -1
debug1: identity file /home/koala/.ssh/id_ed25519_sk-cert type -1
debug1: identity file /home/koala/.ssh/id_xmss type -1
debug1: identity file /home/koala/.ssh/id_xmss-cert type -1
debug1: Local version string SSH-2.0-OpenSSH_8.4
debug1: Remote protocol version 2.0, remote software version OpenSSH_7.4
debug1: match: OpenSSH_7.4 pat OpenSSH_7.0*,OpenSSH_7.1*,OpenSSH_7.2*,OpenSSH_7.3*,OpenSSH_7.4*,OpenSSH_7.5*,OpenSSH_7.6*,OpenSSH_7.7* compat 0x04000002
debug1: Authenticating to domain.com:22 as 'root'
debug1: SSH2_MSG_KEXINIT sent
debug1: SSH2_MSG_KEXINIT received
debug1: kex: algorithm: curve25519-sha256
debug1: kex: host key algorithm: ecdsa-sha2-nistp256
debug1: kex: server->client cipher: chacha20-poly1305@openssh.com MAC: <implicit> compression: none
debug1: kex: client->server cipher: chacha20-poly1305@openssh.com MAC: <implicit> compression: none
debug1: expecting SSH2_MSG_KEX_ECDH_REPLY
Connection closed by xx.xx.xx.xx port 22
此时查看本机mtu值
koala@koala:~$ netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
br-19d23 1500 0 0 0 0 0 0 0 0 BMU
br-79631 1500 0 0 0 0 212 0 0 0 BMRU
docker0 1500 0 0 0 0 0 0 0 0 BMU
enp4s0f1 1500 0 0 0 0 0 0 0 0 BMU
lo 65536 1620 0 0 0 1620 0 0 0 LRU
veth9e8a 1500 0 0 0 0 239 0 0 0 BMRU
vmnet1 1500 0 0 0 0 222 0 0 0 BMRU
vmnet8 1500 0 0 0 0 223 0 0 0 BMRU
wlp3s0 1492 68412 0 0 0 23095 0 0 0 BMRU
测试mtu合理值
ping -s 1444 -M do baidu.com
#错误时
$ ping -s 1472 -M do baidu.com
PING baidu.com (220.181.38.148) 1472(1500) bytes of data.
ping: local error: message too long, mtu=1492
ping: local error: message too long, mtu=1492
ping: local error: message too long, mtu=1492
#正确时
$ ping -s 1464 -M do baidu.com
PING baidu.com (220.181.38.148) 1464(1492) bytes of data.
1452 比特,来自 220.181.38.148 (220.181.38.148): icmp_seq=1 ttl=52 时间=18.6 毫秒
1452 比特,来自 220.181.38.148 (220.181.38.148): icmp_seq=2 ttl=52 时间=18.2 毫秒
1452 比特,来自 220.181.38.148 (220.181.38.148): icmp_seq=3 ttl=52 时间=18.3 毫秒
1452 比特,来自 220.181.38.148 (220.181.38.148): icmp_seq=4 ttl=52 时间=18.2 毫秒
找到一个阈值, 1464(1492) 1492就是要设置本机mtu的值
设置mtu
#1、设置本机的mtu,即时生效,重启后失效
ifconfig eth0 mtu 1492 up #up可加可不加
#2、永久生效的修改方法,缺点是需要重启网卡
ubuntu 服务器是使用netplan管理网络不是networkmanager
#service network restart 重启网卡
tips: 一般以太网MTU都为1500, 在pppoe拨号路由中,会有8字节gre包装头,linux貌似是解析不了
ubuntu apt-get 错误 Temporary failure resolving ‘us.archive.ubuntu.com’ 解决
原因是dns没有配置,解决办法 加入dns服务器地址:
vi /etc/resolv.conf
1.2.5 - 替换清华源
Ubuntu24.04 以后 默认源在 /etc/apt/sources.list.d/ubuntu.list 文件里
https://mirrors4.tuna.tsinghua.edu.cn/help/ubuntu/
方式一 sed替换
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
sudo sed -i "s@http://.*archive.ubuntu.com@https://mirrors.tuna.tsinghua.edu.cn@g" /etc/apt/sources.list
sudo sed -i "s@http://.*security.ubuntu.com@https://mirrors.tuna.tsinghua.edu.cn@g" /etc/apt/sources.list
sudo apt update && sudo apt full-upgrade
方式二 配置文件替换
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
echo "正在替换为清华源..."
cat << EOF | sudo tee /etc/apt/sources.list
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-backports main restricted universe multiverse
# 以下安全更新软件源包含了官方源与镜像站配置,如有需要可自行修改注释切换
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-security main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-security main restricted universe multiverse
# 预发布软件源,不建议启用
# deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-proposed main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ jammy-proposed main restricted universe multiverse
EOF
echo "更新..."
sudo apt-get update
1.3 - 报错处理
启动nginx bind() to 0.0.0.0:80 failed (13: Permission denied)
第一种 端口号小于 1024
原因是1024以下端口启动时需要root权限,所以sudo nginx即可
第二种:端口大于1024的情况: 首先,查看http允许访问的端口:
semanage port -l | grep http_port_t
http_port_t tcp 80, 81, 443, 488, 8008, 8009, 8443, 9000
# 这里的原因是selinux的权限配置问题导致的
semanage port -a -t http_port_t -p tcp 8090
2 - Windows
2.1 - WSL
这是关注WSL的实战经验
WSL安装
https://learn.microsoft.com/zh-cn/windows/wsl/install
- wsl –update 下载特别慢的解决方式 到 https://github.com/microsoft/WSL/releases 下载 Latest版本
WSL的配置
-
详见: https://learn.microsoft.com/zh-cn/windows/wsl/wsl-config
-
扫盲 .wslconfig: 位于 window系统 %UserProfile%.wslconfig 配置了WSL中的功能,为WSL2 提供支持的虚拟机设置(RAM、内核数、CPU数等)。它将设置所有的WSL分发版的通用设置 wsl.conf: 位于 具体分发版的 /etc/wsl.conf 。设置例如启动选项、DrvFs 自动装载、网络、与 Windows 系统的互作性、系统使用情况和默认用户
wsl.conf的配置示例
[boot]
# 此选项用于开启systemd功能,开启后可以使用 sudo systemctl 命令 服务 来对服务进行管理
# 默认为 false,如果开启, 需要在 PowerShell 中执行 wsl --shutdown,然后重新启动 WSL 才能生效
systemd=true
# 你希望在 WSL 实例启动时运行的命令字符串。 此命令以根用户身份运行。 例如service docker start。
# 启动设置仅在 Windows 11 和 Server 2022 上可用。
command=service docker start
[automount]
# Set to true will automount fixed drives (C:/ or D:/) with DrvFs under the root directory set above. Set to false means drives won't be mounted automatically, but need to be mounted manually or with fstab.
#true 导致固定驱动器(即 C:/ 或 D:/)自动装载到 DrvFs 中的 /mnt 下。 false 表示驱动器不会自动装载,但你仍可以手动或通过 fstab 装载驱动器。 default true
enabled = true
# Sets the directory where fixed drives will be automatically mounted. This example changes the mount location, so your C-drive would be /c, rather than the default /mnt/c.
#设置固定驱动器要自动装载到的目录。 默认情况下,这设置为 /mnt/ ,因此Windows文件系统 C 驱动器装载到 /mnt/c/ 。 如果更改为 /mnt//windir/ ,应会看到固定 C 驱动器装载到 /windir/c 。default /mnt/
root = /mnt/
# DrvFs-specific options can be specified.
#下面列出了 automount 选项值,并追加到默认的 DrvFs 装载选项字符串中。 只能指定特定于 DrvFs 的选项。default ""
# 以逗号分隔的值列表(如 uid、gid 等),请参阅下面的自动装载选项
# key desc default
# uid 用于所有文件的所有者的用户 ID 首次安装时,WSL (的默认用户 ID 默认为 1000)
# gid 用于所有文件的所有者的组 ID 首次安装时,WSL (的默认组 ID 默认为 1000)
# umask 要对所有文件和目录排除的权限的八进制掩码 000
# fmask 要对所有文件排除的权限的八进制掩码 000
# dmask 要对所有目录排除的权限的八进制掩码 000
# metadata 是否将元数据添加到 Windows 文件以支持 Linux 系统权限 disabled
# case 确定被视为区分大小写的目录以及使用 WSL 创建的新目录是否将设置标志。 off
# 有关选项的详细说明,请参阅区分大小写。
options = "metadata,uid=1003,gid=1003,umask=077,fmask=11,case=off"
# Sets the `/etc/fstab` file to be processed when a WSL distribution is launched.
#true 设置启动 WSL 时要处理的 /etc/fstab。 /etc/fstab 是可在其中声明其他文件系统的文件,类似于 SMB 共享。 因此,在启动时,可以在 WSL 中自动装载这些文件系统。 default true
mountFsTab = true
# Set whether WSL supports interop process like launching Windows apps and adding path variables. Setting these to false will block the launch of Windows processes and block adding $PATH environment variables.
[interop]
#设置此键可确定 WSL 是否支持启动 Windows 进程。default true
enabled = false
#设置此键可确定 WSL 是否会将 Windows 路径元素添加到 $PATH 环境变量。default true
appendWindowsPath = false
# Set the user when launching a distribution with WSL.
[user]
#设置此键指定在首次启动 WSL 会话时以哪个用户身份运行。default 首次运行时创建的初始用户名
default = root
- .wslconfig 这是好几年以前收集的设置。有的可能已经是过时的选项
# Settings apply across all Linux distros running on WSL 2
[wsl2]
# Limits VM memory to use no more than 4 GB, this can be set as whole numbers using GB or MB
# 要分配给 WSL 2 VM 的内存量。 default:Windows 上总内存的 50% 或 8GB,以较小者为准;在 20175 之前的版本上:Windows 上总内存的 80%
memory=4GB
# Sets the VM to use two virtual processors
#要分配给 WSL 2 VM 的处理器数量。 default: Windows 上相同数量的处理器
processors=2
# Specify a custom Linux kernel to use with your installed distros. The default kernel used can be found at https://github.com/microsoft/WSL2-Linux-Kernel
#自定义 Linux 内核的绝对 Windows 路径。default:Microsoft 内置内核提供的收件箱
kernel=C:\\temp\\myCustomKernel
# Sets additional kernel parameters, in this case enabling older Linux base images such as Centos 6
#其他内核命令行参数。default:空白
kernelCommandLine = vsyscall=emulate
# Sets amount of swap storage space to 8GB, default is 25% of available RAM
# 要向 WSL 2 VM 添加的交换空间量,0 表示无交换文件。 交换存储是内存需求超过硬件设备限制时使用的基于磁盘的 RAM。 default:Windows 上 25% 的内存大小四舍五入到最接近的 GB
swap=8GB
# Sets swapfile path location, default is %USERPROFILE%\AppData\Local\Temp\swap.vhdx
# 交换虚拟硬盘的绝对 Windows 路径。 default: %USERPROFILE%\AppData\Local\Temp\swap.vhdx
swapfile=C:\\temp\\wsl-swap.vhdx
# Disable page reporting so WSL retains all allocated memory claimed from Windows and releases none back when free
#默认设置 true 允许Windows回收分配给 WSL 2 虚拟机的未使用内存。
pageReporting=false
# Turn off default connection to bind WSL 2 localhost to Windows localhost
#一个布尔值,用于指定绑定到 WSL 2 VM 中的通配符或 localhost 的端口是否应可通过 localhost:port 从主机连接。 default:true
localhostforwarding=true
# Disables nested virtualization
# 启用或关闭嵌套虚拟化的布尔值,使其他嵌套 VM 在 WSL 2 中运行。 仅适用于Windows 11。 default : true
nestedVirtualization=false
# Turns on output console showing contents of dmesg when opening a WSL 2 distro for debugging
#一个布尔值,用于在 WSL 2 发行版实例启动时打开显示 dmesg 内容的输出控制台窗口。 仅适用于Windows 11。default: false
debugConsole=true
#一个布尔值,用于在 WSL 中打开或关闭对 GUI 应用程序 (WSLg) 的支持。 仅适用于Windows 11。 default : true
guiApplications=true
#VM 在关闭之前处于空闲状态的毫秒数。 仅适用于Windows 11。 default 60000
vmIdleTimeout=60000
2.2 - 杂乱无章的内容
-
从专业版升级到专业工作站版: 管理员模式打开 命令行 slmgr -ipk DXG7C-N36C4-C4HTG-X4T3X-2YV77 此仅用于版本升级, 升级后需要重新激活系统
-
一个可以制作安装包的软件innosetup
-
win10原生配置端口转发
PS C:\WINDOWS\system32> netsh interface portproxy add v4tov4 listenaddress=192.168.0.101(监听哪个ip) listenport=7001(监听哪个端口) connectaddress=192.168.0.80(转发到哪个ip) connectport=8080(转发到哪个端口)
PS C:\WINDOWS\system32> netsh interface portproxy show all
侦听 ipv4: 连接到 ipv4:
地址 端口 地址 端口
--------------- ---------- --------------- ----------
192.168.0.101 7001 192.168.0.80 8080
PS C:\WINDOWS\system32> netsh interface portproxy delete v4tov4 listenaddress=192.168.0.101 listenport=7001
PS C:\WINDOWS\system32> netsh interface portproxy show all
- windows后台运行
# 新建 xxx.vbe脚本
set ws=wscript.createobject("wscript.shell")
ws.run "可执行文件路径",0
-
win11菜单切换 win10 样式 地址: https://gitee.com/azhw/rookiedev-example/blob/master/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/windows/win11%E8%8F%9C%E5%8D%95%E5%88%87%E6%8D%A2.bat
-
清理系统垃圾文件 地址:https://gitee.com/azhw/rookiedev-example/blob/master/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/windows/cleansys.bat
-
为安全考虑,已锁定该用户账户,原因是登录尝试或密码更改尝试过多
- win+R 输入 gpedit.msc
- 在本地组策略编辑器页面中,选择计算机配置 > Windows设置 > 安全设置 > 账户策略 > 账户锁定策略
- 在账户锁定策略页面,双击账户锁定阈值,进入账户锁定阈值 属性窗口。
- 在账户锁定阈值 属性窗口,将账户不锁定阈值修改为0,单击确定。
- 重新使用远程桌面连接Windows实例,确保可以正常连接。
-
在Windows系统上管理系统服务的一些工具介绍
我常用的是 winsw 这里下载了一个版本 https://gitee.com/azhw/rookiedev-example/blob/master/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F/windows/winsw2.12.0%20V2%20latest%E7%89%88%E6%9C%AC.zip
XYNTservice: XYNTservice 是一个开源的软件,它可以将任何可执行文件转换为 Windows 服务。通过 XYNTservice,你可以将你的应用程序注册为 Windows 服务,使其能够在系统启动时自动运行,并以服务的身份在后台运行,而无需用户登录。这对于需要长时间运行或需要在系统启动时自动启动的应用程序来说非常有用。GitHub - dalfa/XYNTService: XYNTService
-----------------------------------------------------------------------------------------------------------------
NSSM (Non-Sucking Service Manager): NSSM 也是一个开源的软件,它提供了一种在 Windows 上管理服务的方式。NSSM 可以将任何可执行文件包装成 Windows 服务,并提供了一些额外的功能,如重启策略、输入/输出重定向、环境变量配置等。NSSM 的目标是提供一种更加灵活和强大的服务管理方式,使得用户可以更方便地配置和管理他们的服务程序。NSSM - the Non-Sucking Service Manager GitHub - xxnuo/Nssm-Chinese: Nssm_ ch - Windows 系统服务管理器 提供GUI管理Win系统服务的添加、修改、删除
-----------------------------------------------------------------------------------------------------------------
WinSW (Windows Service Wrapper): WinSW 也是一个开源的软件,它的设计目标是简化 Windows 服务的创建和管理。WinSW 提供了一个 XML 配置文件来定义服务,支持自动重新启动、定时任务、日志记录等功能,并且可以很容易地集成到现有的应用程序中。使用 WinSW,你可以快速地将你的应用程序打包成 Windows 服务,并且通过配置文件来定义服务的行为。GitHub - winsw/winsw: A wrapper executable that can run any executable as a Windows service, in a permissive license.
-----------------------------------------------------------------------------------------------------------------
srvany: Srvany 是微软提供的一个工具,它可以将任何可执行文件注册为系统服务。使用 Srvany,你可以在注册服务时指定需要运行的可执行文件,以及启动参数等信息。虽然 Srvany 功能比较简单,但对于一些基本的需求来说是一个有效的解决方案。创建用户定义的服务 - Windows Client | Microsoft Learn
-----------------------------------------------------------------------------------------------------------------
sc.exe: sc.exe 是 Windows 系统自带的命令行工具,用于与服务相关的操作。通过 sc.exe,你可以创建、删除、启动、停止、暂停、恢复服务等。虽然 sc.exe 的使用相对较为繁琐,但它是 Windows 系统自带的工具,对于一些简单的服务管理操作来说是一个方便的选择。sc.exe create | Microsoft Learn
-----------------------------------------------------------------------------------------------------------------
FireDaemon: FireDaemon 是一个商业软件,它可以将任何应用程序转换成 Windows 服务。FireDaemon 提供了丰富的功能,如自动重新启动、CPU 亲和性、内存限制等,并且支持远程管理和监控。虽然 FireDaemon 是商业软件,但它提供了免费试用版,可以在一定期限内使用。Run Any Application Program Script as FireDaemon Windows Service
-----------------------------------------------------------------------------------------------------------------
AlwaysUp: AlwaysUp 是另一个商业软件,它可以将任何应用程序转换成 Windows 服务。AlwaysUp 提供了类似于 FireDaemon 的功能,如自动重新启动、CPU 亲和性、内存限制等,并且支持远程管理和监控。与 FireDaemon 不同的是,AlwaysUp 还提供了一些高级功能,如邮件通知、事件日志记录等。https://www.coretechnologies.com/products/AlwaysUp/
-----------------------------------------------------------------------------------------------------------------
Microsoft Windows Services for Unix: Microsoft Windows Services for Unix 是微软提供的一个工具,它可以在 Windows 系统上运行类 Unix 环境下的应用程序。通过 Windows Services for Unix,你可以将类 Unix 环境下的应用程序注册为 Windows 服务,并且在 Windows 系统上以服务的身份运行。Windows Services for Unix 适用于需要在 Windows 系统上运行 Unix 应用程序的场景。
-----------------------------------------------------------------------------------------------------------------
Service Protector: Service Protector 是一个商业软件,它可以确保你的Windows服务始终保持运行状态。它可以监控你的服务,如果服务意外停止,它可以自动重新启动服务,从而确保你的应用程序始终可用。Service Protector 9.0: Easily Import Many Windows Services | The Core Technologies Blog
-----------------------------------------------------------------------------------------------------------------
Instsrv.exe和Srvinstw.exe: 这是微软提供的两个命令行工具,用于安装和卸载服务。通过这两个工具,你可以将可执行程序安装为Windows服务,并且配置服务的相关信息。https://learn.microsoft.com/zh-cn/windows-hardware/get-started/kits-and-tools-overview
-----------------------------------------------------------------------------------------------------------------
AppToService:
将任何应用程序作为Windows服务运行,使其在计算机启动时自动启动,无需登录;在没有人工干预的情况下持续运行24/7;能够在注销/登录过程中保持运行;在后台默默地执行;并能安全地在受保护的账户下运行。
AppToService 可以将任何应用程序作为Windows服务运行 AppToService 是一个Windows控制台应用程序,允许您将程序、脚本、批处理文件、快捷方式及其他类型的应用程序作为Windows服务运行。这样您就可以享受Windows服务带来的一些好处,比如:
在计算机启动时无需用户交互或登录即可启动应用程序。 在后台默默运行,不会干扰用户。 能够在注销/登录过程中继续运行。 在失败时能够自动重新启动。 以指定的用户账户运行,以确保安全性。 AppToService 让任何应用程序像服务一样运行。AppToService - Run applications as Windows services | Basta
要创建一个带有看门狗功能的服务,可以使用以下步骤:
创建服务: 使用适合你的工具(如sc.exe、srvany等)将你的可执行文件注册为Windows服务。确保你的可执行文件能够在服务模式下正确运行。
实现看门狗功能: 在你的可执行文件中实现看门狗功能,定期检测指定进程是否在运行。如果进程不在运行,你的可执行文件应该能够自动重新启动该进程。
这可以通过以下步骤来实现:
在你的可执行文件中使用进程监控机制,例如轮询或订阅进程状态变化的事件。
定期检查指定进程是否在运行。你可以使用进程列表或进程ID等信息来判断进程是否存在。
如果进程不在运行,使用适当的方法(如启动命令行、API调用等)重新启动该进程。
设置定期检测时间间隔: 在你的可执行文件中,设置定期检测进程状态的时间间隔。你可以根据实际需求选择适当的时间间隔,以确保及时检测并重新启动进程。
-----------------------------------------------------------------------------------------------------------------
在 PowerShell 中可以通过以下代码实现上述功能:
powershell
# 指定进程名称和可执行文件路径
$processName = "YourProcessName"
$exePath = "C:\Path\To\YourExecutable.exe"
# 定义函数,检查进程是否在运行
function CheckProcessRunning($processName) {
if(Get-Process | Where-Object {$_.Name -eq $processName}) {
return $true
} else {
return $false
}
}
# 定义函数,启动进程
function StartProcess($exePath) {
Start-Process -FilePath $exePath -ArgumentList "-arg1", "-arg2" -NoNewWindow
}
# 检查进程是否在运行
if(!CheckProcessRunning($processName)) {
# 如果进程不在运行,启动进程
StartProcess($exePath)
}
在上面的代码中,首先指定了要检查的进程名称和重新启动的可执行文件路径。然后定义了两个函数,分别用于检查进程是否在运行和启动进程。最后在代码中使用这两个函数来检查进程状态并重新启动进程(如果需要)。
当然,这只是一种示例方法,具体的实现方式可能因应用程序的要求而有所不同,例如监控进程状态的频率、重新启动进程的方式等。
------------------------------------------------------------------------------------------------------------
在批处理中,可以使用以下代码实现上述功能:
@echo off
REM 指定进程名称和可执行文件路径
set processName=YourProcessName
set exePath=C:\Path\To\YourExecutable.exe
:loop
REM 检查进程是否在运行
tasklist | find /i "%processName%" > NUL
if errorlevel 1 (
REM 如果进程不在运行,启动进程
start "" "%exePath%"
)
REM 设置检测间隔(单位:秒)
timeout /t 60 > NUL
goto loop
在上面的代码中,首先指定了要检查的进程名称和重新启动的可执行文件路径。然后使用一个无限循环来定期检查进程状态。循环中使用 tasklist 命令和 find 命令来检查进程是否在运行,如果进程不在运行,则使用 start 命令重新启动进程。最后使用 timeout 命令来设置检测间隔,以确保及时检测并重新启动进程。
------------------------------------------------------------------------------------------------------------
创建带有看门狗功能的服务的工具有很多,下面列举几个常用的工具:
NSSM(Non-Sucking Service Manager):NSSM 是一个开源的 Windows 服务管理器,可以将任何可执行文件转换为服务。它提供了看门狗功能,可以监控服务的状态,并在服务崩溃或停止时重新启动。
srvany:srvany 是 Windows 平台上的一个实用工具,可以将任何可执行文件注册为服务。虽然它不直接提供看门狗功能,但你可以在自己的可执行文件中实现该功能。
AlwaysUp:AlwaysUp 是一个商业化的 Windows 服务管理工具,提供了丰富的功能,包括看门狗功能。它可以监控服务的运行状态,并在服务停止时自动重启。
FireDaemon:FireDaemon 是另一个商业化的 Windows 服务管理工具,可以将任何应用程序转换为 Windows 服务。它支持看门狗功能,并提供了各种监控和报警选项。
这些工具都提供了更便捷的方式来创建、管理和监控带有看门狗功能的服务。你可以根据自己的需求和预算选择适合你的工具。
https://www.technlg.net/windows/download-windows-resource-kit-tools/