关于编程语言模块的一些介绍
编程语言
- 1: Golang
- 1.1: GolangUtils
- 1.1.1: goroutine
- 1.1.2: Map
- 1.1.3: 表单验证
- 1.1.4: 结构体
- 1.1.5: 进制转换
- 1.1.6: 日期时间函数
- 1.1.7: 数据类型转换
- 1.1.8: 数学函数
- 1.1.9: 文件目录操作函数
- 1.1.10: 系统变量初始化
- 1.1.11: 序列化
- 1.1.12: 整型
- 1.1.13: 字符串函数
- 1.1.14: 字节数组操作([]byte)
- 1.2: 最佳实践
- 1.2.1: 单元测试
- 1.2.1.1: Golang单元测试-wire依赖注入
- 1.2.1.2: Golang单元测试-简单示例
- 1.2.1.3: Golang单元测试01
- 1.2.1.4: Golang单元测试02
- 1.2.1.5: Golang单元测试03
- 1.2.1.6: Golang单元测试04
- 1.2.2: adodb方式连接sqlServer2k
- 1.2.3: AES-ECB-PKCS5
- 1.2.4: base64
- 1.2.5: cbor
- 1.2.6: channel
- 1.2.7: CRC16
- 1.2.8: gorm连接mssql
- 1.2.9: gorose连接mssql
- 1.2.10: go发送get或post请求
- 1.2.11: go脚本编程接受命令行参数
- 1.2.12: hmac算法
- 1.2.13: md5编码
- 1.2.14: modbustcp-client
- 1.2.15: opc-client
- 1.2.16: Post上传文件
- 1.2.17: RSA-encryption
- 1.2.18: stdin-stdout-stderr
- 1.2.19: UDP简单的示例
- 1.2.20: websocket-client
- 1.2.21: xorm连接mssql
- 1.2.22: 遍历字符串
- 1.2.23: 定时执行
- 1.2.24: 读MySQL数据库所有表并输出见表语句
- 1.2.25: 链接sqlserver2008
- 1.2.26: 使用redis
- 1.2.27: 支持RabbitMQ的AMQP
- 1.3: 31个!Golang常用工具
- 1.4: GO基础
- 1.5: 安装
- 1.6: 报错解决
- 2: Java
- 2.1: Java最佳实践
- 2.1.1: AES加解密
- 2.1.2: fastjson
- 2.1.3: Integer比较
- 2.1.4: Java的参数是值传递
- 2.1.5: Optional
- 2.1.6: PDF转图片
- 2.1.7: Serializable序列化
- 2.1.8: SimpleFTPClient
- 2.1.9: Spring专栏
- 2.1.9.1: 多个网卡时指定注册ip段.md
- 2.1.9.2: 如何在pom文件中管理多个环境
- 2.1.9.3: Spring 上传文件的配置
- 2.1.9.4: SpringBoot单元测试
- 2.1.10: Stream API示例
- 2.1.11: String API
- 2.1.12: TryCache到底怎么返回值
- 2.1.13: Valid参数校验
- 2.1.14: ZIPUtils
- 2.1.15: 遍历List
- 2.1.16: 遍历Map
- 2.1.17: 从mybatis的sql日志自动填充sql占位符
- 2.1.18: 代理模式实现
- 2.1.18.1: ByteBuddy动态代理
- 2.1.18.2: CGLIB动态代理
- 2.1.18.3: 动态代理
- 2.1.18.4: 静态代理
- 2.1.19: 定义一个由builder来构造的实体类
- 2.1.20: 多线程
- 2.1.20.1: 方法一: 继承Thread
- 2.1.20.2: 方法二实现Runnable接口
- 2.1.20.3: 方法三实现Callable接口
- 2.1.20.4: 方法四Executors框架
- 2.1.20.5: 线程池
- 2.1.20.6: 线程交替执行的实践
- 2.1.20.7: Callable捕获异常
- 2.1.21: 根据对象层次路径动态获取和设置值
- 2.1.22: 基于BigDecimal的高精度数字运算
- 2.1.23: 基于序列化的深拷贝
- 2.1.24: 时间日期
- 2.1.25: 使用抽象类来实现接口
- 2.1.26: 文件拷贝
- 2.1.27: 下载图片
- 2.1.28: 原生Java发送Post请求
- 2.2: Netty实战
- 2.3: Spring
- 2.3.1: GetSpringBeanUtil
- 2.4: 一文读懂classLoader
- 3: 汇编
- 3.1: 汇编入门
- 3.1.1: 汇编语言入门一:环境准备
- 3.1.2: 汇编语言入门二:环境有了先过把瘾
- 3.1.3: 汇编语言入门三:是时候上内存了
- 3.1.4: 汇编语言入门四:打通C和汇编语言
- 3.1.5: 汇编语言入门五:流程控制(一)
- 3.1.6: 汇编语言入门六:流程控制(二)
- 3.1.7: 汇编语言入门七:函数调用(一)
- 3.1.8: 汇编语言入门八:函数调用(二)
- 3.1.9: 汇编语言入门九:总结与后续(闲扯)
- 4: JavaScript
- 4.1: Html+Jquery
- 4.1.1: jquery插件开发
- 4.1.2: js获取各种节点的方法
- 4.1.3: reset.css
- 4.1.4: 曾经的纯JavaScript基础
- 4.1.5: 常用函数整理
- 4.1.6: 分享到新浪等
- 4.1.7: 改变url参数并可以把不存在的参数添加进url最后
- 4.1.8: 判断浏览器及版本
- 4.1.9: 瀑布流
- 4.1.10: 手机屏幕触摸
- 4.1.11: 一些案例
- 4.2: 键盘事件编码
- 4.3: ES6语法
- 4.4: mybatisSql语句拼装
- 4.5: Vue
- 4.6: cookie、localStorage和sessionStorage 三者之间的区别以及存储、获取、删除等使用方式
1 - Golang
1.1 - GolangUtils
1.1.1 - goroutine
获取goroutineID
func goID() uint64 {
b := make([]byte, 64)
b = b[:runtime.Stack(b, false)]
b = bytes.TrimPrefix(b, []byte("goroutine "))
b = b[:bytes.IndexByte(b, ' ')]
n, _ := strconv.ParseUint(string(b), 10, 64)
return n
}
1.1.2 - Map
初始化
// 先声明map
var m1 map[string]string
// 再使用make函数创建一个非nil的map,nil map不能赋值
m1 = make(map[string]string)
// 最后给已声明的map赋值
m1["a"] = "aa"
m1["b"] = "bb"
// 直接创建
m2 := make(map[string]string)
// 然后赋值
m2["a"] = "aa"
m2["b"] = "bb"
// 初始化 + 赋值一体化
m3 := map[string]string{
"a": "aa",
"b": "bb",
}
判断key是否存在
if v, ok := m1["a"]; ok {
fmt.Println(v)
} else {
fmt.Println("Key Not Found")
}
遍历map
for k, v := range m1 {
fmt.Println(k, v)
}
删除一个元素
scene := make(map[string]int)
// 准备map数据
scene["route"] = 66
scene["brazil"] = 4
scene["china"] = 960
delete(scene, "brazil")
for k, v := range scene {
fmt.Println(k, v)
}
//route 66
//china 960
安全的Map
1. map+锁
type SafeMap struct {
Data map[string]interface{}
Lock sync.RWMutex
}
func (this *SafeMap) Get(k string) interface{} {
this.Lock.RLock()
defer this.Lock.RUnlock()
if v, exit := this.Data[k]; exit {
return v
}
return nil
}
func (this *SafeMap) Set(k string, v interface{}) {
this.Lock.Lock()
defer this.Lock.Unlock()
if this.Data == nil {
this.Data = make(map[string]interface{})
}
this.Data[k] = v
}
2. sync.map
var test sync.Map
//设置元素
func set (k,v interface{}){
test.Store(k,v)
}
//获得元素
func get (k interface{}) interface{}{
tem ,exit := test.Load(k)
if exit {
return tem
}
return nil
}
//传入一个 函数 ,sync.map 会内部迭代 ,运行这个函数
func ranggfunc (funcs func(key, value interface{}) bool) {
test.Range(funcs)
}
//删除元素
func del(key interface{}){
test.Delete(key)
}
1.1.3 - 表单验证
1.1.4 - 结构体
判断变量是否==空结构体
if reflect.DeepEqual(deviceModel, models.DeviceModel{}) {
//code
}
结构提转map
//使用反射转换的效率要高于 struct->json->map
//传变量
func Struct2Map(obj interface{}) map[string]interface{} {
t := reflect.TypeOf(obj)
v := reflect.ValueOf(obj)
var data = make(map[string]interface{})
for i := 0; i < t.NumField(); i++ {
data[t.Field(i).Name] = v.Field(i).Interface()
}
return data
}
//传指针,如果一定要声明称指针( obj := new(Test)或obj := &Test{} )时,Struct2Map方法中需要将取出指针的内容然后继续操作,因为指针是没有Field()方法的。
func Struct2Map(obj interface{}) map[string]interface{} {
obj_v := reflect.ValueOf(obj)
v := obj_v.Elem()
typeOfType := v.Type()
var data = make(map[string]interface{})
for i := 0; i < v.NumField(); i++ {
field := v.Field(i)
data[typeOfType.Field(i).Name] = field.Interface()
}
return data
}
// Clone deep-copies a to b
func Clone(a, b interface{}) {
buff := new(bytes.Buffer)
enc := gob.NewEncoder(buff)
dec := gob.NewDecoder(buff)
enc.Encode(a)
dec.Decode(b)
}
func main() {
a1 := A{
AA: "jilao",
BB: 1,
}
var a2 A
Clone(a1, a2)
a2.AA = "lakjg;odfig"
fmt.Println(a1.AA)
fmt.Println(a2.AA)
}
1.1.5 - 进制转换
import (
"fmt"
"log"
"math"
"strconv"
"strings"
)
// Decimal to binary 十进制转二进制
func DecBin(n int64) string {
if n < 0 {
log.Println("Decimal to binary error: the argument must be greater than zero.")
return ""
}
if n == 0 {
return "0"
}
s := ""
for q := n; q > 0; q = q / 2 {
m := q % 2
s = fmt.Sprintf("%v%v", m, s)
}
return s
}
// Decimal to octal 十进制转八进制
func DecOct(d int64) int64 {
if d == 0 {
return 0
}
if d < 0 {
log.Println("Decimal to octal error: the argument must be greater than zero.")
return -1
}
s := ""
for q := d; q > 0; q = q / 8 {
m := q % 8
s = fmt.Sprintf("%v%v", m, s)
}
n, err := strconv.Atoi(s)
if err != nil {
log.Println("Decimal to octal error:", err.Error())
return -1
}
return int64(n)
}
// Decimal to hexadecimal 十进制转16进制
func DecHex(n int64) string {
if n < 0 {
log.Println("Decimal to hexadecimal error: the argument must be greater than zero.")
return ""
}
if n == 0 {
return "0"
}
hex := map[int64]int64{10: 65, 11: 66, 12: 67, 13: 68, 14: 69, 15: 70}
s := ""
for q := n; q > 0; q = q / 16 {
m := q % 16
if m > 9 && m < 16 {
m = hex[m]
s = fmt.Sprintf("%v%v", string(m), s)
continue
}
s = fmt.Sprintf("%v%v", m, s)
}
return s
}
// Binary to decimal 二进制转十进制
func BinDec(b string) (n int64) {
s := strings.Split(b, "")
l := len(s)
i := 0
d := float64(0)
for i = 0; i < l; i++ {
f, err := strconv.ParseFloat(s[i], 10)
if err != nil {
log.Println("Binary to decimal error:", err.Error())
return -1
}
d += f * math.Pow(2, float64(l-i-1))
}
return int64(d)
}
// Octal to decimal 八进制转十进制
func OctDec(o int64) (n int64) {
s := strings.Split(strconv.Itoa(int(o)), "")
l := len(s)
i := 0
d := float64(0)
for i = 0; i < l; i++ {
f, err := strconv.ParseFloat(s[i], 10)
if err != nil {
log.Println("Octal to decimal error:", err.Error())
return -1
}
d += f * math.Pow(8, float64(l-i-1))
}
return int64(d)
}
// Hexadecimal to decimal 十六进制转十进制
func HexDec(h string) (n int64) {
s := strings.Split(strings.ToUpper(h), "")
l := len(s)
i := 0
d := float64(0)
hex := map[string]string{"A": "10", "B": "11", "C": "12", "D": "13", "E": "14", "F": "15"}
for i = 0; i < l; i++ {
c := s[i]
if v, ok := hex[c]; ok {
c = v
}
f, err := strconv.ParseFloat(c, 10)
if err != nil {
log.Println("Hexadecimal to decimal error:", err.Error())
return -1
}
d += f * math.Pow(16, float64(l-i-1))
}
return int64(d)
}
// Octal to binary 八进制转二进制
func OctBin(o int64) string {
d := OctDec(o)
if d == -1 {
return ""
}
return DecBin(d)
}
// Hexadecimal to binary 十六进制转二进制
func HexBin(h string) string {
d := HexDec(h)
if d == -1 {
return ""
}
return DecBin(d)
}
// Binary to octal 二进制转八进制
func BinOct(b string) int64 {
d := BinDec(b)
if d == -1 {
return -1
}
return DecOct(d)
}
// Binary to hexadecimal 二进制转十六进制
func BinHex(b string) string {
d := BinDec(b)
if d == -1 {
return ""
}
return DecHex(d)
}
一个硬核的16进制转10进制 看起来有点笨, 但是很有效
var b2m_map map[byte]uint64 = map[byte]uint64{
0x00: 0,
0x01: 1,
0x02: 2,
0x03: 3,
0x04: 4,
0x05: 5,
0x06: 6,
0x07: 7,
0x08: 8,
0x09: 9,
0x0A: 10,
0x0B: 11,
0x0C: 12,
0x0D: 13,
0x0E: 14,
0x0F: 15,
0x10: 16,
0x11: 17,
0x12: 18,
0x13: 19,
0x14: 20,
0x15: 21,
0x16: 22,
0x17: 23,
0x18: 24,
0x19: 25,
0x1A: 26,
0x1B: 27,
0x1C: 28,
0x1D: 29,
0x1E: 30,
0x1F: 31,
0x20: 32,
0x21: 33,
0x22: 34,
0x23: 35,
0x24: 36,
0x25: 37,
0x26: 38,
0x27: 39,
0x28: 40,
0x29: 41,
0x2A: 42,
0x2B: 43,
0x2C: 44,
0x2D: 45,
0x2E: 46,
0x2F: 47,
0x30: 48,
0x31: 49,
0x32: 50,
0x33: 51,
0x34: 52,
0x35: 53,
0x36: 54,
0x37: 55,
0x38: 56,
0x39: 57,
0x3A: 58,
0x3B: 59,
0x3C: 60,
0x3D: 61,
0x3E: 62,
0x3F: 63,
0x40: 64,
0x41: 65,
0x42: 66,
0x43: 67,
0x44: 68,
0x45: 69,
0x46: 70,
0x47: 71,
0x48: 72,
0x49: 73,
0x4A: 74,
0x4B: 75,
0x4C: 76,
0x4D: 77,
0x4E: 78,
0x4F: 79,
0x50: 80,
0x51: 81,
0x52: 82,
0x53: 83,
0x54: 84,
0x55: 85,
0x56: 86,
0x57: 87,
0x58: 88,
0x59: 89,
0x5A: 90,
0x5B: 91,
0x5C: 92,
0x5D: 93,
0x5E: 94,
0x5F: 95,
0x60: 96,
0x61: 97,
0x62: 98,
0x63: 99,
0x64: 100,
0x65: 101,
0x66: 102,
0x67: 103,
0x68: 104,
0x69: 105,
0x6A: 106,
0x6B: 107,
0x6C: 108,
0x6D: 109,
0x6E: 110,
0x6F: 111,
0x70: 112,
0x71: 113,
0x72: 114,
0x73: 115,
0x74: 116,
0x75: 117,
0x76: 118,
0x77: 119,
0x78: 120,
0x79: 121,
0x7A: 122,
0x7B: 123,
0x7C: 124,
0x7D: 125,
0x7E: 126,
0x7F: 127,
0x80: 128,
0x81: 129,
0x82: 130,
0x83: 131,
0x84: 132,
0x85: 133,
0x86: 134,
0x87: 135,
0x88: 136,
0x89: 137,
0x8A: 138,
0x8B: 139,
0x8C: 140,
0x8D: 141,
0x8E: 142,
0x8F: 143,
0x90: 144,
0x91: 145,
0x92: 146,
0x93: 147,
0x94: 148,
0x95: 149,
0x96: 150,
0x97: 151,
0x98: 152,
0x99: 153,
0x9A: 154,
0x9B: 155,
0x9C: 156,
0x9D: 157,
0x9E: 158,
0x9F: 159,
0xA0: 160,
0xA1: 161,
0xA2: 162,
0xA3: 163,
0xA4: 164,
0xA5: 165,
0xA6: 166,
0xA7: 167,
0xA8: 168,
0xA9: 169,
0xAA: 170,
0xAB: 171,
0xAC: 172,
0xAD: 173,
0xAE: 174,
0xAF: 175,
0xB0: 176,
0xB1: 177,
0xB2: 178,
0xB3: 179,
0xB4: 180,
0xB5: 181,
0xB6: 182,
0xB7: 183,
0xB8: 184,
0xB9: 185,
0xBA: 186,
0xBB: 187,
0xBC: 188,
0xBD: 189,
0xBE: 190,
0xBF: 191,
0xC0: 192,
0xC1: 193,
0xC2: 194,
0xC3: 195,
0xC4: 196,
0xC5: 197,
0xC6: 198,
0xC7: 199,
0xC8: 200,
0xC9: 201,
0xCA: 202,
0xCB: 203,
0xCC: 204,
0xCD: 205,
0xCE: 206,
0xCF: 207,
0xD0: 208,
0xD1: 209,
0xD2: 210,
0xD3: 211,
0xD4: 212,
0xD5: 213,
0xD6: 214,
0xD7: 215,
0xD8: 216,
0xD9: 217,
0xDA: 218,
0xDB: 219,
0xDC: 220,
0xDD: 221,
0xDE: 222,
0xDF: 223,
0xE0: 224,
0xE1: 225,
0xE2: 226,
0xE3: 227,
0xE4: 228,
0xE5: 229,
0xE6: 230,
0xE7: 231,
0xE8: 232,
0xE9: 233,
0xEA: 234,
0xEB: 235,
0xEC: 236,
0xED: 237,
0xEE: 238,
0xEF: 239,
0xF0: 240,
0xF1: 241,
0xF2: 242,
0xF3: 243,
0xF4: 244,
0xF5: 245,
0xF6: 246,
0xF7: 247,
0xF8: 248,
0xF9: 249,
0xFA: 250,
0xFB: 251,
0xFC: 252,
0xFD: 253,
0xFE: 254,
0xFF: 255,
}
func hex2int(hexB *[]byte) uint64 {
var retInt uint64
hexLen := len(*hexB)
for k, v := range *hexB {
retInt += b2m_map[v] * exponent(16, uint64(2*(hexLen-k-1)))
}
return retInt
}
1.1.6 - 日期时间函数
对2006-01-02 15:04:05 (go的诞生时间) 按照123456来记忆:01月02号 下午3点04分05秒 2006年
获得秒,毫秒,纳秒时间戳
fmt.Printf("时间戳(秒):%v;\n", time.Now().Unix())
fmt.Printf("时间戳(纳秒):%v;\n",time.Now().UnixNano())
fmt.Printf("时间戳(毫秒):%v;\n",time.Now().UnixNano() / 1e6)
fmt.Printf("时间戳(纳秒转换为秒):%v;\n",time.Now().UnixNano() / 1e9)
获取格式化的前 5秒,5分钟,5小时,5天,5个月,5年前的时间
对 分小时天月年 设置格式 Format(“2006-01-02 15:04:05”) —> Format(“2006-01-02 15:00:00”), 写成00就是把对应位置直接赋值成00
st,_ := time.ParseDuration("-5s")
fmt.Println("5秒前的时间:",time.Now().Add(st).Format("2006-01-02 15:04:05"))
fmt.Println("5秒前的时间:",time.Now().Add(time.Second*-5).Format("2006-01-02 15:04:05"))
st,_ = time.ParseDuration("-5m")
fmt.Println("5分前的时间:",time.Now().Add(st).Format("2006-01-02 15:04:05"))
fmt.Println("5分前的时间:",time.Now().Add(time.Minute*-5).Format("2006-01-02 15:04:05"))
st,_ = time.ParseDuration("-5h")
fmt.Println("5小时前的时间:",time.Now().Add(st).Format("2006-01-02 15:04:05"))
fmt.Println("5小时前的时间:",time.Now().Add(time.Hour*-5).Format("2006-01-02 15:04:05"))
fmt.Println("5天前的时间:",time.Now().AddDate(0, 0, -5).Format("2006-01-02 15:04:05"))
fmt.Println("5月前的时间:",time.Now().AddDate(0, -5, 0).Format("2006-01-02 15:04:05"))
fmt.Println("5年前的时间:",time.Now().AddDate(-5, 0, 0).Format("2006-01-02 15:04:05"))
外部传入字符串时间戳输出
package main
import (
"log"
"time"
)
func main() {
t := int64(1595581744) //外部传入的时间戳(秒为单位),必须为int64类型, time.Unix(t, 0)必须是到秒的时间戳
t1 := "2019-01-08 13:50:30" //外部传入的时间字符串
//时间转换的模板,golang里面只能是 "2006-01-02 15:04:05" (go的诞生时间)
timeTemplate1 := "2006-01-02 15:04:05" //常规类型
timeTemplate2 := "2006/01/02 15:04:05" //其他类型
timeTemplate3 := "2006-01-02" //其他类型
timeTemplate4 := "15:04:05" //其他类型
// ======= 将时间戳格式化为日期字符串 =======
log.Println(time.Unix(t, 0).Format(timeTemplate1)) //输出:2019-01-08 13:50:30
log.Println(time.Unix(t, 0).Format(timeTemplate2)) //输出:2019/01/08 13:50:30
log.Println(time.Unix(t, 0).Format(timeTemplate3)) //输出:2019-01-08
log.Println(time.Unix(t, 0).Format(timeTemplate4)) //输出:13:50:30
// ======= 将时间字符串转换为时间戳 =======
stamp, _ := time.ParseInLocation(timeTemplate1, t1, time.Local) //使用parseInLocation将字符串格式化返回本地时区时间
log.Println(stamp.Unix()) //输出:1546926630
}
1.1.7 - 数据类型转换
string to other = 字符串转其他
string -> int
i1, err := strconv.Atoi("1")
string -> int64
i64, err := strconv.ParseInt("2", 10, 64)
hexstring -> []byte 16进制字符串转(16进制代表的)byte数组
hex_str := "4161"
hex_data, _ := hex.DecodeString(hex_str)
fmt.Println(string(hexData))//Aa
1.1.8 - 数学函数
向上取整math.Ceil() 向下取整math.Floor()
//go没有其他语言得round函数,整数位得四舍五入简单版 func round(x float64){ return int(math.Floor(x + 0/5)) }
package main
import (
"fmt"
"github.com/shopspring/decimal"
)
/*
保有小数位得四舍五入
*/
func main() {
v1, _ := decimal.NewFromFloat(9.824).Round(2).Float64()
v2, _ := decimal.NewFromFloat(9.826).Round(2).Float64()
v3, _ := decimal.NewFromFloat(9.8251).Round(2).Float64()
fmt.Println(v1, v2, v3)
v4, _ := decimal.NewFromFloat(9.815).Round(2).Float64()
v5, _ := decimal.NewFromFloat(9.825).Round(2).Float64()
v6, _ := decimal.NewFromFloat(9.835).Round(2).Float64()
v7, _ := decimal.NewFromFloat(9.845).Round(2).Float64()
fmt.Println(v4, v5, v6, v7)
v8, _ := decimal.NewFromFloat(3.3).Round(2).Float64()
v9, _ := decimal.NewFromFloat(3.3000000000000003).Round(2).Float64()
v10, _ := decimal.NewFromFloat(3).Round(2).Float64()
fmt.Println(v8, v9, v10)
v11, _ := decimal.NewFromFloat(129.975).Round(2).Float64()
v12, _ := decimal.NewFromFloat(34423.125).Round(2).Float64()
fmt.Println(v11, v12)
}
1.1.9 - 文件目录操作函数
获取指定目录下正则匹配到的文件
package main
import (
"fmt"
"log"
"os"
"path/filepath"
)
func main() {
files, err := WalkMatch("./", "*.exe")
if err != nil {
log.Fatalln(err)
}
fmt.Println(files)
}
func WalkMatch(root, pattern string) ([]string, error) {
var matches []string
err := filepath.Walk(root, func(path string, info os.FileInfo, err error) error {
if err != nil {
return err
}
if info.IsDir() {
return nil
}
if matched, err := filepath.Match(pattern, filepath.Base(path)); err != nil {
return err
} else if matched {
path, _ = filepath.Abs(path)
matches = append(matches, path)
}
return nil
})
if err != nil {
return nil, err
}
return matches, nil
}
1.1.10 - 系统变量初始化
Context
ctx, _ := context.WithTimeout(context.Background(), 15 * time.Second)
获取当前路径
package main
import (
"os"
"path/filepath"
)
func main() {
// 据说这个方法在某些特别场景会获取到错误的路径
dir1, _ := os.Getwd()
//推荐使用下面的方法
dir2, _ := os.Executable()
exPath := filepath.Dir(dir2)
println(exPath2)
}
1.1.11 - 序列化
序列化存入内存
f,err = os.Open("path")
if err != nil {
driver.logger.Error("文件打开失败:"+err.Error())
os.Exit(-1)
}
dec := gob.NewDecoder(f)
err = dec.Decode(&helper.DeviceTerminalMap)
//判断有错误并且不是文件为空的错误,文件如果为空,在读文件是直接返回文件结束符(EOF)
if err != nil && err != io.EOF {
driver.logger.Error("设备终端档案存储文件解析失败:"+err.Error())
os.Exit(-1)
}
写入序列化内容
f, _ := os.Open("device-terminal.god")
defer f.Close()
dec := gob.NewDecoder(f)
err = dec.Decode(&helper.DeviceTerminalMap)
1.1.12 - 整型
int64 -> string
var i1 int64
i1 = 555
str1 := strconv.FormatInt(int1,10)
int -> string
i2 := 1
str2 := strconv.Itoa(i2)
int8 -> string
var int8Value int8
int8Value = 2
strconv.Itoa(int(int8Value))
//整形转换成字节
func IntToBytes(n int) []byte {
x := int32(n)
bytesBuffer := bytes.NewBuffer([]byte{})
binary.Write(bytesBuffer, binary.BigEndian, x)
return bytesBuffer.Bytes()
}
//字节转换成整形
func BytesToInt(b []byte) int {
bytesBuffer := bytes.NewBuffer(b)
var x int32
binary.Read(bytesBuffer, binary.BigEndian, &x)
return int(x)
}
1.1.13 - 字符串函数
生成UUID
package main
import (
"github.com/satori/go.uuid"
"fmt"
)
func main(){
u1 := uuid.Must(uuid.NewV4())
fmt.Printf("UUIDv4:%s\n", u1)
u2, err := uuid.FromString("6ba7b810-9dad-11d1-80b4-00c04fd430c8")
if err != nil {
fmt.Printf("Something went wrong: %s", err)
return
}
fmt.Printf("Successfully parsed: %s", u2)
}
字符串拆分
//1. 按指定字符拆分
s := "iiaiibiiciiiidiiii"
sep:="ii"
arr:=strings.Split(s,sep)
fmt.Println("arr:",arr)
//2. 按空格拆分
s:=" ab cd ef gh ij kl "
arr:=strings.Fields(s)
fmt.Printf("arr:%q\n",arr)
接收gbk编码的中文要转成utf8的中文
//github.com/axgle/mahonia
func ConvertToString(src string, srcCode string, tagCode string) string {
srcCoder := mahonia.NewDecoder(srcCode)
srcResult := srcCoder.ConvertString(src)
tagCoder := mahonia.NewDecoder(tagCode)
_, cdata, _ := tagCoder.Translate([]byte(srcResult), true)
result := string(cdata)
return result
}
func main() {
//gbk编码的中文,用16进制字符串表示
hex_str := "4d6f646275732e58464a2e3330462ec0e4c4fdcbaec5c5cbaeb1c3"
hex_data, _ := hex.DecodeString(hex_str)
// 将 byte 转换 为字符串 输出结果
str := ConvertToString(string(hex_data), "gbk", "utf-8")
fmt.Println(str)
//先试试这个,一般就可以了
s1 := "4d6f646275732e58464a2e3330462ec0e4c4fdcbaec5c5cbaeb1c3"
hex_data, _ := hex.DecodeString(s1)
srcCoder := mahonia.NewDecoder("gbk")
srcResult := srcCoder.ConvertString(string(hex_data))
fmt.Println(srcResult)
}
MD5
package main
import (
"crypto/md5"
"fmt"
"io"
)
func main() {
str := "abc123"
//方法一
data := []byte(str)
has := md5.Sum(data)
md5str1 := fmt.Sprintf("%x", has) //将[]byte转成16进制
fmt.Println(md5str1)
//方法二
w := md5.New()
io.WriteString(w, str) //将str写入到w中
md5str2: = fmt.Sprintf("%x", w.Sum(nil)) //w.Sum(nil)将w的hash转成[]byte格式
fmt.Println(mdtstr2)
}
Base64
package main
import (
"encoding/base64"
"fmt"
)
func main() {
//标准base64编码
data:="abckagfd*^&&^*fadf";
sEnc:=base64.StdEncoding.EncodeToString([]byte(data))
fmt.Println(sEnc)
sDec,_:=base64.StdEncoding.DecodeString(sEnc)
fmt.Println(string(sDec))
//兼容base64编码
uEnc:=base64.URLEncoding.EncodeToString([]byte(data))
fmt.Println(uEnc)
uDec,_:=base64.URLEncoding.DecodeString(uEnc)
fmt.Println(string(uDec))
}
字符串和[]byte相互转换
package main
import (
"fmt"
"reflect"
"time"
"unsafe"
)
//零拷贝字符串转字节数组
func string2bytes(s string) []byte {
stringHeader := (*reflect.StringHeader)(unsafe.Pointer(&s))
var b []byte
pbytes := (*reflect.SliceHeader)(unsafe.Pointer(&b))
pbytes.Data = stringHeader.Data
pbytes.Len = stringHeader.Len
pbytes.Cap = stringHeader.Len
return b
}
//零拷贝字节数组转字符串
func bytes2string(b []byte) string {
bHeader := (*reflect.SliceHeader)(unsafe.Pointer(&b))
var s string
stringHeader := (*reflect.StringHeader)(unsafe.Pointer(&s))
stringHeader.Data = bHeader.Data
stringHeader.Len = bHeader.Len
return s
}
func main() {
s := "零拷贝转换字符串和字节数组"
t1 := time.Now().Nanosecond()
v := string2bytes(s)
t2 := time.Now().Nanosecond()
fmt.Println(v)
t3 := time.Now().Nanosecond()
data := []byte(s)
t4 := time.Now().Nanosecond()
fmt.Println(data)
fmt.Println("method1 time", t2-t1)
fmt.Println("method2 time", t4-t3)
t5 := time.Now().Nanosecond()
s1 := bytes2string(v)
t6 := time.Now().Nanosecond()
fmt.Println(s1)
t7 := time.Now().Nanosecond()
s2 := string(v)
t8 := time.Now().Nanosecond()
fmt.Println(s2)
fmt.Println("method3 time", t6-t5)
fmt.Println("method4 time", t8-t7)
}
1.1.14 - 字节数组操作([]byte)
//isSymbol表示有无符号
func BytesToInt(b []byte, isSymbol bool) (int, error){
if isSymbol {
return bytesToIntS(b)
}
return bytesToIntU(b)
}
//字节数(大端)组转成int(无符号的)
func bytesToIntU(b []byte) (int, error) {
if len(b) == 3 {
b = append([]byte{0},b...)
}
bytesBuffer := bytes.NewBuffer(b)
switch len(b) {
case 1:
var tmp uint8
err := binary.Read(bytesBuffer, binary.BigEndian, &tmp)
return int(tmp), err
case 2:
var tmp uint16
err := binary.Read(bytesBuffer, binary.BigEndian, &tmp)
return int(tmp), err
case 4:
var tmp uint32
err := binary.Read(bytesBuffer, binary.BigEndian, &tmp)
return int(tmp), err
default:
return 0,fmt.Errorf("%s", "BytesToInt bytes lenth is invaild!")
}
}
//字节数(大端)组转成int(有符号)
func bytesToIntS(b []byte) (int, error) {
if len(b) == 3 {
b = append([]byte{0},b...)
}
bytesBuffer := bytes.NewBuffer(b)
switch len(b) {
case 1:
var tmp int8
err := binary.Read(bytesBuffer, binary.BigEndian, &tmp)
return int(tmp), err
case 2:
var tmp int16
err := binary.Read(bytesBuffer, binary.BigEndian, &tmp)
return int(tmp), err
case 4:
var tmp int32
err := binary.Read(bytesBuffer, binary.BigEndian, &tmp)
return int(tmp), err
default:
return 0,fmt.Errorf("%s", "BytesToInt bytes lenth is invaild!")
}
}
//整形转换成字节
func IntToBytes(n int,b byte) ([]byte,error) {
switch b {
case 1:
tmp := int8(n)
bytesBuffer := bytes.NewBuffer([]byte{})
binary.Write(bytesBuffer, binary.BigEndian, &tmp)
return bytesBuffer.Bytes(),nil
case 2:
tmp := int16(n)
bytesBuffer := bytes.NewBuffer([]byte{})
binary.Write(bytesBuffer, binary.BigEndian, &tmp)
return bytesBuffer.Bytes(),nil
case 3,4:
tmp := int32(n)
bytesBuffer := bytes.NewBuffer([]byte{})
binary.Write(bytesBuffer, binary.BigEndian, &tmp)
return bytesBuffer.Bytes(),nil
}
return nil,fmt.Errorf("IntToBytes b param is invaild")
}
1.2 - 最佳实践
1.2.1 - 单元测试
1.2.1.1 - Golang单元测试-wire依赖注入
Golang依赖注入框架wire全攻略
在前一阵介绍单元测试的系列文章中,曾经简单介绍过wire依赖注入框架。但当时的wire还处于alpha阶段,不过最近wire已经发布了首个beta版,API发生了一些变化,同时也承诺除非万不得已,将不会破坏API的兼容性。在前文中,介绍了一些wire的基本概况,本篇就不再重复,感兴趣的小伙伴们可以回看一下: 搞定Go单元测试(四)—— 依赖注入框架(wire)。本篇将具体介绍wire的使用方法和一些最佳实践。
本篇中的代码的完整示例可以在这里找到:wire-examples
Installing
go get github.com/google/wire/cmd/wire
Quick Start
我们先通过一个简单的例子,让小伙伴们对wire有一个直观的认识。下面的例子展示了一个简易wire依赖注入示例:
$ ls
main.go wire.go
main.go
package main
import "fmt"
type Message struct {
msg string
}
type Greeter struct {
Message Message
}
type Event struct {
Greeter Greeter
}
// NewMessage Message的构造函数
func NewMessage(msg string) Message {
return Message{
msg:msg,
}
}
// NewGreeter Greeter构造函数
func NewGreeter(m Message) Greeter {
return Greeter{Message: m}
}
// NewEvent Event构造函数
func NewEvent(g Greeter) Event {
return Event{Greeter: g}
}
func (e Event) Start() {
msg := e.Greeter.Greet()
fmt.Println(msg)
}
func (g Greeter) Greet() Message {
return g.Message
}
// 使用wire前
func main() {
message := NewMessage("hello world")
greeter := NewGreeter(message)
event := NewEvent(greeter)
event.Start()
}
/*
// 使用wire后
func main() {
event := InitializeEvent("hello_world")
event.Start()
}*/
wire.go
// +build wireinject
// The build tag makes sure the stub is not built in the final build.
package main
import "github.com/google/wire"
// InitializeEvent 声明injector的函数签名
func InitializeEvent(msg string) Event{
wire.Build(NewEvent, NewGreeter, NewMessage)
return Event{} //返回值没有实际意义,只需符合函数签名即可
}
调用wire命令生成依赖文件:
$ wire
wire: github.com/DrmagicE/wire-examples/quickstart: wrote XXXX\github.com\DrmagicE\wire-examples\quickstart\wire_gen.go
$ ls
main.go wire.go wire_gen.go
wire_gen.go wire生成的文件
// Code generated by Wire. DO NOT EDIT.
//go:generate wire
//+build !wireinject
package main
// Injectors from wire.go:
func InitializeEvent(msg string) Event {
message := NewMessage(msg)
greeter := NewGreeter(message)
event := NewEvent(greeter)
return event
}
使用前 V.S 使用后
...
/*
// 使用wire前
func main() {
message := NewMessage("hello world")
greeter := NewGreeter(message)
event := NewEvent(greeter)
event.Start()
}*/
// 使用wire后
func main() {
event := InitializeEvent("hello_world")
event.Start()
}
...
使用wire后,只需调一个初始化方法既可得到Event了,对比使用前,不仅减少了三行代码,并且无需再关心依赖之间的初始化顺序。
示例传送门: quickstart
Provider & Injector
provider和injector是wire的两个核心概念。
provider: a function that can produce a value. These functions are ordinary Go code. injector: a function that calls providers in dependency order. With Wire, you write the injector’s signature, then Wire generates the function’s body. github.com/google/wire…
通过提供provider函数,让wire知道如何产生这些依赖对象。wire根据我们定义的injector函数签名,生成完整的injector函数,injector函数是最终我们需要的函数,它将按依赖顺序调用provider。
在quickstart的例子中,NewMessage,NewGreeter,NewEvent都是provider,wire_gen.go中的InitializeEvent函数是injector,可以看到injector通过按依赖顺序调用provider来生成我们需要的对象Event。
上述示例在wire.go中定义了injector的函数签名,注意要在文件第一行加上
// +build wireinject
...
用于告诉编译器无需编译该文件。在injector的签名定义函数中,通过调用wire.Build方法,指定用于生成依赖的provider:
// InitializeEvent 声明injector的函数签名
func InitializeEvent(msg string) Event{
wire.Build(NewEvent, NewGreeter, NewMessage) // <--- 传入provider函数
return Event{} //返回值没有实际意义,只需符合函数签名即可
}
该方法的返回值没有实际意义,只需要符合函数签名的要求即可。
高级特性
quickstart示例展示了wire的基础功能,本节将介绍一些高级特性。
接口绑定
根据依赖倒置原则(Dependence Inversion Principle),对象应当依赖于接口,而不是直接依赖于具体实现。
抽象成接口依赖更有助于单元测试哦! 搞定Go单元测试(一)——基础原理 搞定Go单元测试(二)—— mock框架(gomock)
在quickstart的例子中的依赖均是具体实现,现在我们来看看在wire中如何处理接口依赖:
// UserService
type UserService struct {
userRepo UserRepository // <-- UserService依赖UserRepository接口
}
// UserRepository 存放User对象的数据仓库接口,比如可以是mysql,restful api ....
type UserRepository interface {
// GetUserByID 根据ID获取User, 如果找不到User返回对应错误信息
GetUserByID(id int) (*User, error)
}
// NewUserService *UserService构造函数
func NewUserService(userRepo UserRepository) *UserService {
return &UserService{
userRepo:userRepo,
}
}
// mockUserRepo 模拟一个UserRepository实现
type mockUserRepo struct {
foo string
bar int
}
// GetUserByID UserRepository接口实现
func (u *mockUserRepo) GetUserByID(id int) (*User,error){
return &User{}, nil
}
// NewMockUserRepo *mockUserRepo构造函数
func NewMockUserRepo(foo string,bar int) *mockUserRepo {
return &mockUserRepo{
foo:foo,
bar:bar,
}
}
// MockUserRepoSet 将 *mockUserRepo与UserRepository绑定
var MockUserRepoSet = wire.NewSet(NewMockUserRepo,wire.Bind(new(UserRepository), new(*mockUserRepo)))
在这个例子中,UserService依赖UserRepository接口,其中mockUserRepo是UserRepository的一个实现,由于在Go的最佳实践中,更推荐返回具体实现而不是接口。所以mockUserRepo的provider函数返回的是*mockUserRepo这一具体类型。wire无法自动将具体实现与接口进行关联,我们需要显示声明它们之间的关联关系。通过wire.NewSet和wire.Bind将*mockUserRepo与UserRepository进行绑定:
// MockUserRepoSet 将 *mockUserRepo与UserRepository绑定
var MockUserRepoSet = wire.NewSet(NewMockUserRepo,wire.Bind(new(UserRepository), new(*mockUserRepo)))
定义injector函数签名:
...
func InitializeUserService(foo string, bar int) *UserService{
wire.Build(NewUserService,MockUserRepoSet) // 使用MockUserRepoSet
return nil
}
...
示例传送门: binding-interfaces
返回错误
在前面的例子中,我们的provider函数均只有一个返回值,但在某些情况下,provider函数可能会对入参做校验,如果参数错误,则需要返回error。wire也考虑了这种情况,provider函数可以将返回值的第二个参数设置成error:
// Config 配置
type Config struct {
// RemoteAddr 连接的远程地址
RemoteAddr string
}
// APIClient API客户端
type APIClient struct {
c Config
}
// NewAPIClient APIClient构造函数,如果入参校验失败,返回错误原因
func NewAPIClient(c Config) (*APIClient,error) { // <-- 第二个参数设置成error
if c.RemoteAddr == "" {
return nil, errors.New("没有设置远程地址")
}
return &APIClient{
c:c,
},nil
}
// Service
type Service struct {
client *APIClient
}
// NewService Service构造函数
func NewService(client *APIClient) *Service{
return &Service{
client:client,
}
}
类似的,injector函数定义的时候也需要将第二个返回值设置成error:
...
func InitializeClient(config Config) (*Service, error) { // <-- 第二个参数设置成error
wire.Build(NewService,NewAPIClient)
return nil,nil
}
...
观察一下wire生成的injector:
func InitializeClient(config Config) (*Service, error) {
apiClient, err := NewAPIClient(config)
if err != nil { // <-- 在构造依赖的顺序中如果发生错误,则会返回对应的"零值"和相应错误
return nil, err
}
service := NewService(apiClient)
return service, nil
}
在构造依赖的顺序中如果发生错误,则会返回对应的"零值"和相应错误。
示例传送门: return-error
Cleanup functions
当provider生成的对象需要一些cleanup处理,比如关闭文件,关闭数据库连接等操作时,依然可以通过设置provider的返回值来达到这样的效果:
// FileReader
type FileReader struct {
f *os.File
}
// NewFileReader *FileReader 构造函数,第二个参数是cleanup function
func NewFileReader(filePath string) (*FileReader, func(), error){
f, err := os.Open(filePath)
if err != nil {
return nil,nil,err
}
fr := &FileReader{
f:f,
}
fn := func() {
log.Println("cleanup")
fr.f.Close()
}
return fr,fn,nil
}
跟返回错误类似,将provider的第二个返回参数设置成func()用于返回cleanup function,上述例子中在第三个参数中返回了error,但这是可选的:
wire对provider的返回值个数和顺序有所规定:
- 第一个参数是需要生成的依赖对象
- 如果返回2个返回值,第二个参数必须是func()或者error
- 如果返回3个返回值,第二个参数必须是func(),第三个参数则必须是error
示例传送门: cleanup-functions
Provider set
当一些provider通常是一起使用的时候,可以使用provider set将它们组织起来,以quickstart示例为模板稍作修改:
// NewMessage Message的构造函数
func NewMessage(msg string) Message {
return Message{
msg:msg,
}
}
// NewGreeter Greeter构造函数
func NewGreeter(m Message) Greeter {
return Greeter{Message: m}
}
// NewEvent Event构造函数
func NewEvent(g Greeter) Event {
return Event{Greeter: g}
}
func (e Event) Start() {
msg := e.Greeter.Greet()
fmt.Println(msg)
}
// EventSet Event通常是一起使用的一个集合,使用wire.NewSet进行组合
var EventSet = wire.NewSet(NewEvent, NewMessage, NewGreeter) // <--
上述例子中将Event和它的依赖通过wire.NewSet组合起来,作为一个整体在injector函数签名定义中使用:
func InitializeEvent(msg string) Event{
//wire.Build(NewEvent, NewGreeter, NewMessage)
wire.Build(EventSet)
return Event{}
}
这时只需将EventSet传入wire.Build即可。
示例传送门: provider-set
结构体provider
除了函数外,结构体也可以充当provider的角色,类似于setter注入:
type Foo int
type Bar int
func ProvideFoo() Foo {
return 1
}
func ProvideBar() Bar {
return 2
}
type FooBar struct {
MyFoo Foo
MyBar Bar
}
var Set = wire.NewSet(
ProvideFoo,
ProvideBar,
wire.Struct(new(FooBar), "MyFoo", "MyBar"))
通过wire.Struct来指定那些字段要被注入到结构体中,如果是全部字段,也可以简写成:
var Set = wire.NewSet(
ProvideFoo,
ProvideBar,
wire.Struct(new(FooBar), "*")) // * 表示注入全部字段
生成的injector函数:
func InitializeFooBar() FooBar {
foo := ProvideFoo()
bar := ProvideBar()
fooBar := FooBar{
MyFoo: foo,
MyBar: bar,
}
return fooBar
}
示例传送门: struct-provider
Best Practices
区分类型
由于injector的函数中,不允许出现重复的参数类型,否则wire将无法区分这些相同的参数类型,比如:
type FooBar struct {
foo string
bar string
}
func NewFooBar(foo string, bar string) FooBar {
return FooBar{
foo: foo,
bar: bar,
}
}
injector函数签名定义:
// wire无法得知入参a,b跟FooBar.foo,FooBar.bar的对应关系
func InitializeFooBar(a string, b string) FooBar {
wire.Build(NewFooBar)
return FooBar{}
}
如果使用上面的provider来生成injector,wire会报如下错误:
provider has multiple parameters of type string
因为入参均是字符串类型,wire无法得知入参a,b跟FooBar.foo,FooBar.bar的对应关系。 所以我们使用不同的类型来避免冲突:
type Foo string
type Bar string
type FooBar struct {
foo Foo
bar Bar
}
func NewFooBar(foo Foo, bar Bar) FooBar {
return FooBar{
foo: foo,
bar: bar,
}
}
injector函数签名定义:
func InitializeFooBar(a Foo, b Bar) FooBar {
wire.Build(NewFooBar)
return FooBar{}
}
其中基础类型和通用接口类型是最容易发生冲突的类型,如果它们在provider函数中出现,最好统一新建一个别名来代替它(尽管还未发生冲突),例如:
type MySQLConnectionString string
type FileReader io.Reader
示例传送门 distinguishing-types
Options Structs
如果一个provider方法包含了许多依赖,可以将这些依赖放在一个options结构体中,从而避免构造函数的参数太多:
type Message string
// Options
type Options struct {
Messages []Message
Writer io.Writer
Reader io.Reader
}
type Greeter struct {
}
// NewGreeter Greeter的provider方法使用Options以避免构造函数过长
func NewGreeter(ctx context.Context, opts *Options) (*Greeter, error) {
return nil, nil
}
// GreeterSet 使用wire.Struct设置Options为provider
var GreeterSet = wire.NewSet(wire.Struct(new(Options), "*"), NewGreeter)
injector函数签名:
func InitializeGreeter(ctx context.Context, msg []Message, w io.Writer, r io.Reader) (*Greeter, error) {
wire.Build(GreeterSet)
return nil, nil
}
示例传送门 options-structs
一些缺点和限制
额外的类型定义
由于wire自身的限制,injector中的变量类型不能重复,需要定义许多额外的基础类型别名。
mock支持暂时不够友好
目前wire命令还不能识别_test.go结尾文件中的provider函数,这样就意味着如果需要在测试中也使用wire来注入我们的mock对象,我们需要在常规代码中嵌入mock对象的provider,这对常规代码有侵入性,不过官方似乎也已经注意到了这个问题,感兴趣的小伙伴可以关注一下这条issue:github.com/google/wire…
更多参考
1.2.1.2 - Golang单元测试-简单示例
one.go
package unittest
func AddOne(t int32) int32 {
return t + 1
}
func MinusOne(t int32) int32 {
return t - 1
}
func MultiAddOne(t int32) int32 {
t = MinusOne(t)
t = AddOne(t)
t = AddOne(t)
return t
}
one_test.go
package unittest
import (
"testing"
. "github.com/agiledragon/gomonkey"
. "github.com/smartystreets/goconvey/convey"
)
func TestMultiAddOne(t *testing.T) {
Convey("TestApplyFunc", t, func() {
Convey("input and output param", func() {
patches := ApplyFunc(AddOne, func(t1 int32) int32 {
return 5
}) //对函数AddOne打桩
defer patches.Reset()
patches.ApplyFunc(MinusOne, func(t1 int32) int32 {
return -2
}) //对函数MinusOne打桩
result := MultiAddOne(2) //看好了我调用的是MultiAddOne函数,而MultiAddOne函数内部调用了AddOne和MinusOne。
So(result, ShouldEqual, 3)
})
})
}
1.2.1.3 - Golang单元测试01
搞定Go单元测试(一)——基础原理
单元测试是代码质量的保证。本系列文章将一步步由浅入深展示如何在Go中做单元测试。
Go对单元测试的支持相当友好,标准包中就支持单元测试,在开始本系阅读之前,需要对标准测试包的基本用法有所了解。
现在,我们从单元测试的基本思想和原理入手,一起来看看如何基于Go提供的标准测试包来进行单元测试。
单元测试的难点
1.掌握单元测试粒度
单元测试粒度是让人十分头疼的问题,特别是对于初尝单元测试的程序员。测试粒度做的太细,会耗费大量的开发以及维护时间,每改一个方法,都要改动其对应的测试方法。当发生代码重构的时候那简直就是噩梦(因为你所有的单元测试又都要写一遍了…)。 如单元测试粒度太粗,一个测试方法测试了n多方法,那么单元测试将显的非常臃肿,脱离了单元测试的本意,容易把单元测试写成集成测试。
2. 破除外部依赖(mock,stub 技术)
单元测试一般不允许有任何外部依赖(文件依赖,网络依赖,数据库依赖等),我们不会在测试代码中去连接数据库,调用api等。这些外部依赖在执行测试的时候需要被模拟(mock/stub)。在测试的时候,我们使用模拟的对象来模拟真实依赖下的各种行为。如何运用mock/stub来模拟系统真实行为算是单元测试道路上的一只拦路虎。别着急,本文会通过示例来展示如何在Go中使用mock/stub来完成单元测试。
有的时候模拟是有效的方便的。但我们要提防过度的mock/stub,因为其会导致单元测试主要在测模拟对象而不是实际的系统。
Costs and Benefits
在受益于单元测试的好处的同时,也必然增加了代码量以及维护成本(单元测试代码也是要维护的)。下面这张成本/价值象限图很清晰的阐述了在不同性质的系统中单元测试成本和价值之间的关系。
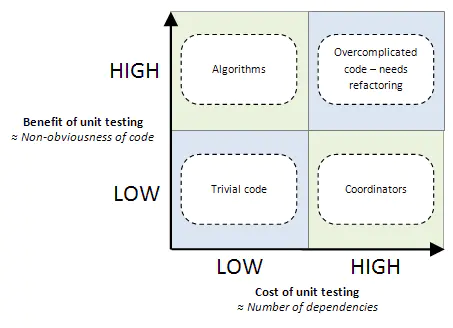
1.依赖很少的简单的代码(左下)
对于外部依赖少,代码又简单的代码。自然其成本和价值都是比较低的。举Go官方库里errors包为例,整个包就两个方法 New()和 Error(),没有任何外部依赖,代码也很简单,所以其单元测试起来也是相当方便。
2. 依赖较多但是很简单的代码(右下)
依赖一多,mock和stub就必然增多,单元测试的成本也就随之增加。但代码又如此简单(比如上述errors包的例子),这个时候写单元测试的成本已经大于其价值,还不如不写单元测试。
3. 依赖很少的复杂代码 (左上)
像这一类代码,是最有价值写单元测试的。比如一些独立的复杂算法(银行利息计算,保险费率计算,TCP协议解析等),像这一类代码外部依赖很少,但却很容易出错,如果没有单元测试,几乎不能保证代码质量。
4.依赖很多又很复杂(右上)
这种代码显然是单元测试的噩梦。写单元测试吧,代价高昂;不写单元测试吧,风险太高。像这种代码我们尽量在设计上将其分为两部分:1.处理复杂的逻辑部分 2.处理依赖部分 然后1部分进行单元测试
迈出单元测试第一步
1. 识别依赖,抽象成接口
识别系统中的外部依赖,普遍来说,我们遇到最常见的依赖无非下面几种:
- 网络依赖——函数执行依赖于网络请求,比如第三方http-api,rpc服务,消息队列等等
- 数据库依赖
- I/O依赖(文件)
当然,还有可能是依赖还未开发完成的功能模块。但是处理方法都是大同小异的——抽象成接口,通过mock和stub进行模拟测试。
2. 明确需要测什么
当我们开始敲产品代码的时候,我们必然已经过初步的设计,已经了解系统中的外部依赖以及业务复杂的部分,这些部分是要优先考虑写单元测试的。在写每一个方法/结构体的时候同时思考这个方法/结构体需不需要测试?如何测试?对于什么样的方法/结构体需要测试,什么样的可以不做,除了可以从上面的成本/价值象限图中获得答案外,还可以参考以下关于单元测试粒度要做多细问题的回答:
老板为我的代码付报酬,而不是测试,所以,我对此的价值观是——测试越少越好,少到你对你的代码质量达到了某种自信(我觉得这种的自信标准应该要高于业内的标准,当然,这种自信也可能是种自大)。如果我的编码生涯中不会犯这种典型的错误(如:在构造函数中设了个错误的值),那我就不会测试它。我倾向于去对那些有意义的错误做测试,所以,我对一些比较复杂的条件逻辑会异常地小心。当在一个团队中,我会非常小心的测试那些会让团队容易出错的代码。 coolshell.cn/articles/82…
Mock和Stub怎么做
Mock(模拟)和Stub(桩)是在测试过程中,模拟外部依赖行为的两种常用的技术手段。 通过Mock和Stub我们不仅可以让测试环境没有外部依赖,而且还可以模拟一些异常行为,如数据库服务不可用,没有文件的访问权限等等。
Mock和Stub的区别
在Go语言中,可以这样描述Mock和Stub:
- Mock:在测试包中创建一个结构体,满足某个外部依赖的接口
interface{} - Stub:在测试包中创建一个模拟方法,用于替换生成代码中的方法
还是有点抽象,下面举例说明。
Mock示例
Mock:在测试包中创建一个结构体,满足某个外部依赖的接口 interface{}
生产代码:
//auth.go
//假设我们有一个依赖http请求的鉴权接口
type AuthService interface{
Login(username string,password string) (token string,e error)
Logout(token string) error
}
mock代码:
//auth_test.go
type authService struct {}
func (auth *authService) Login (username string,password string) (string,error){
return "token", nil
}
func (auth *authService) Logout(token string) error{
return nil
}
在这里我们用 authService实现了 AuthService接口,这样测试 Login,Logout就不再需需要依赖网络请求了。而且我们也可以模拟一些错误的情况进行测试:
//auth_test.go
//模拟登录失败
type authLoginErr struct {
auth AuthService //可以使用组合的特性,Logout方法我们不关心,只用“覆盖”Login方法即可
}
func (auth *authLoginErr) Login (username string,password string) (string,error) {
return "", errors.New("用户名密码错误")
}
//模拟api服务器宕机
type authUnavailableErr struct {
}
func (auth *authUnavailableErr) Login (username string,password string) (string,error) {
return "", errors.New("api服务不可用")
}
func (auth *authUnavailableErr) Logout(token string) error{
return errors.New("api服务不可用")
}
Stub示例
Stub:在测试包中创建一个模拟方法,用于替换生成代码中的方法。 这是《Go语言圣经》(11.2.3)当中的一个例子: 生产代码:
//storage.go
//发送邮件
var notifyUser = func(username, msg string) { //<--将发送邮件的方法变成一个全局变量
auth := smtp.PlainAuth("", sender, password, hostname)
err := smtp.SendMail(hostname+":587", auth, sender,
[]string{username}, []byte(msg))
if err != nil {
log.Printf("smtp.SendEmail(%s) failed: %s", username, err)
}
}
//检查quota,quota不足将发邮件
func CheckQuota(username string) {
used := bytesInUse(username)
const quota = 1000000000 // 1GB
percent := 100 * used / quota
if percent < 90 {
return // OK
}
msg := fmt.Sprintf(template, used, percent)
notifyUser(username, msg) //<---发邮件
}
显然,在跑单元测试的过程中,我们肯定不会真的给用户发邮件。在书中采用了stub的方式来进行测试:
//storage_test.go
func TestCheckQuotaNotifiesUser(t *testing.T) {
var notifiedUser, notifiedMsg string
notifyUser = func(user, msg string) { //<-看这里就够了,在测试中,覆盖了发送邮件的全局变量
notifiedUser, notifiedMsg = user, msg
}
// ...simulate a 980MB-used condition...
const user = "joe@example.org"
CheckQuota(user)
if notifiedUser == "" && notifiedMsg == "" {
t.Fatalf("notifyUser not called")
}
if notifiedUser != user {
t.Errorf("wrong user (%s) notified, want %s",
notifiedUser, user)
}
const wantSubstring = "98% of your quota"
if !strings.Contains(notifiedMsg, wantSubstring) {
t.Errorf("unexpected notification message <<%s>>, "+
"want substring %q", notifiedMsg, wantSubstring)
}
}
可以看到,在Go中,如果要用stub,那将是侵入式的,必须将生产代码设计成可以用stub方法替换的形式。上述例子体现出来的结果就是:为了测试,专门用一个全局变量 notifyUser来保存了具有外部依赖的方法。然而在不提倡使用全局变量的Go语言当中,这显然是不合适的。所以,并不提倡这种Stub方式。
Mock与Stub相结合
既然不提倡Stub方式,那是不是在Go测试当中就可以抛弃Stub了呢?原本我是这么认为的,但直到我读了这篇译文Golang 标准包布局译,虽然这篇译文讲的是包的布局,但里面的测试示例很值得学习。
//生产代码 myapp.go
package myapp
type User struct {
ID int
Name string
Address Address
}
//User的一些增删改查
type UserService interface {
User(id int) (*User, error)
Users() ([]*User, error)
CreateUser(u *User) error
DeleteUser(id int) error
}
常规Mock方式:
//测试代码 myapp_test.go
type userService struct{
}
func (u* userService) User(id int) (*User,error) {
return &User{Id:1,Name:"name",Address:"address"},nil
}
//..省略其他实现方法
//模拟user不存在
type userNotFound struct {
u UserService
}
func (u* userNotFound) User(id int) (*User,error) {
return nil,errors.New("not found")
}
//其他...
一般来说,mock结构体内部很少会放变量,针对每一个要模拟的场景(比如上面的user不存在),最政治正确的方法应该是新建一个mock结构体。这样有两个好处:
- mock出来的结构体十分简单,不需要进行额外的设置,不容易出错。
- mock出来的结构体职责单一,测试代码自说明能力更强,可读性更高。
但在刚才提到的文章中,他是这么做的:
//测试代码
// UserService 代表一个myapp.UserService.的 mock实现
type UserService struct {
UserFn func(id int) (*myapp.User, error)
UserInvoked bool
UsersFn func() ([]*myapp.User, error)
UsersInvoked bool
// 其他接口方法补全..
}
// User调用mock实现, 并标记这个方法为已调用
func (s *UserService) User(id int) (*myapp.User, error) {
s.UserInvoked = true
return s.UserFn(id)
}
这里不仅实现了接口,还通过在结构体内放置与接口方法函数签名一致的方法( UserFnUsersFn...),以及 XxxInvoked是否调用标识符来追踪方法的调用情况。这种做法其实将mock与stub相结合了起来:在mock对象的内部放置了可以被测试函数替换的函数变量( UserFn UsersFn…)。我们可以在我们的测试函数中,根据测试的需要,手动更换函数实现。
//mock与stub结合的方式
func TestUserNotFound(t *testing.T) {
userNotFound := &UserService{}
userNotFound.UserFn = func(id int) (*myapp.User, error) { //<--- 设置UserFn的期望返回结果
return nil,errors.New("not found")
}
//后续业务测试代码...
if !userNotFound.UserInvoked {
t.Fatal("没有调用User()方法")
}
}
// 常规mock方式
func TestUserNotFound(t *testing.T) {
userNotFound := &userNotFound{} //<---结构体方法已经决定了返回值
//后续业务测试代码
}
通过将mock与stub结合,不仅能在测试方法中动态的更改实现,还追踪方法的调用情况,上述例子中只是追踪了方法是否被调用,实际中,如果有需要,我们也可以追踪方法的调用次数,甚至是方法的调用顺序:
type UserService struct {
UserFn func(id int) (*myapp.User, error)
UserInvoked bool
UserInvokedTime int //<--追踪调用次数
UsersFn func() ([]*myapp.User, error)
UsersInvoked bool
// 其他接口方法补全..
FnCallStack []string //<---函数名slice,追踪调用顺序
}
// User调用mock实现, 并标记这个方法为已调用
func (s *UserService) User(id int) (*myapp.User, error) {
s.UserInvoked = true
s.UserInvokedTime++ //<--调用发次数
s.FnCallStack = append(s.FnCallStack,"User") //调用顺序
return s.UserFn(id)
}
但同时,我们也会发现我们的mock结构体更复杂了,维护成本也随之增加了。两种mock风格各有各的好处,反正要记得软件工程没有银弹,合适的场景选用合适的方法就行了。 但总体而言,mock与stub相结合的这种方式的确是一种不错的测试思路,尤其是当我们需要追踪函数是否调用,调用次数,调用顺序等信息时,mock+stub将是我们的不二选择。举个例子:
//缓存依赖
type Cache interface{
Get(id int) interface{} //获取某id的缓存
Put(id int,obj interface{}) //放入缓存
}
//数据库依赖
type UserRepository interface{
//....
}
//User结构体
type User struct {
//...
}
//userservice
type UserService interface{
cache Cache
repository UserRepository
}
func (u *UserService) Get(id int) *User {
//先从缓存找,缓存找不到在去repository里面找
}
func main() {
userService := NewUserService(xxx) //注入一些外部依赖
user := userService.Get(2) //获取id = 2的user
}
现在要测试 userService.Get(id)方法的行为:
- Cache命中之后是否还查数据库?(不应该再查了)
- Cache未命中的情况下是否会查库?
- ….
这种测试通过mock+stub结合做起来将会非常方便,作为小练习,可以尝试自己实现一下。
使用依赖注入传递接口
接口需要以依赖注入的方式注入到结构体中,这样才能为测试提供替换接口实现的可能。Why?我们先看一个反面例子,形如下面的写法是无法测试的:
type A interface {
Fun1()
}
func (f *Foo) Bar() {
a := NewInstanceOfA(...参数若干) //生成A接口的某个实现
a.Fun1() //调用接口方法
}
当你辛辛苦苦的将A接口mock出来后,却发现你根本没有办法在Bar()方法中将mock对象替换进去。下面来看看正确的写法:
type A interface {
Fun1()
}
type Foo struct {
a A // A接口
}
func (f *Foo) Bar() {
f.a.Fun1() //调用接口方法
}
// NewFoo, 通过构造函数的方式,将A接口注入
func NewFoo(a A) *Foo {
return &Foo{a: A}
}
在例子中我们使用了构造函数传参的方法来做依赖注入(当然你也可以用setter的方式做)。在测试的时候,就可以通过NewFoo()方法将我们的mock对象传递给*Foo了。
通常我们会在
main.go中进行依赖注入
总结一下
长篇大论了一大堆,稍微总结一下单元测试的几个关键步骤:
- 识别依赖(网络,文件,未完成的功能等等)
- 将依赖抽象成接口
- 在
main.go中使用依赖注入方式将接口注入
现在,我们已经对单元测试有了一个基本的认识,如果你能完成文中的小练习,那么恭喜你,你已经理解应当如何做单元测试,并成功迈出第一步了。在下一篇文章中,将介绍gomock测试框架,提高我们的测试效率。
1.2.1.4 - Golang单元测试02
搞定Go单元测试(二)—— mock框架(gomock)
通过阅读上一篇文章,相信你对怎么做单元测试已经有了初步的概念,可以着手对现有的项目进行改造并开展测试了。学会了走路,我们尝试跑起来,本篇主要介绍gomock测试框架,让我们的单元测试更加有效率。
表格驱动测试方法(Table Driven Tests)
当针对某方法进行单元测试的时候,通常不止写一个测试用例,我们需要测试该方法在多种入参条件下是否都能正常工作,特别是要针对边界值进行测试。通常这个时候表格驱动测试就派上用场了——当你发现你在写测试方法的时候用上了复制粘贴,这就说明你需要考虑使用表格驱动测试来构建你的测试方法了。我们依旧来举个例子:
func TestTime(t *testing.T) {
testCases := []struct { // 设计我们的测试用例
gmt string
loc string
want string
}{
{"12:31", "Europe/Zuri", "13:31"}, // incorrect location name
{"12:31", "America/New_York", "7:31"}, // should be 07:31
{"08:08", "Australia/Sydney", "18:08"},
}
for _, tc := range testCases { // 循环执行测试用例
loc, err := time.LoadLocation(tc.loc)
if err != nil {
t.Fatalf("could not load location %q", tc.loc)
}
gmt, _ := time.Parse("15:04", tc.gmt)
if got := gmt.In(loc).Format("15:04"); got != tc.want {
t.Errorf("In(%s, %s) = %s; want %s", tc.gmt, tc.loc, got, tc.want)
}
}
}
表格驱动测试方法让我们的测试方法更加清晰和简练,减少了复制粘贴,并大大提高的测试代码的可读性。
还记得上文说单元测试也是需要维护的吗?单元测试也是代码的一部分,也应当被认真对待。记得要用表格驱动测试的方法来组织你的测试用例,同时别忘了像正式代码那样,写上相应的注释。 更多参考: github.com/golang/go/w… blog.golang.org/subtests
使用测试框架——gomock
What is gomock?
gomock是Google开源的golang测试框架。或者引用官方的话来说:“GoMock is a mocking framework for the Go programming language”。
Why gomock?
上篇文章末尾介绍了mock和stub相结合的测试方法,可以感受到mock与stub结合起来功能固然强大——调用顺序检测,调用次数检测,动态控制函数的返回值等等,但同时,其带来的维护成本和复杂度缺是不可忽视的,手动维护这样一套测试代码那将是一场灾难。我们期望能用一套框架或者工具,在提供强大的测试功能的同时帮我们维护复杂的mock代码。
How does it work?
gomock通过mockgen命令生成包含mock对象的.go文件,其生成的mock对象具备mock+stub的强大功能,并将我们从写mock对象中解放了出来:
mockgen -destination foo_mock.go -source foo.go -package foo //mock foo.go里面所有的接口,将mock结果保存到foo_mock.go
gomock让我们既能使用mock与stub结合的强大功能,又不需要手动维护这些mock对象,岂不美哉?
举个栗子
在这里我们对gomock的基本功能做一个简单演示: 假设我们的接口定义在 user.go:
// user.go
package user
// User 表示一个用户
type User struct {
Name string
}
// UserRepository 用户仓库
type UserRepository interface {
// 根据用户id查询得到一个用户或是错误信息
FindOne(id int) (*User,error)
}
通过mockgen在同目录下生成mock文件user_mock.go
mockgen -source user.go -destination user_mock.go -package user
然后在该目录下新建user_test.go来写我们的测试函数,上述步骤完成之后,我们的目录结构如下:
└── user
├── user.go
├── user_mock.go
└── user_test.go
设置函数的返回值
// 静态设置返回值
func TestReturn(t *testing.T) {
ctrl := gomock.NewController(t)
defer ctrl.Finish()
repo := NewMockUserRepository(ctrl)
// 期望FindOne(1)返回张三用户
repo.EXPECT().FindOne(1).Return(&User{Name: "张三"}, nil)
// 期望FindOne(2)返回李四用户
repo.EXPECT().FindOne(2).Return(&User{Name: "李四"}, nil)
// 期望给FindOne(3)返回找不到用户的错误
repo.EXPECT().FindOne(3).Return(nil, errors.New("user not found"))
// 验证一下结果
log.Println(repo.FindOne(1)) // 这是张三
log.Println(repo.FindOne(2)) // 这是李四
log.Println(repo.FindOne(3)) // user not found
log.Println(repo.FindOne(4)) //没有设置4的返回值,却执行了调用,测试不通过
}
// 动态设置返回值
func TestReturnDynamic(t *testing.T) {
ctrl := gomock.NewController(t)
defer ctrl.Finish()
repo := NewMockUserRepository(ctrl)
// 常用方法之一:DoAndReturn(),动态设置返回值
repo.EXPECT().FindOne(gomock.Any()).DoAndReturn(func(i int) (*User,error) {
if i == 0 {
return nil, errors.New("user not found")
}
if i < 100 {
return &User{
Name:"小于100",
}, nil
} else {
return &User{
Name:"大于等于100",
}, nil
}
})
log.Println(repo.FindOne(120))
//log.Println(repo.FindOne(66))
//log.Println(repo.FindOne(0))
}
调用次数检测
func TestTimes(t *testing.T) {
ctrl := gomock.NewController(t)
defer ctrl.Finish()
repo := NewMockUserRepository(ctrl)
// 默认期望调用一次
repo.EXPECT().FindOne(1).Return(&User{Name: "张三"}, nil)
// 期望调用2次
repo.EXPECT().FindOne(2).Return(&User{Name: "李四"}, nil).Times(2)
// 调用多少次可以,包括0次
repo.EXPECT().FindOne(3).Return(nil, errors.New("user not found")).AnyTimes()
// 验证一下结果
log.Println(repo.FindOne(1)) // 这是张三
log.Println(repo.FindOne(2)) // 这是李四
log.Println(repo.FindOne(2)) // FindOne(2) 需调用两次,注释本行代码将导致测试不通过
log.Println(repo.FindOne(3)) // user not found, 不限调用次数,注释掉本行也能通过测试
}
调用顺序检测
func TestOrder(t *testing.T) {
ctrl := gomock.NewController(t)
defer ctrl.Finish()
repo := NewMockUserRepository(ctrl)
o1 := repo.EXPECT().FindOne(1).Return(&User{Name: "张三"}, nil)
o2 := repo.EXPECT().FindOne(2).Return(&User{Name: "李四"}, nil)
o3 := repo.EXPECT().FindOne(3).Return(nil, errors.New("user not found"))
gomock.InOrder(o1, o2, o3) //设置调用顺序
// 按顺序调用,验证一下结果
log.Println(repo.FindOne(1)) // 这是张三
log.Println(repo.FindOne(2)) // 这是李四
log.Println(repo.FindOne(3)) // user not found
// 如果我们调整了调用顺序,将导致测试不通过:
// log.Println(repo.FindOne(2)) // 这是李四
// log.Println(repo.FindOne(1)) // 这是张三
// log.Println(repo.FindOne(3)) // user not found
}
上面的示例只展现了gomock功能的冰山一角,在本篇中不再深入讨论,更多用法请参考文档。
更多官方示例:github.com/golang/mock…
如果你完成了上一章的小练习,尝试动手使用gomock改造一下吧!
总结一下
本篇介绍了表格驱动测试与gomock测试框架。运用表格驱动测试方法不仅能使测试代码更精简易读,还能提高我们测试用例的编写能力,无形中提升了单元测试的质量。gomock的功能十分丰富,想掌握各种骚操作还是要细心阅读一下官方示例,但通常20%的常规功能也足够覆盖80%的测试场景了。
表格驱动单元测试和gomock将我们的单元测试效率与质量提升了一个档次。在下一篇文章中,将介绍 testify断言库,继续优化我们的单元测试。
1.2.1.5 - Golang单元测试03
搞定Go单元测试(三)—— 断言(testify)
在上一篇,介绍了表格驱动测试方法和gomock测试框架,大大提升了测试效率与质量。本篇将介绍在测试中引入断言(assertion),进一步提升测试效率与质量。
为什么需要断言库
我们先来看看Go标准包中为什么没有断言,官方在FAQ里面回答了这个问题。
总体概括一下大意就是:“Go不提供断言,我们知道这会带来一定的不便,其主要目的是为了防止你们这些程序员在错误处理上偷懒。我们知道这是一个争论点,但是我们觉得这样很coooool~~。”所以,我们引入断言库的原因也很明显了:偷懒,引入断言能为我们提供便利——提高测试效率,增强代码可读性。
testify
在断言库的选择上,我们似乎没有过多的选择,从start数和活跃度来看,基本上是testify一枝独秀。
没有对比就没有伤害,先来看看使用testify之前的测试方法:
func TestSomeFun(t *testing.T){
...
if v != want {
t.Fatalf("v值错误,期望值:%s,实际值:%s", want, v)
}
if err != nil {
t.Fatalf("非预期的错误:%s", err)
}
if objectA != objectB {
if objectA.field1 != objectB.field1 {
// t.Fatalf() field1值错误...bla bla bla
}
if objectA.field2 != objectB.field2 {
// t.Fatalf() field2值错误...bla bla bla
}
// 遍历object所有值... bla bla bla
}
...
}
上述代码充斥着大量if...else..判断,大段错误信息拼装(真·体力活…),运气不好碰到结构体判断要得将其遍历一遍——不直观,低效,实在是不fashion。
现在,我们使用 testify来改造一下上面的测试示例:
func TestSomeFun(t *testing.T){
a := assert.New(t)
...
a.Equal(v, want)
a.Nil(err,"如果你还是想输出自己拼装的错误信息,可以传第三个参数")
a.Equal(objectA, objectB)
...
}
三行搞定,测试含义一目了然——直观,高效,简短,fashion。
总结一下
testify使用简单,提升显著,可谓是用一次就会爱上的懒人神器。在结合表格驱动测试,gomock和testify后,我们已经能写出一手优雅漂亮的单元测试代码了。不过,光测试代码优雅还不够,我们还需要帮main.go也打扮打扮。在下一篇,也是本系列最后一篇文章中,我们将介绍wire依赖注入框架,帮main.go减肥瘦身。
1.2.1.6 - Golang单元测试04
搞定Go单元测试(四)—— 依赖注入框架(wire)
在第一篇文章中提到过,为了让代码可测,需要用依赖注入的方式来构建我们的对象,而通常我们会在main.go做依赖注入,这就导致main.go会越来越臃肿。为了让单元测试得以顺利进行,main.go牺牲了它本应该纤细苗条的身材。太胖的main.go可不是什么好的信号,本篇将介绍依赖注入框架(wire),致力于帮助main.go恢复身材。
臃肿的main
在main.go中做依赖注入,意味着在初始化代码中我们要管理:
- 依赖的初始化顺序
- 依赖之间的关系
对于小型项目而言,依赖的数量比较少,初始化代码不会很多,不需要引入依赖注入框架。但对于依赖较多的中大型项目,初始化代码又臭又长,可读性和维护性变的很差,随意感受一下:
func main() {
config := NewConfig()
// db依赖配置
db, err := ConnectDatabase(config)
if err != nil {
panic(err)
}
// PersonRepository 依赖db
personRepository := NewPersonRepository(db)
// PersonService 依赖配置 和 PersonRepository
personService := NewPersonService(config, personRepository)
// NewServer 依赖配置和PersonService
server := NewServer(config, personService)
server.Run()
}
实践表明,修改有大量依赖关系的初始化代码是一项乏味且耗时的工作。这个时候,我们就需要依赖注入框架来帮忙,简化初始化代码。
使用依赖注入框架——wire
What is wire?
wire是google开源的依赖注入框架。或者引用官方的话来说:“Wire is a code generation tool that automates connecting components using dependency injection”。
Why wire?
除了wire,Go的依赖注入框架还有Uber的dig和Facebook的inject,它们都是使用反射机制来实现运行时依赖注入(runtime dependency injection),而wire则是采用代码生成的方式来达到编译时依赖注入(compile-time dependency injection)。使用反射带来的性能损失倒是其次,更重要的是反射使得代码难以追踪和调试(反射会令Ctrl+左键失效…)。而wire生成的代码是符合程序员常规使用习惯的代码,十分容易理解和调试。 关于wire的优点,在官方博文上有更详细的的介绍: blog.golang.org/wire
How does it work?
本部分内容参考官方博文:blog.golang.org/wire
wire有两个基本的概念:provider和injector。
provider
provider就是普通的Go函数,可以把它看作是某对象的构造函数,我们通过provider告诉wire该对象的依赖情况:
// NewUserStore是*UserStore的provider,表明*UserStore依赖于*Config和 *mysql.DB.
func NewUserStore(cfg *Config, db *mysql.DB) (*UserStore, error) {...}
// NewDefaultConfig是*Config的provider,没有依赖
func NewDefaultConfig() *Config {...}
// NewDB是*mysql.DB的provider,依赖于ConnectionInfo
func NewDB(info ConnectionInfo) (*mysql.DB, error) {...}
// UserStoreSet 可选项,可以使用wire.NewSet将通常会一起使用的依赖组合起来。
var UserStoreSet = wire.NewSet(NewUserStore, NewDefaultConfig)
injector
injector是wire生成的函数,我们通过调用injector来获取我们所需的对象或值,injector会按照依赖关系,按顺序调用provider函数:
// File: wire_gen.go
// Code generated by Wire. DO NOT EDIT.
//go:generate wire
//+build !wireinject
// initUserStore是由wire生成的injector
func initUserStore(info ConnectionInfo) (*UserStore, error) {
// *Config的provider函数
defaultConfig := NewDefaultConfig()
// *mysql.DB的provider函数
db, err := NewDB(info)
if err != nil {
return nil, err
}
// *UserStore的provider函数
userStore, err := NewUserStore(defaultConfig, db)
if err != nil {
return nil, err
}
return userStore, nil
}
injector帮我们把按顺序初始化依赖的步骤给做了,我们在main.go中只需要调用initUserStore方法就能得到我们想要的对象了。
那么wire是怎么知道如何生成injector的呢?我们需要写一个函数来告诉它:
- 定义injector的函数签名
- 在函数中使用
wire.Build方法列举生成injector所需的provider
例如:
// initUserStore用于声明injector的函数签名
func initUserStore(info ConnectionInfo) (*UserStore, error) {
// wire.Build声明要获取一个UserStore需要调用到哪些provider函数
wire.Build(UserStoreSet, NewDB)
return nil, nil // 这些返回值wire并不关心。
}
有了上面的函数,wire就可以得知如何生成injector了。wire生成injector的步骤描述如下:
- 确定所生成injector函数的函数签名:
func initUserStore(info ConnectionInfo) (*UserStore, error) - 感知返回值第一个参数是
*UserStore - 检查
wire.Build列表,找到*UserStore的provider:NewUserStore - 由函数签名
func NewUserStore(cfg *Config, db *mysql.DB)得知NewUserStore依赖于*Config, 和*mysql.DB - 检查
wire.Build列表,找到*Config和*mysql.DB的provider:NewDefaultConfig和NewDB - 由函数签名
func NewDefaultConfig() *Config得知*Config没有其他依赖了。 - 由函数签名
func NewDB(info *ConnectionInfo) (*mysql.DB, error)得知*mysql.DB依赖于ConnectionInfo。 - 检查
wire.Build列表,找不到ConnectionInfo的provider,但在injector函数签名中发现匹配的入参类型,直接使用该参数作为NewDB的入参。 - 感知返回值第二个参数是
error - ….
- 按依赖关系,按顺序调用provider函数,拼装injector函数。
举个栗子
栗子传送门:wire-examples
注意
截止本文发布前,官方表明wire的项目状态是alpha,还不适合到生产环境,API存在变化的可能。 虽然是alpha,但其主要作用是为我们生成依赖注入代码,其生成的代码十分通俗易懂,在做好版本控制的前提下,即使是API发生变化,也不会对生成环境造成多坏的影响。我认为还是可以放心使用的。
总结一下
本篇是本系列的最后一篇,回顾前几篇文章,我们以单元测试的原理与基本思想为基础,介绍了表格驱动测试方法,gomock,testify,wire这几样实用工具,经历了“能写单元测试”到“写好单元测试”不断优化的过程。希望本系列文章能让你有所收获。
1.2.2 - adodb方式连接sqlServer2k
sqlServer2k 基本看不到了,但是某些系统竟然还用。之前项目遇到过就记录下来怎么连,这是全网唯一能真连成功的代码了
go.mod
require (
github.com/go-ole/go-ole v1.2.4 // indirect
github.com/mattn/go-adodb v0.0.1
github.com/robfig/cron/v3 v3.0.1
github.com/wonderivan/logger v1.0.0
golang.org/x/net v0.0.0-20200904194848-62affa334b73 // indirect
)
main.go
package main
import (
"database/sql"
"flag"
"fmt"
"log"
"strconv"
_ "github.com/mattn/go-adodb"
"github.com/robfig/cron/v3"
"github.com/wonderivan/logger"
)
var (
local bool
remoteIP string
remoteDS string
database string
)
func init() {
flag.BoolVar(&local, "local", false, "set window connect.")
flag.StringVar(&remoteIP, "remoteIP", "192.168.0.10", "set up remote mssql of ip.")
flag.StringVar(&remoteDS, "remoteDS", "MSSQLSERVER", "set up remote mssql of datasource.")
flag.StringVar(&database, "database", "drivertest", "set up remote mssql of database.")
}
type Mssql struct {
*sql.DB
dataSource string
database string
windows bool
sa *SA
}
type SA struct {
user string
passwd string
port int
}
func NewMssql() *Mssql {
mssql := new(Mssql)
dataS := "localhost"
if !local {
dataS = fmt.Sprintf("%s\\%s", remoteIP, remoteDS)
}
mssql = &Mssql{
// 如果数据库是默认实例(MSSQLSERVER)则直接使用IP,命名实例需要指明。
// dataSource: "192.168.1.104\\MSSQLSERVER",
dataSource: dataS,
database: database,
// windows: true 为windows身份验证,false 必须设置sa账号和密码
windows: local,
sa: &SA{
user: "elink",
passwd: "elink888",
port: 1433,
},
}
return mssql
}
func (m *Mssql) Open() error {
config := fmt.Sprintf("Provider=SQLOLEDB;Initial Catalog=%s;Data Source=%s",
m.database, m.dataSource)
if m.windows {
config = fmt.Sprintf("%s;Integrated Security=SSPI", config)
} else {
// sql 2000的端口写法和sql 2005以上的有所不同,在Data Source 后以逗号隔开。
config = fmt.Sprintf("%s,%d;user id=%s;password=%s",
config, m.sa.port, m.sa.user, m.sa.passwd)
}
var err error
m.DB, err = sql.Open("adodb", config)
fmt.Println(config)
return err
}
func (m *Mssql) Select() {
rows, err := m.Query("select uid, name from sysusers")
if err != nil {
fmt.Printf("select query err: %s\n", err)
}
i := 0
for rows.Next() {
var id, name string
rows.Scan(&id, &name)
fmt.Printf("id = %s, name = %s\n", id, name)
i++
}
fmt.Println(i)
}
func main() {
// flag.Parse()
// m := NewMssql()
// config1 := fmt.Sprintf("Provider=SQLOLEDB;Initial Catalog=%s;Data Source=%s",
// m.database, m.dataSource)
// if m.windows {
// config1 = fmt.Sprintf("%s;Integrated Security=SSPI", config1)
// } else {
// // sql 2000的端口写法和sql 2005以上的有所不同,在Data Source 后以逗号隔开。
// config1 = fmt.Sprintf("%s,%d;user id=%s;password=%s",
// config1, m.sa.port, m.sa.user, m.sa.passwd)
// }
// fmt.Println(config1)
// err := mssql.Open()
// checkError(err)
// mssql.Select()
// config := fmt.Sprintf("Provider=SQLOLEDB;Initial Catalog=%s;Data Source=%s\\MSSQLSERVER,%s;user id=%s;password=%s",
// "drivertest", "192.168.0.10", "1433", "elink", "elink888")
config := fmt.Sprintf("Provider=SQLOLEDB;Initial Catalog=%s;Data Source=%s\\MSSQLSERVER,%s;user id=%s;password=%s",
"znykt", "37.64.227.132", "1433", "elink", "elink888")
DB, err := sql.Open("adodb", config)
if err != nil {
log.Fatal(err)
}
crontab := cron.New(cron.WithSeconds()) //精确到秒
// 定时任务
deviceStatusOnline_spec := "*/5 * * * * ?" //秒 分 时 日 月 周
// 定义定时器调用的任务函数
_, err = crontab.AddFunc(deviceStatusOnline_spec, func() {
rows, err := DB.Query("select top 200 id from MYCARGOOUTRECORD order by id desc")
if err != nil {
fmt.Printf("select query err: %s\n", err)
}
i := 0
for rows.Next() {
// var id, name string
// rows.Scan(&id, &name)
// fmt.Printf("id = %s, name = %s\n", id, name)
i++
}
logger.Info("结果数量:" + strconv.Itoa(i))
})
if err != nil {
log.Fatal(err)
}
// 启动定时器
crontab.Start()
select {}
}
// func checkError(err error) {
// if err != nil {
// log.Fatal(err)
// }
// }
1.2.3 - AES-ECB-PKCS5
AES-ECB-PKCS5,附上对应java能相互加解密的 java代码 aes的ecb模式是对称假面
package main
import (
"bytes"
"crypto/aes"
"crypto/cipher"
"encoding/base64"
"encoding/hex"
"fmt"
"strings"
)
func Base64URLDecode(data string) ([]byte, error) {
var missing = (4 - len(data)%4) % 4
data += strings.Repeat("=", missing)
res, err := base64.URLEncoding.DecodeString(data)
fmt.Println(" decodebase64urlsafe is :", string(res), err)
return base64.URLEncoding.DecodeString(data)
}
func Base64UrlSafeEncode(source []byte) string {
// Base64 Url Safe is the same as Base64 but does not contain '/' and '+' (replaced by '_' and '-') and trailing '=' are removed.
bytearr := base64.StdEncoding.EncodeToString(source)
safeurl := strings.Replace(string(bytearr), "/", "_", -1)
safeurl = strings.Replace(safeurl, "+", "-", -1)
safeurl = strings.Replace(safeurl, "=", "", -1)
return safeurl
}
func AesDecrypt(crypted, key []byte) []byte {
block, err := aes.NewCipher(key)
if err != nil {
fmt.Println("err is:", err)
}
blockMode := NewECBDecrypter(block)
origData := make([]byte, len(crypted))
blockMode.CryptBlocks(origData, crypted)
origData = PKCS5UnPadding(origData)
// fmt.Println("source is :", origData, string(origData))
return origData
}
func AesEncrypt(src, key string) []byte {
block, err := aes.NewCipher([]byte(key))
if err != nil {
fmt.Println("key error1", err)
}
if src == "" {
fmt.Println("plain content empty")
}
ecb := NewECBEncrypter(block)
content := []byte(src)
content = PKCS5Padding(content, block.BlockSize())
crypted := make([]byte, len(content))
ecb.CryptBlocks(crypted, content)
// 普通base64编码加密 区别于urlsafe base64
// fmt.Println("base64 result:", base64.StdEncoding.EncodeToString(crypted))
// fmt.Println("base64UrlSafe result:", Base64UrlSafeEncode(crypted))
return crypted
}
func PKCS5Padding(ciphertext []byte, blockSize int) []byte {
padding := blockSize - len(ciphertext)%blockSize
padtext := bytes.Repeat([]byte{byte(padding)}, padding)
return append(ciphertext, padtext...)
}
func PKCS5UnPadding(origData []byte) []byte {
length := len(origData)
// 去掉最后一个字节 unpadding 次
unpadding := int(origData[length-1])
return origData[:(length - unpadding)]
}
type ecb struct {
b cipher.Block
blockSize int
}
func newECB(b cipher.Block) *ecb {
return &ecb{
b: b,
blockSize: b.BlockSize(),
}
}
type ecbEncrypter ecb
// NewECBEncrypter returns a BlockMode which encrypts in electronic code book
// mode, using the given Block.
func NewECBEncrypter(b cipher.Block) cipher.BlockMode {
return (*ecbEncrypter)(newECB(b))
}
func (x *ecbEncrypter) BlockSize() int { return x.blockSize }
func (x *ecbEncrypter) CryptBlocks(dst, src []byte) {
if len(src)%x.blockSize != 0 {
panic("crypto/cipher: input not full blocks")
}
if len(dst) < len(src) {
panic("crypto/cipher: output smaller than input")
}
for len(src) > 0 {
x.b.Encrypt(dst, src[:x.blockSize])
src = src[x.blockSize:]
dst = dst[x.blockSize:]
}
}
type ecbDecrypter ecb
// NewECBDecrypter returns a BlockMode which decrypts in electronic code book
// mode, using the given Block.
func NewECBDecrypter(b cipher.Block) cipher.BlockMode {
return (*ecbDecrypter)(newECB(b))
}
func (x *ecbDecrypter) BlockSize() int { return x.blockSize }
func (x *ecbDecrypter) CryptBlocks(dst, src []byte) {
if len(src)%x.blockSize != 0 {
panic("crypto/cipher: input not full blocks")
}
if len(dst) < len(src) {
panic("crypto/cipher: output smaller than input")
}
for len(src) > 0 {
x.b.Decrypt(dst, src[:x.blockSize])
src = src[x.blockSize:]
dst = dst[x.blockSize:]
}
}
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
}
func main() {
key, _ := base64.StdEncoding.DecodeString("cmVmb3JtZXJyZWZvcm1lcg==")
strkey := string(key)
fmt.Println(strkey)
fmt.Println([]byte(strkey))
fmt.Println()
fmt.Println()
fmt.Println()
// wait_encode_str := "{\"stationNo\":\"241\"}"
// encode_str := AesEncrypt(wait_encode_str, "reformerreformer")
// hex.EncodeToString(encode_str)
// fmt.Println(hex.EncodeToString(encode_str))
wait_decode_str := "34D4F1A0506840B2A6D93C20C098312FAEE02E16FC26144A0621512E9F20CBB0AD121A74EFAD7A8935B132981D6C4198E06B8949E593E2A7D6AB4AB640CC498EE58CD0A66B5B0BBAAE1DBF4C9E4A02DE5658319E93B46831595515FA9F8EFD4202631F09DADDCD575B40C7F76739B31393A455B10AE73B2093EBD6B58DB88D24ACFB0F1DD123A9883051C8986BE060A168024690058318B8271F12E9D4795ACED75BDCC4F1F9AF75743BB81066F64D934B02CD41BE0528F2CEFFC3C40AC1645CA53943024C236A75F247DF3131704BECA1AFE7ADB81343E6D5914940F4E608BECF0D290EDD3B0F0B1F9CE0CD1557479B9E888007A48B19557A989E325193BD0F3EF40C9530B6B6F0D60F231A2EA2A58E9EA0D3B212E6C7BD177D0165C3FB052CBB672E9591D57F81115EBAEF9DC8116813F8D67289A440403D3CC9C7B0F716736E04780C06FCE2BC2D01938AE55A14FD6E0965A241608A371136FC9229BB61093367C8E674AAA35C66F4004C6478C11DE085A81A8D289DDF47EFA422BB9311355FB35218112F26981084812B3FBA2CC55D1267804FE913495C1518342E94B1C45A122B0516C01488D7FB6FEB3A06F37F"
hex_data, _ := hex.DecodeString(wait_decode_str)
decode_str := AesDecrypt(hex_data, key)
fmt.Println(string(decode_str))
// b1, _ := Base64URLDecode("cmVmb3JtZXJyZWZvcm1lcg==")
// fmt.Println(string(b1))
// b2 := Base64UrlSafeEncode([]byte("reformerreformer"))
// fmt.Println(b2)
}
import java.security.Key;
import java.security.NoSuchAlgorithmException;
import javax.crypto.Cipher;
import javax.crypto.KeyGenerator;
import javax.crypto.SecretKey;
import javax.crypto.spec.SecretKeySpec;
import org.apache.commons.codec.binary.Base64;
import sun.misc.BASE64Decoder;
import sun.misc.BASE64Encoder;
/**
* AES加密类
*
*/
public class AESUtils {
/**
* 密钥算法
*/
private static final String KEY_ALGORITHM = "AES";
private static final String DEFAULT_CIPHER_ALGORITHM = "AES/ECB/PKCS5Padding";
/**
* 初始化密钥
*
* @return byte[] 密钥
* @throws Exception
*/
public static byte[] initSecretKey() {
// 返回生成指定算法的秘密密钥的 KeyGenerator 对象
KeyGenerator kg = null;
try {
kg = KeyGenerator.getInstance(KEY_ALGORITHM);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
return new byte[0];
}
// 初始化此密钥生成器,使其具有确定的密钥大小
// AES 要求密钥长度为 128
kg.init(128);
// 生成一个密钥
SecretKey secretKey = kg.generateKey();
return secretKey.getEncoded();
}
/**
* 转换密钥
*
* @param key
* 二进制密钥
* @return 密钥
*/
public static Key toKey(byte[] key) {
// 生成密钥
return new SecretKeySpec(key, KEY_ALGORITHM);
}
/**
* 加密
*
* @param data
* 待加密数据
* @param key
* 密钥
* @return byte[] 加密数据
* @throws Exception
*/
public static byte[] encrypt(byte[] data, Key key) throws Exception {
return encrypt(data, key, DEFAULT_CIPHER_ALGORITHM);
}
/**
* 加密
*
* @param data
* 待加密数据
* @param key
* 二进制密钥
* @return byte[] 加密数据
* @throws Exception
*/
public static byte[] encrypt(byte[] data, byte[] key) throws Exception {
return encrypt(data, key, DEFAULT_CIPHER_ALGORITHM);
}
/**
* 加密
*
* @param data
* 待加密数据
* @param key
* 二进制密钥
* @param cipherAlgorithm
* 加密算法/工作模式/填充方式
* @return byte[] 加密数据
* @throws Exception
*/
public static byte[] encrypt(byte[] data, byte[] key, String cipherAlgorithm) throws Exception {
// 还原密钥
Key k = toKey(key);
return encrypt(data, k, cipherAlgorithm);
}
/**
* 加密
*
* @param data
* 待加密数据
* @param key
* 密钥
* @param cipherAlgorithm
* 加密算法/工作模式/填充方式
* @return byte[] 加密数据
* @throws Exception
*/
public static byte[] encrypt(byte[] data, Key key, String cipherAlgorithm) throws Exception {
// 实例化
Cipher cipher = Cipher.getInstance(cipherAlgorithm);
// 使用密钥初始化,设置为加密模式
cipher.init(Cipher.ENCRYPT_MODE, key);
// 执行操作
return cipher.doFinal(data);
}
/**
* 解密
*
* @param data
* 待解密数据
* @param key
* 二进制密钥
* @return byte[] 解密数据
* @throws Exception
*/
public static byte[] decrypt(byte[] data, byte[] key) throws Exception {
return decrypt(data, key, DEFAULT_CIPHER_ALGORITHM);
}
/**
* 解密
*
* @param data
* 待解密数据
* @param key
* 密钥
* @return byte[] 解密数据
* @throws Exception
*/
public static byte[] decrypt(byte[] data, Key key) throws Exception {
return decrypt(data, key, DEFAULT_CIPHER_ALGORITHM);
}
/**
* 解密
*
* @param data
* 待解密数据
* @param key
* 二进制密钥
* @param cipherAlgorithm
* 加密算法/工作模式/填充方式
* @return byte[] 解密数据
* @throws Exception
*/
public static byte[] decrypt(byte[] data, byte[] key, String cipherAlgorithm) throws Exception {
// 还原密钥
Key k = toKey(key);
return decrypt(data, k, cipherAlgorithm);
}
/**
* 解密
*
* @param data
* 待解密数据
* @param key
* 密钥
* @param cipherAlgorithm
* 加密算法/工作模式/填充方式
* @return byte[] 解密数据
* @throws Exception
*/
public static byte[] decrypt(byte[] data, Key key, String cipherAlgorithm) throws Exception {
// 实例化
Cipher cipher = Cipher.getInstance(cipherAlgorithm);
// 使用密钥初始化,设置为解密模式
cipher.init(Cipher.DECRYPT_MODE, key);
// 执行操作
return cipher.doFinal(data);
}
public static String showByteArray(byte[] data) {
if (null == data) {
return null;
}
StringBuilder sb = new StringBuilder("{");
for (byte b : data) {
sb.append(b).append(",");
}
sb.deleteCharAt(sb.length() - 1);
sb.append("}");
return sb.toString();
}
/**
* 将16进制转换为二进制
*
* @param hexStr
* @return
*/
public static byte[] parseHexStr2Byte(String hexStr) {
if (hexStr.length() < 1)
return null;
byte[] result = new byte[hexStr.length() / 2];
for (int i = 0; i < hexStr.length() / 2; i++) {
int high = Integer.parseInt(hexStr.substring(i * 2, i * 2 + 1), 16);
int low = Integer.parseInt(hexStr.substring(i * 2 + 1, i * 2 + 2), 16);
result[i] = (byte) (high * 16 + low);
}
return result;
}
/**
* 将二进制转换成16进制
*
* @param buf
* @return
*/
public static String parseByte2HexStr(byte buf[]) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < buf.length; i++) {
String hex = Integer.toHexString(buf[i] & 0xFF);
if (hex.length() == 1) {
hex = '0' + hex;
}
sb.append(hex.toUpperCase());
}
return sb.toString();
}
/**
* @param str
* @param key
* @return
* @throws Exception
*/
public static String aesEncrypt(String str, String key) throws Exception {
if (str == null || key == null)
return null;
Cipher cipher = Cipher.getInstance("AES/ECB/PKCS5Padding");
cipher.init(Cipher.ENCRYPT_MODE, new SecretKeySpec(key.getBytes("utf-8"), "AES"));
byte[] bytes = cipher.doFinal(str.getBytes("utf-8"));
return new BASE64Encoder().encode(bytes);
}
public static String aesDecrypt(String str, String key) throws Exception {
if (str == null || key == null)
return null;
Cipher cipher = Cipher.getInstance("AES/ECB/PKCS5Padding");
cipher.init(Cipher.DECRYPT_MODE, new SecretKeySpec(key.getBytes("utf-8"), "AES"));
byte[] bytes = new BASE64Decoder().decodeBuffer(str);
bytes = cipher.doFinal(bytes);
return new String(bytes, "utf-8");
}
public static void main(String[] args) throws Exception {
byte[] key = initSecretKey();
System.out.println("key:" + Base64.encodeBase64String(key));
System.out.println("key:" + showByteArray(key));
// 指定key
// String kekkk = "9iEepr1twrizIEKrs1hs2A==";
String kekkk = "cmVmb3JtZXJyZWZvcm1lcg==";
byte[] bs = Base64.decodeBase64(kekkk);
System.out.println(bs);
System.out.println("kekkk:" + showByteArray(Base64.decodeBase64(kekkk)));
Key k = toKey(Base64.decodeBase64(kekkk));
String data = "{\"requestName\":\"BeforeIn\",\"requestValue\":{\"carCode\":\"浙AD0V07\",\"inTime\":\"2016-09-29 10:06:03\",\"inChannelId\":\"4\",\"GUID\":\"1403970b-4eb2-46bc-8f2b-eeec91ddcd5f\",\"inOrOut\":\"0\"},\"Type\":\"0\"}";
// System.out.println("加密前数据: string:" + data);
// System.out.println("加密前数据: byte[]:" + showByteArray(data.getBytes()));
// System.out.println();
byte[] encryptData = encrypt(data.getBytes(), k);
String encryptStr=parseByte2HexStr(encryptData);
System.out.println("加密后数据: byte[]:" + showByteArray(encryptData));
System.out.println("加密后数据: Byte2HexStr:" + encryptStr);
System.out.println();
byte[] encryptStrByte = parseHexStr2Byte("96B742F275ECC2C77374E888CC3AD5D46CDDDAFA3BBA1AA8184D07BED0D957B250DF794666F5ACA787A8D2F20FB7D195C39E78FBDBDDD2F14B00AFC021BA306B03DB52706969E8497F91084CCA48EB81D902E3C32112F1DB07B21B45314ECFA2742F838C368C770F9C21DE07B99844A691269F83C5582A4EE21FB2C22A2168420EBC4AEEE6FB7D3B182AE5158F1F8E62F3BE3AA26C4F220E382B304F91A52A8CD823B68129409BA6059621F3EC0C94BBE8C5A9C1236C9A137536502BB6354D56");
System.out.println(encryptStrByte.length);
byte[] decryptData = decrypt(encryptStrByte, k);
System.out.println("解密后数据: byte[]:" + showByteArray(decryptData));
System.out.println("解密后数据: string:" + new String(decryptData));
}
}
java依赖
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.4</version>
</dependency>
1.2.4 - base64
package main
import (
"encoding/base64"
"fmt"
"strings"
)
//Base64UrlSafeEncode 需要替换掉一些字符
func Base64UrlSafeEncode(source []byte) string {
// Base64 Url Safe is the same as Base64 but does not contain '/' and '+' (replaced by '_' and '-') and trailing '=' are removed.
bytearr := base64.StdEncoding.EncodeToString(source)
safeurl := strings.Replace(string(bytearr), "/", "_", -1)
safeurl = strings.Replace(safeurl, "+", "-", -1)
safeurl = strings.Replace(safeurl, "=", "", -1)
return safeurl
}
func main() {
//标准base64编码
wait_encode_data := "reformerreformer"
wait_decode_data := "cmVmb3JtZXJyZWZvcm1lcg"
//使用标准库自带的方式加密
sEnc := base64.StdEncoding.EncodeToString([]byte(wait_encode_data))
fmt.Println(sEnc)
sDec, _ := base64.StdEncoding.DecodeString("cmVmb3JtZXJyZWZvcm1lcg==")
fmt.Println(string(sDec))
//兼容base64编码
uEnc := base64.URLEncoding.EncodeToString([]byte(wait_encode_data))
fmt.Println(uEnc)
uDec, _ := base64.URLEncoding.DecodeString(wait_decode_data)
fmt.Println(string(uDec))
}
1.2.5 - cbor
CBOR(Concise Binary Object Representation)是一种轻量级的数据交换格式,类似于JSON,但它以二进制形式表示数据,而不是文本形式。CBOR设计用于在网络上传输数据时减少数据的大小和复杂性,同时保持良好的可读性和可扩展性。
package main
import (
"encoding/hex"
"fmt"
"github.com/fxamacker/cbor/v2"
)
func main() {
b, _ := cbor.Marshal("hello world")
fmt.Println(hex.EncodeToString(b))
cborBytes, _ := hex.DecodeString(hex.EncodeToString(b))
s := ""
cbor.Unmarshal(cborBytes, &s)
fmt.Printf("%s", s)
}
1.2.6 - channel
- 顺序执行两个协程
package main
import (
"fmt"
"log"
"math/rand"
"sync"
"time"
)
func main() {
//顺序执行两个协程函数
ch1 := make(chan string, 5)
go testBoringWithChannelClose("boring!", ch1)
ch2 := make(chan string, 5)
go testBoringWithChannelClose("funning!", ch2)
for b := range ch1 {
go log.Printf("You say: %s", b)
}
for b := range ch2 {
go log.Printf("You say: %s", b)
}
}
func testBoringWithChannelClose(msg string, c chan string) {
for i := 0; i < 20; i++ {
c <- fmt.Sprintf("%s %d", msg, i)
time.Sleep(time.Duration(rand.Intn(1e3)) * time.Millisecond)
}
fmt.Println(msg + "结束")
close(c)
}
- 带缓冲的channel 就像一个携程池,去执行协程任务。
package main
import (
"fmt"
"log"
"math/rand"
"sync"
"time"
)
func main() {
//限制1024个协程数执行任务
goNum1024Times()
}
// 控制1024个协程
func goNum1024Times() {
var wg sync.WaitGroup
ch := make(chan struct{}, 1024)
for i := 0; i < 20000; i++ {
wg.Add(1)
ch <- struct{}{}
go func() {
defer wg.Done()
fmt.Printf("%d\n", len(ch)) //打印通道的长度
<-ch
}()
}
wg.Wait()
}
1.2.7 - CRC16
package main
import (
"CRC15/method" //因为gomod 定义了模块名为 module CRC15 所以引用目录下的method
"encoding/hex"
"fmt"
"strings"
)
func main() {
byteArr, _ := hex.DecodeString("7F39F60116C067321223344556677889800112230100000000F700000000000000000000000000000000323030B7C2D8BB353030FABBF7D63130")
checkVal := method.UsMBCRC16(byteArr)
fmt.Println(strings.ToUpper(fmt.Sprintf("%X", checkVal)))
}
go.mod
module CRC15
go 1.13
method/crc16.go
package method
import (
"encoding/hex"
"fmt"
"strings"
)
var auchCRCLo = [256]uint8{
0x00, 0xC0, 0xC1, 0x01, 0xC3, 0x03, 0x02, 0xC2, 0xC6, 0x06,
0x07, 0xC7, 0x05, 0xC5, 0xC4, 0x04, 0xCC, 0x0C, 0x0D, 0xCD,
0x0F, 0xCF, 0xCE, 0x0E, 0x0A, 0xCA, 0xCB, 0x0B, 0xC9, 0x09,
0x08, 0xC8, 0xD8, 0x18, 0x19, 0xD9, 0x1B, 0xDB, 0xDA, 0x1A,
0x1E, 0xDE, 0xDF, 0x1F, 0xDD, 0x1D, 0x1C, 0xDC, 0x14, 0xD4,
0xD5, 0x15, 0xD7, 0x17, 0x16, 0xD6, 0xD2, 0x12, 0x13, 0xD3,
0x11, 0xD1, 0xD0, 0x10, 0xF0, 0x30, 0x31, 0xF1, 0x33, 0xF3,
0xF2, 0x32, 0x36, 0xF6, 0xF7, 0x37, 0xF5, 0x35, 0x34, 0xF4,
0x3C, 0xFC, 0xFD, 0x3D, 0xFF, 0x3F, 0x3E, 0xFE, 0xFA, 0x3A,
0x3B, 0xFB, 0x39, 0xF9, 0xF8, 0x38, 0x28, 0xE8, 0xE9, 0x29,
0xEB, 0x2B, 0x2A, 0xEA, 0xEE, 0x2E, 0x2F, 0xEF, 0x2D, 0xED,
0xEC, 0x2C, 0xE4, 0x24, 0x25, 0xE5, 0x27, 0xE7, 0xE6, 0x26,
0x22, 0xE2, 0xE3, 0x23, 0xE1, 0x21, 0x20, 0xE0, 0xA0, 0x60,
0x61, 0xA1, 0x63, 0xA3, 0xA2, 0x62, 0x66, 0xA6, 0xA7, 0x67,
0xA5, 0x65, 0x64, 0xA4, 0x6C, 0xAC, 0xAD, 0x6D, 0xAF, 0x6F,
0x6E, 0xAE, 0xAA, 0x6A, 0x6B, 0xAB, 0x69, 0xA9, 0xA8, 0x68,
0x78, 0xB8, 0xB9, 0x79, 0xBB, 0x7B, 0x7A, 0xBA, 0xBE, 0x7E,
0x7F, 0xBF, 0x7D, 0xBD, 0xBC, 0x7C, 0xB4, 0x74, 0x75, 0xB5,
0x77, 0xB7, 0xB6, 0x76, 0x72, 0xB2, 0xB3, 0x73, 0xB1, 0x71,
0x70, 0xB0, 0x50, 0x90, 0x91, 0x51, 0x93, 0x53, 0x52, 0x92,
0x96, 0x56, 0x57, 0x97, 0x55, 0x95, 0x94, 0x54, 0x9C, 0x5C,
0x5D, 0x9D, 0x5F, 0x9F, 0x9E, 0x5E, 0x5A, 0x9A, 0x9B, 0x5B,
0x99, 0x59, 0x58, 0x98, 0x88, 0x48, 0x49, 0x89, 0x4B, 0x8B,
0x8A, 0x4A, 0x4E, 0x8E, 0x8F, 0x4F, 0x8D, 0x4D, 0x4C, 0x8C,
0x44, 0x84, 0x85, 0x45, 0x87, 0x47, 0x46, 0x86, 0x82, 0x42,
0x43, 0x83, 0x41, 0x81, 0x80, 0x40,
}
var auchCRCHi = [256]uint8{
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0,
0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0,
0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1,
0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1,
0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0,
0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40,
0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1,
0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0,
0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40,
0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0,
0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0,
0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0,
0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41,
0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0,
0x80, 0x41, 0x00, 0xC1, 0x81, 0x40, 0x00, 0xC1, 0x81, 0x40,
0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0, 0x80, 0x41, 0x00, 0xC1,
0x81, 0x40, 0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41,
0x00, 0xC1, 0x81, 0x40, 0x01, 0xC0, 0x80, 0x41, 0x01, 0xC0,
0x80, 0x41, 0x00, 0xC1, 0x81, 0x40,
}
func UsMBCRC16(pucFrame []byte) int {
ucCRCHi := 0xFF
ucCRCLo := 0xFF
iIndex := 0
for i := 0; i < len(pucFrame); i++ {
iIndex = ucCRCLo ^ int(pucFrame[i])
ucCRCLo = ucCRCHi ^ int(auchCRCHi[iIndex])
ucCRCHi = int(auchCRCLo[iIndex])
}
return ucCRCLo<<8 | ucCRCHi
}
func TopscommCrc16(param string, check string) bool {
byteArr, _ := hex.DecodeString(param)
checkVal := UsMBCRC16(byteArr)
h := fmt.Sprintf("%X", checkVal)
if h != strings.ToUpper(check) {
return false
}
return true
}
1.2.8 - gorm连接mssql
go.mod
require (
github.com/denisenkom/go-mssqldb v0.0.0-20200620013148-b91950f658ec
github.com/jinzhu/gorm v1.9.14
)
package main
import (
"flag"
"fmt"
_ "github.com/denisenkom/go-mssqldb"
"github.com/jinzhu/gorm"
)
type Dt_Cardtype struct {
gorm.Model
ID string `gorm:"id"`
CardCname string `gorm:"CardCname"`
}
var (
debug = flag.Bool("debug", true, "enable debugging")
password = flag.String("password", "Elink666.", "the database password")
port *int = flag.Int("port", 1433, "the database port")
server = flag.String("server", "172.16.183.131", "the database server")
user = flag.String("user", "sa", "the database user")
)
func main() {
connString := fmt.Sprintf("server=%s;user id=%s;password=%s;port=%d;database=carpark", *server, *user, *password, *port)
db, err := gorm.Open("mssql", connString)
if err != nil {
panic("连接数据库失败")
}
defer db.Close()
db.SingularTable(true)
db.LogMode(true)
db.CommonDB()
var dc []Dt_Cardtype
db.Find(&dc)
fmt.Println(len(dc))
// // 自动迁移模式
// db.AutoMigrate(&Product{})
// // 创建
// db.Create(&Product{Code: "L1212", Price: 1000})
// // 读取
// var product Product
// db.First(&product, 1) // 查询id为1的product
// db.First(&product, "code = ?", "L1212") // 查询code为l1212的product
// // 更新 - 更新product的price为2000
// db.Model(&product).Update("Price", 2000)
// // 删除 - 删除product
// db.Delete(&product)
}
1.2.9 - gorose连接mssql
go.mod
require (
github.com/denisenkom/go-mssqldb v0.0.0-20200620013148-b91950f658ec
github.com/gohouse/converter v0.0.3 // indirect
github.com/gohouse/gorose v1.0.5
github.com/gohouse/gorose/v2 v2.1.7
github.com/jinzhu/gorm v1.9.14
)
package main
import (
"flag"
"fmt"
"os"
_ "github.com/denisenkom/go-mssqldb"
gorose "github.com/gohouse/gorose/v2"
)
var err error
var engin *gorose.Engin
type DtCardtype struct {
ID int64 `gorose:"id"`
CardCname string `gorose:"CardCname"`
Mark string `gorose:"Mark"`
}
var (
debug = flag.Bool("debug", true, "enable debugging")
password = flag.String("password", "123456", "the database password")
port *int = flag.Int("port", 1433, "the database port")
server = flag.String("server", "10.10.10.53", "the database server")
user = flag.String("user", "sa", "the database user")
)
func init() {
// 全局初始化数据库,并复用
// 这里的engin需要全局保存,可以用全局变量,也可以用单例
// 配置&gorose.Config{}是单一数据库配置
// 如果配置读写分离集群,则使用&gorose.ConfigCluster{}
// mysql Dsn示例 "root:root@tcp(localhost:3306)/test?charset=utf8&parseTime=true"
connString := fmt.Sprintf("server=%s;user id=%s;password=%s;port=%d;database=carpark", *server, *user, *password, *port)
engin, err = gorose.Open(&gorose.Config{Driver: "mssql", Dsn: connString})
if err != nil {
fmt.Println(err)
os.Exit(-1)
}
}
func DB() gorose.IOrm {
return engin.NewOrm()
}
func main() {
var u []DtCardtype
DB().Table("Park").First()
fmt.Println(u)
}
1.2.10 - go发送get或post请求
package main
import (
"bytes"
"crypto/md5"
"crypto/tls"
"encoding/json"
"fmt"
"io"
"io/ioutil"
"log"
"net/http"
"strconv"
"time"
)
func main() {
// GetData()
PostMethod()
}
//这是get请求
func GetData() {
tr := &http.Transport{
TLSClientConfig: &tls.Config{InsecureSkipVerify: true}} //如果需要测试自签名的证书 这里需要设置跳过证书检测 否则编译报错
client := &http.Client{Transport: tr}
resp, err := client.Get("https://192.168.7.15:8080/v1/getaction.do")
//此处需要注意经过测试,不论是否有err在此之前一定要判断resp.Body如果不为空则需要关闭,测试环境go1.16
if resp.Body != nil {
defer resp.Body.Close()
}
if err != nil {
fmt.Println("error:", err)
return
}
body, err := ioutil.ReadAll(resp.Body)
fmt.Println(string(body))
}
//这是post请求
func PostMethod() {
var rsp io.Reader
tr := &http.Transport{TLSClientConfig: &tls.Config{InsecureSkipVerify: true}} //如果需要测试自签名的证书 这里需要设置跳过证书检测 否则编译报错
client := &http.Client{Transport: tr}
data := "cmd=123"
resp, err := client.Post("https://192.168.7.15:8080/v1/postaction.do", data, rsp)
//此处需要注意经过测试,不论是否有err在此之前一定要判断resp.Body如果不为空则需要关闭,测试环境go1.16
if resp.Body != nil {
defer resp.Body.Close()
}
if err != nil {
fmt.Println("err:", err)
} else {
body, er := ioutil.ReadAll(resp.Body)
if er != nil {
fmt.Println("err:", er)
} else {
fmt.Println(string(body))
}
}
}
func PostMethod() {
//{"carmeraId":"epark-370211-dongjiakou~~cctv-dahua~channelCode~dahua!1000003$1$0$6","carmeraDesc":"","status":"1","areaId":"001","dataTime":"2020-11-17 14:30:12"}
//{"carmeraId":"epark-370211-dongjiakou~~cctv-dahua~channelCode~dahua!1000003$1$0$7","carmeraDesc":"2F走廊西","status":"1","areaId":"001","dataTime":"2020-11-17 15:42:01"}
m3 := map[string]string{
"cameraId": "epark-370211-dongjiakou~~cctv-dahua~channelCode~dahua!1000003$1$0$7",
"cameraDesc": "2F走廊西",
"status": "1",
"areaId": "001",
"dataTime": "2020-11-17 15:42:01",
}
exportData, err := json.Marshal(m3)
tr := &http.Transport{TLSClientConfig: &tls.Config{InsecureSkipVerify: true}}
client := &http.Client{Transport: tr}
req, err := http.NewRequest(http.MethodPost, "https://eug-test.elinkit.com.cn/epmet-acs/report/video/info", bytes.NewReader(exportData))
if err != nil {
log.Fatal(err.Error)
}
times := strconv.FormatInt(time.Now().Unix(), 10)
data := []byte("c3c4029b9741f26ab4a4cbd98c2310ff" + times)
has := md5.Sum(data)
accessToken := fmt.Sprintf("%x", has)
req.Header.Set("Content-Type", "application/json")
req.Header.Set("AccessToken", accessToken)
req.Header.Set("Timestamp", times)
response, err := client.Do(req)
//此处需要注意经过测试,不论是否有err在此之前一定要判断 response.Body 如果不为空则需要关闭,测试环境go1.16
if response.Body != nil {
defer response.Body.Close()
}
if err != nil {
fmt.Println("err:", err)
}
body, er := ioutil.ReadAll(response.Body)
if er != nil {
fmt.Println("err:", er)
}
fmt.Println(string(body))
}
1.2.11 - go脚本编程接受命令行参数
package main
import (
"flag"
"fmt"
)
func main() {
// 定义几个变量,用于接收命令行的参数值
var user string
var password string
var host string
var port int
// &user 就是接收命令行中输入 -u 后面的参数值,其他同理
flag.StringVar(&user, "u", "root", "账号,默认为root")
flag.StringVar(&password, "p", "", "密码,默认为空")
flag.StringVar(&host, "h", "localhost", "主机名,默认为localhost")
flag.IntVar(&port, "P", 3306, "端口号,默认为3306")
// 解析命令行参数写入注册的flag里
flag.Parse()
// 输出结果
fmt.Printf("user:%v\npassword:%v\nhost:%v\nport:%v\n",
user, password, host, port)
}
1.2.12 - hmac算法
HMAC (Hash-based Message Authentication Code)是一种基于哈希函数的消息认证码算法,用于验证数据的完整性和认证消息的发送者。HMAC结合了哈希函数和密钥,通过将密钥与消息进行哈希运算来生成消息认证码
HMAC的工作原理
HMAC使用一个密钥和一个哈希函数(如MD5、SHA-1、SHA-256等)生成一个固定长度的哈希值。具体步骤如下:
输入:消息和密钥。
处理:HMAC对输入的消息和密钥进行哈希处理,生成一个固定长度的哈希值。
输出:该哈希值即为HMAC签名
HMAC的安全性
HMAC的安全性依赖于密钥的保密性和所使用的哈希函数的抗碰撞能力。只有持有密钥的一方能够生成或验证该消息的签名,从而确保消息在传输过程中没有被篡改
HMAC的应用场景
HMAC广泛应用于各种需要确保数据完整性和认证的应用场景中,例如:
IPSec :在IPSec中,HMAC用于验证IP数据包的完整性和真实性。
SSL/TLS :在SSL/TLS协议中,HMAC用于验证通信双方的身份和数据完整性。
package main
import (
"crypto/hmac"
"crypto/sha256"
"encoding/base64"
"fmt"
)
func GenHmacSha256(message string, secret string) string {
h := hmac.New(sha256.New, []byte(secret))
h.Write([]byte(message))
return base64.StdEncoding.EncodeToString(h.Sum(nil))
}
func main() {
key := "VHc1CBWM0YS204rydm+wWxkQrqJSVyXAAgFRktVpOF4="
str := "/report/data/device?timestamp=123456789&appKey=9aON8USr&nonce=123456"
ret := GenHmacSha256(str, key)
fmt.Printf("ret: %s\n", ret)
}
//RdYq6cvBpeF84HO8iQErRF6Aq9XdE2fDx5w4qjDWfrg=
//RdYq6cvBpeF84HO8iQErRF6Aq9XdE2fDx5w4qjDWfrg=
//6D+MQzWc3eU4eqZkXaUQ4xmeviQPljjzs4CQmF18ldk=
//6D+MQzWc3eU4eqZkXaUQ4xmeviQPljjzs4CQmF18ldk=
1.2.13 - md5编码
package main
import (
"crypto/md5"
"fmt"
"io"
)
func main() {
str := "abcdefg"
//方法一
data := []byte(str)
has := md5.Sum(data)
md5str1 := fmt.Sprintf("%x", has) //将[]byte转成16进制
fmt.Println(md5str1)
//方法二
w := md5.New()
io.WriteString(w, str) //将str写入到w中
md5str2 := fmt.Sprintf("%x", w.Sum(nil)) //w.Sum(nil)将w的hash转成[]byte格式
fmt.Println(md5str2)
}
1.2.14 - modbustcp-client
go.mod
require (
github.com/goburrow/modbus v0.1.0
github.com/goburrow/serial v0.1.0 // indirect
)
package main
import (
"log"
"os"
"time"
"github.com/goburrow/modbus"
)
func main() {
handler := modbus.NewTCPClientHandler("localhost:502")
handler.Timeout = 10 * time.Second
handler.SlaveId = 0 //SlaveId即modbustcp协议从0开始得第6字节称,在厂家协议中称为RTU地址无效字段,标准协议中如果是0则为广播地址
handler.Logger = log.New(os.Stdout, "test: ", log.LstdFlags)
// Connect manually so that multiple requests are handled in one connection session
err := handler.Connect()
if err != nil {
log.Fatalf("连接错误:%+v", err)
}
defer handler.Close()
// modbus.Tc
// modbus.NewClient(handler)
client := modbus.NewClient(handler)
log.Printf("客户端:%+v", client)
client.ReadHoldingRegisters(40001, 10)
res, e1 := client.ReadHoldingRegisters(40001, 2)
if e1 != nil {
log.Fatalf("E1错误:%+v", e1)
}
log.Printf("资源内容1:%+v", res)
res, _ = client.ReadHoldingRegisters(40000, 3)
log.Printf("资源内容2:%+v", res)
res, _ = client.ReadHoldingRegisters(40000, 3)
log.Printf("资源内容3:%+v", res)
res, _ = client.ReadHoldingRegisters(40000, 3)
log.Printf("资源内容4:%+v", res)
results1, err := client.ReadDiscreteInputs(15, 2)
results2, err = client.WriteMultipleRegisters(1, 2, []byte{0, 3, 0, 4})
}
1.2.15 - opc-client
package main
import (
"fmt"
"github.com/konimarti/opc"
)
func main() {
client, _ := opc.NewConnection(
"Matrikon.OPC.Simulation.1", // ProgId
[]string{"localhost"}, // OPC servers nodes
[]string{"Random.Real8", "Random.String"}, // slice of OPC tags
)
defer client.Close()
// read single tag: value, quality, timestamp
fmt.Println(client.ReadItem("Random.Real8"))
// read all added tags
fmt.Println(client.Read())
}
1.2.16 - Post上传文件
package main
import (
"bytes"
"encoding/json"
"fmt"
"io"
"io/ioutil"
"log"
"mime/multipart"
"net/http"
"os"
"path/filepath"
)
func newfileUploadRequest(uri string, params map[string]string, paramName, path string) (UploadFileRes, error) {
file, err := os.Open(path)
if err != nil {
return UploadFileRes{}, err
}
defer file.Close()
body := &bytes.Buffer{}
writer := multipart.NewWriter(body)
part, err := writer.CreateFormFile(paramName, filepath.Base(path))
if err != nil {
return UploadFileRes{}, err
}
_, err = io.Copy(part, file)
for key, val := range params {
_ = writer.WriteField(key, val)
}
err = writer.Close()
if err != nil {
return UploadFileRes{}, err
}
request, err := http.NewRequest("POST", uri, body)
if err != nil {
log.Fatal(err)
return UploadFileRes{}, err
}
request.Header.Add("Content-Type", writer.FormDataContentType())
client := &http.Client{}
resp, err := client.Do(request)
if err != nil {
log.Fatal(err)
return UploadFileRes{}, err
} else {
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
// body := &bytes.Buffer{}
// _, err := body.ReadFrom(resp.Body)
if err != nil {
log.Fatal(err)
}
// fmt.Println(resp.StatusCode)
// fmt.Println(resp.Header)
// fmt.Println(body.Bytes())
var uploadFileRes UploadFileRes
json.Unmarshal(body, &uploadFileRes)
return uploadFileRes, nil
}
return UploadFileRes{}, fmt.Errorf("lib throwe")
}
func main() {
extraParams := map[string]string{}
res, err := newfileUploadRequest("http://192.168.1.56:1502/uploadeFile", extraParams, "file", "/home/koala/project/tmp/images/1.png")
if err != nil {
log.Fatal(err)
}
fmt.Println(res)
sep := string(os.PathSeparator)
fmt.Println(sep)
}
type UploadFileRes struct {
ErrCode string `json:"errCode"`
ErrMsg string `json:"errMsg"`
Data string `json:"data"`
}
1.2.17 - RSA-encryption
csdn_private.pem
-----BEGIN csdn_privateKey-----
MIIEpAIBAAKCAQEAv5so1PIs1jaJPJ7fOQBUAzpIqf8kZ7vCETs9sGXCs2XzqwH4
sYyzPcU9NY5CBMMtev9bW0oPyETQCsaS5HtbpgHwRPqRfbcSWZXkodUUUgSNP2ss
/74tMjw4tnx4kxW/EmsZnGJGKuyY7Tf5IlI7QD6U9nWWRKAEsKSbyd/7H3HzLxoB
xZsMbXXI3MgERzJcsmacWPnVG98i7QH0oSu+a7zSse5zSrW/RtKQj8WtAOMVZ7FP
x4fqofj6JGXot4SFBkwSgnPD2613PSPMQn6/G2dHUEJqmqtJr4j8ptP+1T6tWpy0
BVm/WhbkN9ymCOlds+SGMkyeCUs6daBJilQ9VQIDAQABAoIBADDsj2qAQ86WskgW
UO0fFlSUp0Uw7rzGBnGb7M6DzUk9eRBrOnMreAEHwe9Q2a6Zn51OYqdWq9z5JR37
Qjqw/N/QkucqC8hL3JWfXnesDro6i05sMVtD1gqDsf92nNsBrH4pdqqltUD0lL/N
kQGgeZyX3jVoJOx0532rKlRLqrWGU5acSosZqTTuCQEjBH94mA1KTvLy0CqZWyWo
yZ/OBtF61TxXa5qejJl4MJ8050UV8T7tqkckK9h4bColVS58VvnYaKST5bf33YiY
sAbE7/o8B9NW/3ogwJG6yvjXnSnICOLNUofb26zftW9DrcYGmLMnsPtm8Tj2xPLj
7zAjbekCgYEA8CZNYs72yDxJjvewvYmeWSkAO9goVBHQSSyMJcgdhiWG4IkZbaAo
1Mrvs3LBIOY1VMr2OjopzwSupNvKqOokLZ+2zcijvqDmv8AgZdh79JdaRVqqXf83
Zvun6RD1Par8vIfNIWPV/ruiM0QFcgbpd3VshAOJbqLv0QVb3Lb/f5MCgYEAzECj
uf1HKCgguRDvajG8aImES+xWdXubyA0yakS6xiBt9Pyr5sNkcum3FDIynj9/i/ke
MrK/4PtewwYwemWpccWf+EAXhQhj7bqKC5TsQr3gu9eQ+A9RVOGJ7WBJca9VY8q6
7jAWf/UlEx8WPxaV11jtvchzA1erwmMwafLGUHcCgYEAwf9PGHj0psD88z9oSVT4
1DHo/G8b9P4G8nXIKWVFZG7ATHa0UfjFw1DE3oPfPAJ8Jqlmy5bc211+77KWPmoX
G7wf4pEopgA5J8G+6kc9q1LxG4GoixJ24Px+oiqO0mhkjrBtp4GNB6Dv4NYcSAcJ
ZvU22lY5GWUKsiHQGbbDI30CgYEAx9h7GdCaXc0db1YFmrb9LJ9YpVyhn6OI4a0f
5eBHivFSBMFwhIIrd0/7xLP02OcyKcdeZ6aDnWL17gXRSwDLULlXcvNqz8xM0d6R
kRFuNUNJbyFVA5EhN9bROEPcuHIgL1q9ma3NZfd7BgGFp8a2Z5ToUKee+Oc/9BtO
1Gso5LMCgYBZKa3mZp1nmWHn7zlD+HeP/MACs34ZgaR33dGIx9j5jO8s5Gw98wJg
Rfjvuf73Yq9T7VhlJp6mZ+fDVuhrbBlI32Itrb+p7FztIx3rVBXjvvuhqOFDupYl
UttiUvkrWuoTKfbPhKZkKVDYp+fm/dd6JBa+c0+2kuwo6tm/Yr3kbw==
-----END csdn_privateKey-----
csdn_PublicKey.pem
-----BEGIN csdn_PublicKey-----
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAv5so1PIs1jaJPJ7fOQBU
AzpIqf8kZ7vCETs9sGXCs2XzqwH4sYyzPcU9NY5CBMMtev9bW0oPyETQCsaS5Htb
pgHwRPqRfbcSWZXkodUUUgSNP2ss/74tMjw4tnx4kxW/EmsZnGJGKuyY7Tf5IlI7
QD6U9nWWRKAEsKSbyd/7H3HzLxoBxZsMbXXI3MgERzJcsmacWPnVG98i7QH0oSu+
a7zSse5zSrW/RtKQj8WtAOMVZ7FPx4fqofj6JGXot4SFBkwSgnPD2613PSPMQn6/
G2dHUEJqmqtJr4j8ptP+1T6tWpy0BVm/WhbkN9ymCOlds+SGMkyeCUs6daBJilQ9
VQIDAQAB
-----END csdn_PublicKey-----
package main
import (
"crypto/rand"
"crypto/rsa"
"crypto/x509"
"encoding/hex"
"encoding/pem"
"fmt"
"os"
)
func Getkeys() {
//得到私钥
privateKey, _ := rsa.GenerateKey(rand.Reader, 2048)
//通过x509标准将得到的ras私钥序列化为ASN.1 的 DER编码字符串
x509_Privatekey := x509.MarshalPKCS1PrivateKey(privateKey)
//创建一个用来保存私钥的以.pem结尾的文件
fp, _ := os.Create("csdn_private.pem")
defer fp.Close()
//将私钥字符串设置到pem格式块中
pem_block := pem.Block{
Type: "csdn_privateKey",
Bytes: x509_Privatekey,
}
//转码为pem并输出到文件中
pem.Encode(fp, &pem_block)
//处理公钥,公钥包含在私钥中
publickKey := privateKey.PublicKey
//接下来的处理方法同私钥
//通过x509标准将得到的ras私钥序列化为ASN.1 的 DER编码字符串
x509_PublicKey, _ := x509.MarshalPKIXPublicKey(&publickKey)
pem_PublickKey := pem.Block{
Type: "csdn_PublicKey",
Bytes: x509_PublicKey,
}
file, _ := os.Create("csdn_PublicKey.pem")
defer file.Close()
//转码为pem并输出到文件中
pem.Encode(file, &pem_PublickKey)
}
//使用公钥进行加密
func RSA_encrypter(path string, msg []byte) []byte {
//首先从文件中提取公钥
fp, _ := os.Open(path)
defer fp.Close()
//测量文件长度以便于保存
fileinfo, _ := fp.Stat()
buf := make([]byte, fileinfo.Size())
fp.Read(buf)
//下面的操作是与创建秘钥保存时相反的
//pem解码
block, _ := pem.Decode(buf)
//x509解码,得到一个interface类型的pub
pub, _ := x509.ParsePKIXPublicKey(block.Bytes)
//加密操作,需要将接口类型的pub进行类型断言得到公钥类型
cipherText, _ := rsa.EncryptPKCS1v15(rand.Reader, pub.(*rsa.PublicKey), msg)
return cipherText
}
//使用私钥进行解密
func RSA_decrypter(path string, cipherText []byte) []byte {
//同加密时,先将私钥从文件中取出,进行二次解码
fp, _ := os.Open(path)
defer fp.Close()
fileinfo, _ := fp.Stat()
buf := make([]byte, fileinfo.Size())
fp.Read(buf)
block, _ := pem.Decode(buf)
PrivateKey, _ := x509.ParsePKCS1PrivateKey(block.Bytes)
//二次解码完毕,调用解密函数
afterDecrypter, _ := rsa.DecryptPKCS1v15(rand.Reader, PrivateKey, cipherText)
return afterDecrypter
}
func main() {
// Getkeys()
//尝试调用
msg := []byte("RSA非对称加密很棒")
ciphertext := RSA_encrypter("csdn_PublicKey.pem", msg)
//转化为十六进制方便查看结果
fmt.Println(hex.EncodeToString(ciphertext))
result := RSA_decrypter("csdn_private.pem", ciphertext)
fmt.Println(string(result))
}
1.2.18 - stdin-stdout-stderr
package main
import (
"fmt"
)
func main() {
v1 := "123"
v2 := 123
v3 := "Have a nice day\n"
v4 := "abc"
fmt.Print(v1, v2, v3, v4)
fmt.Println()
fmt.Println(v1, v2, v3, v4)
fmt.Print(v1, " ", v2, " ", v3, " ", v4, "\n")
fmt.Printf("%s%d %s %s\n", v1, v2, v3, v4)
}
- stderr
package main
import (
"io"
"os"
)
func main() {
myString := ""
arguments := os.Args
if len(arguments) == 1 {
myString = "Please give me one argument!"
} else {
myString = arguments[1]
}
io.WriteString(os.Stdout, "This is Standard output\n")
io.WriteString(os.Stderr, myString)
io.WriteString(os.Stderr, "\n")
}
- stdin
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
var f *os.File
f = os.Stdin
defer f.Close()
scanner := bufio.NewScanner(f)
for scanner.Scan() {
fmt.Println(">", scanner.Text())
}
}
- stdin-command-line
package main
import (
"fmt"
"os"
"strconv"
)
func main() {
if len(os.Args) == 1 {
fmt.Println("Please give one or more floats.")
os.Exit(1)
}
arguments := os.Args
min, _ := strconv.ParseFloat(arguments[1], 64)
max, _ := strconv.ParseFloat(arguments[1], 64)
for i := 2; i < len(arguments); i++ {
n, _ := strconv.ParseFloat(arguments[i], 64)
if n < min {
min = n
}
if n > max {
max = n
}
}
fmt.Println("Min:", min)
fmt.Println("Max:", max)
}
- stdout
package main
import (
"io"
"os"
)
func main() {
myString := ""
arguments := os.Args
if len(arguments) == 1 {
myString = "Please give me one argument!"
} else {
myString = arguments[1]
}
io.WriteString(os.Stdout, myString)
io.WriteString(os.Stdout, "\n")
}
1.2.19 - UDP简单的示例
package main
import (
"context"
"encoding/hex"
"fmt"
"log"
"net"
"time"
)
func main() {
// 本质上udp不存在传统意义上的服务端和客户端, 他其实是无连接的。
// 但是实际使用中, 总要有一方去监听数据, 另一方去连接所以才有了 一个服务 一个客户
// 创建一个监听服务
// conn, err := net.Dial("udp", ":30000")
// conn, err := net.DialUDP("udp", &net.UDPAddr{
// IP: net.ParseIP("0.0.0.0"),
// Port: 45103,
// }, &net.UDPAddr{
// IP: net.ParseIP("127.0.0.1"),
// Port: 30000,
// })
// 连接已经创建的服务
conn, err := net.DialUDP("udp", nil, &net.UDPAddr{
IP: net.ParseIP("127.0.0.1"),
Port: 30000,
})
if err != nil {
log.Fatalf("连接建立错误: %s", err.Error())
return
}
defer conn.Close()
//7F06FE01993FFF3C16
//7F32F601143801001F0250000100000000000000000000000000000000323030B7C2D8BB353030FABBF7D63130381411111501893E
//7F32F60115384000200250000100000000000000000000000000000000323030B7C2D8BB353030FABBF7D631303814111115012F09
// go func() {
// 创建一个计时器
timeTickerChan := time.Tick(time.Second * 2)
ctx, cancel := context.WithTimeout(context.Background(), time.Duration(time.Millisecond*800))
defer cancel()
for {
select {
case <-timeTickerChan:
input, err := hex.DecodeString("7F06FE01993FFF3C16")
if err != nil {
fmt.Printf("输入值解码错误:%s\n", err.Error())
continue
}
//客户端请求数据写入 conn,并传输
conn.WriteToUDP([]byte(input), &net.UDPAddr{
IP: net.ParseIP("10.10.10.4"),
Port: 8887,
})
writeCount, err := conn.Write([]byte(input))
if err != nil {
log.Printf("数据发送错误:%s\n", err.Error())
continue
}
log.Printf("输入值:%s; 发送量: %d\n", string(input), writeCount)
go func(ctx context.Context) {
//服务器端返回的数据写入空buf
buf := make([]byte, 1024)
// conn.ReadFrom()
// conn.ReadFromUDP()
cnt, serverAddr, err := conn.ReadFrom(buf)
if err != nil {
log.Printf("客户端读取数据失败 %s\n", err)
return
}
//回显服务器端回传的信息
log.Printf("服务器端回复: %s; 服务端信息:%s", hex.EncodeToString(buf[0:cnt]), serverAddr.String())
}(ctx)
select {
case <-ctx.Done():
fmt.Println("call successfully!!!")
continue
case <-time.After(time.Duration(time.Millisecond * 900)):
fmt.Println("timeout!!!")
continue
}
// input, _ = hex.DecodeString("7F32F601143801001F0250000100000000000000000000000000000000323030B7C2D8BB353030FABBF7D63130381411111501893E")
// log.Printf("输入值:%v\n", input)
// //客户端请求数据写入 conn,并传输
// conn.Write([]byte(input))
// //服务器端返回的数据写入空buf
// cnt, err = conn.Read(buf)
// if err != nil {
// log.Printf("客户端读取数据失败 %s\n", err)
// continue
// }
// //回显服务器端回传的信息
// log.Printf("服务器端回复" + hex.EncodeToString(buf[0:cnt]) + "\n")
// input, _ = hex.DecodeString("7F32F60115384000200250000100000000000000000000000000000000323030B7C2D8BB353030FABBF7D631303814111115012F09")
// log.Printf("输入值:%v\n", input)
// //客户端请求数据写入 conn,并传输
// conn.Write([]byte(input))
// //服务器端返回的数据写入空buf
// cnt, err = conn.Read(buf)
// if err != nil {
// log.Printf("客户端读取数据失败 %s\n", err)
// continue
// }
// //回显服务器端回传的信息
// log.Printf("服务器端回复" + hex.EncodeToString(buf[0:cnt]) + "\n")
}
}
// }()
}
1.2.20 - websocket-client
package main
import (
"encoding/json"
"fmt"
"log"
"net/url"
"sync"
"time"
"github.com/gorilla/websocket"
)
var mutex sync.Mutex
func main() {
// u := url.URL{Scheme: "ws", Host: "8.136.204.163:8000"}
u := url.URL{Scheme: "ws", Host: "localhost:8001"}
c, _, err := websocket.DefaultDialer.Dial(u.String(), nil)
if err != nil {
log.Fatalf("%+v", err)
}
defer c.Close()
// c.SetCloseHandler(func(code int, text string) error {
// fmt.Printf("SetCloseHandler %d:%s", code, text)
// // message := websocket.FormatCloseMessage(code, "")
// // c.WriteControl(CloseMessage, message, time.Now().Add(writeWait))
// return nil
// })
// c.SetPingHandler(func(appData string) error {
// fmt.Printf("SetPingHandler %s", appData)
// return nil
// })
// c.SetPongHandler(func(appData string) error {
// fmt.Printf("SetPingHandler %s", appData)
// return nil
// })
pingParam := make(map[string]interface{})
pingParam["msgId"] = 3
pingParam["action"] = "Heartbeat"
pingData := make(map[string]interface{})
pingData["echo"] = "ping"
pingParam["data"] = pingData
param := make(map[string]interface{})
param["msgId"] = 2
param["action"] = "Login"
data := make(map[string]interface{})
data["authName"] = "taian"
data["authToken"] = "7ee193f504125d7d9e715e0252648856"
data["clientName"] = "taian123"
param["data"] = data
mutex.Lock()
c.WriteJSON(param)
mutex.Unlock()
// res := make(map[string]interface{})
// err1 := c.ReadJSON(&res)
// if err1 != nil {
// fmt.Printf("%+v\n", err1)
// log.Fatalln(err1)
// }
// bs, _ := json.Marshal(res)
// log.Printf("%s\n", string(bs))
// mutex.Lock()
// err0 := c.WriteJSON(pingParam)
// mutex.Unlock()
// if err0 != nil {
// log.Fatalf("写ping命令ERR:%+v\n", err1)
// }
// res = make(map[string]interface{})
// err1 = c.ReadJSON(&res)
// if err1 != nil {
// log.Fatalf("读ping命令ERR: %+v\n", err1)
// }
// bs, _ = json.Marshal(res)
// log.Printf("%s\n", string(bs))
go func() {
t := time.NewTicker(time.Second * 4)
defer t.Stop()
for {
<-t.C
mutex.Lock()
c.WriteJSON(pingParam)
mutex.Unlock()
}
}()
go func() {
for {
res := make(map[string]interface{})
err1 := c.ReadJSON(&res)
if err1 != nil {
fmt.Printf("%+v\n", err1)
continue
}
bs, _ := json.Marshal(res)
log.Printf("%s\n", string(bs))
}
}()
// param["action"] = "GetDevice"
// data = make(map[string]interface{})
// data["index"] = 1
// data["count"] = -1
param0 := make(map[string]interface{})
param0["msgId"] = 4
param0["action"] = "RegDeviceData"
data0 := make(map[string]interface{})
data0["names"] = []string{"S01"}
data0["count"] = 1
param0["data"] = data0
mutex.Lock()
err0 := c.WriteJSON(param0)
mutex.Unlock()
if err0 != nil {
log.Fatalf("%+v", err0)
}
param1 := make(map[string]interface{})
param1["msgId"] = 4
param1["action"] = "GetRealDeviceData"
data1 := make(map[string][]string)
data1["names"] = []string{"S01"}
param1["data"] = data1
mutex.Lock()
err1 := c.WriteJSON(param1)
mutex.Unlock()
if err1 != nil {
log.Fatalf("%+v", err1)
}
select {}
}
1.2.21 - xorm连接mssql
go.mod
require (
github.com/denisenkom/go-mssqldb v0.0.0-20200620013148-b91950f658ec
xorm.io/xorm v1.0.2
)
main.go
package main
import (
"flag"
"fmt"
"time"
_ "github.com/denisenkom/go-mssqldb"
"xorm.io/xorm"
)
type Park struct {
ID string `xorm:"Id"`
Name string `xorm:"Name"`
}
var (
debug = flag.Bool("debug", true, "enable debugging")
password = flag.String("password", "123456", "the database password")
port *int = flag.Int("port", 1433, "the database port")
server = flag.String("server", "10.10.10.53", "the database server")
user = flag.String("user", "sa", "the database user")
)
func main() {
connString := fmt.Sprintf("server=%s;user id=%s;password=%s;port=%d;database=ed;encrypt=disable", *server, *user, *password, *port)
engine, err := xorm.NewEngine("mssql", connString)
//控制台打印SQL语句
if err != nil {
fmt.Println(err)
return
}
defer engine.Close()
engine.SetConnMaxLifetime(120 * time.Second)
engine.SetMaxOpenConns(16)
engine.SetMaxIdleConns(8)
err = engine.Ping()
if err != nil {
fmt.Println(err)
return
}
var sv []Park
engine.ShowSQL(true)
// err = engine.SQL("SELECT TOP 1000 id,CardCname FROM Dt_CardType order by id asc").Find(&sv)
engine.Find(&sv)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(len(sv))
}
1.2.22 - 遍历字符串
package main
import "fmt"
func main() {
var str = "Hello北京&"
//1. 按index遍历,这种方式按照字节遍历,对于非ASCII字符会出现乱码。因为"北京"每个字占3个字节
fmt.Println("按index遍历开始")
for i := 0; i < len(str); i++ {
fmt.Printf("%d:%c--", i, str[i])
}
fmt.Println("按index遍历结束")
//2. 用for-range遍历,这种方式是按照字符遍历的,不会出现乱码,但是下标index会出现不连续的情况,它具有不确定性
fmt.Println("for-range遍历开始")
for i, ch := range str {
fmt.Printf("%d:%c--", i, ch)
}
fmt.Println("for-range遍历结束")
//3. 转rune切片遍历
fmt.Println("转rune切片遍历开始")
str2 := []rune(str)
for i := 0; i < len(str2); i++ {
fmt.Printf("%d:%c--", i, str2[i])
}
fmt.Println("\n转rune切片遍历结束")
}
1.2.23 - 定时执行
- 最简单的定时执行
package main
import (
"fmt"
"time"
)
func main() {
go func() {
// 创建一个计时器
timeTickerChan := time.Tick(time.Second * 5)
for {
fmt.Println("123")
<-timeTickerChan
}
}()
fmt.Println(112233)
//一定要阻止主线程退出定时任务才能有效
select {}
}
- cron定时执行
require github.com/robfig/cron/v3 v3.0.1
package main
import (
"fmt"
"github.com/robfig/cron/v3"
"time"
)
func main() {
// 新建一个定时任务对象
// 根据cron表达式进行时间调度,cron可以精确到秒,大部分表达式格式也是从秒开始。
//crontab := cron.New() 默认从分开始进行时间调度
crontab := cron.New(cron.WithSeconds()) //精确到秒
//定义定时器调用的任务函数
task := func() {
fmt.Println("hello world", time.Now())
}
//定时任务
spec := "*/5 * * * * ?" //cron表达式,每五秒一次
// 添加定时任务,
crontab.AddFunc(spec, task)
// 启动定时器
crontab.Start()
// 定时任务是另起协程执行的,这里使用 select 简答阻塞.实际开发中需要
// 根据实际情况进行控制
select {} //阻塞主线程停止
}
1.2.24 - 读MySQL数据库所有表并输出见表语句
package main
import (
"fmt"
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
type ShowTablesRes struct {
// 注意这里也要改数据库名
TableName string `gorm:"column:Tables_in_${database}"`
}
type CreateRes struct {
Table string
CreateTable string `gorm:"column:Create Table"`
}
func main() {
dsn := fmt.Sprintf("%s:%s@tcp(%s)/%s?charset=utf8mb4&parseTime=True&loc=Local", "${username}", "${password}", "${ip}:${port}", "${database}")
// useUnicode=true&characterEncoding=utf8&autoReconnect=true&useSSL=true&serverTimezone=GMT%2B8"
fmt.Println(dsn)
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{})
if err != nil {
panic("failed to connect database")
}
var showTablesRes []ShowTablesRes
db.Raw("show tables").Scan(&showTablesRes)
// fmt.Println(&showTablesRes)
for _, v := range showTablesRes {
// fmt.Printf("%s\n", v.TableName)
var createRes []CreateRes
showTableStruct := "show create table " + v.TableName
db.Raw(showTableStruct).Scan(&createRes)
fmt.Printf("%s;\n", createRes[0].CreateTable)
}
}
1.2.25 - 链接sqlserver2008
go.mod
require (
github.com/denisenkom/go-mssqldb v0.0.0-20200620013148-b91950f658ec
github.com/go-ole/go-ole v1.2.4 // indirect
github.com/mattn/go-adodb v0.0.1 // indirect
golang.org/x/net v0.0.0-20200707034311-ab3426394381 // indirect
)
package main
import (
"database/sql"
"fmt"
"log"
_ "github.com/denisenkom/go-mssqldb"
)
// var (
// debug = flag.Bool("debug", true, "enable debugging")
// password = flag.String("password", "123456", "the database password")
// port *int = flag.Int("port", 1433, "the database port")
// server = flag.String("server", "10.10.10.53", "the database server")
// user = flag.String("user", "sa", "the database user")
// )
func main() {
// var debug = flag.Bool("debug", false, "enable debugging")
// var password = flag.String("password", "123456", "the database password")
// var port *int = flag.Int("port", 1433, "the database port")
// var server = flag.String("server", "10.10.10.53", "the database server")
// var user = flag.String("user", "sa", "the database user")
// var database = flag.String("database", "ed", "the database name")
// if *debug {
// fmt.Printf(" password:%s\n", *password)
// fmt.Printf(" port:%d\n", *port)
// fmt.Printf(" server:%s\n", *server)
// fmt.Printf(" user:%s\n", *user)
// }
connString := fmt.Sprintf("server=%s;database=%s;user id=%s;password=%s;port=%d;encrypt=disable", "10.10.10.53", "ed", "sa", "123456", 1433)
fmt.Printf(" connString:%s\n", connString)
db, err := sql.Open("mssql", connString)
if err != nil {
log.Fatal("Open connection failed:", err.Error())
return
}
err = db.Ping()
if err != nil {
fmt.Print("PING:%s", err)
return
}
fmt.Println(1)
}
1.2.26 - 使用redis
package main
import (
"fmt"
"log"
"math/rand"
"sync"
"time"
"github.com/go-redis/redis"
)
var redisdb *redis.Client
var wg sync.WaitGroup
func main() {
wg.Add(1)
go testRedisBase()
wg.Wait()
}
var map1 map[string]string
func testRedisBase() {
defer wg.Done()
//连接服务器
redisdb = redis.NewClient(&redis.Options{
Addr: "localhost:6379", // use default Addr
Password: "", // no password set
DB: 0, // use default DB
})
//心跳
pong, err := redisdb.Ping().Result()
log.Println(pong, err) // Output: PONG <nil>
result, err := redisdb.BLPop(10*time.Second, "list_test").Result()
log.Println("result:", result, err, len(result))
ch := make(chan struct{})
map1 = make(map[string]string)
go func() {
for {
content, _ := redisdb.BLPop(10*time.Second, "list_test").Result()
if content != nil {
ch <- struct{}{}
map1[content[1]] = content[1]
}
}
}()
for {
<-ch
for k, v := range map1 {
log.Println(k, ":", v)
}
if _, ok := map1["1"]; ok {
log.Println(map1["1"])
}
delete(map1, "1")
for k, v := range map1 {
log.Println(k, ":", v)
}
}
// ExampleClient_String()
// ExampleClient_List()
// ExampleClient_Hash()
// ExampleClient_Set()
// ExampleClient_SortSet()
// ExampleClient_HyperLogLog()
// ExampleClient_CMD()
// ExampleClient_Scan()
// ExampleClient_Tx()
// ExampleClient_Script()
// ExampleClient_PubSub()
}
func ExampleClient_String() {
log.Println("ExampleClient_String")
defer log.Println("ExampleClient_String")
//kv读写
err := redisdb.Set("key", "value", 1*time.Second).Err()
log.Println(err)
//获取过期时间
tm, err := redisdb.TTL("key").Result()
log.Println(tm)
val, err := redisdb.Get("key").Result()
log.Println(val, err)
val2, err := redisdb.Get("missing_key").Result()
if err == redis.Nil {
log.Println("missing_key does not exist")
} else if err != nil {
log.Println("missing_key", val2, err)
}
//不存在才设置 过期时间 nx ex
value, err := redisdb.SetNX("counter", 0, 1*time.Second).Result()
log.Println("setnx", value, err)
//Incr
result, err := redisdb.Incr("counter").Result()
log.Println("Incr", result, err)
}
func ExampleClient_List() {
log.Println("ExampleClient_List")
defer log.Println("ExampleClient_List")
//添加
log.Println(redisdb.RPush("list_test", "message1").Err())
log.Println(redisdb.RPush("list_test", "message2").Err())
//设置
log.Println(redisdb.LSet("list_test", 2, "message set").Err())
//remove
ret, err := redisdb.LRem("list_test", 3, "message1").Result()
log.Println(ret, err)
rLen, err := redisdb.LLen("list_test").Result()
log.Println(rLen, err)
//遍历
lists, err := redisdb.LRange("list_test", 0, rLen-1).Result()
log.Println("LRange", lists, err)
//pop没有时阻塞
result, err := redisdb.BLPop(30*time.Second, "list_test").Result()
log.Println("result:", result, err, len(result))
}
func ExampleClient_Hash() {
log.Println("ExampleClient_Hash")
defer log.Println("ExampleClient_Hash")
datas := map[string]interface{}{
"name": "LI LEI",
"sex": 1,
"age": 28,
"tel": 123445578,
}
//添加
if err := redisdb.HMSet("hash_test", datas).Err(); err != nil {
log.Fatal(err)
}
//获取
rets, err := redisdb.HMGet("hash_test", "name", "sex").Result()
log.Println("rets:", rets, err)
//成员
retAll, err := redisdb.HGetAll("hash_test").Result()
log.Println("retAll", retAll, err)
//存在
bExist, err := redisdb.HExists("hash_test", "tel").Result()
log.Println(bExist, err)
bRet, err := redisdb.HSetNX("hash_test", "id", 100).Result()
log.Println(bRet, err)
//删除
log.Println(redisdb.HDel("hash_test", "age").Result())
}
func ExampleClient_Set() {
log.Println("ExampleClient_Set")
defer log.Println("ExampleClient_Set")
//添加
ret, err := redisdb.SAdd("set_test", "11", "22", "33", "44").Result()
log.Println(ret, err)
//数量
count, err := redisdb.SCard("set_test").Result()
log.Println(count, err)
//删除
ret, err = redisdb.SRem("set_test", "11", "22").Result()
log.Println(ret, err)
//成员
members, err := redisdb.SMembers("set_test").Result()
log.Println(members, err)
bret, err := redisdb.SIsMember("set_test", "33").Result()
log.Println(bret, err)
redisdb.SAdd("set_a", "11", "22", "33", "44")
redisdb.SAdd("set_b", "11", "22", "33", "55", "66", "77")
//差集
diff, err := redisdb.SDiff("set_a", "set_b").Result()
log.Println(diff, err)
//交集
inter, err := redisdb.SInter("set_a", "set_b").Result()
log.Println(inter, err)
//并集
union, err := redisdb.SUnion("set_a", "set_b").Result()
log.Println(union, err)
ret, err = redisdb.SDiffStore("set_diff", "set_a", "set_b").Result()
log.Println(ret, err)
rets, err := redisdb.SMembers("set_diff").Result()
log.Println(rets, err)
}
func ExampleClient_SortSet() {
log.Println("ExampleClient_SortSet")
defer log.Println("ExampleClient_SortSet")
addArgs := make([]redis.Z, 100)
for i := 1; i < 100; i++ {
addArgs = append(addArgs, redis.Z{Score: float64(i), Member: fmt.Sprintf("a_%d", i)})
}
//log.Println(addArgs)
Shuffle := func(slice []redis.Z) {
r := rand.New(rand.NewSource(time.Now().Unix()))
for len(slice) > 0 {
n := len(slice)
randIndex := r.Intn(n)
slice[n-1], slice[randIndex] = slice[randIndex], slice[n-1]
slice = slice[:n-1]
}
}
//随机打乱
Shuffle(addArgs)
//添加
ret, err := redisdb.ZAddNX("sortset_test", addArgs...).Result()
log.Println(ret, err)
//获取指定成员score
score, err := redisdb.ZScore("sortset_test", "a_10").Result()
log.Println(score, err)
//获取制定成员的索引
index, err := redisdb.ZRank("sortset_test", "a_50").Result()
log.Println(index, err)
count, err := redisdb.SCard("sortset_test").Result()
log.Println(count, err)
//返回有序集合指定区间内的成员
rets, err := redisdb.ZRange("sortset_test", 10, 20).Result()
log.Println(rets, err)
//返回有序集合指定区间内的成员分数从高到低
rets, err = redisdb.ZRevRange("sortset_test", 10, 20).Result()
log.Println(rets, err)
//指定分数区间的成员列表
rets, err = redisdb.ZRangeByScore("sortset_test", redis.ZRangeBy{Min: "(30", Max: "(50", Offset: 1, Count: 10}).Result()
log.Println(rets, err)
}
//用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
//每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数
func ExampleClient_HyperLogLog() {
log.Println("ExampleClient_HyperLogLog")
defer log.Println("ExampleClient_HyperLogLog")
for i := 0; i < 10000; i++ {
redisdb.PFAdd("pf_test_1", fmt.Sprintf("pfkey%d", i))
}
ret, err := redisdb.PFCount("pf_test_1").Result()
log.Println(ret, err)
for i := 0; i < 10000; i++ {
redisdb.PFAdd("pf_test_2", fmt.Sprintf("pfkey%d", i))
}
ret, err = redisdb.PFCount("pf_test_2").Result()
log.Println(ret, err)
redisdb.PFMerge("pf_test", "pf_test_2", "pf_test_1")
ret, err = redisdb.PFCount("pf_test").Result()
log.Println(ret, err)
}
func ExampleClient_PubSub() {
log.Println("ExampleClient_PubSub")
defer log.Println("ExampleClient_PubSub")
//发布订阅
pubsub := redisdb.Subscribe("subkey")
_, err := pubsub.Receive()
if err != nil {
log.Fatal("pubsub.Receive")
}
ch := pubsub.Channel()
time.AfterFunc(1*time.Second, func() {
log.Println("Publish")
err = redisdb.Publish("subkey", "test publish 1").Err()
if err != nil {
log.Fatal("redisdb.Publish", err)
}
redisdb.Publish("subkey", "test publish 2")
})
for msg := range ch {
log.Println("recv channel:", msg.Channel, msg.Pattern, msg.Payload)
}
}
func ExampleClient_CMD() {
log.Println("ExampleClient_CMD")
defer log.Println("ExampleClient_CMD")
//执行自定义redis命令
Get := func(rdb *redis.Client, key string) *redis.StringCmd {
cmd := redis.NewStringCmd("get", key)
redisdb.Process(cmd)
return cmd
}
v, err := Get(redisdb, "NewStringCmd").Result()
log.Println("NewStringCmd", v, err)
v, err = redisdb.Do("get", "redisdb.do").String()
log.Println("redisdb.Do", v, err)
}
func ExampleClient_Scan() {
log.Println("ExampleClient_Scan")
defer log.Println("ExampleClient_Scan")
//scan
for i := 1; i < 1000; i++ {
redisdb.Set(fmt.Sprintf("skey_%d", i), i, 0)
}
cusor := uint64(0)
for {
keys, retCusor, err := redisdb.Scan(cusor, "skey_*", int64(100)).Result()
log.Println(keys, cusor, err)
cusor = retCusor
if cusor == 0 {
break
}
}
}
func ExampleClient_Tx() {
pipe := redisdb.TxPipeline()
incr := pipe.Incr("tx_pipeline_counter")
pipe.Expire("tx_pipeline_counter", time.Hour)
// Execute
//
// MULTI
// INCR pipeline_counter
// EXPIRE pipeline_counts 3600
// EXEC
//
// using one rdb-server roundtrip.
_, err := pipe.Exec()
fmt.Println(incr.Val(), err)
}
func ExampleClient_Script() {
IncrByXX := redis.NewScript(`
if redis.call("GET", KEYS[1]) ~= false then
return redis.call("INCRBY", KEYS[1], ARGV[1])
end
return false
`)
n, err := IncrByXX.Run(redisdb, []string{"xx_counter"}, 2).Result()
fmt.Println(n, err)
err = redisdb.Set("xx_counter", "40", 0).Err()
if err != nil {
panic(err)
}
n, err = IncrByXX.Run(redisdb, []string{"xx_counter"}, 2).Result()
fmt.Println(n, err)
}
1.2.27 - 支持RabbitMQ的AMQP
package main
import (
"log"
"github.com/streadway/amqp"
)
func failOnError(err error, msg string) {
if err != nil {
log.Fatalf("%s: %s", msg, err)
}
}
func main() {
// 连接 RabbitMQ
conn, err := amqp.Dial("amqp://admin:admin@127.0.0.1:5673")
failOnError(err, "连接失败")
defer conn.Close()
// 建立一个 channel ( 其实就是TCP连接 )
ch, err := conn.Channel()
failOnError(err, "打开通道失败")
defer ch.Close()
// 创建一个名字叫 "hello" 的队列
q, err := ch.QueueDeclare(
"hello", // name
false, // durable
false, // delete when unused
false, // exclusive
false, // no-wait
nil, // arguments
)
failOnError(err, "创建队列失败")
// 构建一个消息
body := "Hello World!"
msg := amqp.Publishing{
ContentType: "text/plain",
Body: []byte(body),
}
// 构建一个生产者,将消息 放入队列
err = ch.Publish(
"", // exchange
q.Name, // routing key
false, // mandatory
false, // immediate
msg)
log.Printf(" [x] Sent %s", body)
failOnError(err, "Failed to publish a message")
}
1.3 - 31个!Golang常用工具
一、G0官方工具
(一)go get
该命令可以根据要求和实际情况从互联网上下载或更新指定的代码包及其依赖包,下载后自动编译,一般引用依赖用go get就可以了。 参考:
go get -u "github.com/VictoriaMetrics/fastcache"
参考: https://www.kancloud.cn/cattong/go_command_tutorial/261349
(二)go build
该命令用于编译我们指定的源码文件或代码包以及它们的依赖包。命令的常用标记说明如下:

编译过程输出到文件:go build -x > result 2>&1,因为go build -x 最终是将日志写到标准错误流当中。
如果只在编译特定包时需要指定参数,可以参考包名=参数列表的格式,比如go build -gcflags=‘log=-N -l’ main.go
参考: https://www.kancloud.cn/cattong/go_command_tutorial/261347
(三)go install
该命令用于编译并安装指定的代码包及它们的依赖包。当指定的代码包的依赖包还没有被编译和安装时,该命令会先去处理依赖包。与go build命令一样,传给go install命令的代码包参数应该以导入路径的形式提供。
并且,go build命令的绝大多数标记也都可以用于go install命令。实际上,go install命令只比go build命令多做了一件事,即:安装编译后的结果文件到指定目录。
参考:
https://www.kancloud.cn/cattong/go_command_tutorial/261348
(四)go fmt和gofmt
Golang的开发团队制定了统一的官方代码风格,并且推出了gofmt工具(gofmt或go fmt)来帮助开发者格式化他们的代码到统一的风格。
gofmt是一个cli程序,会优先读取标准输入,如果传入了文件路径的话,会格式化这个文件,如果传入一个目录,会格式化目录中所有.go文件,如果不传参数,会格式化当前目录下的所有.go文件。
gofmt默认不对代码进行简化,使用-s参数可以开启简化代码功能
gofmt是一个独立的cli程序,而go中还有一个go fmt命令,go fmt命令是gofmt的简单封装。go fmt在调用gofmt时添加了-l -w参数,相当于执行了gofmt -l -w
参考:
https://blog.csdn.net/whatday/article/details/97682094
(五)go env
该命令用于打印Go语言的环境信息,常见的通用环境信息如下:

设置或修改环境变量值:
go env -w GOPROXY="https://goproxy.com,direct"
参考:
https://www.kancloud.cn/cattong/go_command_tutorial/261359
(六)go run
该命令可以运行命令源码文件,只能接受一个命令源码文件以及若干个库源码文件(必须同属于main包)作为文件参数,且不能接受测试源码文件。它在执行时会检查源码文件的类型。如果参数中有多个或者没有命令源码文件,那么go run命令就只会打印错误提示信息并退出,而不会继续执行。
在通过参数检查后,go run命令会将编译参数中的命令源码文件,并把编译后的可执行文件存放到临时工作目录中。
参考:
https://www.kancloud.cn/cattong/go_command_tutorial/261352
(七)go test
该命令用于对Go语言编写的程序进行测试,这种测试是以代码包为单位的,命令会自动测试每一个指定的代码包。当然,前提是指定的代码包中存在测试源码文件。
参考:
https://www.kancloud.cn/cattong/go_command_tutorial/261353
(八)go clean
该命令会删除掉执行其它命令时产生的一些文件和目录。
参考:
https://www.kancloud.cn/cattong/go_command_tutorial/261350
(九)go list
该命令的作用是列出指定的代码包的信息。与其他命令相同,我们需要以代码包导入路径的方式给定代码包。被给定的代码包可以有多个。这些代码包对应的目录中必须直接保存有Go语言源码文件,其子目录中的文件不算在内。
标记-e的作用是以容错模式加载和分析指定的代码包。在这种情况下,命令程序如果在加载或分析的过程中遇到错误只会在内部记录一下,而不会直接把错误信息打印出来。
为了看到错误信息可以使用-json标记。这个标记的作用是把代码包的结构体实例用JSON的样式打印出来。-m标记可以打印出modules而不是package。
# cd yky-sys-backend/cmd/bidengine
参考:
https://www.kancloud.cn/cattong/go_command_tutorial/261354
(十)go mod xxx
该命令初始化并写入一个新的go.mod至当前目录中,实际上是创建一个以当前目录为根的新模块。文件go.mod必须不存在。如果可能,init会从import注释(参阅“go help importpath”)或从版本控制配置猜测模块路径。要覆盖此猜测,提供模块路径作为参数 module为当前项目名。比如:
go mod init demo
参考:
https://www.jianshu.com/p/f6d2d6db2bca
该命令确保go.mod与模块中的源代码一致。它添加构建当前模块的包和依赖所必须的任何缺少的模块,删除不提供任何有价值的包的未使用的模块。它也会添加任何缺少的条目至go.mod并删除任何不需要的条目。
参考:
https://www.jianshu.com/p/f6d2d6db2bca
该命令重置主模块的vendor目录,使其包含构建和测试所有主模块的包所需要的所有包。不包括vendor中的包的测试代码。即将GOPATH或GOROOT下载的包拷贝到项目下的vendor目录,如果不使用vendor隔离项目的依赖,则不需要使用该命令拷贝依赖。
参考:
https://www.jianshu.com/p/f6d2d6db2bca
该命令下载指定名字的模块,可为选择主模块依赖的模块匹配模式,或path@version形式的模块查询。如果download不带参数则代表是主模块的所有依赖。download的只会下载依赖,不会编译依赖,和get是有区别的。
参考:
https://www.jianshu.com/p/f6d2d6db2bca
- go mod edit
该命令提供一个编辑go.mod的命令行接口,主要提供给工具或脚本使用。它只读取go.mod;不查找涉及模块的信息。默认情况下,edit读写主模块的go.mod文件,但也可以在标志后指定不同的目标文件。
参考:
https://www.jianshu.com/p/f6d2d6db2bca
该命令以文本形式打印模块间的依赖关系图。输出的每一行行有两个字段(通过空格分割);模块和其所有依赖中的一个。每个模块都被标记为path@version形式的字符串(除了主模块,因其没有@version后缀)。
参考:
https://www.jianshu.com/p/f6d2d6db2bca
- go mod verify
该命令查存储在本地下载源代码缓存中的当前模块的依赖,是否自从下载之后未被修改。如果所有模块都未被修改,打印“all modules verified”。否则,报告哪个模块已经被修改并令“go mod”以非0状态退出。
参考:
https://www.jianshu.com/p/f6d2d6db2bca
该命令输出每个包或者模块的引用块,每个块以注释行“# package”或“# module”开头,给出目标包或模块。随后的行通过导入图给出路径,一个包一行。每个块之间通过一个空行分割,如果包或模块没有被主模块引用,该小节将显示单独一个带圆括号的提示信息来表明该事实。
参考:
https://www.jianshu.com/p/f6d2d6db2bca
(十一)go tool xxx
go tool的可执行文件在GOROOT或GOPATH的pkg/tool目录。go doc cmd可以查看具体cmd的使用说明,比如:
go doc pprof
在Golang中,可以通过pprof工具对应于程序的运行时进行性能分析,包括CPU、内存、Goroutine等实时信息。
参考:
https://www.kancloud.cn/cattong/go_command_tutorial/261357
该命令可以追踪请求链路,清晰的了解整个程序的调用栈,可以通过追踪器捕获大量信息。
参考:
https://zhuanlan.zhihu.com/p/410590497
该命令可以编译Go文件生成汇编代码,-N参数表示禁止编译优化, -l表示禁止内联,-S表示打印汇编,比如
# 会生成main.o的汇编文件
该命令是一个用于检查Go语言源码中静态错误的简单工具。
go vet命令是go tool vet命令的简单封装。它会首先载入和分析指定的代码包,并把指定代码包中的所有Go语言源码文件和以“.s”结尾的文件的相对路径作为参数传递给go tool vet命令。其中,以“.s”结尾的文件是汇编语言的源码文件。如果go vet命令的参数是Go语言源码文件的路径,则会直接将这些参数传递给go tool vet命令。
参考:
https://www.kancloud.cn/cattong/go_command_tutorial/261356
该命令可以打印附于Go语言程序实体上的文档。我们可以通过把程序实体的标识符作为该命令的参数来达到查看其文档的目的。
所谓Go语言的程序实体,是指变量、常量、函数、结构体以及接口。而程序实体的标识符即是代表它们的名称。
参考:
https://www.kancloud.cn/cattong/go_command_tutorial/261351
该命令可以调用栈的地址转化为文件和行号。
Usage:
该命令可以将汇编文件编译成一个.o文件,后续这个.o文件可以用于生成.a归档文件,命令的file参数必须是汇编文件。
Usage:
每一个 Go 二进制文件内,都有一个独一无二的 Build ID,详情参考 src/cmd/go/internal/work/buildid.go 。Go Build ID 可以用以下命令来查看:
go tool buildid
参考:
https://www.anquanke.com/post/id/215419
该命令可以使我们创建能够调用C语言代码的Go语言源码文件。这使得我们可以使用Go语言代码去封装一些C语言的代码库,并提供给Go语言代码或项目使用。
参考:
https://www.kancloud.cn/cattong/go_command_tutorial/261358
该命令对单元测试过程中生成的代码覆盖率统计生成html文件,可以本地打开展示。
go test -coverprofile=a.out
覆盖度工具不仅可以记录分支是否被执行,还可以记录分支被执行了多少次。
go test -covermode=set|count|atomic: -covermode:
set: 默认模式,统计是否执行
count: 计数
atomic: count的并发安全版本,仅当需要精确统计时使用
通过go tool cover -func=count.out查看每个函数的覆盖度。
参考:
https://blog.csdn.net/xhdxhdxhd/article/details/120424848
dist工具是属于go的一个引导工具,它负责构建C程序(如Go编译器)和Go工具的初始引导副本。它也可以作为一个包罗万象用shell脚本替换以前完成的零工。通过“go tool dist”命令可以操作该工具。
go tool dist
使用go tool dist list可以输出当前安装Go版本所支持的操作系统与架构。
参考:https://blog.csdn.net/byxiaoyuonly/article/details/112492264
该命令会把指定代码包的所有Go语言源码文件中的旧版本代码修正为新版本的代码。这里所说的版本即Go语言的版本。代码包的所有Go语言源码文件不包括其子代码包(如果有的话)中的文件。修正操作包括把对旧程序调用的代码更换为对新程序调用的代码、把旧的语法更换为新的语法等等。
这个工具其实非常有用。在编程语言的升级和演进的过程中,难免会对过时的和不够优秀的语法及标准库进行改进。
参考:
https://www.kancloud.cn/cattong/go_command_tutorial/261355
该命令链接Go的归档文件比如静态库,以及链接其所有依赖,生成一个可执行文件(含main package)。
go tool link [flags] main.a
参考:
http://cache.baiducontent.com/
该命令可以查看符号表的命令,等同于系统的nm命令,非常有用。在断点的时候,如果你不知道断点的函数符号,那么用这个命令查一下就知道了(命令处理的是二进制程序文件),第一列是地址,第二列是类型,第三列是符号。等同于nm命令。
参考:
https://studygolang.com/articles/29906
该命令可以反汇编二进制的工具,等同于系统objdump,命令解析的是二进制格式的程序文件。
go tool objdump example.o
参考:
https://studygolang.com/articles/29906
该命令把二进制文件打包成静态库。
go tool pack op file.a [name...]
参考:
http://cache.baiducontent.com/
该命令用于把测试可执行文件转化可读的json格式。
// 生成测试文件的可执行文件
参考:
https://blog.csdn.net/weixin_33772442/article/details/112098085
该命令可以生成一个Go官方文档的本地http服务,可以在线查看标准库和第三方库文档,以及项目文档,但是需要按照一定的格式去写注释。
// 安装godoc
Web页面如下:

参考:https://www.fujieace.com/golang/godoc.html
二、第三方工具
Go工具和组件汇总项目:
https://github.com/avelino/awesome-go
(一)delve
本地代码调试工具
参考:https://github.com/go-delve/delve
(二)goconvey
goconvey是一款针对Golang的测试框架,可以管理和运行测试用例,同时提供了丰富的断言函数,并支持很多Web界面特性。
参考:https://github.com/smartystreets/goconvey
(三)goleak
本地排查内存泄露的工具
参考:https://github.com/uber-go/goleak
(四)go-wrk
Go接口压测工具
参考:https://github.com/adjust/go-wrk
(五)golint
代码风格检查
参考:https://github.com/golang/lint
(六)revive
代码风格检查,比golint速度更快
参考:https://github.com/mgechev/revive
(七)gocode
代码自动补全工具,可以在vim中使用
参考:https://github.com/nsf/gocode
(八)godoctor
代码重构工具
参考:https://github.com/godoctor/godoctor
(九)gops
查看go进程和相关信息的工具,用于诊断线上服务。
参考:https://github.com/google/gops
(十)goreplay
GoReplay是一个开源网络监控工具,可以将实时HTTP流量捕获并重放到测试环境。
参考:https://github.com/buger/goreplay
https://blog.51cto.com/axzxs/5102596
(十一)depth
一个有用的Golang工具,Depth可帮助Web开发人员检索和可视化Go源代码依赖关系树。它可以用作独立的命令行应用程序或作为项目中的特定包。你可以通过在解析之前在Tree上设置相应的标志来添加自定义。
参考:https://github.com/KyleBanks/depth
(十二)go-swagger
该工具包包括各种功能和功能。Go-Swagger是Swagger 2.0的一个实现,可以序列化和反序列化swagger规范。它是RESTful API简约但强大的代表。
通过Go-Swagger,你可以swagger规范文档,验证JSON模式以及其他额外的规则。其他功能包括代码生成,基于swagger规范的API生成,基于代码的规范文档生成,扩展了的字符串格式,等等。
参考:https://github.com/go-swagger/go-swagger
(十三)gox
交叉编译工具,可以并行编译多个平台。
参考:https://github.com/mitchellh/gox
(十四)gocyclo
gocyclo用来检查函数的复杂度。
# 列出了所有复杂度大于20的函数
参考:https://github.com/fzipp/gocyclo
(十五)deadcode
deadcode会告诉你哪些代码片段根本没用。
find . -type d -not -path "./vendor/*" | xargs deadcode
参考:https://github.com/tsenart/deadcode
(十六)gotype
gotype会对go文件和包进行语义(semantic)和句法(syntactic)的分析,这是google提供的一个工具。
find . -name "*.go" -not -path "./vendor/*" -not -path ".git/*" -print | xargs gotype -a
参考:https://golang.org/x/tools/cmd/gotype
(十七)misspell
misspell用来拼写检查,对国内英语不太熟练的同学很有帮助。
find . -type f -not -path "./vendor/*" -print | xargs misspell
参考:https://github.com/client9/misspell
(十八)staticcheck
staticcheck是一个超牛的工具,提供了巨多的静态检查,就像C#生态圈的 ReSharper一样。
# 安装:
参考:
https://github.com/dominikh/go-tools/tree/master/staticcheck
(十九)goconst
goconst会查找重复的字符串,这些字符串可以抽取成常量。
goconst ./… | grep -v vendor
参考:https://github.com/jgautheron/goconst
参考资料:
1.Go命令教程:
https://www.kancloud.cn/cattong/go_command_tutorial/261351
2.Golang指南:顶级Golang框架、IDE和工具列表:
https://zhuanlan.zhihu.com/p/30432648
3.Go代码检修工具集:
1.4 - GO基础
go语言不需要写分号
1. 基本程序结构
package 包名
import ""
func main(){
//code
}
2. 导包方式
2.1单独导入
import ""
2.2多包导入方式
import(
""
""
)
3. 变量类型
3.1 普通变量类型
bool
string
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
byte // alias for uint8
rune // alias for int32
// represents a Unicode code point
float32 float64
complex64 complex128
3.2 衍生数据类型
Array types 数组
Structure types 结构体
Union types 联合
Slice types 切片,引用类型
Interface types 接口
Map types 字典,引用类型
Channel Types 通道,引用类型
Slice, Map, Channel 这三种是引用数据类型, 使用需要make
3.3 golang支持自定义数据类型–类似于别名
type flag byte
4. 变量定义以及赋值
var 变量1, 变量2 变量类型\
例如
var x, y int
var x, y int = 2, 3
var (
x,y int
a,s = 100, "abc"
)
缺省赋值只能用在函数内部 \
x, y := 2, 3 // 会自动类型推断
5. 常量定义以及赋值
常量可以只定义不使用
常量不能读地址 const 常量名 数据类型 = 值
const variable type = value
const name, size = "carrot", 100
const(
var1 type = value
var2 type = value
var3 = value // 也可以自动类型推断
)
//这种情况下, BBB和CCC的值也是120
const(
AAA = 120
BBB
CCC
)
// Golang中没有枚举类型,但是可以使用iota来更优雅的定义一个枚举
// iota从0开始递增,步长1
const(
Low = 5 * iota //Low = 0
Medium //Medium = 5
High //High = 10
)
//iota可以被中断
const(
a = iota //a = 0,默认值
b //1
c //2
d = 100 //100
e //100
f = iota //5
)
6. 变量 类型转换—必须使用显式类型转换
a := 1
b := byte(a)
// go中不能将非布尔类型的类型转换成布尔类型, 也不能作为布尔类型来使用
7. 流程控制 – GO语言推荐不适用圆括号
关键字展示
- if
- if else
- if (){}else if(){} else{}
- switch
- for
- goto break contunue
- 没有while!没有while!没有while! 重要的事情说三遍
7.1 if
if a > 1 {
//code
}
7.2 if else
if a > 1 {//左花括号不能换行
//code
} else { //else关键字不能换行,左花括号不能换行
//code
}
7.3 if (){}else if(){} else
if a > 1 {
//code
} else if a > 2 {
//code
} else {
//code
}
7.4 switch
//可以不用写break,go语言执行完一个case后默认break
//default也可以不写在最后, 但是建议还是写最后
//如果不想执行完一个case后就被break可以使用fallthrough
func main() {
a, b, c, x := 1, 2, 3, 2
switch x{
case a, b:
fmt.Println("a|b")
fallthrough // 这样就不会被退出了
case c:
fmt.Println("c")
default:
fmt.Println("default")
}
}
7.5 for
//普通的for
for i := 0; i<max; i++ {
}
//迭代列表和切片
date := [4]string{"a","b",“c”}
for i, str := range date {
fmt.Println(i, str)
}
//迭代mqp
for k, v := range map {
fmt.Println(k,v)
}
// 死循环
for {
//code
}
7.6 函数
// 1. 不支持内部定义函数,但是可以定义匿名函数
func main() {
func swap(x, y string) (string, string) {
return y, x
}
a, b := swap("hello", "world")
fmt.Println(a, b)
}
// 错误:syntax error: unexpected swap, expecting (
// 2. 匿名函数, 用法有点像js
func main() {
func (s string) {
fmt.Println(s)
} ("hello, go!")
}
// 3. 函数可以返回多个值, 参数也可以是可变参数
func fun_name (str string, a ...int) int {}
func fun_name (str string, a ...int) (x, y int) {}
// 4. 函数参数没有默认值即使是 下划线开头 func fun_name (str string, a int, _boo bool)
// 5. 闭包的写法, 返回一个函数的函数就是闭包闭包内的局部变量是自我维护的
func intSeq() func() int {
i := 0
return func() int {
i += 1
return i
}
}
func main(){
nextInt := intSeq()
nextInt()
nextInt()
nextInt()
}
1.5 - 安装
#!/bin/bash
# 安装go
wget https://mirrors.aliyun.com/golang/go${GOLANGVERSION}.linux-amd64.tar.gz?spm=a2c6h.25603864.0.0.a6b07c45FOi9wZ -O /opt/go${GOLANGVERSION}.linux-amd64.tar.gz && cd /opt && rm -rf go${GOLANGVERSION} && \
mkdir go${GOLANGVERSION} && \
tar -zxf go${GOLANGVERSION}.linux-amd64.tar.gz -C go${GOLANGVERSION} && \
rm -f go${GOLANGVERSION}.linux-amd64.tar.gz && \
echo "export GOROOT=/opt/go${GOLANGVERSION}/go" >> /etc/profile && \
echo 'export GOPATH=/root/go' >> /etc/profile && \
echo 'PATH=$PATH:$GOROOT/bin:$GOPATH/bin' >> /etc/profile && \
source /etc/profile && \
go env -w GO111MODULE=on && \
go env -w GOPROXY=https://goproxy.cn,direct && \
# 本地k8s测试工具
go install sigs.k8s.io/kind@latest && kind --version && \
# 漏洞检测工具
go install golang.org/x/vuln/cmd/govulncheck@latest && \
# protoc编译器
go install google.golang.org/protobuf/cmd/protoc-gen-go@latest && \
# grpc
go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@latest && \
# gateway
go install github.com/grpc-ecosystem/grpc-gateway/v2/protoc-gen-grpc-gateway@latest && \
# openapi
go install github.com/grpc-ecosystem/grpc-gateway/v2/protoc-gen-openapiv2@latest && \
# 安装delve,用于debug go代码
go install github.com/go-delve/delve/cmd/dlv@latest && \
# 安装wire自动注入工具
go install github.com/google/wire/cmd/wire@latest
1.6 - 报错解决
- 报错描述
For more information, see 'go help module-auth'.
gateway2-http-command-async/cmd/appservice imports
github.com/edgexfoundry/app-functions-sdk-go/v2/pkg/transforms imports
github.com/edgexfoundry/go-mod-core-contracts/v2/common: github.com/edgexfoundry/go-mod-core-contracts/v2@v2.1.0: verifying module: checksum mismatch
downloaded: h1:QIb6pcSYxL9F4TDnZOZk7+USnZ8Nivz1hHxmoAFNPVM=
sum.golang.org: h1:uphot3ZKOH0/aoo/Y5gr2NCRgGzy9RksWsXKtJRVEuQ=
SECURITY ERROR
This download does NOT match the one reported by the checksum server.
The bits may have been replaced on the origin server, or an attacker may
have intercepted the download attempt.
方案: 考虑换goproxy解决,有可能时代理中存储的签名和sum.golang.org存储的签名不同
- 报错描述
在go module 项目中, 全局配置过 GOPROXY=“https://goproxy.io” 此时如果要用go get github.com/xxx/xxx 的包是完全可以导入的(实际是从 https://goproxy.io/github.com/xxx/xxx 来下载包的
但是如果要导入的包是私有仓库比如 gitpack.xxx.cn/myutil/help 实际是从 https://goproxy.io/gitpack.gitpack.xxx.cn/myutil/help 这时一定是返回http 404错误的 报错如下
If your Go version >= 1.13, the GOPRIVATE environment variable controls which modules the go command considers to be private (not available publicly) and should therefore not use the proxy or checksum database.
要导入私有git仓库的包需要设置go 环境变量GOPRIVATE go env -w GOPRIVATE=".xxx.cn" 或者直接设置环境变量GOPRIVATE=.xxx.cn 再用 go get -u gitpack.xxx.cn/myutil/help@分支名(标签名) 就可以成功导入私有包了
2 - Java
public void b() {
int a=3;
int b=4;
a=a^b;
b=b^a;//b=b^(a^b) ->b=a
a=a^b;//a=(a^b)^(b^a) ->a=b
System.out.println(a);//输出4
System.out.println(b);//输出3
}
2.1 - Java最佳实践
Java最佳实践。测试案例均通过JDK21。有些代码在JDK8中报错需要调整
2.1.1 - AES加解密
package cn.anzhongwei.lean.demo.encryption;
import java.security.Key;
import java.security.NoSuchAlgorithmException;
import java.util.Arrays;
import java.util.Base64;
import javax.crypto.Cipher;
import javax.crypto.KeyGenerator;
import javax.crypto.SecretKey;
import javax.crypto.spec.SecretKeySpec;
/**
* AES加密类
*
*/
public class AESUtils {
/**
* 密钥算法
*/
private static final String KEY_ALGORITHM = "AES";
private static final String DEFAULT_CIPHER_ALGORITHM = "AES/ECB/PKCS5Padding";
/**
* 初始化密钥
*
* @return byte[] 密钥
* @throws Exception
*/
public static byte[] initSecretKey() {
// 返回生成指定算法的秘密密钥的 KeyGenerator 对象
KeyGenerator kg = null;
try {
kg = KeyGenerator.getInstance(KEY_ALGORITHM);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
return new byte[0];
}
// 初始化此密钥生成器,使其具有确定的密钥大小
// AES 要求密钥长度为 128
kg.init(128);
// 生成一个密钥
SecretKey secretKey = kg.generateKey();
return secretKey.getEncoded();
}
/**
* 转换密钥
*
* @param key
* 二进制密钥
* @return 密钥
*/
public static Key toKey(byte[] key) {
// 生成密钥
return new SecretKeySpec(key, KEY_ALGORITHM);
}
/**
* 加密
*
* @param data
* 待加密数据
* @param key
* 密钥
* @return byte[] 加密数据
* @throws Exception
*/
public static byte[] encrypt(byte[] data, Key key) throws Exception {
return encrypt(data, key, DEFAULT_CIPHER_ALGORITHM);
}
/**
* 加密
*
* @param data
* 待加密数据
* @param key
* 二进制密钥
* @return byte[] 加密数据
* @throws Exception
*/
public static byte[] encrypt(byte[] data, byte[] key) throws Exception {
return encrypt(data, key, DEFAULT_CIPHER_ALGORITHM);
}
/**
* 加密
*
* @param data
* 待加密数据
* @param key
* 二进制密钥
* @param cipherAlgorithm
* 加密算法/工作模式/填充方式
* @return byte[] 加密数据
* @throws Exception
*/
public static byte[] encrypt(byte[] data, byte[] key, String cipherAlgorithm) throws Exception {
// 还原密钥
Key k = toKey(key);
return encrypt(data, k, cipherAlgorithm);
}
/**
* 加密
*
* @param data
* 待加密数据
* @param key
* 密钥
* @param cipherAlgorithm
* 加密算法/工作模式/填充方式
* @return byte[] 加密数据
* @throws Exception
*/
public static byte[] encrypt(byte[] data, Key key, String cipherAlgorithm) throws Exception {
// 实例化
Cipher cipher = Cipher.getInstance(cipherAlgorithm);
// 使用密钥初始化,设置为加密模式
cipher.init(Cipher.ENCRYPT_MODE, key);
// 执行操作
return cipher.doFinal(data);
}
/**
* 解密
*
* @param data
* 待解密数据
* @param key
* 二进制密钥
* @return byte[] 解密数据
* @throws Exception
*/
public static byte[] decrypt(byte[] data, byte[] key) throws Exception {
return decrypt(data, key, DEFAULT_CIPHER_ALGORITHM);
}
/**
* 解密
*
* @param data
* 待解密数据
* @param key
* 密钥
* @return byte[] 解密数据
* @throws Exception
*/
public static byte[] decrypt(byte[] data, Key key) throws Exception {
return decrypt(data, key, DEFAULT_CIPHER_ALGORITHM);
}
/**
* 解密
*
* @param data
* 待解密数据
* @param key
* 二进制密钥
* @param cipherAlgorithm
* 加密算法/工作模式/填充方式
* @return byte[] 解密数据
* @throws Exception
*/
public static byte[] decrypt(byte[] data, byte[] key, String cipherAlgorithm) throws Exception {
// 还原密钥
Key k = toKey(key);
return decrypt(data, k, cipherAlgorithm);
}
/**
* 解密
*
* @param data
* 待解密数据
* @param key
* 密钥
* @param cipherAlgorithm
* 加密算法/工作模式/填充方式
* @return byte[] 解密数据
* @throws Exception
*/
public static byte[] decrypt(byte[] data, Key key, String cipherAlgorithm) throws Exception {
// 实例化
Cipher cipher = Cipher.getInstance(cipherAlgorithm);
// 使用密钥初始化,设置为解密模式
cipher.init(Cipher.DECRYPT_MODE, key);
// 执行操作
return cipher.doFinal(data);
}
public static String showByteArray(byte[] data) {
if (null == data) {
return null;
}
StringBuilder sb = new StringBuilder("{");
for (byte b : data) {
sb.append(b).append(",");
}
sb.deleteCharAt(sb.length() - 1);
sb.append("}");
return sb.toString();
}
/**
* 将16进制转换为二进制
*
* @param hexStr
* @return
*/
public static byte[] parseHexStr2Byte(String hexStr) {
if (hexStr.length() < 1)
return null;
byte[] result = new byte[hexStr.length() / 2];
for (int i = 0; i < hexStr.length() / 2; i++) {
int high = Integer.parseInt(hexStr.substring(i * 2, i * 2 + 1), 16);
int low = Integer.parseInt(hexStr.substring(i * 2 + 1, i * 2 + 2), 16);
result[i] = (byte) (high * 16 + low);
}
return result;
}
/**
* 将二进制转换成16进制
*
* @param buf
* @return
*/
public static String parseByte2HexStr(byte buf[]) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < buf.length; i++) {
String hex = Integer.toHexString(buf[i] & 0xFF);
if (hex.length() == 1) {
hex = '0' + hex;
}
sb.append(hex.toUpperCase());
}
return sb.toString();
}
/**
* @param str
* @param key
* @return
* @throws Exception
*/
public static String aesEncrypt(String str, String key) throws Exception {
if (str == null || key == null)
return null;
Cipher cipher = Cipher.getInstance("AES/ECB/PKCS5Padding");
cipher.init(Cipher.ENCRYPT_MODE, new SecretKeySpec(key.getBytes("utf-8"), "AES"));
byte[] bytes = cipher.doFinal(str.getBytes("utf-8"));
return Base64.getEncoder().encodeToString(bytes);
}
public static String aesDecrypt(String str, String key) throws Exception {
if (str == null || key == null)
return null;
Cipher cipher = Cipher.getInstance("AES/ECB/PKCS5Padding");
cipher.init(Cipher.DECRYPT_MODE, new SecretKeySpec(key.getBytes("utf-8"), "AES"));
byte[] bytes = Base64.getDecoder().decode(str);
bytes = cipher.doFinal(bytes);
return new String(bytes, "utf-8");
}
public static void main(String[] args) throws Exception {
// 指定key
String base64Str1 = "cmVmb3JtZXJyZWZvcm1lcg==";
byte[] bs = Base64.getDecoder().decode(base64Str1);
System.out.println("base64Str1解密:"+ Arrays.toString(bs));
System.out.println("base64Str1解密:" + showByteArray(Base64.getDecoder().decode(base64Str1)));
Key key1 = toKey(Base64.getDecoder().decode(base64Str1));
String data1 = "{\"aaa\":\"bbb\"}";
System.out.println("明文:" + data1);
byte[] encryptData1 = encrypt(data1.getBytes(), key1);
String encryptStr1=parseByte2HexStr(encryptData1);
System.out.println("加密后数据1: byte[]:" + showByteArray(encryptData1));
System.out.println("加密后数据1: Byte2HexStr:" + encryptStr1);
System.out.println();
byte[] encryptStrByte1 = parseHexStr2Byte(encryptStr1);
byte[] decryptData1 = decrypt(encryptStrByte1, key1);
System.out.println("解密后数据: byte[]:" + showByteArray(decryptData1));
System.out.println("解密后数据: string:" + new String(decryptData1));
System.out.println("--------------------------------------------------------");
byte[] initKey = initSecretKey();
System.out.println("key:" + Arrays.toString(Base64.getEncoder().encode(initKey)));
System.out.println("key:" + showByteArray(initKey));
Key key2 = toKey(initKey);
String data2 = "{\"ccc\":\"ddd\"}";
System.out.println("明文:" + data2);
byte[] encryptData2 = encrypt(data2.getBytes(), key2);
String encryptStr2=parseByte2HexStr(encryptData2);
System.out.println("加密后数据1: byte[]:" + showByteArray(encryptData2));
System.out.println("加密后数据1: Byte2HexStr:" + encryptStr2);
System.out.println();
byte[] encryptStrByte2 = parseHexStr2Byte(encryptStr2);
byte[] decryptData2 = decrypt(encryptStrByte2, key2);
System.out.println("解密后数据: byte[]:" + showByteArray(decryptData2));
System.out.println("解密后数据: string:" + new String(decryptData2));
}
}
2.1.2 - fastjson
这里主要是Map和JSONObject的转换
package cn.anzhongwei.lean.demo.alibabafastjsondemo;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import java.util.Map;
public class JsonToMapDemo1 {
public static void main(String[] args){
String str = "{\"0\":\"zhangsan\",\"1\":\"lisi\",\"2\":\"wangwu\",\"3\":\"maliu\"}";
//第一种方式
Map maps = (Map) JSON.parse(str);
System.out.println("这个是用JSON类来解析JSON字符串!!!");
for (Object map : maps.entrySet()){
System.out.println(((Map.Entry)map).getKey()+" " + ((Map.Entry)map).getValue());
}
//第二种方式
Map mapTypes = JSON.parseObject(str);
System.out.println("这个是用JSON类的parseObject来解析JSON字符串!!!");
for (Object obj : mapTypes.keySet()){
System.out.println("key为:"+obj+"值为:"+mapTypes.get(obj));
}
//第三种方式
Map mapType = JSON.parseObject(str,Map.class);
System.out.println("这个是用JSON类,指定解析类型,来解析JSON字符串!!!");
for (Object obj : mapType.keySet()){
System.out.println("key为:"+obj+"值为:"+mapType.get(obj));
}
//第四种方式
Map json = (Map) JSONObject.parse(str);
System.out.println("这个是用JSONObject类的parse方法来解析JSON字符串!!!");
for (Object map : json.entrySet()){
System.out.println(((Map.Entry)map).getKey()+" "+((Map.Entry)map).getValue());
}
//第五种方式
JSONObject jsonObject = JSONObject.parseObject(str);
System.out.println("这个是用JSONObject的parseObject方法来解析JSON字符串!!!");
for (Object map : json.entrySet()){
System.out.println(((Map.Entry)map).getKey()+" "+((Map.Entry)map).getValue());
}
//第六种方式
Map mapObj = JSONObject.parseObject(str,Map.class);
System.out.println("这个是用JSONObject的parseObject方法并执行返回类型来解析JSON字符串!!!");
for (Object map: json.entrySet()){
System.out.println(((Map.Entry)map).getKey()+" "+((Map.Entry)map).getValue());
}
String strArr = "{{\"0\":\"zhangsan\",\"1\":\"lisi\",\"2\":\"wangwu\",\"3\":\"maliu\"}," +
"{\"00\":\"zhangsan\",\"11\":\"lisi\",\"22\":\"wangwu\",\"33\":\"maliu\"}}";
// JSONArray.parse()
System.out.println(json);
}
}
最终输出结果为:
这个是用JSON类来解析JSON字符串!!!
0 zhangsan
1 lisi
2 wangwu
3 maliu
这个是用JSON类的parseObject来解析JSON字符串!!!
key为:0值为:zhangsan
key为:1值为:lisi
key为:2值为:wangwu
key为:3值为:maliu
这个是用JSON类,指定解析类型,来解析JSON字符串!!!
key为:0值为:zhangsan
key为:1值为:lisi
key为:2值为:wangwu
key为:3值为:maliu
这个是用JSONObject类的parse方法来解析JSON字符串!!!
0 zhangsan
1 lisi
2 wangwu
3 maliu
这个是用JSONObject的parseObject方法来解析JSON字符串!!!
0 zhangsan
1 lisi
2 wangwu
3 maliu
这个是用JSONObject的parseObject方法并执行返回类型来解析JSON字符串!!!
0 zhangsan
1 lisi
2 wangwu
3 maliu
{"0":"zhangsan","1":"lisi","2":"wangwu","3":"maliu"}
2.1.3 - Integer比较
package cn.anzhongwei.lean.demo.intandinteger;
// java 9 以后 此初始化已经标记为废弃,推荐使用 Integer.valueOf("100");
public class IntegerTest {
public static void main(String[] args) {
int a = 100;
Integer b = 100;
if ( a == b ) {
//原因是由于此区间的只都是由IntegerCache.cache而来,具体查看Integer.valueOf(n)方法
//其中IntegerCache.cache static final Integer cache[];
System.out.println("-128 - 127 之间的int类型是在常量池中, ");
}
// 但是 Integer.valueOf("100");
Integer c = Integer.valueOf("300");
Integer d = Integer.valueOf("300");
if ( c != d ) {
System.out.println("Integer.valueOf(\"100\") 初始化的127以上的数字是放到推空间的");
}
Integer e = Integer.valueOf("100");
Integer f = Integer.valueOf("100");
if ( e == f ) {
System.out.println("Integer.valueOf(\"100\") 初始化的127以内的还是从常量池中获取");
}
Integer g = Integer.valueOf("400");
int h = 400;
if ( g == h ) {
System.out.println("Integer会向下转型");
}
}
}
2.1.4 - Java的参数是值传递
class User
package cn.anzhongwei.lean.demo.java传参;
public class User {
private String name;
private String Gender;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGender() {
return Gender;
}
public void setGender(String gender) {
Gender = gender;
}
}
package cn.anzhongwei.lean.demo.java传参;
/**
* 要理解java的传参
* 结果:
主类中实例化user1-hash:cn.anzhongwei.demo.java传参.User@4d7e1886
主类中实例化参数:Name=Hollis
方法中接受到参数user-hash:cn.anzhongwei.demo.java传参.User@4d7e1886 // 与main函数同一个对象
方法中重新实例化参数user-hash:cn.anzhongwei.demo.java传参.User@3cd1a2f1 // 产生新对象,但是只在局部有效
方法中重新实例化参数:Name=hollischuang
经过方法后的user1-hashcn.anzhongwei.demo.java传参.User@4d7e1886 //user1并没有因为在函数中局部参数实例化而发生变化
经过方法后的参数xiaoming //实例属性会被函数中的更改而发生变化
*/
public class PassOn {
public void pass(User user) {
System.out.println("方法中接受到参数user-hash:"+user);
user.setName("xiaoming");
user = new User();
user.setName("hollischuang");
System.out.println("方法中重新实例化参数user-hash:"+user);
System.out.println("方法中重新实例化参数:Name="+user.getName());
}
public static void main(String[] args) {
PassOn pt = new PassOn();
User user1 = new User();
System.out.println("主类中实例化user1-hash:"+user1);
user1.setName("Hollis");
user1.setGender("Male");
System.out.println("主类中实例化参数:Name="+user1.getName());
pt.pass(user1);
System.out.println("经过方法后的user1-hash" + user1);
System.out.println("经过方法后的参数" + user1.getName());
}
}
2.1.5 - Optional
package cn.anzhongwei.lean.demo.optional;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Optional;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Person {
private String name;
private Integer age;
private Address address;
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
public Optional<String> optionalGetName() {
return Optional.ofNullable(this.name);
}
}
package cn.anzhongwei.lean.demo.optional;
import lombok.Data;
@Data
public class Address {
private String city;
private String addInfo;
}
package cn.anzhongwei.lean.demo.optional;
import org.junit.Test;
import java.util.*;
import java.util.stream.Collectors;
public class OptionalTest {
/**
* Optional(T value),empty(),of(T value),ofNullable(T value)
* Optional(T value) 是private的属于内部方法
*/
@Test
public void test1() {
//of(T value) 是实际上调用了Optional(T value) 而其内部的requireNonNull方法源码中判断value==null时会抛出空指针异常
//在开发中如果不想隐藏空指针异常时 使用of函数, 不过这种情况几乎不用
//Optional<Person> p1 = Optional.of(null);
//所以如果要创建一个value为null的Optional对象则应该使用 empty()
Optional<Person> pnull = Optional.empty();
//而ofNullable(T value) 则是一个三元表达式 return value == null ? empty() : of(value);
Optional<Person> p0 = Optional.ofNullable(null);
Optional<Person> p1 = Optional.ofNullable(new Person("zhangs", 20));
}
/**
* orElse(T other),orElseGet(Supplier other)和orElseThrow(Supplier exceptionSupplier)
* 这三个函数放一组进行记忆,都是在构造函数传入的value值为null时,进行调用的。
* orElse 和 orElseGet 没区别 可以认为时完全一样的代码
*
* orElseThrow 则会当value为空时抛出一个自定义异常
*/
@Test
public void test2() {
Person p = null;
//当p值不为null时,orElse函数依然会执行createUser()方法
p = Optional.ofNullable(p).orElse(new Person("zhangsan", 20));
System.out.println("调用orElse 当p为null时:"+p);
//而当p不为空,则相当于使用get()方法
p = Optional.ofNullable(p).orElse(new Person("王五", 60));
System.out.println("调用orElse 此时p不为null时:"+p);
//
p = null;
//重新赋值p=null
System.out.println("重新赋值p=:"+p);
p = Optional.ofNullable(p).orElseGet(() -> new Person("lisi", 30));
System.out.println("orElseGet 当p为null时:"+p);
p = Optional.ofNullable(p).orElseGet(() -> new Person("zhaoliu", 34));
System.out.println("orElseGet 此时p不为null时:"+p);
}
@Test
public void testOrElseThrow() {
Person p = new Person("lisi", 30);
p = Optional.ofNullable(p).orElseThrow(()-> new RuntimeException("用户不存在"));
System.out.println("orElseThrow 此时p不为null时:"+p);
p = null;
p = Optional.ofNullable(p).orElseThrow(()-> new RuntimeException("用户不存在"));
}
/**
* map(Function mapper)和flatMap(Function> mapper)
* 这两个函数做的是转换值的操作
*/
@Test
public void test3() {
Person p = new Person("lisi", 30);
String name = Optional.ofNullable(p).map( person -> person.getName()).get();
System.out.println("name="+name);
String optionalName = Optional.ofNullable(p).flatMap(person -> person.optionalGetName()).get();
System.out.println("optionalName="+optionalName);
}
/**
* isPresent()和ifPresent(Consumer consumer)
* isPresent即判断value值是否为空,而ifPresent就是在value值不为空时,做一些操作。
*/
@Test
public void test4() {
Person p = null;
Optional.ofNullable(p).ifPresent(person -> {
});
}
/**
* filter(Predicate predicate)
*/
@Test
public void test5() {
Person p = null;
//如果 p.name 长度小于6则返回, 否则返回EMPTY
Optional<Person> p1 = Optional.ofNullable(p).filter(u -> u.getName().length()<6);
}
/**
* 实战写法1
*/
public String getCity(Person person) throws Exception{
if(person!=null){
if(person.getAddress()!=null){
Address address = person.getAddress();
if(address.getCity()!=null){
return address.getCity();
}
}
}
throw new RuntimeException("取值错误");
}
public String getCity2(Person person) throws Exception{
return Optional.ofNullable(person)
.map(u-> u.getAddress())
.map(a->a.getCity())
.orElseThrow(()->new Exception("取值错误"));
}
/**
* 实战写法2
*/
public void dosomething(Person person) {
if (Objects.nonNull(person)) {
//......
}
Optional.ofNullable(person).ifPresent(person1 -> {
//......
});
}
/**
* 实战写法3
*/
public Person getUser1(Person user){
if(user!=null){
String name = user.getName();
if(!"zhangsan".equals(name)){
user = new Person();
user.setName("zhangsan");
}
}else{
user = new Person();
user.setName("zhangsan");
}
return user;
}
public Person getUser2(Person user) {
return Optional.ofNullable(user)
.filter(u->"zhangsan".equals(u.getName()))
.orElseGet(()-> {
Person user1 = new Person();
user1.setName("zhangsan");
return user1;
});
}
public Person getUser3(Person user){
if(user!=null){
String name = user.getName();
if(!"zhangsan".equals(name)){
user.setName("zhangsan");
}
}else{
user = new Person();
user.setName("zhangsan");
}
return user;
}
public Person getUser4(Person user) {
//这个逻辑一般来说不会这么写, 大多数情况下都是不为空且不为zhangsan时, 将name赋值成zhangsan,而不是重新实例化
return Optional.ofNullable(user)
.filter(u->"zhangsan".equals(u.getName()))
.orElseGet(()-> {
if (Objects.nonNull(user)) {
user.setName("zhangsan");
return user;
} else {
Person user1 = new Person();
user1.setName("zhangsan");
return user1;
}
});
}
@Test
public void test6() {
//getUser1 和 getUser2 只要name不等于 zhangsan, 就重新初始化
Person p = new Person("wangwu", 26);
Person p1 = getUser1(p);
System.out.println("p1:"+p1);
p = new Person("lisi", 23);
Person p2 = getUser2(p);
System.out.println("p2:"+p2);
//getUser3 和 getUser4 name不等于 zhangsan, 只改变name=张三, 其他内容不变
p = new Person("zhaosi", 26);
Person p3 = getUser3(p);
System.out.println("p3:"+p3);
p = new Person("liuqi", 26);
Person p4 = getUser4(p);
System.out.println("p4:"+p4);
}
@Test
public void test7() {
List<Person> personList = new ArrayList<>();
Person p1 = new Person("zhangsan", 22);personList.add(p1);
Person p2 = new Person("zhaosi", 29);personList.add(p2);
Person p3 = new Person("wangwu", 22);personList.add(p3);
Person p4 = new Person("lisen", 35);personList.add(p4);
Person p5 = new Person("liuming", 248);personList.add(p5);
Optional<Person> personOptional = personList.stream().filter(p -> p.getAge() > 22).findFirst();
Person pp1 = personOptional.orElseGet(() -> personList.get(0));
System.out.println(pp1);
Person pp2 = personOptional.orElse(null);
System.out.println(pp2);
List<Person> personList2 = Optional.ofNullable(personList).orElseGet(ArrayList::new);
System.out.println(personList2);
Map<String, List<Person>> pMap = new HashMap<>();
// List<Person> personList3 = Optional.ofNullable(pMap.get("随便写"))
// //这种写法主要为了后面stream()的流式处理方式不会有空指针
// //这样会空指针
// .get()
// .stream().collect(Collectors.toList());
// System.out.println(personList3);
List<Person> personList4 = Optional.ofNullable(pMap.get("随便写"))
//这种写法主要为了后面stream()的流式处理方式不会有空指针
.orElseGet(ArrayList::new)
.stream().collect(Collectors.toList());
System.out.println(personList4);
}
}
2.1.6 - PDF转图片
package cn.anzhongwei.lean.demo.pdftoimg;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.rendering.ImageType;
import org.apache.pdfbox.rendering.PDFRenderer;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class PdfUtil {
public static void main(String[] args) {
String source = "C:\\Home\\22.pdf";
String desFileName = "invoice";
String desFilePath = "C:\\Home\\ddd";
String imageType = "png";
Long t1 = System.currentTimeMillis();
List<String> pair = PdfUtil.pdfToImg(source, desFilePath, desFileName, imageType);
Long t2 = System.currentTimeMillis();
System.out.println(t2-t1);
pair.forEach(System.out::println);
}
public static List<String> pdfToImg(String source, String desFilePath, String desFileName, String imageType) {
//通过给定的源路径名字符串创建一个File实例
File file = new File(source);
if (!file.exists()) {
throw new RuntimeException("文件不存在,无法转化");
}
//目录不存在则创建目录
File destination = new File(desFilePath);
if (!destination.exists()) {
boolean flag = destination.mkdirs();
System.out.println("创建文件夹结果:" + flag);
}
PDDocument doc = null;
try {
//加载PDF文件
doc = PDDocument.load(file);
PDFRenderer renderer = new PDFRenderer(doc);
//获取PDF文档的页数
int pageCount = doc.getNumberOfPages();
System.out.println("文档一共" + pageCount + "页");
List<String> fileList = new ArrayList<>();
for (int i = 0; i < pageCount; i++) {
//只有一页的时候文件名为传入的文件名,大于一页的文件名为:文件名_自增加数字(从1开始)
String realFileName = pageCount > 1 ? desFileName + "_" + (i + 1) : desFileName;
//每一页通过分辨率和颜色值进行转化
BufferedImage bufferedImage = renderer.renderImageWithDPI(i, 96*2, ImageType.RGB);
String filePath = desFilePath + File.separator + realFileName + "." + imageType;
//写入文件
ImageIO.write(bufferedImage, imageType, new File(filePath));
//文件名存入list
fileList.add(filePath);
}
return fileList;
} catch (IOException e) {
e.printStackTrace();
throw new RuntimeException("PDF转化图片异常,无法转化");
} finally {
try {
if (doc != null) {
doc.close();
}
} catch (IOException e) {
System.out.println("关闭文档失败");
e.printStackTrace();
}
}
}
}
2.1.7 - Serializable序列化
- Person
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.ToString;
import java.io.Serializable;
@Data
@ToString
@AllArgsConstructor
public class Person implements Serializable {
private String name;
private int age;
}
- Teacher
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.ToString;
import java.io.Serializable;
@Data
@ToString
@AllArgsConstructor
public class Teacher implements Serializable {
private String name;
private Person person;
}
- 写序列化到文件
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
// TODO 还没测试成功
public class WriteObject {
public static void main(String[] args) {
// try (//创建一个ObjectOutputStream输出流
// ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("C:\\Home\\teacher.txt"))) {
// //将对象序列化到文件s
// Person person = new Person("9龙", 23);
// Teacher teacher = new Teacher("路飞", person);
// oos.writeObject(teacher);
// } catch (Exception e) {
// e.printStackTrace();
// }
try (//创建一个ObjectOutputStream输出流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("D:\\teacher2.txt"))) {
//将对象序列化到文件s
Person person = new Person("路飞", 20);
Teacher t1 = new Teacher("雷利", person);
Teacher t2 = new Teacher("红发香克斯", person);
//依次将4个对象写入输入流
oos.writeObject(t1);
oos.writeObject(t2);
System.out.println(t2.hashCode());
oos.writeObject(person);
oos.writeObject(t2);
} catch (Exception e) {
e.printStackTrace();
}
}
}
- 从文件读序列化并实例化
import java.io.FileInputStream;
import java.io.ObjectInputStream;
public class ReadObject {
public static void main(String[] args) {
// try (//创建一个ObjectInputStream输入流
// ObjectInputStream ois = new ObjectInputStream(new FileInputStream("C:\\Home\\teacher.txt"))) {
// Teacher teacher = (Teacher) ois.readObject();
// System.out.println(teacher);
// } catch (Exception e) {
// e.printStackTrace();
// }
try (//创建一个ObjectInputStream输入流
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("D:\\teacher2.txt"))) {
Teacher t1 = (Teacher) ois.readObject();
Teacher t2 = (Teacher) ois.readObject();
Person p = (Person) ois.readObject();
Teacher t3 = (Teacher) ois.readObject();
System.out.println(t1 == t2);
System.out.println(t1.getPerson() == p);
System.out.println(t2.getPerson() == p);
System.out.println(t2 == t3);
System.out.println(t2.hashCode());
System.out.println(t3.hashCode());
System.out.println(t1.getPerson() == t2.getPerson());
} catch (Exception e) {
e.printStackTrace();
}
}
}
2.1.8 - SimpleFTPClient
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Inet4Address;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.util.Arrays;
import java.util.Base64;
import java.util.LinkedList;
import java.util.List;
import org.apache.commons.net.ftp.FTP;
import org.apache.commons.net.ftp.FTPClient;
import org.apache.commons.net.ftp.FTPFile;
import org.apache.commons.net.ftp.FTPReply;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
<!--apacheftp-->
<!--导入commons-net依赖-->
<!--https://mvnrepository.com/artifact/commons-net/commons-net-->
<dependency>
<groupId>commons-net</groupId>
<artifactId>commons-net</artifactId>
<version>3.6</version>
</dependency>
<!-- 引入Apache的commons-lang3包,方便操作字符串-->
<!--https://mvnrepository.com/artifact/org.apache.commons/commons-lang3-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.8</version>
</dependency>
<!--引入Apachecommons-io包,方便操作文件-->
<!--https://mvnrepository.com/artifact/commons-io/commons-io-->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
*/
public class SimpleFTPClient {
private static final Logger logger = LoggerFactory.getLogger(SimpleFTPClient.class);
private static FTPClient connectFtpServer(String url,String userName,String password){
String str = url.replaceFirst("ftp://", "").replaceFirst("FTP://", "");
str=str.replaceAll("/+", "/");
int endIndex = str.indexOf("/");
str = str.substring(0,endIndex);
url = str;//"ftp://"+str+"/";
String[] addr = url.split(":");
FTPClient ftpClient = new FTPClient();
ftpClient.setConnectTimeout(1000*5);//设置连接超时时间
// ftpClient.setControlEncoding("GBK");
ftpClient.setControlEncoding("utf-8");//设置ftp字符集
ftpClient.enterLocalPassiveMode();//设置被动模式,文件传输端口设置
try {
ftpClient.connect(addr[0],Integer.parseInt(addr[1]));
if(null==userName||"".equals(userName)){
userName = "anonymous";
password = "password";
}
boolean isLoginSuccess = ftpClient.login(userName,password);
logger.info("isLoginSuccess="+isLoginSuccess);
ftpClient.setFileType(FTP.BINARY_FILE_TYPE);//设置文件传输模式为二进制,可以保证传输的内容不会被改变
int replyCode = ftpClient.getReplyCode();
if (!FTPReply.isPositiveCompletion(replyCode)){
logger.error("connect ftp {} failed",url);
ftpClient.abort();
ftpClient.disconnect();
return null;
}
logger.info("replyCode==========={}",replyCode);
} catch (IOException e) {
logger.error("connect fail ------->>>{}",e);
return null;
}
return ftpClient;
}
/**
*
* @param inputStream 待上传文件的输入流
* @param originName 文件保存时的名字
*/
public void uploadFile(String url,String userName,String password,InputStream inputStream, String originName){
FTPClient ftpClient = connectFtpServer(url,userName,password);
if (ftpClient == null){
return;
}
/* try {
ftpClient.changeWorkingDirectory(remoteDir);//进入到文件保存的目录
Boolean isSuccess = ftpClient.storeFile(originName,inputStream);//保存文件
if (!isSuccess){
throw new BusinessException(ResponseCode.UPLOAD_FILE_FAIL_CODE,originName+"---》上传失败!");
}
logger.info("{}---》上传成功!",originName);
ftpClient.logout();
} catch (IOException e) {
logger.error("{}---》上传失败!",originName);
throw new BusinessException(ResponseCode.UPLOAD_FILE_FAIL_CODE,originName+"上传失败!");
}finally {
if (ftpClient.isConnected()){
try {
ftpClient.disconnect();
} catch (IOException e) {
logger.error("disconnect fail ------->>>{}",e.getCause());
}
}
} */
}
/**
* 读ftp上的文件,并将其转换成base64
* @param remoteFileName ftp服务器上的文件名
* @return
*/
public static String readFileToBase64(String url,String userName,String password){
logger.info("url={}",url);
FTPClient ftpClient = connectFtpServer(url,userName,password);
if (ftpClient == null){
return null;
}
logger.info("ftpClient={}",ftpClient.isAvailable()&&ftpClient.isConnected());
String base64 = "";
InputStream inputStream = null;
ByteArrayOutputStream os=null;
String remoteDir;
String str = url.replaceFirst("ftp://", "").replaceFirst("FTP://", "");
str=str.replaceAll("/+", "/");
int beginIndex = str.indexOf("/");
int endIndex = str.lastIndexOf("/");
remoteDir=str.substring(beginIndex,endIndex+1);
logger.info("remoteDir={}",remoteDir);
String remoteFileName = str.substring(endIndex+1);
logger.info("remoteFileName={}",remoteFileName);
try {
boolean chDirRes = ftpClient.changeWorkingDirectory(remoteDir);
logger.info("changeWorkingDirectory={}",chDirRes);
ftpClient.enterLocalPassiveMode();
FTPFile[] ftpFiles = ftpClient.listFiles(remoteDir);
logger.info("ftpFiles.length={}",ftpFiles.length);
Boolean flag = false;
//遍历当前目录下的文件,判断要读取的文件是否在当前目录下
for (FTPFile ftpFile:ftpFiles){
if (ftpFile.getName().equals(remoteFileName)){
flag = true;
break;
}
}
if (!flag){
logger.error("directory:{}下没有 {}",remoteDir,remoteFileName);
return null;
}
/* // 下载ftp上指定文件到本地
File localFile = new File("D:" + File.separator +"abc_"+ remoteFileName);
boolean downloaded = ftpClient.retrieveFile(remoteFileName,
new FileOutputStream(localFile));
System.out.println(ftpClient.getReplyString()); */
logger.info("开始获取文件流");
//获取待读文件输入流
inputStream = ftpClient.retrieveFileStream(remoteFileName); // remoteDir+remoteFileName
// //inputStream.available() 获取返回在不阻塞的情况下能读取的字节数,正常情况是文件的大小
logger.info("完成获取文件流");
byte[] bytes = new byte[1024];
os = new ByteArrayOutputStream();
int len=-1;
while( (len=inputStream.read(bytes))!=-1){//将文件数据读到字节数组中
os.write(bytes, 0, len);
}
os.flush();
byte[] fileBytes = os.toByteArray();
/* File file = new File("d:/"+remoteFileName);
OutputStream fos = new FileOutputStream(file);
try {
fos.write(fileBytes);
fos.flush();
} catch (Exception e) {
//TODO: handle exception
}
finally{
fos.close();
} */
int fileSize = fileBytes.length;
logger.info("fileSize={}",fileSize);
Base64.Encoder encoder = Base64.getEncoder();
base64 = encoder.encodeToString(fileBytes);
logger.debug("base64 img="+base64);
logger.info("read file {} success",remoteFileName);
if(!ftpClient.completePendingCommand()) {
ftpClient.logout();
ftpClient.disconnect();
logger.error("File transfer failed.");
return null;
}
ftpClient.logout();
} catch (IOException e) {
logger.error("read file fail ----->>>{}",e.getCause());
return null;
}finally {
if (ftpClient.isConnected()){
try {
ftpClient.disconnect();
} catch (IOException e) {
logger.error("disconnect fail ------->>>{}",e.getCause());
}
}
if (inputStream != null){
try {
inputStream.close();
} catch (IOException e) {
logger.error("inputStream close fail -------- {}",e.getCause());
}
}
if (os != null){
try {
os.close();
} catch (IOException e) {
logger.error("os close fail -------- {}",e.getCause());
}
}
}
return base64;
}
/**
* 文件下载
* @param remoteFileName ftp上的文件名
* @param localFileName 本地文件名
*/
public void download(String url,String userName,String password,String remoteFileName,String localFileName){
FTPClient ftpClient = connectFtpServer(url,userName,password);
if (ftpClient == null){
return ;
}
OutputStream outputStream = null;
/* try {
ftpClient.changeWorkingDirectory(remoteDir);
FTPFile[] ftpFiles = ftpClient.listFiles(remoteDir);
Boolean flag = false;
//遍历当前目录下的文件,判断是否存在待下载的文件
for (FTPFile ftpFile:ftpFiles){
if (ftpFile.getName().equals(remoteFileName)){
flag = true;
break;
}
}
if (!flag){
logger.error("directory:{}下没有 {}",remoteDir,remoteFileName);
return ;
}
outputStream = new FileOutputStream(localDir+localFileName);//创建文件输出流
Boolean isSuccess = ftpClient.retrieveFile(remoteFileName,outputStream); //下载文件
if (!isSuccess){
logger.error("download file 【{}】 fail",remoteFileName);
}
logger.info("download file success");
ftpClient.logout();
} catch (IOException e) {
logger.error("download file 【{}】 fail ------->>>{}",remoteFileName,e.getCause());
}finally {
if (ftpClient.isConnected()){
try {
ftpClient.disconnect();
} catch (IOException e) {
logger.error("disconnect fail ------->>>{}",e.getCause());
}
}
if (outputStream != null){
try {
outputStream.close();
} catch (IOException e) {
logger.error("outputStream close fail ------->>>{}",e.getCause());
}
}
} */
}
public static void main(String[] args) {
// String ftpPath = "ftp://192.168.1.3:8010/recordsImg/2019-05-31/STRANGERBABY_1559265983072.jpg";
// readFileToBase64(ftpPath,"","");
String url="ftp://106.12.195.197:21/";
FTPClient ftpClient = connectFtpServer(url,"myftp","123456");
if (ftpClient == null){
return ;
}
logger.info("ftpClient={}",ftpClient.isAvailable()&&ftpClient.isConnected());
String base64 = "";
InputStream inputStream = null;
ByteArrayOutputStream os=null;
String remoteDir;
String str = url.replaceFirst("ftp://", "").replaceFirst("FTP://", "");
str=str.replaceAll("/+", "/");
int beginIndex = str.indexOf("/");
// int endIndex = str.lastIndexOf("/");
// remoteDir=str.substring(beginIndex,endIndex+1);
String remotePath =str.substring(beginIndex);
logger.info("remotePath={}",remotePath);
String status="nil";
try {
status=ftpClient.getStatus(remotePath);
} catch (Exception e) {
//TODO: handle exception
e.printStackTrace();
}
logger.info("ftpClient.getStatus={}",status);
try {
// boolean chDirRes = ftpClient.changeWorkingDirectory(remoteDir);
// logger.info("changeWorkingDirectory={}",chDirRes);
// ftpClient.enterLocalPassiveMode();
/* FTPFile[] ftpFiles = ftpClient.listFiles(remoteDir);
logger.info("ftpFiles.length={}",ftpFiles.length);
Boolean flag = false;
//遍历当前目录下的文件,判断要读取的文件是否在当前目录下
for (FTPFile ftpFile:ftpFiles){
logger.info("ftpFiles------{}",ftpFile.getName());
} */
// boolean renameRes = ftpClient.rename("/imgfacebak/bb1.png", "/test/a.png");
// logger.info("renameRes={}",renameRes);
// if(!ftpClient.completePendingCommand()) {
// ftpClient.logout();
// ftpClient.disconnect();
// logger.error("File transfer failed.");
// return ;
// }
ftpClient.logout();
} catch (IOException e) {
logger.error("read file fail ----->>>{}",e.getCause());
return ;
}finally {
if (ftpClient.isConnected()){
try {
ftpClient.disconnect();
} catch (IOException e) {
logger.error("disconnect fail ------->>>{}",e.getCause());
}
}
}
}
}
2.1.9 - Spring专栏
所有和Spring相关的内容。
2.1.9.1 - 多个网卡时指定注册ip段.md
添加配置项
cloud:
inetutils:
preferred-networks: 192.168.*
2.1.9.2 - 如何在pom文件中管理多个环境
2.1.9.3 - Spring 上传文件的配置
spring:
servlet:
multipart:
#配置文件传输
enabled: true
file-size-threshold: 0B
#单个文件的最大上限
max-file-size: 100MB
#单个请求的文件总大小上限
max-request-size: 1000MB
2.1.9.4 - SpringBoot单元测试
测试均通过 SpringBoot3.5.0、JDK版本21。
简介
1. 完全脱离上下文(纯单元测试)
-
实现方式:
Mockito+JUnit5(无Spring注解) -
特点:
-
仅测试类自身逻辑
-
执行速度最快(毫秒级)
-
-
适用场景:Service工具类、纯POJO逻辑测试
-
代码示例:
@ExtendWith(MockitoExtension.class)
class GoodsControllerTest {
private MockMvc mockMvc;
// 需要模拟的控制器
@InjectMocks // 可以注入要模拟的类
private GoodsController goodsController;
// 需要打桩的Service
@Mock
GoodsService goodsService;
@BeforeEach
public void initOne() {
// 通过goodsController构建mvc模拟对象
mockMvc = MockMvcBuilders.standaloneSetup(goodsController).build();
}
}
2. 部分加载上下文(切片测试)
-
实现方式:
@WebMvcTest/@DataJpaTest等 -
特点:
-
仅加载相关模块组件(如MVC层/JPA层)
-
启动较快(秒级)
-
-
适用场景:控制器测试、Repository接口测试
-
代码示例:
@WebMvcTest(HomeController.class) // HomeController要测试那个控制器
class GoodsControllerTest {
@Autowired
private MockMvc mockMvc;
// 需要打桩的Service
@MockitoBean
GoodsService goodsService;
}
3. 完全加载上下文(集成测试)
-
实现方式:
@SpringBootTest -
特点:
-
加载完整Spring容器
-
支持真实数据库交互
-
启动慢(10秒+)
-
-
适用场景:端到端测试、多组件协同测试
-
代码示例:
@AutoConfigureMockMvc
@SpringBootTest
class GoodsControllerTest {
@Autowired
private MockMvc mockMvc;
// 需要模拟的控制器
@InjectMocks // 可以注入要模拟的类
private GoodsController goodsController;
// 需要打桩的Service
@MockitoBean
GoodsService goodsService;
}
测试用例
测试用例项目源代码: https://gitee.com/azhw/rookiedev-example/tree/master/编程/编程语言/Java/最佳实践/unittest/SpringBoot3UnitTest
-
Service测试: no01servicetest
-
Controller测试: no02ControllerTest
-
Controller对Service打桩&Service对Mapper打桩的测试: no03MockitoService
-
对文件上传下载的测试: no04FileUploadDownload
-
使用H2数据库对数据写入进行实际测试: no05H2DBTest
在 no03MockitoService 其实已经包含了该测试内容
-
测试Controller 对 Cookie 、 Session 、 Header 的读写: no06CookieSessionHeaderTest
-
使用嵌入式redis服务器(embedded-redis)对Redis进行测试: no07RedisTest
这种场景只有使用完整的spring容器方式进行单元测试能进行测试, 其他两种(完全脱离spring和部分启动的方式只能对redisTemplate进行打桩测试)
-
测试SrpingBoot的Filter: no08SpringFilterTest
-
演示controller使用thymeleaf模板而不是返回json时的单元测试: no09ThymeleafTest
-
异步调用测试: no10AsyncTest
-
Service超时测试: no11TimeoutTest
-
普通的类中(不是spring bean) 静态方法和非静态方法的打桩测试:no12NoSpringBeanMethodMockTest
2.1.10 - Stream API示例
import lombok.Data;
import org.junit.Test;
import java.util.*;
import java.util.stream.Collectors;
public class StreamAPI {
/**
*
* Comparator.reverseOrder()是让某个条件进行倒序排序.
* reversed()是让他前面的字段进行倒序。
*
* 例如:Comparator.comparing(名称).reversed(),此时名称倒序;
* Comparator.comparing(名称).thenComparing(状态).reversed(),此时名称和状态进行倒序。
*
* Comparator.comparing(名称).thenComparing(状态).reversed().thenComparing(年龄),此时名称和状态会倒序,年龄会升序。
*
* 加多个.reversed()
* Comparator.comparing(状态).reversed().thenComparing(年龄).reversed(),最终结果是只有年龄倒排,状态未排序
*/
/**
* 练习1:让年龄进行倒序排序。
*/
@Test
public void test1() {
/*
* Comparator.comparing(放实体类名称::放列名):添加排序字段;
* reversed():倒序。
* collect(Collectors.toList()):转成集合。
* forEach(System.out::println):打印循环。
*/
List<User> userList = generatorUserList();
// userList.stream()
// .sorted(Comparator.comparing(User::getAge).reversed())//reversed()是让其前面得所有字段都倒排
// .collect(Collectors.toList())
// .forEach(System.out::println);
// List<User> userList2 = generatorUserList();
// userList2.stream()
// .sorted(Comparator.comparing(User::getAge, Comparator.reverseOrder()))//Comparator.reverseOrder()是让某个条件进行倒序排序
// .collect(Collectors.toList()).forEach(System.out::println);
userList.stream().sorted(Comparator.comparing(User::getAge).reversed())
.collect(Collectors.toList()).forEach(System.out::println);
}
/**
* 练习2:让使用状态进行升序排序。
*/
@Test
public void test2() {
List<User> userList = generatorUserList();
//默认是升序,所以只需要把排序字段放进去就行了。
userList.stream().sorted(Comparator.comparing(User::getAge)).collect(Collectors.toList()).forEach(System.out::println);
}
/**
* 练习3:让使用先状态和后年龄都进行倒序排序。
*/
@Test
public void test3() {
List<User> userList = generatorUserList();
userList.stream()
//先根据使用状态倒序,而王五使用状态为2,所以王五排在第一。
//而李四和张三使用状态都是1,就会触发另一个排序条件根据年龄排序
.sorted(Comparator.comparing(User::getState).thenComparing(User::getAge).reversed())
.collect(Collectors.toList())
.forEach(System.out::println);
//写法2
List<User> userList2 = generatorUserList();
userList2.stream()
.sorted(
Comparator.comparing(User::getState, Comparator.reverseOrder())//根据state倒排
.thenComparing(User::getAge, Comparator.reverseOrder())//根据age倒排
)
.forEach(System.out::println);
}
/**
* 练习4:让使用状态和年龄都进行升序排序。
*/
@Test
public void test4() {
List<User> userList = generatorUserList();
//默认就是升序
userList.stream().sorted(Comparator.comparing(User::getState).thenComparing(User::getAge)).forEach(System.out::println);
}
/**
* 练习5:让使用状态进行升序排序,年龄进行倒序排序,创建时间进行倒序排序。名字正排序
* 注意:假如多个排序条件的排序方向不一致,需要倒序的字段应该用Comparator.reverseOrder(),每个倒排得字段单独写。
*/
@Test
public void test5() {
List<User> userList = generatorUserList();
userList.stream()
.sorted(
Comparator.comparing(User::getState)
.thenComparing(User::getAge, Comparator.reverseOrder())
.thenComparing(User::getCreateTime,Comparator.reverseOrder())
.thenComparing(User::getName)
)
.forEach(System.out::println);
}
/**
* 练习6,按 State 分组 组成 Map<Ingeter, List<User>>的结构
*/
@Test
public void test6() {
List<User> userList = generatorUserList();
Map<Integer, List<User>> stateToUserList = userList.stream().collect(Collectors.groupingBy(User::getState));
System.out.println(stateToUserList);
}
/**
* 联系7 根据姓名作为key, User对象为val,组成map<String, User>
* 如果是根据state, 因为元素不唯一, 所以会抛出异常
* 根据姓名为key, age为val组成 map<String, Ingeter>
*/
@Test
public void test7() {
List<User> userList = generatorUserList();
Map<String, User> nameToUser = userList.stream().collect(Collectors.toMap(User::getName, user -> user));
//下面这样也行
// Map<String, User> nameToUser = userList.stream().collect(Collectors.toMap(User::getName, user -> {return user;}));
System.out.println(nameToUser);
//在映射时, 把年龄加1再返回
Map<String, User> nameToAge0 = userList.stream().collect(Collectors.toMap(User::getName, user -> { user.setAge(user.age+1); return user;}));
System.out.println(nameToAge0);
//那么如果分组的字段是一个非唯一的,比如state, 会报错
// Map<Integer, User> stateToUser = userList.stream().collect(Collectors.toMap(User::getState, user -> user));
// System.out.println(stateToUser);
//根据姓名为key, age为val组成 map<String, Ingeter>
//写法1
Map<String, Integer> nameToAge = userList.stream().collect(Collectors.toMap(User::getName, User::getAge));
System.out.println(nameToAge);
//写法2
Map<String, Integer> nameToAge2 = userList.stream().collect(Collectors.toMap(User::getName, user -> {return user.age;}));
System.out.println(nameToAge2);
Map<String, Integer> nameToAge3 = userList.stream().collect(Collectors.toMap(User::getName, user -> { user.setAge(user.age+1); return user.age;}));
System.out.println(nameToAge3);
}
/**
* 练习8 按名字去重
*/
@Test
public void test8() {
List<User> userList = generatorUserList();
Set<String> collect1 = userList.stream().distinct().map(User::getName).collect(Collectors.toSet());
System.out.println(collect1);
return;
}
/**
* 按名字统计数量
*/
@Test
public void test9() {
List<User> userList = generatorUserList();
Map<String, Long> collect = userList.stream().collect(Collectors.groupingBy(User::getName, Collectors.counting()));
System.out.println(collect);
return;
}
/**
* 求年龄最大值、最小值
*/
@Test
public void test10() {
List<User> userList = generatorUserList();
//如果有年龄一样的,会按list顺序取第一条, 所以除非能唯一, 否则多维度需要使用排序来获取值
Optional<User> min = userList.stream().min(Comparator.comparing(User::getAge));
System.out.println("min = " + min);
}
/**
* 获取某个字段的 最大值、最小值、求和、统计、计数
*/
@Test
public void test11() {
List<User> userList = generatorUserList();
IntSummaryStatistics collect = userList.stream().collect(Collectors.summarizingInt(User::getAge));
double average = collect.getAverage();
int max = collect.getMax();
int min = collect.getMin();
long sum = collect.getSum();
long count = collect.getCount();
System.out.println("collect = " + collect);
//单独对某个字段汇总
int sum1 = userList.stream().mapToInt(User::getAge).sum();
System.out.println("sum = " + sum1);
double avg1 = userList.stream().collect(Collectors.averagingDouble(User::getAge));
System.out.println("avg1 = " + avg1);
OptionalDouble avg2 = userList.stream().mapToDouble(User::getAge).average();
if (avg2.isPresent()) {
System.out.println("avg2 = " + avg2);
}
}
/**
* 按名字分组, 统计年龄相关的 计数, 总数,最大,最小,平均
*/
@Test
public void test12() {
List<User> userList = generatorUserList();
Map<String, IntSummaryStatistics> collect = userList.stream().collect(Collectors.groupingBy(User::getName, Collectors.summarizingInt(User::getAge)));
for(Map.Entry<String, IntSummaryStatistics> entry : collect.entrySet()) {
System.out.println(entry.getKey()+"-----"+entry.getValue());
}
}
/**
* 生成用户示例用户列表
* @return
*/
private List<User> generatorUserList() {
List<User> list = new ArrayList<>();
User user1 = new User();
user1.setName("19");
user1.setAge(18);
user1.setState(1);
user1.setCreateTime(new Date());
list.add(user1);
User user2 = new User();
user2.setName("1");
user2.setAge(22);
user2.setState(1);
user2.setCreateTime(new Date());
list.add(user2);
User user3 = new User();
user3.setName("2");
user3.setAge(15);
user3.setState(2);
user3.setCreateTime(new Date());
list.add(user3);
User user4 = new User();
user4.setName("23");
user4.setAge(15);
user4.setState(2);
user4.setCreateTime(new Date());
list.add(user4);
User user5 = new User();
user5.setName("23");
user5.setAge(18);
user5.setState(2);
user5.setCreateTime(new Date());
list.add(user5);
return list;
}
@Data
class User{
private String name;
private Integer age;
private Integer state;
private Date createTime;
}
}
2.1.11 - String API
/**
* public final class String
* String 是包装类型,且为final修饰不能被继承
* 一下提供字符串拼接和字符串反转的方法
*/
public class StringUtils {
public static void main(String[] args) {
StringUtils.stringJoin();
StringUtils.stringReverse();
}
public static void stringJoin(){
//StringBuffer字符串连接 线程安全的
StringBuffer buffer = new StringBuffer();
buffer.append("a");
buffer.append("b");
buffer.append("c");
buffer.append("d");
System.out.println(buffer.toString());
//StringBuilder字符串连接, 非线程安全的,但是速度快
StringBuilder builder = new StringBuilder();
builder.append("a");
builder.append("b");
builder.append("c");
builder.append("d");
System.out.println(builder.toString());
}
//字符串反转
public static void stringReverse(){
// StringBuffer reverse
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("abcdefg");
System.out.println(stringBuffer.reverse()); // gfedcba
// StringBuilder reverse
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("abcdefg");
System.out.println(stringBuilder.reverse()); // gfedcba
}
}
2.1.12 - TryCache到底怎么返回值
package cn.anzhongwei.lean.demo;
public class TestTryCatch {
public static void main(String[] args) {
System.out.println(getInt1());
System.out.println(getInt2());
}
public static int getInt1() {
int a = 10;
try {
System.out.println(a / 0);
a = 20;
} catch (ArithmeticException e) {
a = 30;
return a;
/*
* return a 在程序执行到这一步的时候,这里不是return a 而是 return 30;这个返回路径就形成了
* 但是呢,它发现后面还有finally,所以继续执行finally的内容,a=40
* 再次回到以前的路径,继续走return 30,形成返回路径之后,这里的a就不是a变量了,而是常量30
*/
} finally {
a = 40;
}
return a;
}
public static int getInt2() {
int a = 10;
try {
System.out.println(a / 0);
a = 20;
} catch (ArithmeticException e) {
a = 30;
return a;
/*
* return a 在程序执行到这一步的时候,这里不是return a 而是 return 30;这个返回路径就形成了
* 但是呢,它发现后面还有finally,所以继续执行finally的内容,a=40
* 再次回到以前的路径,继续走return 30,形成返回路径之后,这里的a就不是a变量了,而是常量30
*/
} finally {
a = 40;
return a; //如果这样,就又重新形成了一条返回路径,由于只能通过1个return返回,所以这里直接返回40
}
// return a;
}
}
2.1.13 - Valid参数校验
简单使用
Java API规范(JSR303)定义了Bean校验的标准validation-api,但没有提供实现。hibernate validation是对这个规范的实现,并增加了校验注解如@Email、@Length等。
Spring Validation是对hibernate validation的二次封装,用于支持spring mvc参数自动校验。接下来,我们以spring-boot项目为例,介绍Spring Validation的使用。
引入依赖
如果spring-boot版本小于2.3.x,spring-boot-starter-web会自动传入hibernate-validator依赖。如果spring-boot版本大于2.3.x,则需要手动引入依赖:
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>6.0.1.Final</version>
</dependency>
对于web服务来说,为防止非法参数对业务造成影响,在Controller层一定要做参数校验的!大部分情况下,请求参数分为如下两种形式:
-
POST、PUT请求,使用requestBody传递参数;
-
GET请求,使用requestParam/PathVariable传递参数。
下面我们简单介绍下requestBody和requestParam/PathVariable的参数校验实战!
requestBody参数校验
POST、PUT请求一般会使用requestBody传递参数,这种情况下,后端使用DTO对象进行接收。只要给DTO对象加上@Validated注解就能实现自动参数校验。比如,有一个保存User的接口,要求userName长度是2-10,account和password字段长度是6-20。
如果校验失败,会抛出MethodArgumentNotValidException异常,Spring默认会将其转为400(Bad Request)请求。
DTO表示数据传输对象(Data Transfer Object),用于服务器和客户端之间交互传输使用的。在spring-web项目中可以表示用于接收请求参数的Bean对象。
在DTO字段上声明约束注解
@Data
public class UserDTO {
private Long userId;
@NotNull
@Length(min = 2, max = 10)
private String userName;
@NotNull
@Length(min = 6, max = 20)
private String account;
@NotNull
@Length(min = 6, max = 20)
private String password;
}
在方法参数上声明校验注解
@PostMapping("/save")
public Result saveUser(@RequestBody @Validated UserDTO userDTO) {
// 校验通过,才会执行业务逻辑处理
return Result.ok();
}
这种情况下,使用@Valid和@Validated都可以。
requestParam/PathVariable参数校验
GET请求一般会使用requestParam/PathVariable传参。如果参数比较多(比如超过6个),还是推荐使用DTO对象接收。
否则,推荐将一个个参数平铺到方法入参中。在这种情况下,必须在Controller类上标注@Validated注解,并在入参上声明约束注解(如@Min等)。如果校验失败,会抛出ConstraintViolationException异常。
代码示例如下:
@RequestMapping("/api/user")
@RestController
@Validated
public class UserController {
// 路径变量
@GetMapping("{userId}")
public Result detail(@PathVariable("userId") @Min(10000000000000000L) Long userId) {
// 校验通过,才会执行业务逻辑处理
UserDTO userDTO = new UserDTO();
userDTO.setUserId(userId);
userDTO.setAccount("11111111111111111");
userDTO.setUserName("xixi");
userDTO.setAccount("11111111111111111");
return Result.ok(userDTO);
}
// 查询参数
@GetMapping("getByAccount")
public Result getByAccount(@Length(min = 6, max = 20) @NotNull String account) {
// 校验通过,才会执行业务逻辑处理
UserDTO userDTO = new UserDTO();
userDTO.setUserId(10000000000000003L);
userDTO.setAccount(account);
userDTO.setUserName("xixi");
userDTO.setAccount("11111111111111111");
return Result.ok(userDTO);
}
}
统一异常处理
前面说过,如果校验失败,会抛出MethodArgumentNotValidException或者ConstraintViolationException异常。在实际项目开发中,通常会用统一异常处理来返回一个更友好的提示。
比如我们系统要求无论发送什么异常,http的状态码必须返回200,由业务码去区分系统的异常情况。
@RestControllerAdvice
public class CommonExceptionHandler {
@ExceptionHandler({MethodArgumentNotValidException.class})
@ResponseStatus(HttpStatus.OK)
@ResponseBody
public Result handleMethodArgumentNotValidException(MethodArgumentNotValidException ex) {
BindingResult bindingResult = ex.getBindingResult();
StringBuilder sb = new StringBuilder("校验失败:");
for (FieldError fieldError : bindingResult.getFieldErrors()) {
sb.append(fieldError.getField()).append(":").append(fieldError.getDefaultMessage()).append(", ");
}
String msg = sb.toString();
return Result.fail(BusinessCode.参数校验失败, msg);
}
@ExceptionHandler({ConstraintViolationException.class})
@ResponseStatus(HttpStatus.OK)
@ResponseBody
public Result handleConstraintViolationException(ConstraintViolationException ex) {
return Result.fail(BusinessCode.参数校验失败, ex.getMessage());
}
}
进阶使用
分组校验
在实际项目中,可能多个方法需要使用同一个DTO类来接收参数,而不同方法的校验规则很可能是不一样的。这个时候,简单地在DTO类的字段上加约束注解无法解决这个问题。因此,spring-validation支持了分组校验的功能,专门用来解决这类问题。
还是上面的例子,比如保存User的时候,UserId是可空的,但是更新User的时候,UserId的值必须>=10000000000000000L;其它字段的校验规则在两种情况下一样。这个时候使用分组校验的代码示例如下:
约束注解上声明适用的分组信息groups
@Data
public class UserDTO {
@Min(value = 10000000000000000L, groups = Update.class)
private Long userId;
@NotNull(groups = {Save.class, Update.class})
@Length(min = 2, max = 10, groups = {Save.class, Update.class})
private String userName;
@NotNull(groups = {Save.class, Update.class})
@Length(min = 6, max = 20, groups = {Save.class, Update.class})
private String account;
@NotNull(groups = {Save.class, Update.class})
@Length(min = 6, max = 20, groups = {Save.class, Update.class})
private String password;
/**
* 保存的时候校验分组
*/
public interface Save {
}
/**
* 更新的时候校验分组
*/
public interface Update {
}
}
@Validated注解上指定校验分组
@PostMapping("/save")
public Result saveUser(@RequestBody @Validated(UserDTO.Save.class) UserDTO userDTO) {
// 校验通过,才会执行业务逻辑处理
return Result.ok();
}
@PostMapping("/update")
public Result updateUser(@RequestBody @Validated(UserDTO.Update.class) UserDTO userDTO) {
// 校验通过,才会执行业务逻辑处理
return Result.ok();
}
嵌套校验
前面的示例中,DTO类里面的字段都是基本数据类型和String类型。但是实际场景中,有可能某个字段也是一个对象,这种情况先,可以使用嵌套校验。
比如,上面保存User信息的时候同时还带有Job信息。需要注意的是,此时DTO类的对应字段必须标记@Valid注解。
@Data
public class UserDTO {
@Min(value = 10000000000000000L, groups = Update.class)
private Long userId;
@NotNull(groups = {Save.class, Update.class})
@Length(min = 2, max = 10, groups = {Save.class, Update.class})
private String userName;
@NotNull(groups = {Save.class, Update.class})
@Length(min = 6, max = 20, groups = {Save.class, Update.class})
private String account;
@NotNull(groups = {Save.class, Update.class})
@Length(min = 6, max = 20, groups = {Save.class, Update.class})
private String password;
@NotNull(groups = {Save.class, Update.class})
@Valid
private Job job;
@Data
public static class Job {
@Min(value = 1, groups = Update.class)
private Long jobId;
@NotNull(groups = {Save.class, Update.class})
@Length(min = 2, max = 10, groups = {Save.class, Update.class})
private String jobName;
@NotNull(groups = {Save.class, Update.class})
@Length(min = 2, max = 10, groups = {Save.class, Update.class})
private String position;
}
/**
* 保存的时候校验分组
*/
public interface Save {
}
/**
* 更新的时候校验分组
*/
public interface Update {
}
}
嵌套校验可以结合分组校验一起使用。还有就是嵌套集合校验会对集合里面的每一项都进行校验,例如List<Job>字段会对这个list里面的每一个Job对象都进行校验
集合校验
如果请求体直接传递了json数组给后台,并希望对数组中的每一项都进行参数校验。此时,如果我们直接使用java.util.Collection下的list或者set来接收数据,参数校验并不会生效!我们可以使用自定义list集合来接收参数:
包装List类型,并声明@Valid注解
public class ValidationList<E> implements List<E> {
@Delegate // @Delegate是lombok注解
@Valid // 一定要加@Valid注解
public List<E> list = new ArrayList<>();
// 一定要记得重写toString方法
@Override
public String toString() {
return list.toString();
}
}
@Delegate注解受lombok版本限制,1.18.6以上版本可支持。如果校验不通过,会抛出NotReadablePropertyException,同样可以使用统一异常进行处理。
比如,我们需要一次性保存多个User对象,Controller层的方法可以这么写:
@PostMapping("/saveList")
public Result saveList(@RequestBody @Validated(UserDTO.Save.class) ValidationList<UserDTO> userList) {
// 校验通过,才会执行业务逻辑处理
return Result.ok();
}
自定义校验
业务需求总是比框架提供的这些简单校验要复杂的多,我们可以自定义校验来满足我们的需求。
自定义spring validation非常简单,假设我们自定义加密id(由数字或者a-f的字母组成,32-256长度)校验,主要分为两步:
自定义约束注解
@Target({METHOD, FIELD, ANNOTATION_TYPE, CONSTRUCTOR, PARAMETER})
@Retention(RUNTIME)
@Documented
@Constraint(validatedBy = {EncryptIdValidator.class})
public @interface EncryptId {
// 默认错误消息
String message() default "加密id格式错误";
// 分组
Class<?>[] groups() default {};
// 负载
Class<? extends Payload>[] payload() default {};
}
实现ConstraintValidator接口编写约束校验器
public class EncryptIdValidator implements ConstraintValidator<EncryptId, String> {
private static final Pattern PATTERN = Pattern.compile("^[a-f\\d]{32,256}$");
@Override
public boolean isValid(String value, ConstraintValidatorContext context) {
// 不为null才进行校验
if (value != null) {
Matcher matcher = PATTERN.matcher(value);
return matcher.find();
}
return true;
}
}
这样我们就可以使用@EncryptId进行参数校验了!
编程式校验
上面的示例都是基于注解来实现自动校验的,在某些情况下,我们可能希望以编程方式调用验证。这个时候可以注入javax.validation.Validator对象,然后再调用其api。
@Autowired
private javax.validation.Validator globalValidator;
// 编程式校验
@PostMapping("/saveWithCodingValidate")
public Result saveWithCodingValidate(@RequestBody UserDTO userDTO) {
Set<ConstraintViolation<UserDTO>> validate = globalValidator.validate(userDTO, UserDTO.Save.class);
// 如果校验通过,validate为空;否则,validate包含未校验通过项
if (validate.isEmpty()) {
// 校验通过,才会执行业务逻辑处理
} else {
for (ConstraintViolation<UserDTO> userDTOConstraintViolation : validate) {
// 校验失败,做其它逻辑
System.out.println(userDTOConstraintViolation);
}
}
return Result.ok();
}
快速失败(Fail Fast)
Spring Validation默认会校验完所有字段,然后才抛出异常。可以通过一些简单的配置,开启Fali Fast模式,一旦校验失败就立即返回。
@Bean
public Validator validator() {
ValidatorFactory validatorFactory = Validation.byProvider(HibernateValidator.class)
.configure()
// 快速失败模式
.failFast(true)
.buildValidatorFactory();
return validatorFactory.getValidator();
}
@Valid和@Validated区别

实现原理
requestBody参数校验实现原理
在spring-mvc中,RequestResponseBodyMethodProcessor是用于解析@RequestBody标注的参数以及处理@ResponseBody标注方法的返回值的。显然,执行参数校验的逻辑肯定就在解析参数的方法resolveArgument()中:
public class RequestResponseBodyMethodProcessor extends AbstractMessageConverterMethodProcessor {
@Override
public Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception {
parameter = parameter.nestedIfOptional();
//将请求数据封装到DTO对象中
Object arg = readWithMessageConverters(webRequest, parameter, parameter.getNestedGenericParameterType());
String name = Conventions.getVariableNameForParameter(parameter);
if (binderFactory != null) {
WebDataBinder binder = binderFactory.createBinder(webRequest, arg, name);
if (arg != null) {
// 执行数据校验
validateIfApplicable(binder, parameter);
if (binder.getBindingResult().hasErrors() && isBindExceptionRequired(binder, parameter)) {
throw new MethodArgumentNotValidException(parameter, binder.getBindingResult());
}
}
if (mavContainer != null) {
mavContainer.addAttribute(BindingResult.MODEL_KEY_PREFIX + name, binder.getBindingResult());
}
}
return adaptArgumentIfNecessary(arg, parameter);
}
}
可以看到,resolveArgument()调用了validateIfApplicable()进行参数校验。
protected void validateIfApplicable(WebDataBinder binder, MethodParameter parameter) {
// 获取参数注解,比如@RequestBody、@Valid、@Validated
Annotation[] annotations = parameter.getParameterAnnotations();
for (Annotation ann : annotations) {
// 先尝试获取@Validated注解
Validated validatedAnn = AnnotationUtils.getAnnotation(ann, Validated.class);
//如果直接标注了@Validated,那么直接开启校验。
//如果没有,那么判断参数前是否有Valid起头的注解。
if (validatedAnn != null || ann.annotationType().getSimpleName().startsWith("Valid")) {
Object hints = (validatedAnn != null ? validatedAnn.value() : AnnotationUtils.getValue(ann));
Object[] validationHints = (hints instanceof Object[] ? (Object[]) hints : new Object[] {hints});
//执行校验
binder.validate(validationHints);
break;
}
}
}
看到这里,大家应该能明白为什么这种场景下@Validated、@Valid两个注解可以混用。我们接下来继续看WebDataBinder.validate()实现。
@Override
public void validate(Object target, Errors errors, Object... validationHints) {
if (this.targetValidator != null) {
processConstraintViolations(
//此处调用Hibernate Validator执行真正的校验
this.targetValidator.validate(target, asValidationGroups(validationHints)), errors);
}
}
最终发现底层最终还是调用了Hibernate Validator进行真正的校验处理。
方法级别的参数校验实现原理
上面提到的将参数一个个平铺到方法参数中,然后在每个参数前面声明约束注解的校验方式,就是方法级别的参数校验。
实际上,这种方式可用于任何Spring Bean的方法上,比如Controller/Service等。其底层实现原理就是AOP,具体来说是通过MethodValidationPostProcessor动态注册AOP切面,然后使用MethodValidationInterceptor对切点方法织入增强。
public class MethodValidationPostProcessor extends AbstractBeanFactoryAwareAdvisingPostProcessorimplements InitializingBean {
@Override
public void afterPropertiesSet() {
//为所有`@Validated`标注的Bean创建切面
Pointcut pointcut = new AnnotationMatchingPointcut(this.validatedAnnotationType, true);
//创建Advisor进行增强
this.advisor = new DefaultPointcutAdvisor(pointcut, createMethodValidationAdvice(this.validator));
}
//创建Advice,本质就是一个方法拦截器
protected Advice createMethodValidationAdvice(@Nullable Validator validator) {
return (validator != null ? new MethodValidationInterceptor(validator) : new MethodValidationInterceptor());
}
}
接着看一下MethodValidationInterceptor:
public class MethodValidationInterceptor implements MethodInterceptor {
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
//无需增强的方法,直接跳过
if (isFactoryBeanMetadataMethod(invocation.getMethod())) {
return invocation.proceed();
}
//获取分组信息
Class<?>[] groups = determineValidationGroups(invocation);
ExecutableValidator execVal = this.validator.forExecutables();
Method methodToValidate = invocation.getMethod();
Set<ConstraintViolation<Object>> result;
try {
//方法入参校验,最终还是委托给Hibernate Validator来校验
result = execVal.validateParameters(
invocation.getThis(), methodToValidate, invocation.getArguments(), groups);
}
catch (IllegalArgumentException ex) {
...
}
//有异常直接抛出
if (!result.isEmpty()) {
throw new ConstraintViolationException(result);
}
//真正的方法调用
Object returnValue = invocation.proceed();
//对返回值做校验,最终还是委托给Hibernate Validator来校验
result = execVal.validateReturnValue(invocation.getThis(), methodToValidate, returnValue, groups);
//有异常直接抛出
if (!result.isEmpty()) {
throw new ConstraintViolationException(result);
}
return returnValue;
}
}
实际上,不管是requestBody参数校验还是方法级别的校验,最终都是调用Hibernate Validator执行校验,Spring Validation只是做了一层封装。
各种检查注解示意
空检查
@Null 验证对象是否为null
@NotNull 验证对象是否不为null, 无法查检长度为0的字符串
@NotBlank 检查约束字符串是不是Null还有被Trim的长度是否大于0,只对字符串,且会去掉前后空格.
@NotEmpty 检查约束元素是否为NULL或者是EMPTY. 验证注解的元素值不为null且不为空(字符串长度不为0、集合大小不为0)
Booelan检查
@AssertTrue 验证 Boolean 对象是否为 true
@AssertFalse 验证 Boolean 对象是否为 false
长度检查
@Size(min=, max=) 验证对象(Array,Collection,Map,String)长度是否在给定的范围之内
@Length(min=, max=) Validates that the annotated string is between min and max included.
日期检查
@Past 验证 Date 和 Calendar 对象是否在当前时间之前
@Future 验证 Date 和 Calendar 对象是否在当前时间之后
@Pattern 验证 String 对象是否符合正则表达式的规则 数值检查,建议使用在Stirng,Integer类型,不建议使用在int类型上,因为表单值为“”时无法转换为int,但可以转换为Stirng为"",Integer为null
@Min 验证 Number 和 String 对象是否大等于指定的值
@Max 验证 Number 和 String 对象是否小等于指定的值
@DecimalMax 被标注的值必须不大于约束中指定的最大值. 这个约束的参数是一个通过BigDecimal定义的最大值的字符串表示.小数存在精度
@DecimalMin 被标注的值必须不小于约束中指定的最小值. 这个约束的参数是一个通过BigDecimal定义的最小值的字符串表示.小数存在精度
@Digits 验证 Number 和 String 的构成是否合法 @Digits(integer=,fraction=) 验证字符串是否是符合指定格式的数字,interger指定整数精度,fraction指定小数精度。
@Range(min=, max=) 检查数字是否介于min和max之间.
@Range(min=10000,max=50000,message="range.bean.wage")
private BigDecimal wage;
@Valid 递归的对关联对象进行校验, 如果关联对象是个集合或者数组,那么对其中的元素进行递归校验,如果是一个map,则对其中的值部分进行校验.(是否进行递归验证)
@CreditCardNumber信用卡验证
@Email 验证是否是邮件地址,如果为null,不进行验证,算通过验证。
@ScriptAssert(lang= ,script=, alias=)
@URL(protocol=,host=, port=,regexp=, flags=)
最后再附上一个demo
- 被校验的类 User
import lombok.Data;
import javax.validation.constraints.Email;
import javax.validation.constraints.NotNull;
import javax.validation.constraints.Size;
@Data
public class User {
@NotNull(message = "主键不能为空", groups = {CheckGroup1.class})
private String id;
@Email(message = "邮箱格式不正确")
private String email;
@Size(min = 4, max = 16, message = "昵称长度为4~16个字符之间", groups = {CheckGroup1.class})
private String nickName;
@NotNull(message = "密码不能为空")
@Size(min = 8, max = 24, message = "密码长度为8~24个字符之间")
private String pwd;
}
- 校验结果实体ValidationResult
import lombok.Data;
import lombok.ToString;
import java.text.MessageFormat;
import java.util.Map;
/**
* @Description 实体校验结果
*/
@Data
@ToString
public class ValidationResult {
/**
* 是否有异常
*/
private boolean hasErrors;
/**
* 异常消息记录
*/
private Map<String, String> errorMsg;
/**
* 获取异常消息组装
*
* @return
*/
public String getMessage() {
if (errorMsg == null || errorMsg.isEmpty()) {
return "";
}
StringBuilder message = new StringBuilder();
errorMsg.forEach((key, value) -> {
message.append(MessageFormat.format("{0}:{1} \r\n", key, value));
});
return message.toString();
}
}
- 校验Util类
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import org.apache.commons.collections4.CollectionUtils;
import org.hibernate.validator.HibernateValidator;
import javax.validation.*;
import javax.validation.groups.Default;
/**
*
*/
public class ValidateUtils {
private ValidateUtils() {
}
// 线程安全的,直接构建也可以,这里使用静态代码块一样的效果
private static Validator validator;
static {
ValidatorFactory factory = Validation.buildDefaultValidatorFactory();
validator = factory.getValidator();
}
public static <T> void validate(T t) {
Set<ConstraintViolation<T>> constraintViolations = validator.validate(t);
if (constraintViolations.size() > 0) {
StringBuilder validateError = new StringBuilder();
for (ConstraintViolation<T> constraintViolation : constraintViolations) {
validateError.append(constraintViolation.getMessage()).append(";");
}
throw new ValidationException(validateError.toString());
}
}
public static <T> void validate(T t, Class clazz) {
Set<ConstraintViolation<T>> constraintViolations = validator.validate(t, clazz);
if (constraintViolations.size() > 0) {
StringBuilder validateError = new StringBuilder();
for (ConstraintViolation<T> constraintViolation : constraintViolations) {
validateError.append(constraintViolation.getMessage()).append(";");
}
throw new ValidationException(validateError.toString());
}
}
public static <T> void validate1(T t) {
Validator validator = Validation.byProvider(HibernateValidator.class).configure().failFast(false) // 为true,则有一个错误就结束校验
.buildValidatorFactory().getValidator();
Set<ConstraintViolation<T>> constraintViolations = validator.validate(t);
StringBuilder validateError = new StringBuilder();
for (ConstraintViolation<T> constraintViolation : constraintViolations) {
validateError.append(constraintViolation.getMessage()).append(";");
}
throw new ValidationException(validateError.toString());
}
// 自定义校验结果返回
/**
* 校验实体,返回实体所有属性的校验结果
*
* @param obj
* @param <T>
* @return
*/
public static <T> ValidationResult validateEntity(T obj) {
// 解析校验结果
Set<ConstraintViolation<T>> validateSet = validator.validate(obj, Default.class);
return buildValidationResult(validateSet);
}
/**
* 校验指定实体的指定属性是否存在异常
*
* @param obj
* @param propertyName
* @param <T>
* @return
*/
public static <T> ValidationResult validateProperty(T obj, String propertyName) {
Set<ConstraintViolation<T>> validateSet = validator.validateProperty(obj, propertyName, Default.class);
return buildValidationResult(validateSet);
}
/**
* 将异常结果封装返回
*
* @param validateSet
* @param <T>
* @return
*/
private static <T> ValidationResult buildValidationResult(Set<ConstraintViolation<T>> validateSet) {
ValidationResult validationResult = new ValidationResult();
if (!CollectionUtils.isEmpty(validateSet)) {
validationResult.setHasErrors(true);
Map<String, String> errorMsgMap = new HashMap<>();
for (ConstraintViolation<T> constraintViolation : validateSet) {
errorMsgMap.put(constraintViolation.getPropertyPath().toString(), constraintViolation.getMessage());
}
validationResult.setErrorMsg(errorMsgMap);
}
return validationResult;
}
public static <T> ValidationResult validateEntity1(T obj) {
ValidationResult result = new ValidationResult();
Set<ConstraintViolation<T>> set = validator.validate(obj, Default.class);
if (!CollectionUtils.isEmpty(set)) {
result.setHasErrors(true);
Map<String, String> errorMsg = new HashMap<String, String>();
for (ConstraintViolation<T> cv : set) {
errorMsg.put(cv.getPropertyPath().toString(), cv.getMessage());
}
result.setErrorMsg(errorMsg);
}
return result;
}
public static <T> ValidationResult validateEntity1(T obj, Class clazz) {
ValidationResult result = new ValidationResult();
Set<ConstraintViolation<T>> set = validator.validate(obj, clazz);
if (!CollectionUtils.isEmpty(set)) {
result.setHasErrors(true);
Map<String, String> errorMsg = new HashMap<String, String>();
for (ConstraintViolation<T> cv : set) {
errorMsg.put(cv.getPropertyPath().toString(), cv.getMessage());
}
result.setErrorMsg(errorMsg);
}
return result;
}
public static <T> ValidationResult validateProperty1(T obj, String propertyName) {
ValidationResult result = new ValidationResult();
Set<ConstraintViolation<T>> set = validator.validateProperty(obj, propertyName, Default.class);
if (!CollectionUtils.isEmpty(set)) {
result.setHasErrors(true);
Map<String, String> errorMsg = new HashMap<String, String>();
for (ConstraintViolation<T> cv : set) {
errorMsg.put(propertyName, cv.getMessage());
}
result.setErrorMsg(errorMsg);
}
return result;
}
}
- 分组校验的交验组定义
public interface CheckGroup1 {
}
- 测试客户端
import java.util.Map;
public class Client {
public static void main(String[] args) {
User user = new User();
ValidationResult validRes = ValidateUtils.validateEntity1(user, CheckGroup1.class);
if (validRes.isHasErrors()) {
for (Map.Entry<String, String> entry : validRes.getErrorMsg().entrySet()) {
System.out.println(entry.getValue());
}
}
}
}
2.1.14 - ZIPUtils
package cn.anzhongwei.lean.demo.zip;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class ZipUtilFileInfo {
private String name;
private String url;
private Boolean Local;
}
package cn.anzhongwei.lean.demo.zip;
import org.apache.commons.lang.ArrayUtils;
import org.apache.pdfbox.io.IOUtils;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;
import java.util.zip.*;
public class ZipUtils2 {
private static final int BUFFER = 256;
public static void main(String[] args) throws IOException {
String hallFilePath = "d:/" + "qwe";
compress(Paths.get(hallFilePath).toString(), hallFilePath + ".zip");
List<ZipUtilFileInfo> downFileInfos = new ArrayList<>();
ZipUtilFileInfo d1 = new ZipUtilFileInfo( "价格导入模板.xlsx", "http://网络地址", false);
ZipUtilFileInfo d2 = new ZipUtilFileInfo( "订单导入_仓储.xlsx", "http://网络地址", false);
downFileInfos.add(d1);
downFileInfos.add(d2);
File zipfile1 = gerenatorZIPFileFromUrl(downFileInfos, "t1.zip");
File zipfile2 = gerenatorZIPFileFromUrl(downFileInfos, "t2.zip");
File zipfile3 = gerenatorZIPFileFromUrl(downFileInfos, "t3.zip");
List<ZipUtilFileInfo> downFileInfos2 = new ArrayList<>();
ZipUtilFileInfo dd1 = new ZipUtilFileInfo( zipfile1.getName(), zipfile1.getAbsolutePath(), true);
ZipUtilFileInfo dd2 = new ZipUtilFileInfo( zipfile2.getName(), zipfile1.getAbsolutePath(), true);
ZipUtilFileInfo dd3 = new ZipUtilFileInfo( zipfile3.getName(), zipfile1.getAbsolutePath(), true);
downFileInfos2.add(dd1);
downFileInfos2.add(dd2);
downFileInfos2.add(dd3);
File ff2 = gerenatorZIPFileFromUrl(downFileInfos2, "tt1.zip");
System.out.println(zipfile1.getAbsolutePath());
InputStream inputStream = new FileInputStream(ff2);
File tempFile = new File("C:\\testFile\\");
if (!tempFile.exists()) {
tempFile.mkdirs();
}
OutputStream os = new FileOutputStream(tempFile.getPath() + File.separator + "shishi.zip");
byte[] bs = new byte[1024];
int len;
while ((len = inputStream.read(bs)) != -1) {
os.write(bs, 0, len);
}
}
//文件或目录打包成zip
public static void compress(String fromPath, String toPath) throws IOException {
File fromFile = new File(fromPath);
File toFile = new File(toPath);
if (!fromFile.exists()) {
throw new RuntimeException(fromPath + "不存在!");
}
try (FileOutputStream outputStream = new FileOutputStream(toFile);
CheckedOutputStream checkedOutputStream = new CheckedOutputStream(outputStream, new CRC32());
ZipOutputStream zipOutputStream = new ZipOutputStream(checkedOutputStream)) {
String baseDir = "";
compress(fromFile, zipOutputStream, baseDir);
}
}
private static void compress(File file, ZipOutputStream zipOut, String baseDir) throws IOException {
if (file.isDirectory()) {
compressDirectory(file, zipOut, baseDir);
} else {
compressFile(file, zipOut, baseDir);
}
}
private static void compressFile(File file, ZipOutputStream zipOut, String baseDir) throws IOException {
if (!file.exists()) {
return;
}
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream(file))) {
ZipEntry entry = new ZipEntry(baseDir + file.getName());
zipOut.putNextEntry(entry);
int count;
byte[] data = new byte[BUFFER];
while ((count = bis.read(data, 0, BUFFER)) != -1) {
zipOut.write(data, 0, count);
}
}
}
private static void compressDirectory(File dir, ZipOutputStream zipOut, String baseDir) throws IOException {
File[] files = dir.listFiles();
if (files != null && ArrayUtils.isNotEmpty(files)) {
for (File file : files) {
compress(file, zipOut, baseDir + dir.getName() + File.separator);
}
}
}
private static File gerenatorZIPFileFromUrl(List<ZipUtilFileInfo> downFileInfos, String zipFileName) {
try {
File zipFile = File.createTempFile(zipFileName, ".zip");
FileOutputStream f = new FileOutputStream(zipFile);
CheckedOutputStream csum = new CheckedOutputStream(f, new Adler32());
ZipOutputStream zos = new ZipOutputStream(csum);
for (ZipUtilFileInfo downFileInfo : downFileInfos) {
InputStream inputStream;
if (Objects.isNull(downFileInfo.getLocal())) {
throw new RuntimeException("url类型未指定是否本地,请检查代码");
}
if (downFileInfo.getLocal()) {
inputStream = new FileInputStream(downFileInfo.getUrl());
} else {
inputStream = getStreamByUrl(downFileInfo.getUrl());
}
zos.putNextEntry(new ZipEntry(downFileInfo.getName()));
int bytesRead = 0;
// 向压缩文件中输出数据
while((bytesRead = inputStream.read()) != -1){
zos.write(bytesRead);
}
inputStream.close();
zos.closeEntry();
}
zos.close();
return zipFile;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public static InputStream getStreamByUrl(String strUrl){
HttpURLConnection conn = null;
try {
URL url = new URL(strUrl);
conn = (HttpURLConnection)url.openConnection();
conn.setRequestMethod("GET");
conn.setConnectTimeout(20 * 1000);
final ByteArrayOutputStream output = new ByteArrayOutputStream();
IOUtils.copy(conn.getInputStream(),output);
return new ByteArrayInputStream(output.toByteArray());
} catch (Exception e) {
e.printStackTrace();
}finally {
try{
if (conn != null) {
conn.disconnect();
}
}catch (Exception e){
e.printStackTrace();
}
}
return null;
}
}
2.1.15 - 遍历List
package cn.anzhongwei.lean.demo.list.arraylist;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Demo {
public static void main(String[] args) {
Object obj = new Object();
List<Object> list = new ArrayList<>();
int objCount = 1000;
for (int i = 0; i < objCount; i++) {
list.add(obj);
}
int testTimes = 5;
for (int i = 0; i < testTimes; i++) {
testFor(list);
testForEnhanced(list);
testForEach(list);
testIterator(list);
System.out.println("\n");
}
System.out.println("---------------------------------------------------------\n");
List<Object> list2 = new ArrayList<>();
for (int i = 0; i < objCount; i++) {
list2.add(obj);
}
for (int i = 0; i < testTimes; i++) {
testFor(list2);
testForEnhanced(list2);
testForEach(list2);
testIterator(list2);
System.out.println();
}
}
private static void testFor(List<Object> list) {
long startTime = 0L;
long endTime = 0L;
startTime = System.nanoTime();
for (int i = 0; i < list.size(); i++) {
Object o = list.get(i);
}
endTime = System.nanoTime();
System.out.println("for所用时间(ns) :" + (endTime - startTime));
}
private static void testForEnhanced(List<Object> list) {
long startTime = 0L;
long endTime = 0L;
startTime = System.nanoTime();
for (Object o : list) {
Object value = o;
}
endTime = System.nanoTime();
System.out.println("增强for所用时间(ns) :" + (endTime - startTime));
}
private static void testForEach(List<Object> list) {
long startTime = 0L;
long endTime = 0L;
startTime = System.nanoTime();
list.forEach(o->{Object obj = o;});
endTime = System.nanoTime();
System.out.println("forEach所用时间(ns) :" + (endTime - startTime));
}
private static void testIterator(List<Object> list) {
long startTime = 0L;
long endTime = 0L;
startTime = System.nanoTime();
Iterator<Object> iterator = list.iterator();
while (iterator.hasNext()) {
Object o = iterator.next();
}
endTime = System.nanoTime();
System.out.println("iterator所用时间(ns) :" + (endTime - startTime));
}
}
2.1.16 - 遍历Map
package cn.anzhongwei.lean.demo.map;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class MapTest {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
//第一种:普遍使用,二次取值
System.out.println("通过Map.keySet遍历key和value:");
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
//第二种
System.out.println("通过Map.entrySet使用iterator遍历key和value:");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第三种:推荐,尤其是容量大时
System.out.println("通过Map.entrySet遍历key和value");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第四种
System.out.println("通过Map.values()遍历所有的value,但不能遍历key");
for (String v : map.values()) {
System.out.println("value= " + v);
}
}
}
2.1.17 - 从mybatis的sql日志自动填充sql占位符
应该由bug,没详细测试
import javax.swing.*;
import java.awt.*;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 从mybatis的sql日志自动填充sql占位符
*/
public class SqlReplaceUtil extends JFrame {
private static final Pattern HUMP_PATTERN = Pattern.compile("\\?");
JPanel jp;
JButton b1;
JTextArea sqlTextField;
JTextArea paramTextField;
JTextArea resultTextField;
JLabel lb3;
JLabel lb4;
SqlReplaceUtil() {
jp = new JPanel();
b1 = new JButton("替换");
sqlTextField = new JTextArea("输入待处理的SQL,比如:insert into test (id,name,age) values (?,?,?)",10,90);
paramTextField = new JTextArea("输入待处理参数,比如:100(Integer),zhangsan(String),null",10,90);
resultTextField = new JTextArea(10,90);
lb3 = new JLabel("结果为:");
lb4 = new JLabel("");
b1.addActionListener(new ActionListener() {//响应按钮的事件
public void actionPerformed(ActionEvent e) {
try {
lb4.setText("");
String sql = sqlTextField.getText();
String param = paramTextField.getText();
resultTextField.setText(replaceSql(sql, param));
} catch (Exception ex) {
lb4.setText(ex.getMessage());
}
}
});
jp.add(sqlTextField);
jp.add(paramTextField);
jp.add(b1);
jp.add(resultTextField);
jp.add(lb4);
add(jp);
setDefaultCloseOperation(WindowConstants.EXIT_ON_CLOSE);
setLocationRelativeTo(null);
setLocation(600, 200);
setVisible(true);
pack();
setSize(1050, 700);
setLocationRelativeTo(null);
setVisible(true);
setResizable(false);
}
public static void main(String[] args) {
SqlReplaceUtil e = new SqlReplaceUtil();
Container contentPane = e.getContentPane();
contentPane.setLayout(new BoxLayout(contentPane, BoxLayout.Y_AXIS));
}
private String replaceSql(String sql, String param) {
String[] split = param.split(",");
//校验数量
int paramCount = split.length;
int matcherCount = 0;
Matcher matcher = HUMP_PATTERN.matcher(sql);
while (matcher.find()) {
matcherCount++;
}
if (paramCount != matcherCount) {
throw new RuntimeException("待替换参数和参数数量不一致");
}
//处理参数
for (int i = 0; i < split.length; i++) {
split[i] = split[i].trim();
int index = split[i].lastIndexOf('(');
if (split[i].equals("null")||index<0) {
continue;
}
split[i] = "'" + split[i].substring(0, index) + "'";
}
StringBuffer sb = new StringBuffer();
Matcher matcher2 = HUMP_PATTERN.matcher(sql);
int index = 0;
while (matcher2.find()) {
matcher2.appendReplacement(sb, split[index]);
index++;
}
matcher2.appendTail(sb);
return sb.toString();
}
}
2.1.18 - 代理模式实现
2.1.18.1 - ByteBuddy动态代理
java17以后替换cglib方式的动态代理。他和cglib实现动态代理的优势是不用定义接口也不需要去实现接口,对现有的代码扩展更友好。
- pom文件添加依赖
<dependency>
<groupId>net.bytebuddy</groupId>
<artifactId>byte-buddy</artifactId>
<!-- 我用的最新的, 一般1.14.0以上都没问题 -->
<version>1.15.1</version>
</dependency>
- 先创建要被代理的类
public class TargetClass {
public void performAction() {
System.out.println("原始方法: performAction");
}
public String sayHello(String name) {
return "Hello, " + name;
}
}
- 创建拦截器
import net.bytebuddy.implementation.bind.annotation.*;
import java.lang.reflect.Method;
import java.util.concurrent.Callable;
/**
* 通用方法拦截器
*/
public class GenericInterceptor {
@RuntimeType
public static Object intercept(@Origin Method method,
@AllArguments Object[] args,
@This Object obj,
@SuperCall Callable<?> callable) throws Exception {
// 获取动态添加的字段值
String proxyField = (String) obj.getClass().getField("proxyField").get(obj);
System.out.println("[拦截] proxyField 值: " + proxyField);
// 修改字段值
System.out.println("[通用拦截] 修改字段proxyField值: Modified by interceptor" );
obj.getClass().getField("proxyField").set(obj, "Modified by interceptor");
System.out.println("[通用拦截] 方法开始: " + method.getName());
Object result = callable.call(); // 执行原始方法
System.out.println("[通用拦截] 方法结束: " + method.getName());
return result;
}
}
- 代理工具
import net.bytebuddy.ByteBuddy;
import net.bytebuddy.description.modifier.Visibility;
import net.bytebuddy.implementation.MethodDelegation;
import net.bytebuddy.matcher.ElementMatchers;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationTargetException;
/**
* 通用 Byte Buddy 动态代理工具类
*/
public class ByteBuddyProxy {
/**
* 创建一个代理对象
*
* @param targetClass 目标类类型
* @param interceptor 拦截器类(需使用 Byte Buddy 注解定义逻辑)
* @param <T> 泛型
* @return 代理实例
* @throws NoSuchMethodException
* @throws IllegalAccessException
* @throws InvocationTargetException
* @throws InstantiationException
*/
public static <T> T createProxy(Class<T> targetClass, Class<?> interceptor) throws Exception {
Class<?> dynamicType = new ByteBuddy()
.subclass(targetClass)
// ElementMatchers.any() 拦截所有方法
.method(ElementMatchers.any())
// MethodDelegation.to(interceptor) 拦截器类 方法增强
.intercept(MethodDelegation.to(interceptor))
// 动态的添加字段。这里可以放到参数里面,然后由调用方传递进来要添加什么参数
.defineField("proxyField", String.class, Visibility.PUBLIC) // 可选:添加字段
.defineField("abc", String.class, Visibility.PUBLIC) // 可选:添加字段
.make()
.load(targetClass.getClassLoader())
.getLoaded();
// 支持构造实例
// .getDeclaredConstructor()
// .newInstance();
Constructor<?> constructor = dynamicType.getDeclaredConstructor();
Object instance = constructor.newInstance();
// 现在就可以 调用方法触发拦截逻辑 了
// ((TargetClass) instance).performAction();
// 设置字段值
System.out.println("[通用拦截] 设置字段proxyField值: Hello Dynamic Field" );
dynamicType.getField("proxyField").set(instance, "Hello Dynamic Field");
System.out.println("[通用拦截] 设置字段abc值: def" );
dynamicType.getField("abc").set(instance, "def");
return (T) instance;
}
}
- 一个测试类用来测试动态代理
public class ByteBuddyGenericExample {
public static void main(String[] args) throws Exception {
// 创建代理对象
TargetClass proxyInstance = ByteBuddyProxy
.createProxy(TargetClass.class, GenericInterceptor.class);
// 调用方法
proxyInstance.performAction();
String result = proxyInstance.sayHello("World");
System.out.println("返回值: " + result);
String abc = (String) proxyInstance.getClass().getField("abc").get(proxyInstance);
System.out.println("last在打印一遍proxyField: " + abc);
}
}
2.1.18.2 - CGLIB动态代理
CGLIB基于ASM实现。提供比反射更为强大的动态特性。使用CGLIB可以非常方便的实现的动态代理。但是由于jdk17+由于java.base模块未向未命名模块开放java.lang包,所以CGLIB无法在jdk17+中运行。在java17+后 需要使用 Byte Buddy,这里cglib就没法测试了,
maven项目需要添加依赖
<!-- https://mvnrepository.com/artifact/cglib/cglib -->
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.3.0</version>
</dependency>
1 0.1 CGLIB包结构
-
*net.sf.cglib.core *底层字节码处理类。
-
*net.sf.cglib.transform *该包中的类用于class文件运行时转换或编译时转换。
-
*net.sf.cglib.proxy *该包中的类用于创建代理和方法拦截。
-
*net.sf.cglib.reflect *该包中的类用于快速反射,并提供了C#风格的委托。
-
*net.sf.cglib.util *集合排序工具类。
-
*net.sf.cglib.beans *JavaBean工具类。
1 使用CGLIB实现动态代理
2 1.1 CGLIB代理相关的类
- net.sf.cglib.proxy.Enhancer 主要的增强类。
- net.sf.cglib.proxy.MethodInterceptor 主要的方法拦截类,它是Callback接口的子接口,需要用户实现。
- net.sf.cglib.proxy.MethodProxy JDK的java.lang.reflect.Method类的代理类,可以方便的实现对源对象方法的调用。
cglib是通过动态的生成一个子类去覆盖所要代理类的非final方法,并设置好callback,则原有类的每个方法调用就会转变成调用用户定义的拦截方法(interceptors)。
CGLIB代理相关的常用API如下图所示:
net.sf.cglib.proxy.Callback接口在CGLIB包中是一个重要的接口,所有被net.sf.cglib.proxy.Enhancer类调用的回调(callback)接口都要继承这个接口。
net.sf.cglib.proxy.MethodInterceptor能够满足任何的拦截(interception )需要。对有些情况下可能过度。为了简化和提高性能,CGLIB包提供了一些专门的回调(callback)类型:
- net.sf.cglib.proxy.FixedValue 为提高性能,FixedValue回调对强制某一特别方法返回固定值是有用的。
- net.sf.cglib.proxy.NoOp NoOp回调把对方法调用直接委派到这个方法在父类中的实现。
- net.sf.cglib.proxy.LazyLoader 当实际的对象需要延迟装载时,可以使用LazyLoader回调。一旦实际对象被装载,它将被每一个调用代理对象的方法使用。
- net.sf.cglib.proxy.Dispatcher Dispathcer回调和LazyLoader回调有相同的特点,不同的是,当代理方法被调用时,装载对象的方法也总要被调用。
- net.sf.cglib.proxy.ProxyRefDispatcher ProxyRefDispatcher回调和Dispatcher一样,不同的是,它可以把代理对象作为装载对象方法的一个参数传递。
3 1.2 CGLIB动态代理的基本原理
CGLIB动态代理的原理就是用Enhancer生成一个原有类的子类,并且设置好callback到proxy, 则原有类的每个方法调用都会转为调用实现了MethodInterceptor接口的proxy的intercept() 函数,如图
在intercept()函数里,除执行代理类的原因方法,在原有方法前后加入其他需要实现的过程,改变原有方法的参数值,即可以实现对原有类的代理了。这似于AOP中的around advice。
4 1.3 使用MethodInterceptor接口实现方法回调
当对代理中所有方法的调用时,都会转向MethodInterceptor类型的拦截(intercept)方法,在拦截方法中再调用底层对象相应的方法。下面我们举个例子,假设你想对目标对象的所有方法调用进行权限的检查,如果没有经过授权,就抛出一个运行时的异常。
net.sf.cglib.proxy.MethodInterceptor接口是最通用的回调(callback)类型,它经常被基于代理的AOP用 来实现拦截(intercept)方法的调用。
MethodInterceptor接口只定义了一个方法:
public Object intercept(Object object, java.lang.reflect.Method method, Object[] args, MethodProxy proxy) throws Throwable;
参数Object object是被代理对象,不会出现死循环的问题。
参数java.lang.reflect.Method method是java.lang.reflect.Method类型的被拦截方法。
参数Object[] args是被被拦截方法的参数。
参数MethodProxy proxy是CGLIB提供的MethodProxy 类型的被拦截方法。
注意:
1、若原方法的参数存在基本类型,则对于第三个参数Object[] args会被转化成类的类型。如原方法的存在一个参数为int,则在intercept方法中,对应的会存在一个Integer类型的参数。
2、若原方法为final方法,则MethodInterceptor接口无法拦截该方法。
4.1 1.3.1 实现MethodInterceptor接口
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
class MethodInterceptorImpl implements MethodInterceptor {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("Before invoke " + method);
Object result = proxy.invokeSuper(obj, args);
System.out.println("After invoke" + method);
return result;
}
}
Object result=proxy.invokeSuper(o,args); 表示调用原始类的被拦截到的方法。这个方法的前后添加需要的过程。在这个方法中,我们可以在调用原方法之前或之后注入自己的代码。
由于性能的原因,对原始方法的调用使用CGLIB的net.sf.cglib.proxy.MethodProxy对象,而不是反射中一般使用java.lang.reflect.Method对象。
5 1.4 使用CGLIB代理最核心类Enhancer生成代理对象
net.sf.cglib.proxy.Enhancer中有几个常用的方法:
- void setSuperclass(java.lang.Class superclass) 设置产生的代理对象的父类。
- void setCallback(Callback callback) 设置CallBack接口的实例。
- void setCallbacks(Callback[] callbacks) 设置多个CallBack接口的实例。
- void setCallbackFilter(CallbackFilter filter) 设置方法回调过滤器。
- Object create() 使用默认无参数的构造函数创建目标对象。
- Object create(Class[], Object[]) 使用有参数的构造函数创建目标对象。参数Class[] 定义了参数的类型,第二个Object[]是参数的值。
注意:在参数中,基本类型应被转化成类的类型。
基本代码:
public Object createProxy(Class targetClass) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(targetClass);
enhancer.setCallback(new MethodInterceptorImpl ());
return enhancer.create();
}
createProxy方法返回值是targetClass的一个实例的代理。
6 1.5 使用CGLIB继进行动态代理示例
例1:使用CGLIB生成代理的基本使用。
import java.lang.reflect.Method;
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
public class TestMain {
public static void main(String[] args) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(Cglib.class);
enhancer.setCallback(new HelloProxy());
Cglib cglibProxy = (Cglib)enhancer.create();
cglibProxy.cglib();
}
}
class Cglib{
public void cglib(){
System.out.println("CGLIB");
}
}
class HelloProxy implements MethodInterceptor{
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("Hello");
Object object = proxy.invokeSuper(obj, args);
System.out.println("Powerful!");
return object;
}
}
输出内容:
Hello
CGLIB
Powerful!
例2:使用CGLIB创建一个Dao工厂,并展示一些基本特性。
public interface Dao {
void add(Object o);
void add(int i);
void add(String s);
}
public class DaoImpl implements Dao {
@Override
public void add(Object o) {
System.out.println("add(Object o)");
}
@Override
public void add(int i) {
System.out.println("add(int i)");
}
public final void add(String s) {
System.out.println("add(String s)");
}
}
public class Proxy implements MethodInterceptor {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("拦截前...");
// 输出参数类型
for (Object arg : args) {
System.out.print(arg.getClass() + ";");
}
Object result = proxy.invokeSuper(obj, args);
System.out.println("拦截后...");
return result;
}
}
public class DaoFactory {
public static Dao create() {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(DaoImpl.class);
enhancer.setCallback(new Proxy());
Dao dao = (Dao) enhancer.create();
return dao;
}
}
public class TestMain {
public static void main(String[] args) {
Dao dao = DaoFactory.create();
dao.add(new Object());
dao.add(1);
dao.add("1");
}
}
输出内容:
拦截前...
class java.lang.Object;add(Object o)
拦截后...
拦截前...
class java.lang.Integer;add(int i)
拦截后...
add(String s)
2 回调过滤器CallbackFilter
net.sf.cglib.proxy.CallbackFilter有选择的对一些方法使用回调。
CallbackFilter可以实现不同的方法使用不同的回调方法。所以CallbackFilter称为"回调选择器"更合适一些。
CallbackFilter中的accept方法,根据不同的method返回不同的值i,这个值是在callbacks中callback对象的序号,就是调用了callbacks[i]。
import java.lang.reflect.Method;
import net.sf.cglib.proxy.Callback;
import net.sf.cglib.proxy.CallbackFilter;
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
import net.sf.cglib.proxy.NoOp;
public class CallbackFilterDemo {
public static void main(String[] args) {
// 回调实例数组
Callback[] callbacks = new Callback[]{new MethodInterceptorImpl(), NoOp.INSTANCE};
// 使用enhancer,设置相关参数。
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(User.class);
enhancer.setCallbacks(callbacks);
enhancer.setCallbackFilter(new CallbackFilterImpl());
// 产生代理对象
User proxyUser = (User) enhancer.create();
proxyUser.pay(); // 买
proxyUser.eat(); // 吃
}
}
/**
* 回调过滤器类。
*/
public class CallbackFilterImpl implements CallbackFilter {
@Override
public int accept(Method method) {
String methodName = method.getName();
if ("eat".equals(methodName)) {
return 1; // eat()方法使用callbacks\[1\]对象拦截。
} else if ("pay".equals(methodName)) {
return 0; // pay()方法使用callbacks\[0\]对象拦截。
}
return 0;
}
}
/**
* 自定义回调类。
*/
public class MethodInterceptorImpl implements MethodInterceptor {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("Before invoke " + method);
Object result = proxy.invokeSuper(obj, args); // 原方法调用。
System.out.println("After invoke" + method);
return result;
}
}
class User {
public void pay() {
System.out.println("买东西");
}
public void eat() {
System.out.println("吃东西");
}
}
输出结果:
Before invoke public void sjq.cglib.filter.User.pay()
pay()
After invokepublic void sjq.cglib.filter.User.pay()
eat()
3 CGLIB对Mixin的支持
CGLIB的代理包net.sf.cglib.proxy.Mixin类提供对Minix编程的支持。Minix允许多个对象绑定到一个单个的大对象上。在代理中对方法的调用委托到下面相应的对象中。 这是一种将多个接口混合在一起的方式 , 实现了多个接口。
Minix是一种多继承的替代方案, 很大程度上解决了多继承的很多问题 , 实现和理解起来都比较容易。
import net.sf.cglib.proxy.Mixin;
public class MixinDemo {
public static void main(String[] args) {
//接口数组
Class<?>[] interfaces = new Class[] { MyInterfaceA.class, MyInterfaceB.class };
//实例对象数组
Object[] delegates = new Object[] { new MyInterfaceAImpl(), new MyInterfaceBImpl() };
//Minix组合为o对象。
Object o = Mixin.create(interfaces, delegates);
MyInterfaceA a = (MyInterfaceA) o;
a.methodA();
MyInterfaceB b = (MyInterfaceB) o;
b.methodB();
System.out.println("\\r\\n 输出Mixin对象的结构...");
Class clazz = o.getClass();
Method[] methods = clazz.getDeclaredMethods();
for (int i = 0; i < methods.length; i++) {
System.out.println(methods[i].getName());
}
System.out.println(clazz);
}
}
interface MyInterfaceA {
public void methodA();
}
interface MyInterfaceB {
public void methodB();
}
class MyInterfaceAImpl implements MyInterfaceA {
@Override
public void methodA() {
System.out.println("MyInterfaceAImpl.methodA()");
}
}
class MyInterfaceBImpl implements MyInterfaceB {
@Override
public void methodB() {
System.out.println("MyInterfaceBImpl.methodB()");
}
}
输出结果:
MyInterfaceAImpl.methodA()
MyInterfaceBImpl.methodB()
输出Mixin对象的结构...
methodA
methodB
newInstance
class sjq.cglib.mixin.MyInterfaceA
M ixin ByC GLI B MixinByCGLIB
d1f6261a
4 CGLIB用来对象之间拷贝属性
package sjq.cglib.bean.copy;
import net.sf.cglib.beans.BeanCopier;
public class PropertyCopyDemo {
public static void main(String[] args) {
//两个对象
Other other = new Other("test", "1234");
Myth myth = new Myth();
System.out.println(other);
System.out.println(myth);
//构建BeanCopier,并copy对象的属性值。
BeanCopier copier = BeanCopier.create(Other.class, Myth.class, false);
copier.copy(other, myth, null);
System.out.println(other);
System.out.println(myth);
}
}
class Other {
private String username;
private String password;
private int age;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public Other(String username, String password) {
super();
this.username = username;
this.password = password;
}
@Override
public String toString() {
return "Other: " + username + ", " + password + ", " + age;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
class Myth {
private String username;
private String password;
private String remark;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
@Override
public String toString() {
return "Myth: " + username + ", " + password + ", " + remark;
}
public void setRemark(String remark) {
this.remark = remark;
}
public String getRemark() {
return remark;
}
}
运行结果如下:
Other: test, 1234, 0
Myth: null, null, null
Other: test, 1234, 0
Myth: test, 1234, null
5 使用CGLIB动态生成Bean
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import net.sf.cglib.beans.BeanGenerator;
import net.sf.cglib.beans.BeanMap;
/**
* 动态实体bean
*/
public class CglibBean {
/**
* 实体Object
*/
public Object object = null;
/**
* 属性map
*/
public BeanMap beanMap = null;
public CglibBean() {
super();
}
@SuppressWarnings("unchecked")
public CglibBean(Map<String, Class> propertyMap) {
this.object = generateBean(propertyMap);
this.beanMap = BeanMap.create(this.object);
}
/**
* 给bean属性赋值
* @param property属性名
* @param value值
*/
public void setValue(String property, Object value) {
beanMap.put(property, value);
}
/**
* 通过属性名得到属性值
* @param property属性名
*/
public Object getValue(String property) {
return beanMap.get(property);
}
/**
* 得到该实体bean对象。
*/
public Object getObject() {
return this.object;
}
/**
* 生成Bean
* @param propertyMap
* @return
*/
@SuppressWarnings("unchecked")
private Object generateBean(Map<String, Class> propertyMap) {
BeanGenerator generator = new BeanGenerator();
Set keySet = propertyMap.keySet();
for (Iterator i = keySet.iterator(); i.hasNext();) {
String key = (String) i.next();
generator.addProperty(key, (Class) propertyMap.get(key));
}
return generator.create();
}
}
测试并使用动态Bean
import java.lang.reflect.Method;
import java.util.HashMap;
/**
* Cglib测试类
*/
public class CglibTest {
@SuppressWarnings("unchecked")
public static void main(String[] args) throws ClassNotFoundException {
// 设置类成员属性
HashMap<String, Class> propertyMap = new HashMap<String, Class>();
propertyMap.put("id", Class.forName("java.lang.Integer"));
propertyMap.put("name", Class.forName("java.lang.String"));
propertyMap.put("address", Class.forName("java.lang.String"));
// 生成动态Bean
CglibBean bean = new CglibBean(propertyMap);
// 给Bean设置值
bean.setValue("id", new Integer(123));
bean.setValue("name", "454");
bean.setValue("address", "789");
// 从Bean中获取值,当然了获得值的类型是Object
System.out.println(">>id=" + bean.getValue("id"));
System.out.println(">>name=" + bean.getValue("name"));
System.out.println(">>address=" + bean.getValue("address"));// 获得bean的实体
Object object = bean.getObject();
// 通过反射查看所有方法名
Class clazz = object.getClass();
Method[] methods = clazz.getDeclaredMethods();
for (int i = 0; i < methods.length; i++) {
System.out.println(methods[i].getName());
}
}
}
输出:
\>>id=123
\>>name=454
\>>address=789
setId
getAddress
getName
getId
setName
setAddress
class net.sf.cglib.empty.Object
B eanG ener ator ByC GLI B BeanGeneratorByCGLIB
1d39cfaa
2.1.18.3 - 动态代理
动态代理实现 MethodInterceptor 他可以在使用时再确定要代理什么并且由使用者决定要调用的方法。本质上是使用了反射来实现的
- 定义一个接口
public interface IRegisterService {
void register(String name, String pwd);
}
- 一个接口的实现类
public class RegisterServiceImpl implements IRegisterService {
@Override
public void register(String name, String pwd) {
System.out.println(String.format("【向数据库中插入数据】name:%s,pwd:%s", name, pwd));
}
}
- 一个实现了InvocationHandler接口的类
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
class InsertDataHandler implements InvocationHandler {
// 持有一个被代理类的引用, 但是这个被代理类不是具体的类。而是超类
Object obj;
public Object getProxy(Object obj){
this.obj = obj;
return Proxy.newProxyInstance(obj.getClass().getClassLoader(), obj.getClass().getInterfaces(), this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
doBefore();
// 在这里调用被代理的方法
Object result = method.invoke(obj, args);
doAfter();
return result;
}
private void doBefore() {
System.out.println("[Proxy]一些前置处理");
}
private void doAfter() {
System.out.println("[Proxy]一些后置处理");
}
}
- 测试
public class DynamicProxy {
public static void main(String[] args) {
// 实例化被代理类
IRegisterService iRegisterService = new RegisterServiceImpl();
// 实例化代理类
InsertDataHandler insertDataHandler = new InsertDataHandler();
// 通过Proxy获取代理类
IRegisterService proxy = (IRegisterService)insertDataHandler.getProxy(iRegisterService);
// 执行方法
proxy.register("RyanLee", "123");
}
}
2.1.18.4 - 静态代理
静态代理的代理类持有要代理的目标类的引用。代理关系是确定的。每一个需要代理的类都需要一个代理类来持有他的引用
- 定义一个接口 IRegisterService
public interface IRegisterService {
void register(String name, String pwd);
}
- 创建被代理的类,并实现 接口
public class RegisterServiceImpl implements IRegisterService {
@Override
public void register(String name, String pwd) {
System.out.println(String.format("【向数据库中插入数据】name:%s,pwd:%s", name, pwd));
}
}
- 创建代理类,并实现接口
class RegisterServiceProxy implements IRegisterService {
// 代理类持有被代理类对象的引用
IRegisterService iRegisterService;
public RegisterServiceProxy(IRegisterService iRegisterService) {
this.iRegisterService = iRegisterService;
}
@Override
public void register(String name, String pwd) {
System.out.println("[Proxy]一些前置处理");
//这里调用被代理类的方法,也是静态指定的
iRegisterService.register(name, pwd);
System.out.println("[Proxy]一些后置处理");
}
}
- 测试
public class StaticProxy {
public static void main(String[] args) {
IRegisterService iRegisterService = new RegisterServiceImpl();
IRegisterService proxy = new RegisterServiceProxy(iRegisterService);
proxy.register("RyanLee", "123");
}
}
2.1.19 - 定义一个由builder来构造的实体类
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* description: Java Builder模式练习
* @version v1.0
* @author w
* @date 2021年7月7日上午11:37:49
**/
@AllArgsConstructor
@Data
@NoArgsConstructor
public class User {
private String id ;
private String name ;
private Integer age ;
public static Builder builder(){
return new Builder();
}
public static class Builder{
private String id ;
private String name ;
private Integer age ;
public Builder id(String id) {
this.id = id ;
return this;
}
public Builder name(String name) {
this.name = name ;
return this ;
}
public Builder age(Integer age) {
this.age = age ;
return this;
}
public User build() {
return new User(this);
}
public User build2() {
return new User(this.id , this.name , this.age);
}
}
public User(Builder builder) {
this.id = builder.id;
this.name = builder.name ;
this.age = builder.age;
}
}
public class TestBuilder {
public static void main(String[] args) {
User user = User.builder().id("1").name("xiaoming").age(18).build();
System.out.println(user);
}
}
2.1.20 - 多线程
多线程
2.1.20.1 - 方法一: 继承Thread
import java.io.IOException;
/**
* 方法一: 继承Thread
*/
public class M01ExtentThread {
public static void main(String[] args) throws IOException {
M01ExtentThread test = new M01ExtentThread();
MyThread thread1 = test.new MyThread();
MyThread thread2 = test.new MyThread();
thread1.setName("线程1");
thread2.setName("线程2");
thread1.start();
thread2.start();
System.out.println("主线程输出");
}
class MyThread extends Thread{
@Override
public void run() {
for(int i = 0; i < 3; i++) {
System.out.println(Thread.currentThread().getName()+"线程输出"+i);
}
}
}
}
2.1.20.2 - 方法二实现Runnable接口
/**
* 方法2实现Runnable接口
*/
public class M02ImplentRunnable {
public static void main(String[] args) {
Runnable runnable = new Runnable() {
@Override
public void run() {
for(int i = 0; i < 3; i++) {
System.out.println("runnablex线程输出"+i);
}
}
};
new Thread(runnable).start();
System.out.println("主线程输出");
}
}
2.1.20.3 - 方法三实现Callable接口
package cn.anzhongwei.lean.demo.thread;
import java.util.Random;
import java.util.concurrent.*;
/**
* 和Runnable接口不一样,Callable接口提供了一个call()方法作为线程执行体,call()方法比run()方法功能要强大。
*
* call()方法可以有返回值
*
* call()方法可以声明抛出异常
*
* Java5提供了Future接口来代表Callable接口里call()方法的返回值,并且为Future接口提供了一个实现类FutureTask,这个实现类既实现了Future接口,还实现了Runnable接口。
* 因此可以作为Thread类的target。在Future接口里定义了几个公共方法来控制它关联的Callable任务。
* public interface Future<V> {
* //视图取消该Future里面关联的Callable任务
* boolean cancel(boolean mayInterruptIfRunning);
* //如果在Callable任务正常完成前被取消,返回True
* boolean isCancelled();
* //若Callable任务完成,返回True
* boolean isDone();
* //返回Callable里call()方法的返回值,调用这个方法会导致程序阻塞,必须等到子线程结束后才会得到返回值
* V get() throws InterruptedException, ExecutionException;
* //返回Callable里call()方法的返回值,最多阻塞timeout时间,经过指定时间没有返回抛出TimeoutException
* V get(long timeout, TimeUnit unit)
* throws InterruptedException, ExecutionException, TimeoutException;
* }
*
* 介绍了相关的概念之后,创建并启动有返回值的线程的步骤如下:
*
* 1】创建Callable接口的实现类,并实现call()方法,然后创建该实现类的实例(从java8开始可以直接使用Lambda表达式创建Callable对象)。
*
* 2】使用FutureTask类来包装Callable对象,该FutureTask对象封装了Callable对象的call()方法的返回值
*
* 3】使用FutureTask对象作为Thread对象的target创建并启动线程(因为FutureTask实现了Runnable接口)
*
* 4】调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
*/
public class M03ImplementCallable01 {
public static void main(String[] args) {
//1. 此处使用的是匿名类方式
// Callable<String> callable = new Callable<String>() {
// public String call() throws Exception {
// for(int i = 0; i < 3; i++) {
// System.out.println("callable线程输出"+i);
// }
// return "返回随机数"+(new Random().nextInt(100));
// }
// };
//2. 使用静态内部类
Callable<String> callable = new InnerStaticCallable();
//3. 使用外部实现类。略
FutureTask<String> future = new FutureTask<String>(callable);
Thread thread = new Thread(future);
thread.start();
try {
String resI = future.get();
System.out.println(resI);
} catch (InterruptedException ie) {
ie.printStackTrace();
} catch (ExecutionException ee) {
ee.printStackTrace();
}
//此种方法可以用, 但是不明确应用场景, 返回资源的值是在new FutureTask中传入的,
//runnable接口实现直接使用Thread的start方法运行就行,传到FutureTask中有啥用
Runnable runnable = new Runnable() {
@Override
public void run() {
for(int i = 0; i < 3; i++) {
System.out.println("Runnable线程输出"+i);
}
}
};
FutureTask<Integer> target = new FutureTask<>(runnable, 12);
Thread thread1 = new Thread(target);
thread1.start();
try {
Integer resI1 = target.get();
System.out.println(resI1);
} catch (InterruptedException ie) {
ie.printStackTrace();
} catch (ExecutionException ee) {
ee.printStackTrace();
}
System.out.println("主线程输出");
}
//也可以使用内部类方式
static class InnerStaticCallable implements Callable<String> {
@Override
public String call() {
for(int i = 0; i < 3; i++) {
System.out.println("callable线程输出"+i);
}
return "返回随机数"+(new Random().nextInt(100));
}
}
}
2.1.20.4 - 方法四Executors框架
import java.util.concurrent.*;
/**
* 1.5后引入的Executor框架的最大优点是把任务的提交和执行解耦。
* 要执行任务的人只需把Task描述清楚,然后提交即可。
* 这个Task是怎么被执行的,被谁执行的,什么时候执行的,提交的人就不用关心了。
* 具体点讲,提交一个Callable对象给ExecutorService(如最常用的线程池ThreadPoolExecutor),将得到一个Future对象,调用Future对象的get方法等待执行结果就好了。
* Executor框架的内部使用了线程池机制,它在java.util.cocurrent 包下,通过该框架来控制线程的启动、执行和关闭,可以简化并发编程的操作。
* 因此,在Java 5之后,通过Executor来启动线程比使用Thread的start方法更好,除了更易管理,效率更好(用线程池实现,节约开销)外,
* 还有关键的一点:有助于避免this逃逸问题——如果我们在构造器中启动一个线程,因为另一个任务可能会在构造器结束之前开始执行,此时可能会访问到初始化了一半的对象用Executor在构造器中。
*
* 关于ExecutorService执行submit和execute的区别
* 1、接收的参数不一样
* 2、submit有返回值,而execute没有
* 3、submit方便Exception处理
* 如果你在你的task里会抛出checked或者unchecked exception,而你又希望外面的调用者能够感知这些exception并做出及时的处理,那么就需要用到submit,通过捕获Future.get抛出的异常。
*/
public class M04ExccutorCallable {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executorService1 = Executors.newSingleThreadExecutor();
ExecutorService executorService2 = Executors.newSingleThreadExecutor();
Runnable runnable = new Runnable(){
@Override
public void run() {
for(int i = 0; i < 3; i++) {
System.out.println("Runnable接口"+i);
}
}
};
//执行Runnable接口,无返回值
executorService1.execute(runnable);
executorService1.shutdown();
//执行Callable接口,有返回值
Callable<String> stringCallable = new Callable(){
@Override
public String call() throws Exception {
for(int i = 0; i < 3; i++) {
System.out.println("Callable接口"+i);
}
return "Hello World";
}
};
Future<String> submit2 = executorService2.submit(stringCallable);
executorService2.shutdown();
//get操作会造成执行线程的阻塞
String submit2Res = submit2.get();
System.out.println(submit2Res);
System.out.println("main Thread output");
}
}
2.1.20.5 - 线程池
import java.io.IOException;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
public class TestThreadPoolExecutor {
/*
corePoolSize:指定了线程池中的线程数量,它的数量决定了添加的任务是开辟新的线程去执行,还是放到workQueue任务队列中去;
当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。
如果调用了线程池的prestartAllCoreThreads方法,线程池会提前创建并启动所有基本线程。
maximumPoolSize:指定了线程池中的最大线程数量,这个参数会根据你使用的workQueue任务队列的类型,决定线程池会开辟的最大线程数量;
如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。
值得注意的是,如果使用了无界的任务队列这个参数就没用了
执行:
1、2任务直接压入1、2线程直接创建并执行,
3任务放入缓冲队列,最大线程数未满,创建新线程执行3任务
*/
public static void main(String[] args) throws InterruptedException, IOException {
int corePoolSize = 2;
int maximumPoolSize = 10;
long keepAliveTime = 10;
TimeUnit unit = TimeUnit.SECONDS;
BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(2);
ThreadFactory threadFactory = new NameTreadFactory();
RejectedExecutionHandler handler = new MyIgnorePolicy();
ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, unit,
workQueue, threadFactory);
executor.prestartAllCoreThreads(); // 预启动所有核心线程
for (int i = 1; i <= 10; i++) {
// Thread.sleep(1);
MyTask task = new MyTask(String.valueOf(i));
executor.execute(task);
System.out.println("当前队列数两"+executor.getQueue().size());
}
System.out.println(executor.getActiveCount());
Thread.sleep(10000);
System.out.println(executor.getActiveCount());
System.in.read(); //阻塞主线程
}
static class NameTreadFactory implements ThreadFactory {
private final AtomicInteger mThreadNum = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
// try {
// Thread.sleep(200);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
Thread t = new Thread(r, "my-thread-" + mThreadNum.getAndIncrement());
System.out.println(t.getName() + " has been created");
return t;
}
}
public static class MyIgnorePolicy implements RejectedExecutionHandler {
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
doLog(r, e);
}
private void doLog(Runnable r, ThreadPoolExecutor e) {
// 可做日志记录等
System.err.println( r.toString() + " rejected");
// System.out.println("completedTaskCount: " + e.getCompletedTaskCount());
}
}
static class MyTask implements Runnable {
private String name;
public MyTask(String name) {
this.name = name;
}
@Override
public void run() {
try {
System.out.println(this.toString() + " is running!");
Thread.sleep(1000); //让任务执行慢点
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public String getName() {
return name;
}
@Override
public String toString() {
return "MyTask [name=" + name + "]";
}
}
}
2.1.20.6 - 线程交替执行的实践
线程交替执行的实践 也就是 1a2b3c4d交替输出的问题
- 只能保证交替执行, 至于先输出1 还是先输出A 谁先抢到o锁谁就输出
public class Syncwaitnotify1 {
public static void main(String[] args) {
final Object o = new Object();
char[] aI = "123456789".toCharArray();
char[] aC = "ABCDEFGHI".toCharArray();
new Thread(()->{
//1. 先拿到o锁
synchronized (o) {
for(char c : aI) {
//2. 执行
System.out.print(c);
try {
o.notify();//唤醒线程队列中得下一个线程, 这里只有两个,就相当于唤醒另一个
o.wait();//让出锁,重新进入等待队列
}catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify();
}
}, "t1").start();
new Thread(()->{
//1. 和上面得Thread强锁
synchronized (o) {
for(char i : aC) {
System.out.print(i);
try {
o.notify();
o.wait();
}catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify();
}
}, "t2").start();
}
}
- 先等待一直等到CountDownLatch计数器为0, 所以这个程序一定先输出A
import java.util.concurrent.CountDownLatch;
public class Syncwaitnotify2 {
/*
CountDownLatch latch = new CountDownLatch(n);
latch.countDown();每执行一次,n-1
*/
private static CountDownLatch latch = new CountDownLatch(1);
public static void main(String[] args) {
final Object o = new Object();
char[] aI = "123456789".toCharArray();
char[] aC = "ABCDEFGHI".toCharArray();
new Thread(()->{
try{
latch.await();
}catch (InterruptedException e) {
e.printStackTrace();
}
//1. 先拿到o锁
synchronized (o) {
for(char c : aI) {
//2. 执行
System.out.print(c);
try {
o.notify();//唤醒线程队列中得下一个线程, 这里只有两个,就相当于唤醒另一个
o.wait();//让出锁,重新进入等待队列
}catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify();
}
}, "t1").start();
new Thread(()->{
//1. 和上面得Thread强锁
synchronized (o) {
for(char i : aC) {
System.out.print(i);
latch.countDown();
try {
o.notify();
o.wait();
}catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify();
}
}, "t2").start();
}
}
- 通过volatile 实现 volatile是原子操作并且线程可见,也可以保证顺序执行
/**
* 如果t1先拿到锁,此时t25 = false 在while中不断得会让出锁
* 等t2拿到锁后, 设置t25=true就可以正常交替执行了
*/
public class Syncwaitnotify3 {
private static volatile boolean t25 = false;
public static void main(String[] args) {
final Object o = new Object();
char[] aI = "123456789".toCharArray();
char[] aC = "ABCDEFGHI".toCharArray();
new Thread(()->{
//1. 如果t1先拿到锁
synchronized (o) {
//2. 此时t25=false
while (!t25) {
try {
//3. 让出线程, 进入等待队列
o.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
for(char c : aI) {
System.out.print(c);
try {
o.notify();//唤醒线程队列中得下一个线程, 这里只有两个,就相当于唤醒另一个
o.wait();//让出锁,重新进入等待队列
}catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify();
}
}, "t1").start();
new Thread(()->{
//4. 此时t2后拿到锁
synchronized (o) {
for(char i : aC) {
System.out.print(i);
t25 = true;
try {
o.notify();
o.wait();
}catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify();
}
}, "t2").start();
}
}
- 指定线程锁,相互唤醒,第一次也使用latch.await(); 保证, 和2差不多
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class LockCondition {
public static void main(String[] args) {
char[] aI = "123456789".toCharArray();
char[] aC = "ABCDEFGHI".toCharArray();
Lock lock = new ReentrantLock();
Condition conditionT1 = lock.newCondition();
Condition conditionT2 = lock.newCondition();
CountDownLatch latch = new CountDownLatch(1);
new Thread(()->{
try {
//1. 启动线程直接进入等待
latch.await();
}catch (InterruptedException e) {
e.printStackTrace();
}
lock.lock();
try {
for(char c : aI) {
System.out.print(c);
conditionT2.signal();
conditionT1.await();
}
conditionT2.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}, "t1").start();
new Thread(()->{
lock.lock();
try {
//2. 线程启动直接进入循环进行输出
for(char c : aC) {
System.out.print(c);
//3. 标记完成
latch.countDown();
//4. 唤醒conditionT1队列
conditionT1.signal();
conditionT2.await();
}
conditionT1.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}, "t2").start();
}
}
- LockSupport的实现
import java.util.concurrent.locks.LockSupport;
public class LockSupport1 {
static Thread t1=null, t2=null;
public static void main(String[] args) {
char[] aI = "123456789".toCharArray();
char[] aC = "ABCDEFGHI".toCharArray();
t1 = new Thread(() -> {
for(char c: aI) {
LockSupport.park();
System.out.print(c);
LockSupport.unpark(t2);
}
},"t1");
t2 = new Thread(() -> {
for(char c: aC) {
System.out.print(c);
LockSupport.unpark(t1);
LockSupport.park();
}
},"t2");
t1.start();
t2.start();
}
}
- TransferQueue的实现
import java.util.concurrent.LinkedTransferQueue;
public class TransferQueue1 {
public static void main(String[] args) {
char[] aI = "123456789".toCharArray();
char[] aC = "ABCDEFGHI".toCharArray();
java.util.concurrent.TransferQueue<Character> queue = new LinkedTransferQueue<>();
new Thread(() ->{
try{
for(char c: aI) {
System.out.print(queue.take());
queue.transfer(c);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t1").start();
new Thread(() ->{
try{
for(char c: aC) {
queue.transfer(c);
System.out.print(queue.take());
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t2").start();
}
}
2.1.20.7 - Callable捕获异常
import java.util.concurrent.*;
/**
* Callable捕获异常
*/
public class CallableGetThrow {
public static void main(String[] args){
int timeout = 2;
ExecutorService executor = Executors.newSingleThreadExecutor();
Boolean result = false;
Future<Boolean> future = executor.submit(new TaskThread("发送请求"));//将任务提交给线程池
try {
System.out.println("try");
result = future.get(timeout, TimeUnit.SECONDS);//获取结果
future.cancel(true);
System.out.println("发送请求任务的返回结果:"+result); //2
} catch (InterruptedException e) {
System.out.println("线程中断出错。"+e);
future.cancel(true);// 中断执行此任务的线程
} catch (ExecutionException e) {
System.out.println("线程服务出错。");
future.cancel(true);
} catch (TimeoutException e) {// 超时异常
System.out.println("超时。");
future.cancel(true);
}finally{
System.out.println("线程服务关闭。");
executor.shutdown();
}
}
static class TaskThread implements Callable<Boolean> {
private String t;
public TaskThread(String temp){
this.t= temp;
}
/*
try
继续执行..........
发送请求任务的返回结果: true
线程服务关闭。
*/
// public Boolean call() throws InterruptedException {
// Thread.currentThread().sleep(1000);
// System.out.println("继续执行..........");
// return true;
// }
/*
try
超时。
线程服务关闭。
*/
// public Boolean call() throws InterruptedException {
// Thread.currentThread().sleep(3000);
// System.out.println("继续执行..........");
// return true;
// }
/*
* try
* start
* 线程服务出错。
* 线程服务关闭。
*/
public Boolean call() throws InterruptedException {
System.out.println("start");
throw new InterruptedException();
}
}
}
2.1.21 - 根据对象层次路径动态获取和设置值
先看一段json
{
"wmPlans":
[
{
"skuInfos":
[
{
"customerItemNO":"no-03",
"goCargoId":"go03"
},
{
"customerItemNO":"no-04",
"goCargoId":"go04",
"extensionParameter":
{
"invNo":"abcd01",
"bu":"BM"
}
}
],
"warehouseType":"wmsHouse1",
"warehousedocumentType":"wmsDocument1"
},
{
"skuInfos":
[
{
"customerItemNO":"no-03",
"goCargoId":"go03"
},
{
"customerItemNO":"no-04",
"goCargoId":"go04"
}
],
"warehouseType":"wmsHouse2",
"warehousedocumentType":"wmsDocument2"
}
],
"goOrder":
{
"extionParam":
{
"bbb":"ccc"
},
"skuInfos":
[
{
"customerItemNO":"no-01",
"goCargoId":"go01"
},
{
"customerItemNO":"no-02",
"goCargoId":"go02"
}
],
"i3":20,
"mark3":"mark3",
"consignorCode":"ConsignorCode01"
}
}
我希望能根据一个路径
例如
goOrder.skuInfos.customerItemNO 获取到两个值 no-01 no-02
goOrder.skuInfos[0].customerItemNO 获取到 no-01
wmPlans.skuInfos.customerItemNO 获取到 no-03 no-04 no-03 no-04
wmPlans[0].skuInfos.customerItemNO 获取到 no-03 no-04
wmPlans.skuInfos[0].customerItemNO 获取到 no-03 no-03
不仅仅是获取, 我还希望可以对这个深层次的对象进行赋值 所以有了这个小例子
先定义数据结构
- OrderInfoDTO
import lombok.Data;
import lombok.ToString;
import java.util.List;
@Data
@ToString
public class OrderInfoDTO {
private GoOrderDTO goOrder;
private List<WmsPlanDTO> wmPlans;
}
- GoOrderDTO
import lombok.Data;
import lombok.ToString;
import java.util.List;
import java.util.Map;
@Data
@ToString
public class GoOrderDTO {
private String consignorCode;
private String mark3;
private Integer i3;
private List<SkuInfoDTO> skuInfos;
private Map<String, String> extionParam;
}
- WmsPlanDTO
import lombok.Data;
import lombok.ToString;
import java.util.List;
@Data
@ToString
public class WmsPlanDTO {
private String warehouseType;
private String warehousedocumentType;
private List<SkuInfoDTO> skuInfos;
}
- SkuInfoDTO
import lombok.Data;
import lombok.ToString;
import java.util.Map;
@Data
@ToString
public class SkuInfoDTO {
private String customerItemNO;
private String goCargoId;
private Map<String, String> extensionParameter;
}
定义反射方法这是我们的核心
- ReflectGetPathValRes
import lombok.Data;
@Data
public class ReflectGetPathValRes {
private Boolean success;
private String val;
public ReflectGetPathValRes(Boolean success, String val) {
this.success = success;
this.val = val;
}
}
- ReflectUtil 这个类方法里面很多重复代码,可以考虑封装成函数
import cn.hutool.json.JSONUtil;
import org.apache.commons.lang.StringUtils;
import java.lang.reflect.Field;
import java.util.*;
public class ReflectUtil {
/**
* 通过反射,对rootObj 对象 对应conditionPath路径 赋值为val
* @param rootObj
* @param conditionPath
* @param val
* @return
*/
public static boolean reflectAssignEvaluate(Object rootObj, String conditionPath, Object val) {
if (conditionPath.isEmpty()) {
System.out.println("条件比较路径发生空值错误错误");
return false;
}
String[] paths = StringUtils.split(conditionPath, '.');
int pathsLen = paths.length;
Object currObj = rootObj;
Object[] objArr = new Object[pathsLen+1];
objArr[0] = rootObj;
for(int i=0; i <= pathsLen-1; i++) {
try{
Class currObjClass = currObj.getClass();
String currGetDeclaredPath = paths[i];
// 虽然命名是mapKey 但是他也会获取到list的索引值
String mapKey = "";
if (StringUtils.contains(currGetDeclaredPath, '[')) {
currGetDeclaredPath = paths[i].substring(0, paths[i].indexOf('['));
mapKey = paths[i].substring(paths[i].indexOf('[')+1, paths[i].indexOf(']'));
}
Field currObjField = currObjClass.getDeclaredField(currGetDeclaredPath);
currObjField.setAccessible(true);
currObj = currObjField.get(currObj);
if(currObj != null) {
objArr[i+1] = currObj;
}
//如果获取到当前对象为空,并且路径不是最后一级,则为错误
if (currObj == null && i < pathsLen-1) {
System.out.println(currObjField.getType().getTypeName()+"."+currObjField.getName()+"为空,下一级属性无法获取及赋值");
return false;
}
//赋值操作
if(i == pathsLen-1) {
return objAssignEvaluate(currObjField, objArr[i], val, mapKey);
}
if (currObjField.getType().getTypeName().contains("List")) {
List srcList=(List)currObj;
String newPaths = StringUtils.join(arraySub(paths, i+1, pathsLen),'.');
if (StringUtils.isNotBlank(mapKey) && StringUtils.isNumeric(mapKey)) {
int mapKeyIndex = Integer.parseInt(mapKey);
srcList.get(mapKeyIndex);
return reflectAssignEvaluate(srcList.get(mapKeyIndex), newPaths, val);
} else {
boolean assignEvaluateRes = true;
for(Object src : srcList) {
if (!reflectAssignEvaluate(src, newPaths, val)) {
assignEvaluateRes = false;
}
}
return assignEvaluateRes;
}
}
}catch (NoSuchFieldException | IllegalAccessException e) {
System.out.println(e.getMessage());
return false;
}
}
return true;
}
/**
* 利用反射,校验条件路径下对象中的值是否与期望值相同
* 期望值都是String类型,因为是从数据库中获取到的,所以无法判定具体类型
* @param rootObj
* @param conditionPath
* @param expVal
* @return
*/
public static boolean reflectCheckCondition(Object rootObj, String conditionPath, String expVal) {
ReflectGetPathValRes getValRes = reflectGetPathVal(rootObj, conditionPath);
if (getValRes.getSuccess()) {
if (Objects.isNull(getValRes.getVal())) {
getValRes.setVal("");
}
return StringUtils.equals(getValRes.getVal(), expVal);
}
return false;
}
/**
* 通过反射,对rootObj 对象 对应conditionPath路径 代表得值
* 本方法支持map对应得key值
* list获取对应索引后得内容
* @param rootObj
* @param conditionPath
* @return
*/
public static ReflectGetPathValRes reflectGetPathVal(Object rootObj, String conditionPath) {
if (conditionPath.isEmpty()) {
System.out.println("条件比较路径发生空值错误错误");
return new ReflectGetPathValRes(false,"");
}
String[] paths = StringUtils.split(conditionPath, '.');
int pathsLen = paths.length;
Object currObj = rootObj;
Object[] objArr = new Object[pathsLen+1];
objArr[0] = rootObj;
for(int i=0; i <= pathsLen-1; i++) {
try{
Class currObjClass = currObj.getClass();
String currGetDeclaredPath = paths[i];
String mapKey = "";
if (StringUtils.contains(currGetDeclaredPath, '[')) {
currGetDeclaredPath = paths[i].substring(0, paths[i].indexOf('['));
mapKey = paths[i].substring(paths[i].indexOf('[')+1, paths[i].indexOf(']'));
}
Field currObjField = currObjClass.getDeclaredField(currGetDeclaredPath);
currObjField.setAccessible(true);
currObj = currObjField.get(currObj);
if(currObj != null) {
objArr[i+1] = currObj;
}
//如果获取到当前对象为空,并且路径不是最后一级,则为错误
if (currObj == null && i < pathsLen-1) {
System.out.println(currObjField.getType().getTypeName()+"."+currObjField.getName()+"为空,下一级属性无法获取及赋值");
return new ReflectGetPathValRes(false,"");
}
//赋值操作
if(i == pathsLen-1) {
return new ReflectGetPathValRes(true,fromObjGetFieldValue(currObjField, objArr[i], mapKey));
}
if (currObjField.getType().getTypeName().contains("List")) {
List srcList=(List)currObj;
String newPaths = StringUtils.join(arraySub(paths, i+1, pathsLen),'.');
if (StringUtils.isNotBlank(mapKey)) {
return reflectGetPathVal(srcList.get(Integer.parseInt(mapKey)),newPaths);
}
List<Object> resList = new ArrayList<>();
for(Object src : srcList) {
// return reflectGetPathVal(src,newPaths);
ReflectGetPathValRes getPathValRes = reflectGetPathVal(src,newPaths);
// 检查 getPathValRes.getVal() 是否是一个jsonarray
if (getPathValRes.getVal().startsWith("[")) {
resList.addAll(JSONUtil.toList(JSONUtil.parseArray(getPathValRes.getVal()), Object.class));
} else {
resList.add(getPathValRes.getVal());
}
}
return new ReflectGetPathValRes(true, JSONUtil.toJsonStr(resList));
}
}catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
return new ReflectGetPathValRes(false,"");
}
}
return new ReflectGetPathValRes(false,"");
}
public static boolean objAssignEvaluate(Field field, Object rootObj, Object val, String mapKey) throws IllegalAccessException {
if (field.getType().getName().contains("Integer")) {
field.set(rootObj, Integer.parseInt(String.valueOf(val)));return true;
}else if (field.getType().getName().contains("String")) {
field.set(rootObj, String.valueOf(val));
} else if (field.getType().getName().contains("Map")) {
Map<String, String> currMap = (Map<String, String>) field.get(rootObj);
if (currMap == null) {
currMap = new HashMap<>();
}
currMap.put(mapKey, String.valueOf(val));
field.set(rootObj, currMap);
} else if (field.getType().getName().contains("List")) {
List srcList=(List)field.get(rootObj);
if (srcList == null) {
srcList = new ArrayList();
}
if (StringUtils.isNotBlank(mapKey) && StringUtils.isNumeric(mapKey)) {
int index = Integer.valueOf(mapKey);
srcList.set(index, val);
// field.set(rootObj, srcList);
} else {
field.set(rootObj, val);
}
}
//其他类型的强制转换
return true;
}
/**
* 从rootObj中获取字段field得值
* @param field
* @param rootObj
* @param mapKey
* @return
* @throws IllegalAccessException
*/
public static String fromObjGetFieldValue(Field field, Object rootObj, String mapKey) throws IllegalAccessException {
if (field.getType().getName().contains("Integer")) {
Integer realVal = (Integer)field.get(rootObj);
return String.valueOf(realVal);
} else if (field.getType().getName().contains("String")) {
return (String)field.get(rootObj);
} else if (field.getType().getName().contains("Map")) {
Map<String, String> currMap = (Map<String, String>) field.get(rootObj);
return currMap.get(mapKey);
} else if (field.getType().getName().contains("List")) {
List srcList=(List)field.get(rootObj);
// mapkey不是空并且他还是一个数字
if (StringUtils.isNotBlank(mapKey) && StringUtils.isNumeric(mapKey)) {
int index = Integer.valueOf(mapKey);
return JSONUtil.toJsonStr(srcList.get(index));
}
return JSONUtil.toJsonStr(srcList);
}
//其他类型的强制转换
return "";
}
public static String[] arraySub(String[] data, int start, int end) {
String[] c = new String[end-start];
int j = 0;
for(int i=start; i<end; i++){
c[j] = data[i];
j++;
}
return c;
}
//对对象中所有字符串类型的空对象赋值空字符串
public static void javaBeanNullStrToEmptyStr(Object obj){
Class currObjClass = obj.getClass();
Field[] fields = currObjClass.getDeclaredFields();
for(Field field : fields) {
field.setAccessible(true);
if (field.getType().getName().contains("String")) {
try {
String currValue = (String) field.get(obj);
if (StringUtils.isBlank(currValue)) {
objAssignEvaluate(field, obj, "", "");
}
} catch (IllegalAccessException e) {
e.printStackTrace();
System.out.println(e.toString());
}
}
}
}
}
接下来我们进行测试
TestMain.java
import cn.hutool.json.JSONUtil;
import java.util.*;
public class TestMain {
public static void main(String[] args) {
OrderInfoDTO orderInfoDTO = initData();
System.out.println(JSONUtil.formatJsonStr(JSONUtil.toJsonStr(orderInfoDTO)));
/********************************************************************************/
// 第一次测试 一个正常的属性路径
// String path1 = "goOrder.consignorCode";
// String expValTrue="ConsignorCode01";
// // 检查一个正确的值
// boolean res11 = ReflectUtil.reflectCheckCondition(orderInfoDTO, path1, expValTrue);//true
// System.out.println(res11); // true
//
// // 重新赋值
// ReflectUtil.reflectAssignEvaluate(orderInfoDTO, path1, "ConsignorCode03");
// System.out.println(ReflectUtil.reflectGetPathVal(orderInfoDTO, path1)); // ConsignorCode03
/********************************************************************************/
// 第二次测试 一个arraylist的属性路径
// String path2 = "goOrder.skuInfos";
// String expValTrue="[{\"customerItemNO\":\"no-01\",\"goCargoId\":\"go01\"},{\"customerItemNO\":\"no-02\",\"goCargoId\":\"go02\"}]";
// boolean resTrue = ReflectUtil.reflectCheckCondition(orderInfoDTO, path2, expValTrue);
// System.out.println(resTrue);
// List<SkuInfoDTO> skuList = new ArrayList<>();
// SkuInfoDTO skuInfoDTO1 = new SkuInfoDTO();
// skuInfoDTO1.setGoCargoId("goSku01");
// skuInfoDTO1.setCustomerItemNO("noSKU01");
//
// SkuInfoDTO skuInfoDTO2 = new SkuInfoDTO();
// skuInfoDTO2.setGoCargoId("goSku02");
// skuInfoDTO2.setCustomerItemNO("noSku02");
// skuList.add(skuInfoDTO1);
// skuList.add(skuInfoDTO2);
// ReflectUtil.reflectAssignEvaluate(orderInfoDTO, path2, skuList);
// System.out.println(ReflectUtil.reflectGetPathVal(orderInfoDTO, path2));
/********************************************************************************/
// 第三次测试对数组中的某个元素的属性路径
// String path3 = "goOrder.skuInfos[0].goCargoId";
// String expValTrue="go01";
//
// boolean resTrue = ReflectUtil.reflectCheckCondition(orderInfoDTO, path3, expValTrue);
// System.out.println(resTrue); // true
// ReflectUtil.reflectAssignEvaluate(orderInfoDTO, path3, "goCargo01");
// System.out.println(JSONUtil.toJsonStr(orderInfoDTO)); // goCargo01
/********************************************************************************/
// 第四次测试 数组的指定索引进行赋值和取值
// String path4 = "goOrder.skuInfos[0]";
// System.out.println(ReflectUtil.reflectGetPathVal(orderInfoDTO, path4));
// String expValTrue="{\"customerItemNO\":\"no-01\",\"goCargoId\":\"go01\"}";
// boolean resTrue = ReflectUtil.reflectCheckCondition(orderInfoDTO, path4, expValTrue);
//
// SkuInfoDTO skuInfoDTO1 = new SkuInfoDTO();
// skuInfoDTO1.setGoCargoId("goSku01");
// skuInfoDTO1.setCustomerItemNO("noSKU01");
// ReflectUtil.reflectAssignEvaluate(orderInfoDTO, path4, skuInfoDTO1);
// System.out.println(ReflectUtil.reflectGetPathVal(orderInfoDTO, path4));
/********************************************************************************/
// 第五次测试 此次测试的赋值无意义,几乎不会有吧所有数组元素赋值成完全一样内容的需求
// String path5 = "wmPlans.skuInfos";
// System.out.println(ReflectUtil.reflectGetPathVal(orderInfoDTO, path5));
// 这样取值会将上层数组平铺开然后展示出来 [{"customerItemNO":"no-01","goCargoId":"go01"},{"customerItemNO":"no-02","goCargoId":"go02"},{"customerItemNO":"no-03","goCargoId":"go03"},{"customerItemNO":"no-04","goCargoId":"go04","extensionParameter":{"bbb":"ccc"}}]
/********************************************************************************/
// 第六次测试 第一层是数组,第二层指定索引
// String path6 = "wmPlans.skuInfos[0].customerItemNO";
// System.out.println(ReflectUtil.reflectGetPathVal(orderInfoDTO, path6));
// ReflectUtil.reflectAssignEvaluate(orderInfoDTO, path6, "shishi");
// System.out.println(JSONUtil.toJsonStr(orderInfoDTO));
/********************************************************************************/
// 第七次测试 第一层是数组指定索引,第二层是数组
// String path7 = "wmPlans[0].skuInfos.customerItemNO";
// System.out.println(ReflectUtil.reflectGetPathVal(orderInfoDTO, path7));
// ReflectUtil.reflectAssignEvaluate(orderInfoDTO, path7, "shishi");
// System.out.println(ReflectUtil.reflectGetPathVal(orderInfoDTO, path7));
// System.out.println(JSONUtil.toJsonStr(orderInfoDTO));
/********************************************************************************/
// 第八次测试 第一层是数组,然后跟一个普通的属性
// String path8 = "wmPlans.warehouseType";
// System.out.println(ReflectUtil.reflectGetPathVal(orderInfoDTO, path8));
// ReflectUtil.reflectAssignEvaluate(orderInfoDTO, path8, "warehouseTypeTh8");
// System.out.println(ReflectUtil.reflectGetPathVal(orderInfoDTO, path8));
/********************************************************************************/
// String path9 = "goOrder.skuInfos.goCargoId";
// System.out.println(ReflectUtil.reflectGetPathVal(orderInfoDTO, path9));
// ReflectUtil.reflectAssignEvaluate(orderInfoDTO,path9, "123456");
// System.out.println(JSONUtil.toJsonStr(orderInfoDTO));
/********************************************************************************/
// 第十次测试 给 所有的wmPlans 里面所有的sku 添加扩展属性 aaa = wmsplanPath10keyaaaValue
// String path10 = "wmPlans.skuInfos.extensionParameter[aaa]";
// String val3="wmsplanPath10keyaaaValue";
// ReflectUtil.reflectAssignEvaluate(orderInfoDTO,path10, val3);
// System.out.println(JSONUtil.toJsonStr(orderInfoDTO));
/********************************************************************************/
// 第十一次测试给 wmPlans[0] 的 所有sku 添加扩展属性 aaa = wmsplanPath10keyaaaValue
// String path11 = "wmPlans[0].skuInfos.extensionParameter[aaa]";
// String val11="wmsplanPath11keyaaaValue";
// ReflectUtil.reflectAssignEvaluate(orderInfoDTO,path11, val11);
// System.out.println(JSONUtil.toJsonStr(orderInfoDTO));
/********************************************************************************/
// 第十一次测试 给 所有的wmPlans 的 skuInfos[1] 添加扩展属性 aaa = wmsplanPath12keyaaaValue
// String path12 = "wmPlans.skuInfos[1].extensionParameter[aaa]";
// String val12="wmsplanPath12keyaaaValue";
// ReflectUtil.reflectAssignEvaluate(orderInfoDTO,path12, val12);
// System.out.println(JSONUtil.toJsonStr(orderInfoDTO));
/********************************************************************************/
}
public static OrderInfoDTO initData() {
SkuInfoDTO skuInfoDTO1 = new SkuInfoDTO();
skuInfoDTO1.setGoCargoId("go01");
skuInfoDTO1.setCustomerItemNO("no-01");
SkuInfoDTO skuInfoDTO2 = new SkuInfoDTO();
skuInfoDTO2.setGoCargoId("go02");
skuInfoDTO2.setCustomerItemNO("no-02");
Map<String, String> goOrderEXTMap1 = new HashMap<>();
goOrderEXTMap1.put("bbb", "ccc");
List<SkuInfoDTO> goOrderSKUInfos = new ArrayList<>();
goOrderSKUInfos.add(skuInfoDTO1);
goOrderSKUInfos.add(skuInfoDTO2);
GoOrderDTO goOrderDTO = new GoOrderDTO();
goOrderDTO.setConsignorCode("ConsignorCode01");
goOrderDTO.setMark3("mark3");
goOrderDTO.setI3(20);
goOrderDTO.setSkuInfos(goOrderSKUInfos);
goOrderDTO.setExtionParam(goOrderEXTMap1);
// goOrder赋值完成
SkuInfoDTO wmsSku0101 = new SkuInfoDTO();
wmsSku0101.setGoCargoId("go03");
wmsSku0101.setCustomerItemNO("no-03");
SkuInfoDTO wmsSku0102 = new SkuInfoDTO();
wmsSku0102.setGoCargoId("go04");
wmsSku0102.setCustomerItemNO("no-04");
Map<String, String> wmsSku0102ExtionParam = new HashMap<>();
wmsSku0102ExtionParam.put("invNo", "abcd01");
wmsSku0102ExtionParam.put("bu", "BM");
wmsSku0102.setExtensionParameter(wmsSku0102ExtionParam);
WmsPlanDTO wmsPlanDTO1 = new WmsPlanDTO();
wmsPlanDTO1.setWarehouseType("wmsHouse1");
wmsPlanDTO1.setWarehousedocumentType("wmsDocument1");
wmsPlanDTO1.setSkuInfos(Arrays.asList(wmsSku0101, wmsSku0102));
// wmsPlanDTO1赋值完成
SkuInfoDTO wmsSku0201 = new SkuInfoDTO();
wmsSku0201.setGoCargoId("go03");
wmsSku0201.setCustomerItemNO("no-03");
SkuInfoDTO wmsSku0202 = new SkuInfoDTO();
wmsSku0202.setGoCargoId("go04");
wmsSku0202.setCustomerItemNO("no-04");
Map<String, String> wmsSku0202ExtionParam = new HashMap<>();
wmsSku0202ExtionParam.put("invNo", "abcd01");
wmsSku0202ExtionParam.put("bu", "BM");
wmsSku0102.setExtensionParameter(wmsSku0202ExtionParam);
WmsPlanDTO wmsPlanDTO2 = new WmsPlanDTO();
wmsPlanDTO2.setWarehouseType("wmsHouse2");
wmsPlanDTO2.setWarehousedocumentType("wmsDocument2");
wmsPlanDTO2.setSkuInfos(Arrays.asList(wmsSku0201, wmsSku0202));
// wmsPlanDTO2赋值完成
OrderInfoDTO orderInfoDTO = new OrderInfoDTO();
orderInfoDTO.setGoOrder(goOrderDTO);
orderInfoDTO.setWmPlans(Arrays.asList(wmsPlanDTO1, wmsPlanDTO2));
return orderInfoDTO;
}
}
2.1.22 - 基于BigDecimal的高精度数字运算
package cn.anzhongwei.lean.demo.bigdecimal;
import java.math.BigDecimal;
import java.math.RoundingMode;
/**
* 用于高精确处理常用的数学运算
*/
public class ArithmeticUtils {
public static void main(String[] args) {
System.out.println("2.5 to "+toCeiling(new BigDecimal(2.5)));
System.out.println("4 to "+toCeiling(new BigDecimal(4)));
System.out.println("4.023 to "+toCeiling(new BigDecimal(4.023)));
System.out.println("0.5 to "+toCeiling(new BigDecimal(0.5)));
System.out.println("-0.5 to "+toCeiling(new BigDecimal(-0.5)));
System.out.println("-1.5 to "+toCeiling(new BigDecimal(-1.5)));
System.out.println(new BigDecimal("1.000").abs());
System.out.println(new BigDecimal("1").abs());
BigDecimal b1 = new BigDecimal("5");
BigDecimal b2 = new BigDecimal("4.000");
System.out.println(b1.compareTo(b2));
}
//默认除法运算精度
private static final int DEF_DIV_SCALE = 10;
/**
* 提供精确的加法运算
*
* @param v1 被加数
* @param v2 加数
* @return 两个参数的和
*/
public static double add(double v1, double v2) {
BigDecimal b1 = new BigDecimal(Double.toString(v1));
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.add(b2).doubleValue();
}
/**
* 提供精确的加法运算
*
* @param v1 被加数
* @param v2 加数
* @return 两个参数的和
*/
public static BigDecimal add(String v1, String v2) {
BigDecimal b1 = new BigDecimal(v1);
BigDecimal b2 = new BigDecimal(v2);
return b1.add(b2);
}
/**
* 提供精确的加法运算
*
* @param v1 被加数
* @param v2 加数
* @param scale 保留scale 位小数
* @return 两个参数的和
*/
public static String add(String v1, String v2, int scale) {
if (scale < 0) {
throw new IllegalArgumentException(
"The scale must be a positive integer or zero");
}
BigDecimal b1 = new BigDecimal(v1);
BigDecimal b2 = new BigDecimal(v2);
return b1.add(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString();
}
/**
* 提供精确的减法运算
*
* @param v1 被减数
* @param v2 减数
* @return 两个参数的差
*/
public static double sub(double v1, double v2) {
BigDecimal b1 = new BigDecimal(Double.toString(v1));
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.subtract(b2).doubleValue();
}
/**
* 提供精确的减法运算。
*
* @param v1 被减数
* @param v2 减数
* @return 两个参数的差
*/
public static BigDecimal sub(String v1, String v2) {
BigDecimal b1 = new BigDecimal(v1);
BigDecimal b2 = new BigDecimal(v2);
return b1.subtract(b2);
}
/**
* 提供精确的减法运算
*
* @param v1 被减数
* @param v2 减数
* @param scale 保留scale 位小数
* @return 两个参数的差
*/
public static String sub(String v1, String v2, int scale) {
if (scale < 0) {
throw new IllegalArgumentException(
"The scale must be a positive integer or zero");
}
BigDecimal b1 = new BigDecimal(v1);
BigDecimal b2 = new BigDecimal(v2);
return b1.subtract(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString();
}
/**
* 提供精确的乘法运算
*
* @param v1 被乘数
* @param v2 乘数
* @return 两个参数的积
*/
public static double mul(double v1, double v2) {
BigDecimal b1 = new BigDecimal(Double.toString(v1));
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.multiply(b2).doubleValue();
}
/**
* 提供精确的乘法运算
*
* @param v1 被乘数
* @param v2 乘数
* @return 两个参数的积
*/
public static BigDecimal mul(String v1, String v2) {
BigDecimal b1 = new BigDecimal(v1);
BigDecimal b2 = new BigDecimal(v2);
return b1.multiply(b2);
}
/**
* 提供精确的乘法运算
*
* @param v1 被乘数
* @param v2 乘数
* @param scale 保留scale 位小数
* @return 两个参数的积
*/
public static double mul(double v1, double v2, int scale) {
BigDecimal b1 = new BigDecimal(Double.toString(v1));
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return round(b1.multiply(b2).doubleValue(), scale);
}
/**
* 提供精确的乘法运算
*
* @param v1 被乘数
* @param v2 乘数
* @param scale 保留scale 位小数
* @return 两个参数的积
*/
public static String mul(String v1, String v2, int scale) {
if (scale < 0) {
throw new IllegalArgumentException(
"The scale must be a positive integer or zero");
}
BigDecimal b1 = new BigDecimal(v1);
BigDecimal b2 = new BigDecimal(v2);
return b1.multiply(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString();
}
/**
* 提供(相对)精确的除法运算,当发生除不尽的情况时,精确到
* 小数点以后10位,以后的数字四舍五入
*
* @param v1 被除数
* @param v2 除数
* @return 两个参数的商
*/
public static double div(double v1, double v2) {
return div(v1, v2, DEF_DIV_SCALE);
}
/**
* 提供(相对)精确的除法运算。当发生除不尽的情况时,由scale参数指
* 定精度,以后的数字四舍五入
*
* @param v1 被除数
* @param v2 除数
* @param scale 表示表示需要精确到小数点以后几位。
* @return 两个参数的商
*/
public static double div(double v1, double v2, int scale) {
if (scale < 0) {
throw new IllegalArgumentException("The scale must be a positive integer or zero");
}
BigDecimal b1 = new BigDecimal(Double.toString(v1));
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.divide(b2, scale, BigDecimal.ROUND_HALF_UP).doubleValue();
}
/**
* 提供(相对)精确的除法运算。当发生除不尽的情况时,由scale参数指
* 定精度,以后的数字四舍五入
*
* @param v1 被除数
* @param v2 除数
* @param scale 表示需要精确到小数点以后几位
* @return 两个参数的商
*/
public static String div(String v1, String v2, int scale) {
if (scale < 0) {
throw new IllegalArgumentException("The scale must be a positive integer or zero");
}
BigDecimal b1 = new BigDecimal(v1);
BigDecimal b2 = new BigDecimal(v1);
return b1.divide(b2, scale, BigDecimal.ROUND_HALF_UP).toString();
}
/**
* 提供精确的小数位四舍五入处理
*
* @param v 需要四舍五入的数字
* @param scale 小数点后保留几位
* @return 四舍五入后的结果
*/
public static double round(double v, int scale) {
if (scale < 0) {
throw new IllegalArgumentException("The scale must be a positive integer or zero");
}
BigDecimal b = new BigDecimal(Double.toString(v));
return b.setScale(scale, BigDecimal.ROUND_HALF_UP).doubleValue();
}
/**
* 提供精确的小数位四舍五入处理
*
* @param v 需要四舍五入的数字
* @param scale 小数点后保留几位
* @return 四舍五入后的结果
*/
public static String round(String v, int scale) {
if (scale < 0) {
throw new IllegalArgumentException(
"The scale must be a positive integer or zero");
}
BigDecimal b = new BigDecimal(v);
return b.setScale(scale, BigDecimal.ROUND_HALF_UP).toString();
}
/**
* 取余数
*
* @param v1 被除数
* @param v2 除数
* @param scale 小数点后保留几位
* @return 余数
*/
public static String remainder(String v1, String v2, int scale) {
if (scale < 0) {
throw new IllegalArgumentException(
"The scale must be a positive integer or zero");
}
BigDecimal b1 = new BigDecimal(v1);
BigDecimal b2 = new BigDecimal(v2);
return b1.remainder(b2).setScale(scale, BigDecimal.ROUND_HALF_UP).toString();
}
/**
* 取余数 BigDecimal
*
* @param v1 被除数
* @param v2 除数
* @param scale 小数点后保留几位
* @return 余数
*/
public static BigDecimal remainder(BigDecimal v1, BigDecimal v2, int scale) {
if (scale < 0) {
throw new IllegalArgumentException(
"The scale must be a positive integer or zero");
}
return v1.remainder(v2).setScale(scale, BigDecimal.ROUND_HALF_UP);
}
/**
* 比较大小
*
* @param v1 被比较数
* @param v2 比较数
* @return 如果v1 大于v2 则 返回true 否则false
*/
public static boolean compare(String v1, String v2) {
BigDecimal b1 = new BigDecimal(v1);
BigDecimal b2 = new BigDecimal(v2);
int bj = b1.compareTo(b2);
boolean res;
if (bj > 0)
res = true;
else
res = false;
return res;
}
public static BigDecimal toCeiling(BigDecimal val){
// if (val.compareTo(new BigDecimal(1)) >= 0) {
// return val.round(new MathContext(1, RoundingMode.CEILING));
// } else {
return val.setScale(0, RoundingMode.CEILING);
// }
}
}
运行结果
2.1.23 - 基于序列化的深拷贝
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.ToString;
import java.io.Serializable;
@AllArgsConstructor
@Data
@ToString
class Car implements Serializable {
private static final long serialVersionUID = -5713945027627603702L;
private String brand; // 品牌
private int maxSpeed; // 最高时速
}
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.ToString;
import java.io.Serializable;
@AllArgsConstructor
@Data
@ToString
class Person implements Serializable {
private static final long serialVersionUID = -9102017020286042305L;
private String name; // 姓名
private int age; // 年龄
private Car car; // 座驾
}
import java.io.*;
/**
* 浅拷贝只是复制了对象的引用地址,两个对象指向同一个内存地址,所以修改其中任意的值,另一个值都会随之变化,这就是浅拷贝(例:assign())
*
* 深拷贝是将对象及值复制过来,两个对象修改其中任意的值另一个值不会改变,这就是深拷贝(例:JSON.parse()和JSON.stringify(),但是此方法无法复制函数类型)
*/
public class CloneUtil {
public static void main(String[] args) {
try {
Person p1 = new Person("郭靖", 33, new Car("Benz", 300));
Person p2 = CloneUtil.clone(p1); // 深度克隆
p2.getCar().setBrand("BYD");
// 修改克隆的Person对象p2关联的汽车对象的品牌属性
// 原来的Person对象p1关联的汽车不会受到任何影响
// 因为在克隆Person对象时其关联的汽车对象也被克隆了
System.out.println(p1);
} catch (Exception e) {
e.printStackTrace();
}
}
// 私有构造方法
private CloneUtil() {
throw new AssertionError();
}
/*
注意:基于序列化和反序列化实现的克隆不仅仅是深度克隆,更重要的是通过泛型限定,
可以检查出要克隆的对象是否支持序列化,这项检查是编译器完成的,不是在运行时抛出异常,
这种是方案明显优于使用Object类的clone方法克隆对象。
让问题在编译的时候暴露出来总是好过把问题留到运行时。
*/
@SuppressWarnings("unchecked")
public static <T extends Serializable> T clone(T obj) throws Exception {
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bout);
oos.writeObject(obj);
ByteArrayInputStream bin = new ByteArrayInputStream(bout.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bin);
return (T) ois.readObject();
// 说明:调用ByteArrayInputStream或ByteArrayOutputStream对象的close方法没有任何意义
// 这两个基于内存的流只要垃圾回收器清理对象就能够释放资源,这一点不同于对外部资源(如文件流)的释放
}
}
2.1.24 - 时间日期
package cn.anzhongwei.lean.demo.date;
import java.time.*;
import java.time.format.DateTimeFormatter;
import java.time.temporal.ChronoUnit;
import java.util.Date;
public class DateUtils {
private static final DateTimeFormatter YEAH_MONTH_DAY = DateTimeFormatter.ofPattern("yyyy-MM-dd");
private static final DateTimeFormatter YEAH_MONTH_DAY_HOUR_MINUTE_SECOND = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
public DateUtils() {
}
public static void main(String[] args) {
System.out.println("1. 获取当前日期字符串: " + getNowDateTime());
//
System.out.println("2.1 获取UTC时间: " + getUTCTime());
System.out.println("2.2 获取时间戳: " + getTimestamp());
//
System.out.println("3. 根据字符串日期转LocalDate: " + getString2LocalDate("2019-01-01"));
System.out.println("4. 根据字符串日期时间转 LocalDateTime: " + getString2FullDate("2019-01-01 00:00:00"));
System.out.println("5. 根据自定义格式获取当前日期: " + getNowDateByFormatter("yyyy++MM++dd"));
System.out.println("6. 根据自定义格式获取当前日期时间: " + getNowDateTimeByFormatter("yyyy++MM++dd HH:mm:ss"));
System.out.printf(
"""
7. 根据节点获取当前日期时间信息
%s 年 %s 月 %s 日 星期 %s 是今年的第%s天
%s时 %s分 %s秒
%n""", getNowDateNode(DateEnum.YEAR),
getNowDateNode(DateEnum.MONTH),
getNowDateNode(DateEnum.DAY),
getNowDateNode(DateEnum.WEEK),
getNowDateNode(DateEnum.DAYOFYEAR),
getNowDateNode(DateEnum.HOUR),
getNowDateNode(DateEnum.MINUTE),
getNowDateNode(DateEnum.SECOND)
);
System.out.println("8. 一年后的日期时间: " + getPreOrAfterDateTime(DateEnum.YEAR, 1));
System.out.println("8. 一年前的日期时间: " + getPreOrAfterDateTime(DateEnum.YEAR, -1));
System.out.println("8. 一小时后的日期时间: " + getPreOrAfterDateTime(DateEnum.HOUR, 1));
System.out.println("8. 一小时前的日期时间: " + getPreOrAfterDateTime(DateEnum.HOUR, -1));
System.out.println("9. 比较两个日期时间大小 2019-01-01 00:00:00 & 2019-01-01 00:00:01: " + compareDateTime("2019-01-01 00:00:00", "2019-01-01 00:00:01"));
System.out.println("10. 判断是否闰年: " + isLeapYear("2024-01-01"));
System.out.println("11. 两个日期间隔天数: " + getPeridNum("2019-01-01", "2019-01-01", DateEnum.DAY));
System.out.println("12. 获取当前时区:" + getTimeZone());
System.out.println("13. 获取America/Los_Angeles时区时间 ZoneId.SHORT_IDS:" + getTimeZoneDateTime("America/Los_Angeles"));
}
// 1. 获取当前日期时间字符串
// 改成LocalDate.now().toString() 获取当前日期字符串
// 改成LocalTime.now().toString() 获取当前时间字符串
public static String getNowDateTime() {
return LocalDateTime.now().format(YEAH_MONTH_DAY_HOUR_MINUTE_SECOND);
}
// 2.1 获得utd时间
public static String getUTCTime() {
//Clock类
return Clock.systemUTC().instant().toString();
}
// 2.2 获得时间戳
public static Long getTimestamp() {
//Clock类
return Clock.systemUTC().millis();
}
// 3. 根据字符串日期转LocalDate
public static LocalDate getString2LocalDate(String date) {
return LocalDate.parse(date, YEAH_MONTH_DAY);
}
// 4. 根据字符串日期时间转 LocalDateTime
public static LocalDateTime getString2FullDate(String date) {
return LocalDateTime.parse(date, YEAH_MONTH_DAY_HOUR_MINUTE_SECOND);
}
// 5. 根据自定义格式获取当前日期
public static String getNowDateByFormatter(String formatterPattern) {
return LocalDate.now().format(DateTimeFormatter.ofPattern(formatterPattern));
}
// 6. 根据自定义格式获取当前日期时间
public static String getNowDateTimeByFormatter(String formatterPattern) {
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(formatterPattern));
}
// 7. 获取当前 节点
public static Integer getNowDateNode(DateEnum dateEnum) {
LocalDateTime nowDate = LocalDateTime.now();
Integer nowNode = null;
switch (dateEnum) {
case YEAR:
nowNode = nowDate.getYear();
break;
case MONTH:
nowNode = nowDate.getMonthValue();
break;
case WEEK:
nowNode = conversionWeek2Num(DateUtils.WeekEnum.valueOf(nowDate.getDayOfWeek().toString()));
break;
case DAY:
nowNode = nowDate.getDayOfMonth();
break;
case DAYOFYEAR:
nowNode = nowDate.getDayOfYear();
break;
case HOUR:
nowNode = nowDate.getHour();
break;
case MINUTE:
nowNode = nowDate.getMinute();
break;
case SECOND:
nowNode = nowDate.getSecond();
}
return nowNode;
}
// 8. 从当前日期加或减一个 年 月 日 周 时 分 秒 的时间 加就是正数 减就是负数
// LocalDateTime nowDate = LocalDateTime.now();
// 改成 LocalDate nowDate = LocalDate.now(); 就是只能获取 年月日周
// 改成 LocalTime nowDate = LocalTime.now(); 就是只能获取 时 分 秒
public static String getPreOrAfterDateTime(DateEnum dateEnum, long time) {
LocalDateTime nowDate = LocalDateTime.now();
switch (dateEnum) {
case YEAR:
// 从api 的角度也可以用 这个api提供的时间单位更多
// nowDate.plus(time, ChronoUnit.YEARS);
// nowDate.minus(time, ChronoUnit.YEARS)
return nowDate.plusYears(time).format(YEAH_MONTH_DAY_HOUR_MINUTE_SECOND);
case MONTH:
return nowDate.plusMonths(time).format(YEAH_MONTH_DAY_HOUR_MINUTE_SECOND);
case WEEK:
return nowDate.plusWeeks(time).format(YEAH_MONTH_DAY_HOUR_MINUTE_SECOND);
case DAY:
return nowDate.plusDays(time).format(YEAH_MONTH_DAY_HOUR_MINUTE_SECOND);
case DAYOFYEAR:
throw new RuntimeException("不支持的选项");
case HOUR:
return nowDate.plusHours(time).format(YEAH_MONTH_DAY_HOUR_MINUTE_SECOND);
case MINUTE:
return nowDate.plusMinutes(time).format(YEAH_MONTH_DAY_HOUR_MINUTE_SECOND);
case SECOND:
return nowDate.plusSeconds(time).format(YEAH_MONTH_DAY_HOUR_MINUTE_SECOND);
default:
throw new RuntimeException("不支持的选项");
}
}
// 9. 比较日期时间 begin 比 end 早 返回true
// 同理LocalDate比较日期 LocalTime 比较时间
public static boolean compareDateTime(String begin, String end) {
LocalDateTime beginDate = LocalDateTime.parse(begin, YEAH_MONTH_DAY_HOUR_MINUTE_SECOND);
LocalDateTime endDate = LocalDateTime.parse(end, YEAH_MONTH_DAY_HOUR_MINUTE_SECOND);
return beginDate.isBefore(endDate);
}
// 10. 判断是否闰年
public static boolean isLeapYear(String date) {
return LocalDate.parse(date.trim()).isLeapYear();
}
// 11. 获取两个日期之间的间隔 这个函数只能用LocalDate
public static Integer getPeridNum(String begin, String end, DateEnum dateEnum) {
switch (dateEnum) {
case YEAR:
return Period.between(LocalDate.parse(begin), LocalDate.parse(end)).getYears();
case MONTH:
return Period.between(LocalDate.parse(begin), LocalDate.parse(end)).getMonths();
case WEEK:
throw new RuntimeException("不支持的参数");
case DAY:
return Period.between(LocalDate.parse(begin), LocalDate.parse(end)).getDays();
default:
throw new RuntimeException("不支持的参数");
}
}
// 12. 获取当前时区
public static String getTimeZone() {
return ZoneId.systemDefault().toString();
}
// 13. 获取指定时区时间 ZoneId.SHORT_IDS
public static String getTimeZoneDateTime(String timeZone) {
return LocalDateTime.now(ZoneId.of(timeZone)).format(YEAH_MONTH_DAY_HOUR_MINUTE_SECOND);
}
public static int conversionWeek2Num(WeekEnum weekEnum) {
switch (weekEnum) {
case MONDAY:
return 1;
case TUESDAY:
return 2;
case WEDNESDAY:
return 3;
case THURSDAY:
return 4;
case FRIDAY:
return 5;
case SATURDAY:
return 6;
case SUNDAY:
return 7;
default:
return -1;
}
}
public static enum WeekEnum {
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY,
SATURDAY,
SUNDAY;
private WeekEnum() {
}
}
public static enum DateEnum {
YEAR,
MONTH,
WEEK,
DAY,
HOUR,
MINUTE,
SECOND,
DAYOFYEAR;
private DateEnum() {
}
}
}
2.1.25 - 使用抽象类来实现接口
- 创建接口类
package cn.anzhongwei.lean.demo.abstractImplementInterface;
import java.math.BigDecimal;
/**
* 接口中定义3个方法
*/
public interface InterfaceA {
int a();
String b();
BigDecimal c();
}
- 创建抽象类
package cn.anzhongwei.lean.demo.abstractImplementInterface;
/**
* 抽象中去实现两个方法,只有c()没有在抽象类中实现,留给最后类去实现c
*
*/
public abstract class AbstractB implements InterfaceA{
@Override
public int a() {
return 1;
}
@Override
public String b() {
return "Hello World!";
}
}
- 创建实现类
package cn.anzhongwei.lean.demo.abstractImplementInterface;
import java.math.BigDecimal;
/**
* 由类来实现抽象中未实现得方法, 这样得好处是可以将抽象当成通用得实现,每个最终得实现只去实现差异即可,
* 既有通用得又有灵活的方法
*/
public class ClassC extends AbstractB{
@Override
public BigDecimal c() {
return new BigDecimal(20);
}
}
- 测试类
package cn.anzhongwei.lean.demo.abstractImplementInterface;
public class TestMain {
public static void main(String[] args) {
InterfaceA interfaceA1 = new ClassC();
System.out.println(interfaceA1.a()); // 1
System.out.println(interfaceA1.b()); // Hello World!
System.out.println(interfaceA1.c()); // 20
AbstractB abstractB2 = new ClassC();
System.out.println(abstractB2.a()); // 1
System.out.println(abstractB2.b()); // Hello World!
System.out.println(abstractB2.c()); // 20
ClassC classc3 = new ClassC();
System.out.println(classc3.a()); // 1
System.out.println(classc3.b()); // Hello World!
System.out.println(classc3.c()); // 20
}
}
2.1.26 - 文件拷贝
import java.io.*;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.Charset;
import java.nio.charset.CharsetDecoder;
public class NIOFileReadAndWrite {
private String file;
public String getFile() {
return file;
}
public void setFile(String file) {
this.file = file;
}
public NIOFileReadAndWrite(String file) throws IOException {
super();
this.file = file;
}
/**
* NIO读取文件
* @param allocate
* @throws IOException
*/
public void read(int allocate) throws IOException {
RandomAccessFile access = new RandomAccessFile(this.file, "r");
//FileInputStream inputStream = new FileInputStream(this.file);
FileChannel channel = access.getChannel();
ByteBuffer byteBuffer = ByteBuffer.allocate(allocate);
CharBuffer charBuffer = CharBuffer.allocate(allocate);
Charset charset = Charset.forName("GBK");
CharsetDecoder decoder = charset.newDecoder();
int length = channel.read(byteBuffer);
while (length != -1) {
byteBuffer.flip();
decoder.decode(byteBuffer, charBuffer, true);
charBuffer.flip();
System.out.println(charBuffer.toString());
// 清空缓存
byteBuffer.clear();
charBuffer.clear();
// 再次读取文本内容
length = channel.read(byteBuffer);
}
channel.close();
if (access != null) {
access.close();
}
}
/**
* NIO写文件
* @param context
* @param allocate
* @param chartName
* @throws IOException
*/
public void write(String context, int allocate, String chartName) throws IOException{
// FileOutputStream outputStream = new FileOutputStream(this.file); //文件内容覆盖模式 --不推荐
FileOutputStream outputStream = new FileOutputStream(this.file, true); //文件内容追加模式--推荐
FileChannel channel = outputStream.getChannel();
ByteBuffer byteBuffer = ByteBuffer.allocate(allocate);
byteBuffer.put(context.getBytes(chartName));
byteBuffer.flip();//读取模式转换为写入模式
channel.write(byteBuffer);
channel.close();
if(outputStream != null){
outputStream.close();
}
}
/**
* nio事实现文件拷贝
* @param source
* @param target
* @param allocate
* @throws IOException
*/
public static void nioCpoy(String source, String target, int allocate) throws IOException{
ByteBuffer byteBuffer = ByteBuffer.allocate(allocate);
FileInputStream inputStream = new FileInputStream(source);
FileChannel inChannel = inputStream.getChannel();
FileOutputStream outputStream = new FileOutputStream(target);
FileChannel outChannel = outputStream.getChannel();
int length = inChannel.read(byteBuffer);
while(length != -1){
byteBuffer.flip();//读取模式转换写入模式
outChannel.write(byteBuffer);
byteBuffer.clear(); //清空缓存,等待下次写入
// 再次读取文本内容
length = inChannel.read(byteBuffer);
}
outputStream.close();
outChannel.close();
inputStream.close();
inChannel.close();
}
public static void fileChannelCopy(String sfPath, String tfPath) {
File sf = new File(sfPath);
File tf = new File(tfPath);
FileInputStream fi = null;
FileOutputStream fo = null;
FileChannel in = null;
FileChannel out = null;
try{
fi = new FileInputStream(sf);
fo = new FileOutputStream(tf);
in = fi.getChannel();//得到对应的文件通道
out = fo.getChannel();//得到对应的文件通道
in.transferTo(0, in.size(), out);//连接两个通道,并且从in通道读取,然后写入out通道
}catch (Exception e){
e.printStackTrace();
}finally {
try{
fi.close();
in.close();
fo.close();
out.close();
}catch (Exception e){
e.printStackTrace();
}
}
}
//IO方法实现文件k拷贝
private static void traditionalCopy(String sourcePath, String destPath) throws Exception {
File source = new File(sourcePath);
File dest = new File(destPath);
if (!dest.exists()) {
dest.createNewFile();
}
FileInputStream fis = new FileInputStream(source);
FileOutputStream fos = new FileOutputStream(dest);
byte[] buf = new byte[1024];
int len = 0;
while ((len = fis.read(buf)) != -1) {
fos.write(buf, 0, len);
}
fis.close();
fos.close();
}
public static void main(String[] args) throws Exception{
long start = System.currentTimeMillis();
nioCpoy("D:\\迅雷下载\\jdk-21_windows-x64_bin.zip", "D:\\qwe\\jdk-21_windows-x64_bin.zip",10240);
long end = System.currentTimeMillis();
System.out.println("用时为:" + (end-start));
long start2 = System.currentTimeMillis();
fileChannelCopy("D:\\迅雷下载\\jdk-21_windows-x64_bin.zip", "D:\\qwe\\jdk-21_windows-x64_bin.zip");
long end2 = System.currentTimeMillis();
System.out.println("用时为:" + (end2-start2));
long start3 = System.currentTimeMillis();
traditionalCopy("D:\\迅雷下载\\jdk-21_windows-x64_bin.zip", "D:\\qwe\\jdk-21_windows-x64_bin.zip");
long end3 = System.currentTimeMillis();
System.out.println("用时为:" + (end3-start3));
}
}
2.1.27 - 下载图片
package cn.anzhongwei.lean.demo.downfileforweb;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.HttpServletResponse;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.nio.charset.StandardCharsets;
@RestController
@ResponseBody
public class DownImgController {
//http://localhost:8080/ttpng?seriesUniqueCode=1
@GetMapping(value = "/writeImg1")
public void writeImg1(HttpServletResponse response) throws IOException {
//设置响应头信息需要在输出流之前, 就可以触发浏览器下载机制, 注释下列3行或将其写在输出流之后, 都只会在浏览器显示不会触发下载
// response.setHeader("Content-disposition", "attachment;filename=cargoExport.jpg");
// response.setContentType("multipart/form-data");
// response.setCharacterEncoding(StandardCharsets.UTF_8.name());
URL url = null;
InputStream is = null;
ByteArrayOutputStream outStream = null;
HttpURLConnection httpUrl = null;
//随便找一张图片
url = new URL("http://img.ay1.cc/uploads/20221114/9f3e884272b562cf8b27a048c3634621.jpg");
httpUrl = (HttpURLConnection) url.openConnection();
httpUrl.connect();
httpUrl.getInputStream();
is = httpUrl.getInputStream();
outStream = new ByteArrayOutputStream();
//创建一个Buffer字符串
byte[] buffer = new byte[1024];
//每次读取的字符串长度,如果为-1,代表全部读取完毕
int len = 0;
//使用一个输入流从buffer里把数据读取出来
while ((len = is.read(buffer)) != -1) {
//用输出流往buffer里写入数据,中间参数代表从哪个位置开始读,len代表读取的长度
response.getOutputStream().write(buffer, 0, len);
}
response.flushBuffer();
}
@GetMapping(value = "/writeImg2", produces = MediaType.IMAGE_JPEG_VALUE)
public void writeImg2(HttpServletResponse response) throws IOException {
URL url = null;
InputStream is = null;
ByteArrayOutputStream outStream = null;
HttpURLConnection httpUrl = null;
url = new URL("http://img.ay1.cc/uploads/20221114/9f3e884272b562cf8b27a048c3634621.jpg");
httpUrl = (HttpURLConnection) url.openConnection();
httpUrl.connect();
httpUrl.getInputStream();
is = httpUrl.getInputStream();
outStream = new ByteArrayOutputStream();
//创建一个Buffer字符串
byte[] buffer = new byte[1024];
//每次读取的字符串长度,如果为-1,代表全部读取完毕
int len = 0;
//使用一个输入流从buffer里把数据读取出来
while ((len = is.read(buffer)) != -1) {
//用输出流往buffer里写入数据,中间参数代表从哪个位置开始读,len代表读取的长度
outStream.write(buffer, 0, len);
}
byte[] temp = outStream.toByteArray();
response.setHeader("Content-disposition", "attachment;filename=cargoExport.jpg");
response.setContentType("multipart/form-data");
response.setCharacterEncoding(StandardCharsets.UTF_8.name());
response.getOutputStream().write(temp);
response.flushBuffer();
}
public void imgToBase64() {
URL downUrl = new URL("http://localhost/test.png");
HttpURLConnection conn = (HttpURLConnection) downUrl.openConnection();
conn.setRequestMethod("GET");
conn.setConnectTimeout(5000);
InputStream inputStream = conn.getInputStream();
ByteArrayOutputStream data = new ByteArrayOutputStream();
byte[] by = new byte[1024];
int len = -1;
while((len = inputStream.read(by)) != -1){
data.write(by,0,len);
}
inputStream.close();
Base64.getEncoder().encode(data.toByteArray());
String imgStr = Base64.getEncoder().encodeToString(data.toByteArray());
System.out.println(imgStr);
}
}
2.1.28 - 原生Java发送Post请求
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;
import java.net.URL;
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class JavaPostJson2 {
final static String url = "http://localhost:1111/sendData";
// final static String params = "{\"token\":\"12345\","
// + "\"appId\":\"20180628173051169c85d965d164ed9ab1281d22ff350ec19\""
// + "\"appName\":\"test33\""
// + "\"classTopic\":\"112\""
// + "\"eventTag\":\"22\""
// + "\"msg\":{}"
// + "}";
final static String params = "{\"token\":\"12345\","
+ "\"appId\":\"20180628173051169c85d965d164ed9ab1281d22ff350ec19\","
+ "\"appName\":\"test33\","
+ "\"classTopic\":\"112\","
+ "\"eventTag\":\"22\""
+ "}";
public static void main(String[] args) {
String res = post(url, params);
System.out.println(res);
}
/**
* 发送HttpPost请求
*
* @param strURL
* 服务地址
* @param params
* json字符串,例如: "{ \"id\":\"12345\" }" ;其中属性名必须带双引号<br/>
* @return 成功:返回json字符串<br/>
*/
public static String post(String strURL, String params) {
System.out.println(strURL);
System.out.println(params);
BufferedReader reader = null;
try {
URL url = new URL(strURL);// 创建连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setDoOutput(true);
connection.setDoInput(true);
connection.setUseCaches(false);
connection.setInstanceFollowRedirects(true);
connection.setRequestMethod("POST"); // 设置请求方式
// connection.setRequestProperty("Accept", "application/json"); // 设置接收数据的格式
connection.setRequestProperty("Content-Type", "application/json"); // 设置发送数据的格式
connection.connect();
OutputStreamWriter out = new OutputStreamWriter(connection.getOutputStream(), "UTF-8"); // utf-8编码
out.append(params);
out.flush();
out.close();
// 读取响应
reader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
String line;
String res = "";
while ((line = reader.readLine()) != null) {
res += line;
}
reader.close();
return res;
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return "error"; // 自定义错误信息
}
}
2.2 - Netty实战
Netty实战,小傅哥博客Netty实战的实现
案例一 TCP服务端
要求1: 在客户端连接后打印客户端端的ip和端口号
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.ChannelFuture;
import io.netty.channel.EventLoopGroup;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioServerSocketChannel;
public class DemoNetty101 {
public static void main(String[] args) {
DemoNetty101 demoNetty101 = new DemoNetty101();
demoNetty101.startTCP();
}
private void startTCP() {
// 一个监听工作组,在很多写法中叫做master组
EventLoopGroup bossGroup = new NioEventLoopGroup();
// 一个工作监听组,在很多写法中交child组
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap server = new ServerBootstrap();
server.group(bossGroup, workerGroup)
// 设置非阻塞模式
.channel(NioServerSocketChannel.class)
// 添加自定义处理器
.childHandler(new TCPServerInitializer());
ChannelFuture f = server.bind(8088).sync();
System.out.println("Http Server started, Listening on " + 8088);
f.channel().closeFuture().sync();
} catch (Exception e) {
e.printStackTrace();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}
import io.netty.channel.ChannelInitializer;
import io.netty.channel.socket.SocketChannel;
public class TCPServerInitializer extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
System.out.println("初始化连接成功");
System.out.println(socketChannel.remoteAddress().getHostString()+":"+socketChannel.remoteAddress().getPort());
}
}
案例二 TCP服务端
要求1: 在客户端连接后打印客户端端的ip和端口号 要求2:能打印出客户端发送的内容
案例三 TCP服务端
要求1: 在客户端连接后打印客户端端的ip和端口号 要求2: 使用内置的协议解析器解码客户端发送的内容 要求3:使用字符串解码器解码, 打印出客户端发送的内容
案例四 TCP服务端
要求1: 让入站数据经过多个Handle处理器 要求2: 每个处理器都知道客户端关闭了连接
案例五 TCP服务端
要求1: 能将收到的内容原样回复给客户端程序(这里的变化主要是要将返回的数据进行编码)
案例六 TCP服务端
要求1: 使用内置的字符串编解码器
案例七 TCP服务端
要求1: 接收多个客户端链接(其实就是可以缓存多个客户端链接),并每次响应给所有客户端(群发消息)
案例八 TCP客户端
要求1: 新建客户端能正常连接到一个服务端
案例九 TCP客户端
要求1: 新建客户端能正常连接到一个服务端 要求2: 使用netty自带的换行解析器拆分数据, 并使用字符串解码编码器来打印服务端信息和返回服务端字符串
案例十 TCP客户端和服务端
要求1: 使用继承ChannelInboundHandlerAdapter处理入站信息 使用继承ChannelOutboundHandlerAdapter处理出站时间
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
System.out.println("链接报告开始");
System.out.println("链接报告信息:本客户端链接到服务端。channelId:" + socketChannel.id());
System.out.println("链接报告完毕");
socketChannel.pipeline().addLast(new LineBasedFrameDecoder(1024))
.addLast(new StringDecoder(Charset.forName("GBK")))
.addLast(new StringEncoder(Charset.forName("GBK")))
.addLast(new Outbound1())
.addLast(new Outbound2())
.addLast(new Inbound1())
//必须使用ctx.writeAndFlush(message); 否则出站处理器收不到消息,
//如果定义到Outbound前面相当于数据提前掉头了
.addLast(new Inbound2())
;
}
//在Inbound2中必须使用ctx.writeAndFlush(message); 也就是最后一个入站处理器必须使用ctx.writeAndFlush(message); 否则出站处理器收不到消息
// 同时如果在Inbound1中使用了ctx.writeAndFlush(message); 那么数据将不再向Inbound2中传递
//根据处理器执行顺序,数据会先走Outbound2 再走Outbound1, 所以再Outbund1中必须调用ctx.writeAndFlush(message, promise);
案例十一 UDP客户端和服务端
案例十二 简单的http服务器
2.3 - Spring
以SpringBoot 3 的支持
2.3.1 - GetSpringBeanUtil
import org.springframework.aop.framework.AopContext;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.NoSuchBeanDefinitionException;
import org.springframework.beans.factory.config.BeanFactoryPostProcessor;
import org.springframework.beans.factory.config.ConfigurableListableBeanFactory;
import org.springframework.stereotype.Component;
/**
* 可以实现在普通类中获取springBean实例
*/
@Component
public final class GetSpringBeanUtil implements BeanFactoryPostProcessor {
private static ConfigurableListableBeanFactory beanFactory;
public GetSpringBeanUtil() {
}
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
GetSpringBeanUtil.beanFactory = beanFactory;
}
public static <T> T getBean(String name) throws BeansException {
return (T) beanFactory.getBean(name);
}
public static <T> T getBean(Class<T> clz) throws BeansException {
T result = beanFactory.getBean(clz);
return result;
}
public static boolean containsBean(String name) {
return beanFactory.containsBean(name);
}
public static boolean isSingleton(String name) throws NoSuchBeanDefinitionException {
return beanFactory.isSingleton(name);
}
public static Class<?> getType(String name) throws NoSuchBeanDefinitionException {
return beanFactory.getType(name);
}
public static String[] getAliases(String name) throws NoSuchBeanDefinitionException {
return beanFactory.getAliases(name);
}
public static <T> T getAopProxy(T invoker) {
return (T) AopContext.currentProxy();
}
}
2.4 - 一文读懂classLoader
本篇文章已授权微信公众号 guolin_blog (郭霖)独家发布
ClassLoader翻译过来就是类加载器,普通的java开发者其实用到的不多,但对于某些框架开发者来说却非常常见。理解ClassLoader的加载机制,也有利于我们编写出更高效的代码。ClassLoader的具体作用就是将class文件加载到jvm虚拟机中去,程序就可以正确运行了。但是,jvm启动的时候,并不会一次性加载所有的class文件,而是根据需要去动态加载。想想也是的,一次性加载那么多jar包那么多class,那内存不崩溃。本文的目的也是学习ClassLoader这种加载机制。
备注:本文篇幅比较长,但内容简单,大家不要恐慌,安静地耐心翻阅就是
Class文件的认识
我们都知道在Java中程序是运行在虚拟机中,我们平常用文本编辑器或者是IDE编写的程序都是.java格式的文件,这是最基础的源码,但这类文件是不能直接运行的。如我们编写一个简单的程序HelloWorld.java
public class HelloWorld{
public static void main(String[] args){
System.out.println("Hello world!");
}
}
如图:

然后,我们需要在命令行中进行java文件的编译
javac HelloWorld.java

可以看到目录下生成了.class文件
我们再从命令行中执行命令:
java HelloWorld
上面是基本代码示例,是所有入门JAVA语言时都学过的东西,这里重新拿出来是想让大家将焦点回到class文件上,class文件是字节码格式文件,java虚拟机并不能直接识别我们平常编写的.java源文件,所以需要javac这个命令转换成.class文件。另外,如果用C或者PYTHON编写的程序正确转换成.class文件后,java虚拟机也是可以识别运行的。更多信息大家可以参考这篇。
了解了.class文件后,我们再来思考下,我们平常在Eclipse中编写的java程序是如何运行的,也就是我们自己编写的各种类是如何被加载到jvm(java虚拟机)中去的。
你还记得java环境变量吗?
初学java的时候,最害怕的就是下载JDK后要配置环境变量了,关键是当时不理解,所以战战兢兢地照着书籍上或者是网络上的介绍进行操作。然后下次再弄的时候,又忘记了而且是必忘。当时,心里的想法很气愤的,想着是–这东西一点也不人性化,为什么非要自己配置环境变量呢?太不照顾菜鸟和新手了,很多菜鸟就是因为卡在环境变量的配置上,遭受了太多的挫败感。
因为我是在Windows下编程的,所以只讲Window平台上的环境变量,主要有3个:JAVA_HOME、PATH、CLASSPATH。
JAVA_HOME
指的是你JDK安装的位置,一般默认安装在C盘,如
C:\Program Files\Java\jdk1.8.0_91
PATH
将程序路径包含在PATH当中后,在命令行窗口就可以直接键入它的名字了,而不再需要键入它的全路径,比如上面代码中我用的到javac和java两个命令。
一般的
PATH=%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;%PATH%;
也就是在原来的PATH路径上添加JDK目录下的bin目录和jre目录的bin.
CLASSPATH
CLASSPATH=.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar
一看就是指向jar包路径。
需要注意的是前面的.;,.代表当前目录。
环境变量的设置与查看
设置可以右击我的电脑,然后点击属性,再点击高级,然后点击环境变量,具体不明白的自行查阅文档。
查看的话可以打开命令行窗口
echo %JAVA_HOME%
echo %PATH%
echo %CLASSPATH%
好了,扯远了,知道了环境变量,特别是CLASSPATH时,我们进入今天的主题Classloader.
JAVA类加载流程
Java语言系统自带有三个类加载器:
- Bootstrap ClassLoader 最顶层的加载类,主要加载核心类库,%JRE_HOME%\lib下的rt.jar、resources.jar、charsets.jar和class等。另外需要注意的是可以通过启动jvm时指定-Xbootclasspath和路径来改变Bootstrap ClassLoader的加载目录。比如
java -Xbootclasspath/a:path被指定的文件追加到默认的bootstrap路径中。我们可以打开我的电脑,在上面的目录下查看,看看这些jar包是不是存在于这个目录。 - Extention ClassLoader 扩展的类加载器,加载目录%JRE_HOME%\lib\ext目录下的jar包和class文件。还可以加载
-D java.ext.dirs选项指定的目录。 - Appclass Loader也称为SystemAppClass 加载当前应用的classpath的所有类。
我们上面简单介绍了3个ClassLoader。说明了它们加载的路径。并且还提到了-Xbootclasspath和-D java.ext.dirs这两个虚拟机参数选项。
加载顺序?
我们看到了系统的3个类加载器,但我们可能不知道具体哪个先行呢?
我可以先告诉你答案
- Bootstrap CLassloder
- Extention ClassLoader
- AppClassLoader
为了更好的理解,我们可以查看源码。
看sun.misc.Launcher,它是一个java虚拟机的入口应用。
public class Launcher {
private static Launcher launcher = new Launcher();
private static String bootClassPath =
System.getProperty("sun.boot.class.path");
public static Launcher getLauncher() {
return launcher;
}
private ClassLoader loader;
public Launcher() {
// Create the extension class loader
ClassLoader extcl;
try {
extcl = ExtClassLoader.getExtClassLoader();
} catch (IOException e) {
throw new InternalError(
"Could not create extension class loader", e);
}
// Now create the class loader to use to launch the application
try {
loader = AppClassLoader.getAppClassLoader(extcl);
} catch (IOException e) {
throw new InternalError(
"Could not create application class loader", e);
}
//设置AppClassLoader为线程上下文类加载器,这个文章后面部分讲解
Thread.currentThread().setContextClassLoader(loader);
}
/*
* Returns the class loader used to launch the main application.
*/
public ClassLoader getClassLoader() {
return loader;
}
/*
* The class loader used for loading installed extensions.
*/
static class ExtClassLoader extends URLClassLoader {}
/**
* The class loader used for loading from java.class.path.
* runs in a restricted security context.
*/
static class AppClassLoader extends URLClassLoader {}
源码有精简,我们可以得到相关的信息。
- Launcher初始化了ExtClassLoader和AppClassLoader。
- Launcher中并没有看见BootstrapClassLoader,但通过
System.getProperty("sun.boot.class.path")得到了字符串bootClassPath,这个应该就是BootstrapClassLoader加载的jar包路径。
我们可以先代码测试一下sun.boot.class.path是什么内容。
System.out.println(System.getProperty("sun.boot.class.path"));
得到的结果是:
C:\Program Files\Java\jre1.8.0_91\lib\resources.jar;
C:\Program Files\Java\jre1.8.0_91\lib\rt.jar;
C:\Program Files\Java\jre1.8.0_91\lib\sunrsasign.jar;
C:\Program Files\Java\jre1.8.0_91\lib\jsse.jar;
C:\Program Files\Java\jre1.8.0_91\lib\jce.jar;
C:\Program Files\Java\jre1.8.0_91\lib\charsets.jar;
C:\Program Files\Java\jre1.8.0_91\lib\jfr.jar;
C:\Program Files\Java\jre1.8.0_91\classes
可以看到,这些全是JRE目录下的jar包或者是class文件。
ExtClassLoader源码
如果你有足够的好奇心,你应该会对它的源码感兴趣
/*
* The class loader used for loading installed extensions.
*/
static class ExtClassLoader extends URLClassLoader {
static {
ClassLoader.registerAsParallelCapable();
}
/**
* create an ExtClassLoader. The ExtClassLoader is created
* within a context that limits which files it can read
*/
public static ExtClassLoader getExtClassLoader() throws IOException
{
final File[] dirs = getExtDirs();
try {
// Prior implementations of this doPrivileged() block supplied
// aa synthesized ACC via a call to the private method
// ExtClassLoader.getContext().
return AccessController.doPrivileged(
new PrivilegedExceptionAction<ExtClassLoader>() {
public ExtClassLoader run() throws IOException {
int len = dirs.length;
for (int i = 0; i < len; i++) {
MetaIndex.registerDirectory(dirs[i]);
}
return new ExtClassLoader(dirs);
}
});
} catch (java.security.PrivilegedActionException e) {
throw (IOException) e.getException();
}
}
private static File[] getExtDirs() {
String s = System.getProperty("java.ext.dirs");
File[] dirs;
if (s != null) {
StringTokenizer st =
new StringTokenizer(s, File.pathSeparator);
int count = st.countTokens();
dirs = new File[count];
for (int i = 0; i < count; i++) {
dirs[i] = new File(st.nextToken());
}
} else {
dirs = new File[0];
}
return dirs;
}
......
}
我们先前的内容有说过,可以指定-D java.ext.dirs参数来添加和改变ExtClassLoader的加载路径。这里我们通过可以编写测试代码。
System.out.println(System.getProperty("java.ext.dirs"));
结果如下:
C:\Program Files\Java\jre1.8.0_91\lib\ext;C:\Windows\Sun\Java\lib\ext
AppClassLoader源码
/**
* The class loader used for loading from java.class.path.
* runs in a restricted security context.
*/
static class AppClassLoader extends URLClassLoader {
public static ClassLoader getAppClassLoader(final ClassLoader extcl)
throws IOException
{
final String s = System.getProperty("java.class.path");
final File[] path = (s == null) ? new File[0] : getClassPath(s);
return AccessController.doPrivileged(
new PrivilegedAction<AppClassLoader>() {
public AppClassLoader run() {
URL[] urls =
(s == null) ? new URL[0] : pathToURLs(path);
return new AppClassLoader(urls, extcl);
}
});
}
......
}
可以看到AppClassLoader加载的就是java.class.path下的路径。我们同样打印它的值。
System.out.println(System.getProperty("java.class.path"));
结果:
D:\workspace\ClassLoaderDemo\bin
这个路径其实就是当前java工程目录bin,里面存放的是编译生成的class文件。
好了,自此我们已经知道了BootstrapClassLoader、ExtClassLoader、AppClassLoader实际是查阅相应的环境属性sun.boot.class.path、java.ext.dirs和java.class.path来加载资源文件的。
接下来我们探讨它们的加载顺序,我们先用Eclipse建立一个java工程。
然后创建一个Test.java文件。
public class Test{}
然后,编写一个ClassLoaderTest.java文件。
public class ClassLoaderTest {
public static void main(String[] args) {
// TODO Auto-generated method stub
ClassLoader cl = Test.class.getClassLoader();
System.out.println("ClassLoader is:"+cl.toString());
}
}
我们获取到了Test.class文件的类加载器,然后打印出来。结果是:
ClassLoader is:sun.misc.Launcher$AppClassLoader@73d16e93
也就是说明Test.class文件是由AppClassLoader加载的。
这个Test类是我们自己编写的,那么int.class或者是String.class的加载是由谁完成的呢?
我们可以在代码中尝试
public class ClassLoaderTest {
public static void main(String[] args) {
// TODO Auto-generated method stub
ClassLoader cl = Test.class.getClassLoader();
System.out.println("ClassLoader is:"+cl.toString());
cl = int.class.getClassLoader();
System.out.println("ClassLoader is:"+cl.toString());
}
}
运行一下,却报错了
ClassLoader is:sun.misc.Launcher$AppClassLoader@73d16e93
Exception in thread "main" java.lang.NullPointerException
at ClassLoaderTest.main(ClassLoaderTest.java:15)
提示的是空指针,意思是int.class这类基础类没有类加载器加载?
当然不是!
int.class是由Bootstrap ClassLoader加载的。要想弄明白这些,我们首先得知道一个前提。
每个类加载器都有一个父加载器
每个类加载器都有一个父加载器,比如加载Test.class是由AppClassLoader完成,那么AppClassLoader也有一个父加载器,怎么样获取呢?很简单,通过getParent方法。比如代码可以这样编写:
ClassLoader cl = Test.class.getClassLoader();
System.out.println("ClassLoader is:"+cl.toString());
System.out.println("ClassLoader\'s parent is:"+cl.getParent().toString());
运行结果如下:
ClassLoader is:sun.misc.Launcher$AppClassLoader@73d16e93
ClassLoader's parent is:sun.misc.Launcher$ExtClassLoader@15db9742
这个说明,AppClassLoader的父加载器是ExtClassLoader。那么ExtClassLoader的父加载器又是谁呢?
System.out.println("ClassLoader is:"+cl.toString());
System.out.println("ClassLoader\'s parent is:"+cl.getParent().toString());
System.out.println("ClassLoader\'s grand father is:"+cl.getParent().getParent().toString());
运行如果:
ClassLoader is:sun.misc.Launcher$AppClassLoader@73d16e93
Exception in thread "main" ClassLoader's parent is:sun.misc.Launcher$ExtClassLoader@15db9742
java.lang.NullPointerException
at ClassLoaderTest.main(ClassLoaderTest.java:13)
又是一个空指针异常,这表明ExtClassLoader也没有父加载器。那么,为什么标题又是每一个加载器都有一个父加载器呢?这不矛盾吗?为了解释这一点,我们还需要看下面的一个基础前提。
父加载器不是父类
我们先前已经粘贴了ExtClassLoader和AppClassLoader的代码。
static class ExtClassLoader extends URLClassLoader {}
static class AppClassLoader extends URLClassLoader {}
可以看见ExtClassLoader和AppClassLoader同样继承自URLClassLoader,但上面一小节代码中,为什么调用AppClassLoader的getParent()代码会得到ExtClassLoader的实例呢?先从URLClassLoader说起,这个类又是什么?
先上一张类的继承关系图
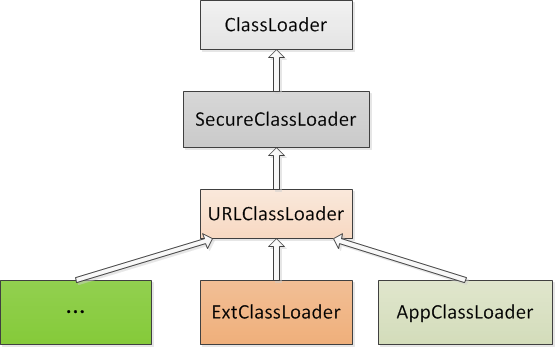
URLClassLoader的源码中并没有找到getParent()方法。这个方法在ClassLoader.java中。
public abstract class ClassLoader {
// The parent class loader for delegation
// Note: VM hardcoded the offset of this field, thus all new fields
// must be added *after* it.
private final ClassLoader parent;
// The class loader for the system
// @GuardedBy("ClassLoader.class")
private static ClassLoader scl;
private ClassLoader(Void unused, ClassLoader parent) {
this.parent = parent;
...
}
protected ClassLoader(ClassLoader parent) {
this(checkCreateClassLoader(), parent);
}
protected ClassLoader() {
this(checkCreateClassLoader(), getSystemClassLoader());
}
public final ClassLoader getParent() {
if (parent == null)
return null;
return parent;
}
public static ClassLoader getSystemClassLoader() {
initSystemClassLoader();
if (scl == null) {
return null;
}
return scl;
}
private static synchronized void initSystemClassLoader() {
if (!sclSet) {
if (scl != null)
throw new IllegalStateException("recursive invocation");
sun.misc.Launcher l = sun.misc.Launcher.getLauncher();
if (l != null) {
Throwable oops = null;
//通过Launcher获取ClassLoader
scl = l.getClassLoader();
try {
scl = AccessController.doPrivileged(
new SystemClassLoaderAction(scl));
} catch (PrivilegedActionException pae) {
oops = pae.getCause();
if (oops instanceof InvocationTargetException) {
oops = oops.getCause();
}
}
if (oops != null) {
if (oops instanceof Error) {
throw (Error) oops;
} else {
// wrap the exception
throw new Error(oops);
}
}
}
sclSet = true;
}
}
}
我们可以看到getParent()实际上返回的就是一个ClassLoader对象parent,parent的赋值是在ClassLoader对象的构造方法中,它有两个情况:
- 由外部类创建ClassLoader时直接指定一个ClassLoader为parent。
- 由
getSystemClassLoader()方法生成,也就是在sun.misc.Laucher通过getClassLoader()获取,也就是AppClassLoader。直白的说,一个ClassLoader创建时如果没有指定parent,那么它的parent默认就是AppClassLoader。
我们主要研究的是ExtClassLoader与AppClassLoader的parent的来源,正好它们与Launcher类有关,我们上面已经粘贴过Launcher的部分代码。
public class Launcher {
private static URLStreamHandlerFactory factory = new Factory();
private static Launcher launcher = new Launcher();
private static String bootClassPath =
System.getProperty("sun.boot.class.path");
public static Launcher getLauncher() {
return launcher;
}
private ClassLoader loader;
public Launcher() {
// Create the extension class loader
ClassLoader extcl;
try {
extcl = ExtClassLoader.getExtClassLoader();
} catch (IOException e) {
throw new InternalError(
"Could not create extension class loader", e);
}
// Now create the class loader to use to launch the application
try {
//将ExtClassLoader对象实例传递进去
loader = AppClassLoader.getAppClassLoader(extcl);
} catch (IOException e) {
throw new InternalError(
"Could not create application class loader", e);
}
public ClassLoader getClassLoader() {
return loader;
}
static class ExtClassLoader extends URLClassLoader {
/**
* create an ExtClassLoader. The ExtClassLoader is created
* within a context that limits which files it can read
*/
public static ExtClassLoader getExtClassLoader() throws IOException
{
final File[] dirs = getExtDirs();
try {
// Prior implementations of this doPrivileged() block supplied
// aa synthesized ACC via a call to the private method
// ExtClassLoader.getContext().
return AccessController.doPrivileged(
new PrivilegedExceptionAction<ExtClassLoader>() {
public ExtClassLoader run() throws IOException {
//ExtClassLoader在这里创建
return new ExtClassLoader(dirs);
}
});
} catch (java.security.PrivilegedActionException e) {
throw (IOException) e.getException();
}
}
/*
* Creates a new ExtClassLoader for the specified directories.
*/
public ExtClassLoader(File[] dirs) throws IOException {
super(getExtURLs(dirs), null, factory);
}
}
}
我们需要注意的是
ClassLoader extcl;
extcl = ExtClassLoader.getExtClassLoader();
loader = AppClassLoader.getAppClassLoader(extcl);
代码已经说明了问题AppClassLoader的parent是一个ExtClassLoader实例。
ExtClassLoader并没有直接找到对parent的赋值。它调用了它的父类也就是URLClassLoder的构造方法并传递了3个参数。
public ExtClassLoader(File[] dirs) throws IOException {
super(getExtURLs(dirs), null, factory);
}
对应的代码
public URLClassLoader(URL[] urls, ClassLoader parent,
URLStreamHandlerFactory factory) {
super(parent);
}
答案已经很明了了,ExtClassLoader的parent为null。
上面张贴这么多代码也是为了说明AppClassLoader的parent是ExtClassLoader,ExtClassLoader的parent是null。这符合我们之前编写的测试代码。
不过,细心的同学发现,还是有疑问的我们只看到ExtClassLoader和AppClassLoader的创建,那么BootstrapClassLoader呢?
还有,ExtClassLoader的父加载器为null,但是Bootstrap CLassLoader却可以当成它的父加载器这又是为何呢?
我们继续往下进行。
Bootstrap ClassLoader是由C++编写的。
Bootstrap ClassLoader是由C/C++编写的,它本身是虚拟机的一部分,所以它并不是一个JAVA类,也就是无法在java代码中获取它的引用,JVM启动时通过Bootstrap类加载器加载rt.jar等核心jar包中的class文件,之前的int.class,String.class都是由它加载。然后呢,我们前面已经分析了,JVM初始化sun.misc.Launcher并创建Extension ClassLoader和AppClassLoader实例。并将ExtClassLoader设置为AppClassLoader的父加载器。Bootstrap没有父加载器,但是它却可以作用一个ClassLoader的父加载器。比如ExtClassLoader。这也可以解释之前通过ExtClassLoader的getParent方法获取为Null的现象。具体是什么原因,很快就知道答案了。
双亲委托
双亲委托。
我们终于来到了这一步了。
一个类加载器查找class和resource时,是通过“委托模式”进行的,它首先判断这个class是不是已经加载成功,如果没有的话它并不是自己进行查找,而是先通过父加载器,然后递归下去,直到Bootstrap ClassLoader,如果Bootstrap classloader找到了,直接返回,如果没有找到,则一级一级返回,最后到达自身去查找这些对象。这种机制就叫做双亲委托。
整个流程可以如下图所示:
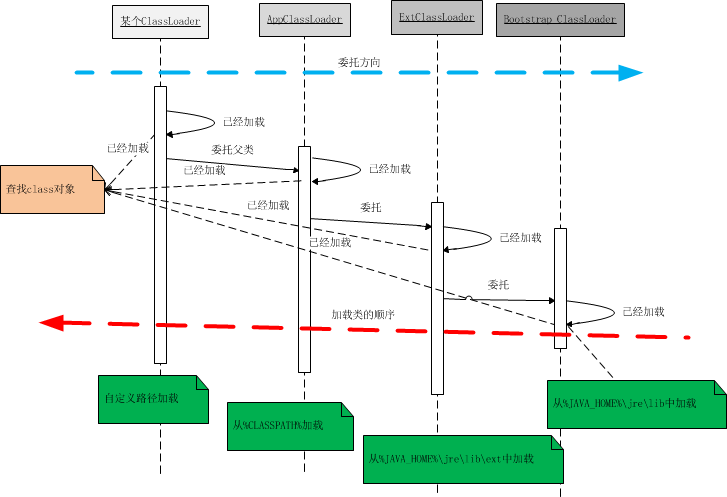
这张图是用时序图画出来的,不过画出来的结果我却自己都觉得不理想。
大家可以看到2根箭头,蓝色的代表类加载器向上委托的方向,如果当前的类加载器没有查询到这个class对象已经加载就请求父加载器(不一定是父类)进行操作,然后以此类推。直到Bootstrap ClassLoader。如果Bootstrap ClassLoader也没有加载过此class实例,那么它就会从它指定的路径中去查找,如果查找成功则返回,如果没有查找成功则交给子类加载器,也就是ExtClassLoader,这样类似操作直到终点,也就是我上图中的红色箭头示例。
用序列描述一下:
- 一个AppClassLoader查找资源时,先看看缓存是否有,缓存有从缓存中获取,否则委托给父加载器。
- 递归,重复第1部的操作。
- 如果ExtClassLoader也没有加载过,则由Bootstrap ClassLoader出面,它首先查找缓存,如果没有找到的话,就去找自己的规定的路径下,也就是
sun.mic.boot.class下面的路径。找到就返回,没有找到,让子加载器自己去找。 - Bootstrap ClassLoader如果没有查找成功,则ExtClassLoader自己在
java.ext.dirs路径中去查找,查找成功就返回,查找不成功,再向下让子加载器找。 - ExtClassLoader查找不成功,AppClassLoader就自己查找,在
java.class.path路径下查找。找到就返回。如果没有找到就让子类找,如果没有子类会怎么样?抛出各种异常。
上面的序列,详细说明了双亲委托的加载流程。我们可以发现委托是从下向上,然后具体查找过程却是自上至下。
我说过上面用时序图画的让自己不满意,现在用框图,最原始的方法再画一次。
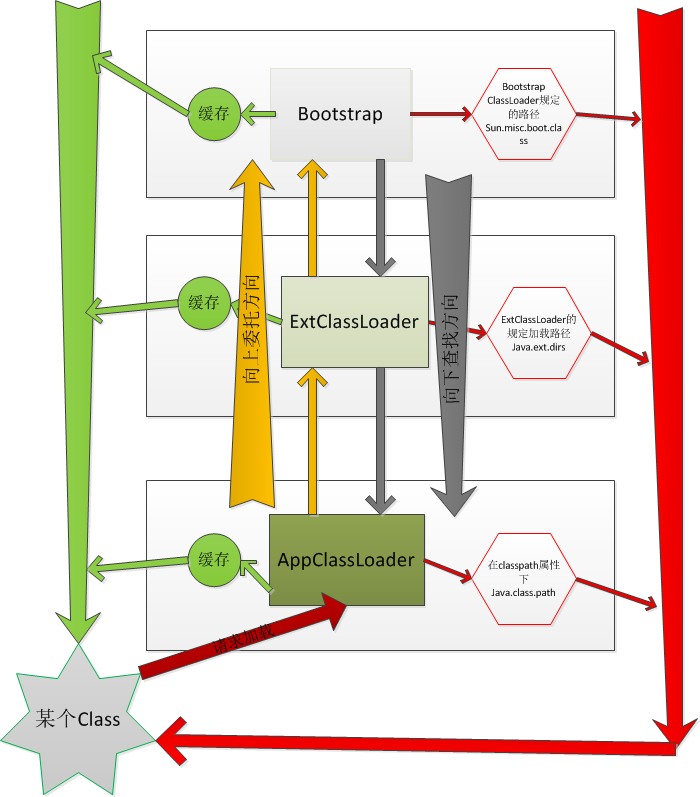
上面已经详细介绍了加载过程,但具体为什么是这样加载,我们还需要了解几个个重要的方法loadClass()、findLoadedClass()、findClass()、defineClass()。
重要方法
loadClass()
JDK文档中是这样写的,通过指定的全限定类名加载class,它通过同名的loadClass(String,boolean)方法。
protected Class<?> loadClass(String name,
boolean resolve)
throws ClassNotFoundException
上面是方法原型,一般实现这个方法的步骤是
- 执行
findLoadedClass(String)去检测这个class是不是已经加载过了。 - 执行父加载器的
loadClass方法。如果父加载器为null,则jvm内置的加载器去替代,也就是Bootstrap ClassLoader。这也解释了ExtClassLoader的parent为null,但仍然说Bootstrap ClassLoader是它的父加载器。 - 如果向上委托父加载器没有加载成功,则通过
findClass(String)查找。
如果class在上面的步骤中找到了,参数resolve又是true的话,那么loadClass()又会调用resolveClass(Class)这个方法来生成最终的Class对象。 我们可以从源代码看出这个步骤。
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 首先,检测是否已经加载
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
//父加载器不为空则调用父加载器的loadClass
c = parent.loadClass(name, false);
} else {
//父加载器为空则调用Bootstrap Classloader
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
//父加载器没有找到,则调用findclass
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
//调用resolveClass()
resolveClass(c);
}
return c;
}
}
代码解释了双亲委托。
另外,要注意的是如果要编写一个classLoader的子类,也就是自定义一个classloader,建议覆盖findClass()方法,而不要直接改写loadClass()方法。
另外
if (parent != null) {
//父加载器不为空则调用父加载器的loadClass
c = parent.loadClass(name, false);
} else {
//父加载器为空则调用Bootstrap Classloader
c = findBootstrapClassOrNull(name);
}
前面说过ExtClassLoader的parent为null,所以它向上委托时,系统会为它指定Bootstrap ClassLoader。
自定义ClassLoader
不知道大家有没有发现,不管是Bootstrap ClassLoader还是ExtClassLoader等,这些类加载器都只是加载指定的目录下的jar包或者资源。如果在某种情况下,我们需要动态加载一些东西呢?比如从D盘某个文件夹加载一个class文件,或者从网络上下载class主内容然后再进行加载,这样可以吗?
如果要这样做的话,需要我们自定义一个classloader。
自定义步骤
- 编写一个类继承自ClassLoader抽象类。
- 复写它的
findClass()方法。 - 在
findClass()方法中调用defineClass()。
defineClass()
这个方法在编写自定义classloader的时候非常重要,它能将class二进制内容转换成Class对象,如果不符合要求的会抛出各种异常。
注意点:
**一个ClassLoader创建时如果没有指定parent,那么它的parent默认就是AppClassLoader。 **
上面说的是,如果自定义一个ClassLoader,默认的parent父加载器是AppClassLoader,因为这样就能够保证它能访问系统内置加载器加载成功的class文件。
自定义ClassLoader示例之DiskClassLoader。
假设我们需要一个自定义的classloader,默认加载路径为D:\lib下的jar包和资源。
我们写编写一个测试用的类文件,Test.java
Test.java
package com.frank.test;
public class Test {
public void say(){
System.out.println("Say Hello");
}
}
然后将它编译过年class文件Test.class放到D:\lib这个路径下。
DiskClassLoader
我们编写DiskClassLoader的代码。
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class DiskClassLoader extends ClassLoader {
private String mLibPath;
public DiskClassLoader(String path) {
// TODO Auto-generated constructor stub
mLibPath = path;
}
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
// TODO Auto-generated method stub
String fileName = getFileName(name);
File file = new File(mLibPath,fileName);
try {
FileInputStream is = new FileInputStream(file);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
int len = 0;
try {
while ((len = is.read()) != -1) {
bos.write(len);
}
} catch (IOException e) {
e.printStackTrace();
}
byte[] data = bos.toByteArray();
is.close();
bos.close();
return defineClass(name,data,0,data.length);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return super.findClass(name);
}
//获取要加载 的class文件名
private String getFileName(String name) {
// TODO Auto-generated method stub
int index = name.lastIndexOf('.');
if(index == -1){
return name+".class";
}else{
return name.substring(index+1)+".class";
}
}
}
我们在findClass()方法中定义了查找class的方法,然后数据通过defineClass()生成了Class对象。
测试
现在我们要编写测试代码。我们知道如果调用一个Test对象的say方法,它会输出"Say Hello"这条字符串。但现在是我们把Test.class放置在应用工程所有的目录之外,我们需要加载它,然后执行它的方法。具体效果如何呢?我们编写的DiskClassLoader能不能顺利完成任务呢?我们拭目以待。
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class ClassLoaderTest {
public static void main(String[] args) {
// TODO Auto-generated method stub
//创建自定义classloader对象。
DiskClassLoader diskLoader = new DiskClassLoader("D:\\lib");
try {
//加载class文件
Class c = diskLoader.loadClass("com.frank.test.Test");
if(c != null){
try {
Object obj = c.newInstance();
Method method = c.getDeclaredMethod("say",null);
//通过反射调用Test类的say方法
method.invoke(obj, null);
} catch (InstantiationException | IllegalAccessException
| NoSuchMethodException
| SecurityException |
IllegalArgumentException |
InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
我们点击运行按钮,结果显示。

可以看到,Test类的say方法正确执行,也就是我们写的DiskClassLoader编写成功。
回首
讲了这么大的篇幅,自定义ClassLoader才姗姗来迟。 很多同学可能觉得前面有些啰嗦,但我按照自己的思路,我觉得还是有必要的。因为我是围绕一个关键字进行讲解的。
关键字是什么?
关键字 路径
- 从开篇的环境变量
- 到3个主要的JDK自带的类加载器
- 到自定义的ClassLoader
它们的关联部分就是路径,也就是要加载的class或者是资源的路径。
BootStrap ClassLoader、ExtClassLoader、AppClassLoader都是加载指定路径下的jar包。如果我们要突破这种限制,实现自己某些特殊的需求,我们就得自定义ClassLoader,自已指定加载的路径,可以是磁盘、内存、网络或者其它。
所以,你说路径能不能成为它们的关键字?
当然上面的只是我个人的看法,可能不正确,但现阶段,这样有利于自己的学习理解。
自定义ClassLoader还能做什么?
突破了JDK系统内置加载路径的限制之后,我们就可以编写自定义ClassLoader,然后剩下的就叫给开发者你自己了。你可以按照自己的意愿进行业务的定制,将ClassLoader玩出花样来。
玩出花之Class解密类加载器
常见的用法是将Class文件按照某种加密手段进行加密,然后按照规则编写自定义的ClassLoader进行解密,这样我们就可以在程序中加载特定了类,并且这个类只能被我们自定义的加载器进行加载,提高了程序的安全性。
下面,我们编写代码。
1.定义加密解密协议
加密和解密的协议有很多种,具体怎么定看业务需要。在这里,为了便于演示,我简单地将加密解密定义为异或运算。当一个文件进行异或运算后,产生了加密文件,再进行一次异或后,就进行了解密。
2.编写加密工具类
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileUtils {
public static void test(String path){
File file = new File(path);
try {
FileInputStream fis = new FileInputStream(file);
FileOutputStream fos = new FileOutputStream(path+"en");
int b = 0;
int b1 = 0;
try {
while((b = fis.read()) != -1){
//每一个byte异或一个数字2
fos.write(b ^ 2);
}
fos.close();
fis.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
我们再写测试代码
FileUtils.test("D:\\lib\\Test.class");
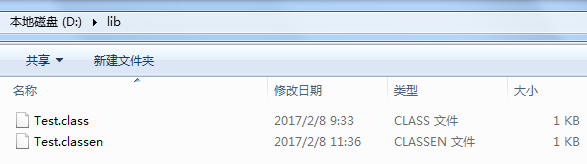
然后可以看见路径D:\\lib\\Test.class下Test.class生成了Test.classen文件。
编写自定义classloader,DeClassLoader
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class DeClassLoader extends ClassLoader {
private String mLibPath;
public DeClassLoader(String path) {
// TODO Auto-generated constructor stub
mLibPath = path;
}
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
// TODO Auto-generated method stub
String fileName = getFileName(name);
File file = new File(mLibPath,fileName);
try {
FileInputStream is = new FileInputStream(file);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
int len = 0;
byte b = 0;
try {
while ((len = is.read()) != -1) {
//将数据异或一个数字2进行解密
b = (byte) (len ^ 2);
bos.write(b);
}
} catch (IOException e) {
e.printStackTrace();
}
byte[] data = bos.toByteArray();
is.close();
bos.close();
return defineClass(name,data,0,data.length);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return super.findClass(name);
}
//获取要加载 的class文件名
private String getFileName(String name) {
// TODO Auto-generated method stub
int index = name.lastIndexOf('.');
if(index == -1){
return name+".classen";
}else{
return name.substring(index+1)+".classen";
}
}
}
测试
我们可以在ClassLoaderTest.java中的main方法中如下编码:
DeClassLoader diskLoader = new DeClassLoader("D:\\lib");
try {
//加载class文件
Class c = diskLoader.loadClass("com.frank.test.Test");
if(c != null){
try {
Object obj = c.newInstance();
Method method = c.getDeclaredMethod("say",null);
//通过反射调用Test类的say方法
method.invoke(obj, null);
} catch (InstantiationException | IllegalAccessException
| NoSuchMethodException
| SecurityException |
IllegalArgumentException |
InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
查看运行结果是:
可以看到了,同样成功了。现在,我们有两个自定义的ClassLoader:DiskClassLoader和DeClassLoader,我们可以尝试一下,看看DiskClassLoader能不能加载Test.classen文件也就是Test.class加密后的文件。
我们首先移除D:\\lib\\Test.class文件,只剩下一下Test.classen文件,然后进行代码的测试。
DeClassLoader diskLoader1 = new DeClassLoader("D:\\lib");
try {
//加载class文件
Class c = diskLoader1.loadClass("com.frank.test.Test");
if(c != null){
try {
Object obj = c.newInstance();
Method method = c.getDeclaredMethod("say",null);
//通过反射调用Test类的say方法
method.invoke(obj, null);
} catch (InstantiationException | IllegalAccessException
| NoSuchMethodException
| SecurityException |
IllegalArgumentException |
InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
DiskClassLoader diskLoader = new DiskClassLoader("D:\\lib");
try {
//加载class文件
Class c = diskLoader.loadClass("com.frank.test.Test");
if(c != null){
try {
Object obj = c.newInstance();
Method method = c.getDeclaredMethod("say",null);
//通过反射调用Test类的say方法
method.invoke(obj, null);
} catch (InstantiationException | IllegalAccessException
| NoSuchMethodException
| SecurityException |
IllegalArgumentException |
InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
运行结果:
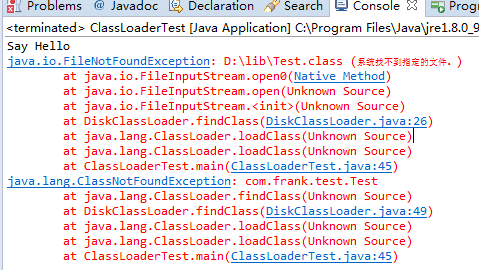
我们可以看到。DeClassLoader运行正常,而DiskClassLoader却找不到Test.class的类,并且它也无法加载Test.classen文件。
Context ClassLoader 线程上下文类加载器
前面讲到过Bootstrap ClassLoader、ExtClassLoader、AppClassLoader,现在又出来这么一个类加载器,这是为什么?
前面三个之所以放在前面讲,是因为它们是真实存在的类,而且遵从”双亲委托“的机制。而ContextClassLoader其实只是一个概念。
查看Thread.java源码可以发现
public class Thread implements Runnable {
/* The context ClassLoader for this thread */
private ClassLoader contextClassLoader;
public void setContextClassLoader(ClassLoader cl) {
SecurityManager sm = System.getSecurityManager();
if (sm != null) {
sm.checkPermission(new RuntimePermission("setContextClassLoader"));
}
contextClassLoader = cl;
}
public ClassLoader getContextClassLoader() {
if (contextClassLoader == null)
return null;
SecurityManager sm = System.getSecurityManager();
if (sm != null) {
ClassLoader.checkClassLoaderPermission(contextClassLoader,
Reflection.getCallerClass());
}
return contextClassLoader;
}
}
contextClassLoader只是一个成员变量,通过setContextClassLoader()方法设置,通过getContextClassLoader()设置。
每个Thread都有一个相关联的ClassLoader,默认是AppClassLoader。并且子线程默认使用父线程的ClassLoader除非子线程特别设置。
我们同样可以编写代码来加深理解。
现在有2个SpeakTest.class文件,一个源码是
package com.frank.test;
public class SpeakTest implements ISpeak {
@Override
public void speak() {
// TODO Auto-generated method stub
System.out.println("Test");
}
}
它生成的SpeakTest.class文件放置在D:\\lib\\test目录下。
另外ISpeak.java代码
package com.frank.test;
public interface ISpeak {
public void speak();
}
然后,我们在这里还实现了一个SpeakTest.java
package com.frank.test;
public class SpeakTest implements ISpeak {
@Override
public void speak() {
// TODO Auto-generated method stub
System.out.println("I\' frank");
}
}
它生成的SpeakTest.class文件放置在D:\\lib目录下。
然后我们还要编写另外一个ClassLoader,DiskClassLoader1.java这个ClassLoader的代码和DiskClassLoader.java代码一致,我们要在DiskClassLoader1中加载位置于D:\\lib\\test中的SpeakTest.class文件。
测试代码:
DiskClassLoader1 diskLoader1 = new DiskClassLoader1("D:\\lib\\test");
Class cls1 = null;
try {
//加载class文件
cls1 = diskLoader1.loadClass("com.frank.test.SpeakTest");
System.out.println(cls1.getClassLoader().toString());
if(cls1 != null){
try {
Object obj = cls1.newInstance();
//SpeakTest1 speak = (SpeakTest1) obj;
//speak.speak();
Method method = cls1.getDeclaredMethod("speak",null);
//通过反射调用Test类的speak方法
method.invoke(obj, null);
} catch (InstantiationException | IllegalAccessException
| NoSuchMethodException
| SecurityException |
IllegalArgumentException |
InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
DiskClassLoader diskLoader = new DiskClassLoader("D:\\lib");
System.out.println("Thread "+Thread.currentThread().getName()+" classloader: "+Thread.currentThread().getContextClassLoader().toString());
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Thread "+Thread.currentThread().getName()+" classloader: "+Thread.currentThread().getContextClassLoader().toString());
// TODO Auto-generated method stub
try {
//加载class文件
// Thread.currentThread().setContextClassLoader(diskLoader);
//Class c = diskLoader.loadClass("com.frank.test.SpeakTest");
ClassLoader cl = Thread.currentThread().getContextClassLoader();
Class c = cl.loadClass("com.frank.test.SpeakTest");
// Class c = Class.forName("com.frank.test.SpeakTest");
System.out.println(c.getClassLoader().toString());
if(c != null){
try {
Object obj = c.newInstance();
//SpeakTest1 speak = (SpeakTest1) obj;
//speak.speak();
Method method = c.getDeclaredMethod("speak",null);
//通过反射调用Test类的say方法
method.invoke(obj, null);
} catch (InstantiationException | IllegalAccessException
| NoSuchMethodException
| SecurityException |
IllegalArgumentException |
InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}).start();
结果如下:
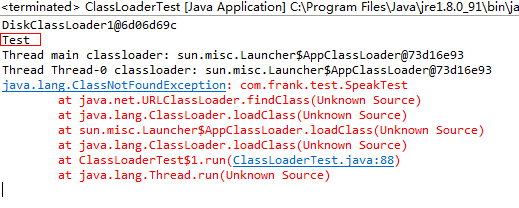
我们可以得到如下的信息:
- DiskClassLoader1加载成功了SpeakTest.class文件并执行成功。
- 子线程的ContextClassLoader是AppClassLoader。
- AppClassLoader加载不了父线程当中已经加载的SpeakTest.class内容。
我们修改一下代码,在子线程开头处加上这么一句内容。
Thread.currentThread().setContextClassLoader(diskLoader1);
结果如下:
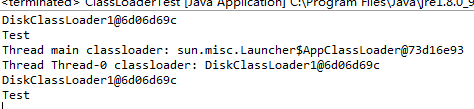
可以看到子线程的ContextClassLoader变成了DiskClassLoader。
继续改动代码:
Thread.currentThread().setContextClassLoader(diskLoader);
结果:
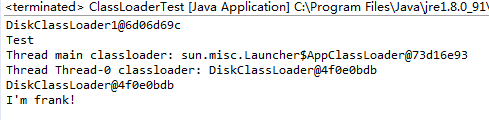
可以看到DiskClassLoader1和DiskClassLoader分别加载了自己路径下的SpeakTest.class文件,并且它们的类名是一样的com.frank.test.SpeakTest,但是执行结果不一样,因为它们的实际内容不一样。
Context ClassLoader的运用时机
其实这个我也不是很清楚,我的主业是Android,研究ClassLoader也是为了更好的研究Android。网上的答案说是适应那些Web服务框架软件如Tomcat等。主要为了加载不同的APP,因为加载器不一样,同一份class文件加载后生成的类是不相等的。如果有同学想多了解更多的细节,请自行查阅相关资料。
总结
- ClassLoader用来加载class文件的。
- 系统内置的ClassLoader通过双亲委托来加载指定路径下的class和资源。
- 可以自定义ClassLoader一般覆盖findClass()方法。
- ContextClassLoader与线程相关,可以获取和设置,可以绕过双亲委托的机制。
下一步
- 你可以研究ClassLoader在Web容器内的应用了,如Tomcat。
- 可以尝试以这个为基础,继续学习Android中的ClassLoader机制。
引用
我这篇文章写了好几天,修修改改,然后加上自己的理解。参考了下面的这些网站。
3 - 汇编
3.1 - 汇编入门
汇编语言入门转发于https://zhuanlan.zhihu.com/p/23618489 \n 示例代码 https://gitee.com/azhw/rookiedev-example/tree/master/%E7%BC%96%E7%A8%8B/%E7%BC%96%E7%A8%8B%E8%AF%AD%E8%A8%80/%E6%B1%87%E7%BC%96/%E6%B1%87%E7%BC%96%E5%85%A5%E9%97%A8
3.1.1 - 汇编语言入门一:环境准备
现阶段,找个方便好使的编程环境还是比较蛋疼的,对于部分想过瘾或者想从学习实践中学习的小伙伴来说,略显蛋疼。不过,仔细琢磨,还是能够自己折腾出一个好用的环境来的。开搞。
环境
- Ubuntu
- gcc/nasm
也就是说,你先安装一个能正常使用的Ubuntu再说吧,然后顺便熟悉一些相关的概念和操作。
后面若没有特殊说明,那我们讨论的问题都是在这个软件环境下。
环境检查
先打开终端,安装所需软件(注意$开头的才是命令,并且$并不属于命令的一部分):
$ sudo apt-get install gcc nasm vim gcc-multilib -y
在终端中分别执行which nasm和which gcc,得到如下结果,则表示环境已经安装完毕。
$ which nasm
/usr/bin/nasm
$ which gcc
/usr/bin/gcc
开始第一个程序
在汇编语言环境下,我们先别急着搞什么Hello World,在这里要打印出Hello World还不是一个简单的事情,这也算是初入汇编比较让人不解的地方,成天都在扯什么寄存器寻址啥的,说好的变量分支循环函数呢?
别说话,先按照我的套路把环境配好,程序跑起来了再说。注意,不是Hello World。先亮出第一个程序的C语言等价代码:
int main() {
return 0;
}
不好意思,大括号没换行。你以为接下来我要gcc -S吗?Too naive。我这可是正宗手工艺,非机械化生产。
说正事,先一股脑啥都不知道地把代码敲完,跑起来再说:
首先准备个文件,暂且叫做first.asm吧,然后把下面的代码搞进去:
global main
main:
mov eax, 0
ret
好了程序写完了,你能感受到这里的0就是上面C代码里的0,说明你有学习汇编的天赋。
OK接下来就要编译运行了。来一堆命令先:
$ nasm -f elf first.asm -o first.o
$ gcc -m32 first.o -o first
这下,程序就编译好了,像这样:
$ ls
first first.asm first.o
好了我们运行一下:
$ ./first ; echo $?
别问我为何上面的命令后面多了一串奇怪的代码,你自己把它删掉之后再看就能猜出来是干啥的了。如果还有疑惑,可以再次做实验确认,比如把代码里的0改成1。变成这样:
global main
main:
mov eax, 1
ret
再按照同样的套路来编译运行:
$ nasm -f elf first.asm -o first.o
$ gcc -m32 first.o -o first
$ ./first ; echo $?
1
OK,咱们的环境准备工作大功告成,后面再细说该怎么搞事情(心情好的话还有ARM版的哦,准备好ARM环境或者买个树莓派吧)。
3.1.2 - 汇编语言入门二:环境有了先过把瘾
上回说到,咱们把环境搭好了,可以开始玩耍汇编了。
寄存器是啥玩意儿?
开始学C的时候,有没有一种感觉,变量?类型?我可是要改变世界的男人,怎么就成天在跟i++较劲啊?这黑框程序还只能用来算数学,跟说好的不一样呢???想必后来,见得多了,你的想法也不那么幼稚了吧。
好了,接下来汇编也会给你同样一种感觉的。啥玩意儿?寄存器?寻址?说好的变量类型循环函数呢?。
好了,我想先刻意避开这些晦涩难懂的东西,找到感觉了,再回头来研究条条框框。在此先把基本的几个简单的东西弄熟练,过早引入太多概念容易让人头昏眼花。
这里就说寄存器,通俗地来解释一下。回到上小学的时候,现在有一大堆计算题:
99+10=
32-20=
14+21=
47-9=
87+3=
86-8=
...
正常来讲,要算出这个么多题目,你需要一支笔,一边计算的同时一边把结果写下来。
好了,到这里,我就来做个类比,助你大致理解寄存器是干啥用的。首先,我们把CPU和大脑做一个类比。
你在纸上进行计算的时候,需要不断往纸上写下计算结果,一边在脑子里进行计算。大致过程就像:
1. 在纸上找一个题目,先看清两个数字,并迅速记下来
2. 在脑子里对这两个数字进行计算,计算出的结果也是记在脑子里的
3. 将计算结果写在纸上,继续做下一个题目
好了,这个过程就和计算机执行的过程有几分相似。草稿纸就相当于是个内存,脑子就是CPU。
在计算的时候,你需要知道计算的两个数字,而且还得知道是做什么运算,这些信息都是从草稿纸上看见之后,短暂记忆在脑子里的。
CPU在计算的时候也是一样,需要知道要计算的数据是什么,还得知道是做什么运算,这些信息也需要临时保存在CPU的某个地方。这个地方就是寄存器。
好了到这里,不知道你有没有看明白?也就是说CPU里头的寄存器的作用,就像我们在做计算的时候会临时在脑子里记住数字一样。当然你的脑子能记住不止一个数据,CPU也不止一个寄存器。
为啥C语言里没有说这些?
就是因为写汇编语言的时候,要在有限的寄存器情况下,编写复杂的程序,还要考虑灵活性、性能、正确性等等乱七八糟的问题,对于程序员是一个超级大的负担。
因此有人专门发明了许多更方便好用的“高级语言”,然后还专门写了个配套的程序能够把用这个“高级语言”写的东西翻译成汇编语言,再将汇编语言翻译成机器能执行的指令。其中之一就是C语言。也就是C语言发明出来就是奔着比汇编语言好用的目标去的。所以啊,相比汇编这种繁琐复杂的编程方式,高级语言不知道高级到哪里去了。
那学习汇编语言有用吗?
没有。
开始一顿乱写
好了,先介绍个程序,运行完了能够开心一下:
global main
main:
mov eax, 1
mov ebx, 2
add eax, ebx
ret
老套路,保存成文件,比如叫做nmb.asm,然后编译运行:
$ nasm -f elf nmb.asm -o nmb.o
$ gcc -m32 nmb.o -o nmb
$ ./nmb ; echo $?
3
如果你能看出来这里面的端倪,说明你是一个聪明伶俐的天才。不就是做了个算术题1+2=3么。
好了我们来看一下这个程序。里面的eax就是指代的寄存器。同理ebx也是一个寄存器。也就是这个CPU在做计算题的时候至少能够记住两个数字,实际上,它有更多寄存器,稍后再慢慢说。
OK。既然找到一些感觉了,就继续胡乱地拍出一大堆程序来先玩个够吧:
global main
main:
mov eax, 1
add eax, 2
add eax, 3
add eax, 4
add eax, 5
ret
global main
main:
mov eax, 1
mov ebx, 2
mov ecx, 3
mov edx, 4
add eax, ebx
add eax, ecx
add eax, edx
ret
至于这两个程序是什么结果,你自己玩吧。不动手练练怎么学得好。
指令
指令就像是你发给CPU的一个个命令,你让它做啥它就做啥。当然了,前提是CPU得支持对应的功能,CPU是没有“吃饭”功能的,你也写不出让它”吃饭“的指令来。
前面我们共用到了三个指令:分别是mov、add、ret。
我来逐个解释这些指令:
- mov
数据传送指令,我们可以像下面这样用mov指令,达到数据传送的目的。
mov eax, 1 ; 让eax的值为1(eax = 1)
mov ebx, 2 ; 让ebx的值为2(ebx = 2)
mov ecx, eax ; 把eax的值传送给ecx(ecx = eax)
- add
加法指令
add eax, 2 ; eax = eax + 2
add ebx, eax ; ebx = ebx + eax
- ret
返回指令,类似于C语言中的return,用于函数调用后的返回(后面细说)。
为啥指令长得这么丑?和我想的不一样?
首先,CPU里是一坨电路,有的功能对于人来说可能很简单,但是对于想要用电路来实现这个功能的人来说,就不一定简单了。这是需要明白的第一个道理。
所以啊,这长得丑是有原因的。其中一个原因就是,某些长的漂亮的功能用电路实现起来超级麻烦,所以干脆设计丑一点,反正到时候这些古怪的指令能够组合出我想要的功能,也就足够了。
所以,汇编语言蛋疼就在这些地方:
- 为了迁就电路的设计,很多指令不一定会按照朴素的思维方式去设计
- 需要知道CPU的工作原理,否则都不知道该怎么组织程序
- 程序复杂之后,连我自己都看不懂了,虽然能够运行得到正确的结果
- …
按道理,随着技术的发展,指令应该越来越好看,越来越符合人的思考方式才对啊。然而,世事难料,自从出现了高级语言,多数编程场景下,已经不需要关心指令和寄存器到底长啥样了,这个事情已经由编译器代劳了,99%甚至更多的程序员不需关心寄存器和指令了。所以,长得不好看就算了,反正也没什么人看。
好了,按照前面的介绍,接下来再继续了解一些东西:
更多指令、更多寄存器
- sub
减法指令(用法和加法指令类似)
sub eax, 1 ; eax = eax - 1
sub eax, ecx ; eax = eax - ecx
乘法和除法、以及更多的运算,这里就不再介绍了,这里的重点是为汇编学习带路。
- 更多寄存器
除了前面列举的eax、ebx、ecx、edx之外,还有一些寄存器:
esi
edi
ebp
其中eax、ebx、ecx、edx这四个寄存器是通用寄存器,可以随便存放数据,也能参与到大多数的运算。而余下的三个多见于一些访问内存的场景下,不过,目前,你还是可以随便抓住一个就拿来用的。
总结
到这里,赶紧根据前面了解的东西,多写几遍吧,加深一下印象。
前面说的学习汇编没用,是瞎说的。学习汇编有用,后面想起来了再说。
3.1.3 - 汇编语言入门三:是时候上内存了
上回说到了寄存器和指令,这回说下内存访问。开始之前,先来复习一下。
回顾
寄存器
- 寄存器是在CPU里面
- 寄存器的存储空间很小
- 寄存器存放的是CPU马上要处理的数据或者刚处理出的结果(还是热乎的)
指令
- 传送数据用的指令mov
- 做加法用的指令add
- 做减法用的指令sub
- 函数调用后返回的指令ret
指针和内存
高能预警
高能预警,后面会涉及到一些高难度动作,请提前做好以下准备:
- 精通2进制和16进制加减法
- 精通2进制表示与16进制表示之间的关系
- 精通8位、16位、32位、64位二进制数的16进制表示
举个例子,一个16进制数0BC71820,其二进制表示为:
00001011 11000111 00011000 00100000
你能快速地找到它们之间的对应关系吗?不会的话快去复习吧。
寄存器宽度
现在,为了简便,我们只讨论32位宽的寄存器。也就是说,目前我们讨论的寄存器,它的宽度都是32位的,也就是里面存放了一个32位长的2进制数。
通常,一个字节为8个二进制比特位,那么一个32位长的二进制数,那么它的大小就应该是4个字节。也就是把32位长的寄存器写入到内存里,会覆盖掉四个字节的存储空间。
内存
想必内存大家心里都比较有数,就是暂时存放CPU计算所需的指令和数据的地方。
诶?那前面说好的寄存器呢?寄存器也是类似的功能啊。对的,寄存器有类似功能,理论上一个最小的计算系统只需要寄存器和CPU的计算部件(ALU)就够了。不过,实际情况更加复杂一些,还是拿计算题举例,这次更复杂了:
(这里的例子只够说明寄存器和内存的角色区别,而非出现内存和寄存器这样角色的根本原因)
( 847623785 * 12874873 + 274632 ) / 999 =
好了,这个题目就不像前面的那么简单了,首先你肯定没法直接在脑子里三两下就算出来,还是得需要一个草稿纸了。
计算过程中,你还是会把草稿纸上正在计算的几个数字记在脑子里,然后快速地算完并记下来,然后往草稿纸上写。
最后,在草稿纸上演算完毕后,你会把最终结果写到试卷上。
好了,这里的草稿纸就相当于是内存了。它也充当一个临时记录数据的作用,不过它的容量就比自己的脑子要大得多了,而且一旦你把东西写下来,也就不那么担心忘记了。
诶?我不能多做点寄存器,就不需要单独的内存了呀?是的,理论上是这样,然而,实际上如果多做一点寄存器的话,CPU就要卖$9999999一片了,贵啊(具体原因可以了解SRAM与DRAM)。
也就是说,在计算机系统里,寄存器和内存都充当临时存储用,但是寄存器太小也太少了,内存就能帮个大忙了。
指针
在C语言里面,有个神奇的东西叫做指针,它是初学者的噩梦,也是高手的天堂。
这里不打算给不明白指针的人讲个明白,直接进入正题。首先,内存是一个比较大的存储器,里面可以存放非常非常多的字节。
好了,现在我们来为整个内存的所有字节编号,为了方便,咱们首先考虑按照字节为单位连续编号:
0 1 2 3 4 5 6 7 ...
......................... ......................
|12|b7|33|e8|66|4c|87|3c| ... |cc|cc|cc|cc|cc|cd|cd|
````````````````````````` ``````````````````````
大概意思一下,你可以想象每一个格子就是一个字节,每个格子都有编号,相邻的格子的编号也是相邻的。这个编号,你就可以理解为所谓的指针或者地址(这里不严格区分指针与地址)。那么当我需要获取某个位置的数据时,那么我们只需要一个编号(也就是地址)就知道在哪些格子里获取数据了,当然,写入数据也是一样的道理。
到这里,我们大概清楚了访问内存的时候需要一些什么东西:
- 首先得有内存
- 要访问内存的哪个位置(编号,地址)
那,我哪知道地址是多少呢?别介,这不是重点,你不需要知道地址具体是多少,你只需要知道它是个地址,按照正确的方式去思考和使用就行了。继续。
mov指令还没完
前面说到,寄存器可以临时存储计算所需数据和结果,那么,问题来了,寄存器也就那么几个,用完了咋办?你能发现这个问题,说明你有成为大佬的潜质。接下来,说正事。
前面说到了mov指令,可以将数据送入寄存器,也可以将一个寄存器的数据送到另一个寄存器,像这样:
mov eax, 1
mov ebx, eax
好了,这还没完,mov指令可谓是x86中花样比较多的指令了,前面的两种情形都还是比较简单的情形,今天我们来扯一下更复杂的。
寄存器不够用了
现在,某个很复杂的运算让你感觉寄存器不够用了,怎么办?按照前面说的意思,要把寄存器的东西放到内存里去,把寄存器的空间腾出来,就可以了。
好的思路有了,可是,怎么把寄存器的数据丢到内存里去呢?还是使用mov指令,只是写法不同了:
mov [0x5566], eax
好了,现在,请全神贯注。这条指令就是将寄存器的数据丢到内存里去。再多看几眼,免得看得不够顺眼:
mov [0x0699], eax
mov [0x0998], ebx
mov [0x1299], ecx
mov [0x1499], edx
mov [0x1999], esi
好了,应该已经脸熟了。
现在,我告诉你,最前面那个指令mov [0x5566], eax的作用:
将eax寄存器的值,保存到编号为0x5566对应的内存里去,按照前面的说法,一个eax需要4个字节的空间才装得下,所以编号为0x5566 0x5567 0x5568 0x5569这四个字节都会被eax的某一部分覆盖掉。
好了,我们已经了解了如何将一个寄存器的值保存到内存里去,那么我怎么把它取出来呢?
mov eax, [0x0699]
mov ebx, [0x0998]
mov ecx, [0x1299]
mov edx, [0x1499]
mov esi, [0x1999]
反过来写就是了,比如mov eax, [0x0699]就表示把0x0699这个地址对应那片内存区域中的后4个字节取出来放到eax里面去。
到此
到这,我们已经学会了如何把寄存器的数据临时保存到内存里,也知道怎么把内存里的数据重新放回寄存器了。
动手编程
接下来,该动手操练了。先来一个题目:
假设我们现在有一个比较蛋疼的要求,就是把1和2相加,然后把结果放到内存里面,最后再把内存里的结果取出来。(好无聊的题目)
那么按理说,我们就应该这么写代码:
global main
main:
mov ebx, 1
mov ecx, 2
add ebx, ecx
mov [0x233], ebx
mov eax, [0x233]
ret
好了,编译运行,假如程序是danteng,那么运行结果应该是这样:
$ ./danteng ; echo $?
3
实际上,并不能行。程序挂了,没有输出我们想要的结果。
这是在逗我呢?别急,按理说,前面说的都是没问题的,只是这里有另外一个问题,那就是“我们的程序运行在一个受管控的环境下,是不能随便读写内存的”。这里需要特殊处理一下,至于具体为何,后面有机会再慢慢叙述,这不是当下的重点,先照抄就是了。
程序应该改成这样才行:
global main
main:
mov ebx, 1
mov ecx, 2
add ebx, ecx
mov [sui_bian_xie], ebx
mov eax, [sui_bian_xie]
ret
section .data
sui_bian_xie dw 0
好了这下运行,我们得到了结果:
$ ./danteng ; echo $?
3
好了,有了程序,咱们来梳理一下每一条语句的功能:
mov ebx, 1 ; 将ebx赋值为1
mov ecx, 2 ; 将ecx赋值为2
add ebx, ecx ; ebx = ebx + ecx
mov [sui_bian_xie], ebx ; 将ebx的值保存起来
mov eax, [sui_bian_xie] ; 将刚才保存的值重新读取出来,放到eax中
ret ; 返回,整个程序最后的返回值,就是eax中的值
好了,到这里想必你基本也明白是怎么一回事了,有几点需要专门注意的:
- 程序返回时eax寄存器的值,便是整个程序退出后的返回值,这是当下我们使用的这个环境里的一个约定,我们遵守便是
与前面那个崩溃的程序相比,后者有一些微小的变化,还多了两行代码
section .data
sui_bian_xie dw 0
第一行先不管是表示接下来的内容经过编译后,会放到可执行文件的数据区域,同时也会随着程序启动的时候,分配对应的内存。
第二行就是描述真实的数据的关键所在里,这一行的意思是开辟一块4字节的空间,并且里面用0填充。这里的dw(double word)就表示4个字节,前面那个sui_bian_xie的意思就是这里可以随便写,也就是起个名字而已,方便自己写代码的时候区分,这个sui_bian_xie会在编译时被编译器处理成一个具体的地址,我们无需理会地址具体时多少,反正知道前后的sui_bian_xie指代的是同一个东西就行了。
疯狂的写代码
好了,有了这一个程序作铺垫,我们继续。趁热打铁,继续写代码,分析代码:
global main
main:
mov ebx, [number_1]
mov ecx, [number_2]
add ebx, ecx
mov [result], ebx
mov eax, [result]
ret
section .data
number_1 dw 10
number_2 dw 20
result dw 0
好了,自己琢磨着写代码,运行程序,然后分析程序每一条指令都在干什么。还有,这个程序本身还可以精简,如果你已经发现了,那说明你老T*棒了。
global main
main:
mov eax, [number_1]
mov ebx, [number_2]
add eax, ebx
ret
section .data
number_1 dw 10
number_2 dw 20
好了,好好分析比较上面的几个程序,基本这一块就了解得差不多了。随着了解的逐渐深入,我们后续还会介绍更多更复杂,更全面的内容。
反汇编
这里插播一段反汇编的讲解。引入调试器和反汇编工具,我们后续将有更多机会对程序进行深入的分析,现阶段,我们先找一个简单的程序上手,熟悉一下操作和工具。
先安装gdb:
$ sudo apt-get install gdb -y
然后,我们把这个程序,保存为test.asm:
global main
main:
mov eax, 1
mov ebx, 2
add eax, ebx
ret
然后编译:
$ nasm -f elf test.asm -o test.o ; gcc -m32 test.o -o test
运行:
$ ./test ; echo $?
3
OK,到这里,程序是对的了。开始动刀子,使用gdb:
$ gdb ./test
启动之后,你会看到终端编程变成这样了:
(gdb)
OK,说明你成功了,接下来输入,并回车:
这里要先run一次,才能开辟真正的内存空间,只要不退出本次gdb,不论run多少次,都还是占用这些内存地址
(gdb) run
Starting program: /home/vagrant/code/asm/03/test
[Inferior 1 (process 408757) exited with code 03]
(gdb) set disassembly-flavor intel
这一步是把反汇编的格式调整称为intel的格式,稍后完事儿后你可以尝试不用这个设置,看看是什么效果。好了,继续,反汇编,输入命令并回车:
(gdb) disas main
Dump of assembler code for function main:
0x080483f0 <+0>: mov eax,0x1
0x080483f5 <+5>: mov ebx,0x2
0x080483fa <+10>: add eax,ebx
0x080483fc <+12>: ret
0x080483fd <+13>: xchg ax,ax
0x080483ff <+15>: nop
End of assembler dump.
(gdb)
好了,整个程序就在这里被反汇编出来了,请你先仔细看一看,是不是和我们写的源代码差不多?(后面多了两行汇编,你把它们当成路人甲看待就行了,不用理它)。
动态调试
后面将继续介绍动态调试,帮助更加深入地理解汇编中的一些概念。现在先提示一些概念:
- 断点:程序在运行过程中,当它执行到“断点”对应的这条语句的时候,就会被强行叫停,等着我们把它看个精光,然后再把它放走
- 注意看反汇编代码,每一行代码的前面都有一串奇怪的数字,这串奇怪的数字指它右边的那条指令在程序运行时的内存中的位置(地址)。注意,指令也是在内存里面的,也有相应的地址。
好了,我们开始尝试一下调试功能,首先是设置一个断点,让程序执行到某一个地方就停下来,给我们足够的时间观察。在gdb的命令行中输入:
(gdb) break *0x080483f5
后面那串奇怪的数字在不同的环境下可能不一样,你可以结合这里的代码,对照着自己的实际情况修改。(使用反汇编中<+5>所在的那一行前面的数字)
然后我们执行程序:
(gdb) run
Starting program: /home/vagrant/code/asm/03/test
Breakpoint 1, 0x080483f5 in main ()
(gdb)
看到了吧,这下程序就被停在了我们设置的断点那个地方,对比着反汇编和你的汇编代码,找一找现在程序是停在哪个位置的吧。run后面提示的内容里,那一串奇怪的数字又出现了,其实这就是我们前面设置断点的那个地址。
好了,到这里,我们就把程序看个精光吧,先看一下eax寄存器的值:
(gdb) info register eax
eax 0x1 1
刚好就是1啊,在我们设置断点的那个地方,它的前面一个指令是mov eax, 1,这时候eax的内容就真的变成1了,同样,你还可以看一下ebx:
info register ebx
ebx 0xf7fce000 -134422528
ebx的值并不是2,这是因为mov ebx, 2这个语句还没有执行,所以暂时你看不到。那我们现在让它执行一下吧:
(gdb) stepi
0x080483fa in main ()
好了,输入stepi之后,到这里,程序在我们的控制之下,向后运行了一条指令,也就是刚刚执行了mov ebx, 2,这时候看下ebx:
(gdb) info register ebx
ebx 0x2 2
看到了吧,ebx已经变成2了。继续,输入stepi,然后看执行了add指令后的各个寄存器的值:
(gdb) stepi
0x080483fc in main ()
(gdb) info register eax
eax 0x3 3
执行完add指令之后,eax跟我们想的一样,变成了3。如果我不知道程序现在停在哪里了,怎么办?很简单,输入disas之后,又能看到反汇编了,同时gdb还会标记出当前断点所在的位置:
(gdb) disas
Dump of assembler code for function main:
0x080483f0 <+0>: mov eax,0x1
0x080483f5 <+5>: mov ebx,0x2
0x080483fa <+10>: add eax,ebx
=> 0x080483fc <+12>: ret
0x080483fd <+13>: xchg ax,ax
0x080483ff <+15>: nop
End of assembler dump.
现在刚好就在add执行过后的ret那个地方。这时候,如果你不想玩了,可以输入continue,让程序自由地飞翔起来,直到GG。
(gdb) continue
Continuing.
[Inferior 1 (process 1283) exited with code 03]
看到了吧,程序已经GG了,而且返回了一个数字03。这刚好就是那个eax寄存器的值嘛。
完整的过程
注意进入gdb后一定要先run一次,这样才会开辟真正的内存空间,之后再看内存分配和设置断点才好用
koala@koala:~/桌面/DesktopHelper/汇编语言入门/03demo$ gdb ./test
GNU gdb (Ubuntu 9.2-0ubuntu1~20.04) 9.2
Copyright (C) 2020 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from ./test...
(No debugging symbols found in ./test)
(gdb) run
Starting program: /media/koala/data/WinUserHome/DesktopFile/DesktopHelper/汇编语言入门/03demo/test
[Inferior 1 (process 408757) exited with code 03]
(gdb) set disassembly-flavor intel
(gdb) disas main
Dump of assembler code for function main:
0x565561a0 <+0>: mov eax,0x1
0x565561a5 <+5>: mov ebx,0x2
0x565561aa <+10>: add eax,ebx
0x565561ac <+12>: ret
0x565561ad <+13>: xchg ax,ax
0x565561af <+15>: nop
End of assembler dump.
(gdb) break *0x565561a5
Breakpoint 1 at 0x565561a5
(gdb) run
Starting program: /media/koala/data/WinUserHome/DesktopFile/DesktopHelper/汇编语言入门/03demo/test
Breakpoint 1, 0x565561a5 in main ()
(gdb) info register eax
eax 0x1 1
(gdb) info register ebx
ebx 0x0 0
(gdb) stepi
0x565561aa in main ()
(gdb) info register ebx
ebx 0x2 2
(gdb) stepi
0x565561ac in main ()
(gdb) info register eax
eax 0x3 3
(gdb) disas
Dump of assembler code for function main:
0x565561a0 <+0>: mov eax,0x1
0x565561a5 <+5>: mov ebx,0x2
0x565561aa <+10>: add eax,ebx
=> 0x565561ac <+12>: ret
0x565561ad <+13>: xchg ax,ax
0x565561af <+15>: nop
End of assembler dump.
(gdb) continue
Continuing.
[Inferior 1 (process 409281) exited with code 03]
总结
好了,这次就到这里结束,内容有点多,没关系可以慢慢来,没事的时候就翻出来,把目前学的汇编语言和gdb都好好玩一下,最好是能玩出花来,这样才能有更多的收获。清点一下今天的内容:
- 通过mov指令可以把内存的数据放到寄存器中,也可以把寄存器的数据放回到内存
- 在操作系统的保护下,程序是不能随便到处访问内存的,乱搞的话会GG
- gdb的功能很牛逼
若读者对文中部分内容有疑惑或是有表达不当或是有疏漏,欢迎指正。
3.1.4 - 汇编语言入门四:打通C和汇编语言
回顾
上回我们把汇编里涉及到的寄存器和内存访问相关的内容说了。先来梳理一下:
- 寄存器是一些超级小的临时存储器,在CPU里面,存放CPU马上就要用到的数据或者刚处理完的结果
- 要处理的数据太多,寄存器装不下了,需要更多寄存器,但是这玩意贵啊
- 内存可以解决上述问题,但是内存相比寄存器要慢,优点是相对便宜,容量也大
插曲:C语言与汇编语言的关系
还有一些疑虑,先暂时解释一下。首先,C语言里编程里,我们从来没有关心过寄存器。汇编语言里突然冒出这么一个东西,学起来好难受。接下来的内容,我们先把C语言和汇编语言的知识,来一次大一统,帮助理解。
首先我们来看一个C语言程序:
int x, y, z;
int main() {
x = 2;
y = 3;
z = x + y;
return z;
}
考虑到我们的汇编教程才刚开始,我这里尽可能先简化C程序,这样稍后涉及到等价的汇编内容时所需的知识都是前面介绍过的。
保存为test01.c文件,先编译运行这个程序:
(注意,这里的gcc带了一个参数-m32,因为我们要编译出32位(x86)的可执行文件)
$ gcc -m32 test01.c -o test01
$ ./test01 ; echo $?
5
好了,在这里,我们的程序返回了一个值:5。
好的,接下来我们看看如果我们要用汇编实现几乎相同的过程,该怎么做?
首先,三个全局变量:
int x, y, z;
总得有吧。(这里之所以会用全局变量,是考虑到局部变量相关的汇编知识还未介绍,先将就一下,后续再说局部变量的内容)
首先,在C语言里,你可以认为每个变量都会占用一定的内存空间,也就是说,这里的x、y、z分别都占用了一个“整型”也就是4字节的存储空间。
上次我们介绍过在汇编里面访问内存的知识,当然,我们也知道了怎么在数据区划出一定的空间,这次我们就照搬前面提及的方法:
global main
main:
mov eax, 0
ret
section .data
x dw 0
y dw 0
z dw 0
这个程序就等价于下面的C代码:
int x, y, z;
int main() {
return 0;
}
也就是现在有了三个全局变量,只是现在汇编程序什么都没做,仅仅返回了0而已。
这里的C代码和上述汇编代码从某种程度上来说,就是完全等价的。甚至,我们的C语言编译器就可以直接把C代码,翻译成上述的汇编代码,余下的工作交给nasm再编译一次,把汇编转化为可执行文件,就能够得到最后的程序了。当然,理论上可以这么做,实际上有的编译器也就是这么做的,只是人家生成的汇编格式不是nasm,而是其它的类型,但是道理都差不多。
也就是说,一个足够精简的C编译器,只需要能够把C代码翻译成汇编代码,剩下的交给汇编器完成,也就能实现完整的C语言编译器了,也就能得到最后的可执行文件了。实际上C编译器是完全可以这么做的,甚至有的就是这么做的。
好了,先不扯这些,我们先把前面的程序补充完整,达到和最前面的C代码等价为止。接下来,我们要关注这个:
x = 2;
y = 3;
也就是要把数字2和3,分别放到x和y对应的内存区域中去。很简单,我们可以这么做:
mov eax, 2
mov [x], eax
mov eax, 3
mov [y], eax
也就是先把2扔到寄存器eax中去,然后把eax中的内容放回到x对应的内存中。同理,y也这样处理。
好了,接下来的加法语句:
z = x + y;
也可以做了:
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
好了,这段代码应该可以看懂吧,简单说一下思路:
- 把x和y对应的内存中的内容分别放到eax和ebx中去
- 进行形如eax = eax + ebx的加法,最终的和存放在eax中
- 再将eax中的内容存放到z对应的内存中去
最后,我们还有一个事情需要处理,也就是返回语句:
return z;
这个也很好办,按照约定,eax中的值,就是函数的返回值:
mov eax, [z]
ret
整个程序就算完了,我们已经完整地将C代码的汇编语言等价形式写出来了,最终的代码是这样的:
global main
main:
mov eax, 2
mov [x], eax
mov eax, 3
mov [y], eax
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret
section .data
x dw 0
y dw 0
z dw 0
来先保存成文件test02.asm,编译运行看看效果:
$ nasm -f elf test02.asm -o test02.o
$ gcc -m32 test02.o -o test02
$ ./test02 ; echo $?
5
搞定。结果完全和前面的C代码一致。
揭开C程序的庐山真面目
你以为自己YY出等价的汇编代码就完事儿了?图样,接下来我们继续用工具一探究竟,玩真的。
先说一下准备工作,首先有下面两个文件:
test01.c test02.asm
其中一个为上面提到的完整C代码,一个为上述完整的汇编代码。然后按照前面的指示,都编译成可执行文件,编译完成后是这样的:
$ gcc -m32 test01.c -o test01
$ nasm -f elf test02.asm -o test02.o
$ gcc -m32 -fno-lto test02.o -o test02
$ ls
test01 test01.c test02 test02.asm test02.o
(注意,要按照这里的编译命令来做)
其中的test01是C代码编译出来的,test02是汇编代码编译出来的。
祭出gdb
好,接下来有请我们的大将军gdb登场。
先来看看我们的C编译后的程序,反汇编之后是什么鬼样子:
gdb ./test01
然后输入命令查看反汇编代码:
(gdb) set disassembly-flavor intel
(gdb) disas main
Dump of assembler code for function main:
0x080483ed <+0>: push ebp
0x080483ee <+1>: mov ebp,esp
0x080483f0 <+3>: mov DWORD PTR ds:0x804a024,0x2
0x080483fa <+13>: mov DWORD PTR ds:0x804a028,0x3
0x08048404 <+23>: mov edx,DWORD PTR ds:0x804a024
0x0804840a <+29>: mov eax,ds:0x804a028
0x0804840f <+34>: add eax,edx
0x08048411 <+36>: mov ds:0x804a020,eax
0x08048416 <+41>: mov eax,ds:0x804a020
0x0804841b <+46>: pop ebp
0x0804841c <+47>: ret
End of assembler dump.
(gdb) quit
$
好,别急,先退出,我们再看看我们汇编程序的反汇编代码:
gdb ./test02
(gdb) set disassembly-flavor intel
(gdb) disas main
0x080483f0 <+0>: mov eax,0x2
0x080483f5 <+5>: mov ds:0x804a01c,eax
0x080483fa <+10>: mov eax,0x3
0x080483ff <+15>: mov ds:0x804a01e,eax
0x08048404 <+20>: mov eax,ds:0x804a01c
0x08048409 <+25>: mov ebx,DWORD PTR ds:0x804a01e
0x0804840f <+31>: add eax,ebx
0x08048411 <+33>: mov ds:0x804a020,eax
0x08048416 <+38>: mov eax,ds:0x804a020
0x0804841b <+43>: ret
0x0804841c <+44>: xchg ax,ax
0x0804841e <+46>: xchg ax,ax
End of assembler dump.
(gdb) quit
好了,我们都看到反汇编代码了。先来检查一下这里test02的反汇编代码,和我们写的汇编代码是不是一致的:
0x080483f0 <+0>: mov eax,0x2
0x080483f5 <+5>: mov ds:0x804a01c,eax
0x080483fa <+10>: mov eax,0x3
0x080483ff <+15>: mov ds:0x804a01e,eax
0x08048404 <+20>: mov eax,ds:0x804a01c
0x08048409 <+25>: mov ebx,DWORD PTR ds:0x804a01e
0x0804840f <+31>: add eax,ebx
0x08048411 <+33>: mov ds:0x804a020,eax
0x08048416 <+38>: mov eax,ds:0x804a020
0x0804841b <+43>: ret
直接和前面写的汇编进行比对便是,由于格式问题,里面的部分地址和标签已经面目全非,但是我们只要能够辨识出来就行了,不需要全部都搞得明明白白。这是前面的汇编代码:
mov eax, 2
mov [x], eax
mov eax, 3
mov [y], eax
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret
数一下行数就知道,是相同的。再仔细看看每一条指令,基本也是差不多的。当然x、y、z这些东西不见了,变成了一些奇奇怪怪的符号,在此暂不深究。
我们再看看C程序的汇编代码:
0x080483ed <+0>: push ebp
0x080483ee <+1>: mov ebp,esp
0x080483f0 <+3>: mov DWORD PTR ds:0x804a024,0x2
0x080483fa <+13>: mov DWORD PTR ds:0x804a028,0x3
0x08048404 <+23>: mov edx,DWORD PTR ds:0x804a024
0x0804840a <+29>: mov eax,ds:0x804a028
0x0804840f <+34>: add eax,edx
0x08048411 <+36>: mov ds:0x804a020,eax
0x08048416 <+41>: mov eax,ds:0x804a020
0x0804841b <+46>: pop ebp
0x0804841c <+47>: ret
这里,先撇开下面几个指令(这几个指令本身是有用的,但是在这个例子里,可以暂时先去掉,具体它们是干啥的,后面说),去掉它们:
push ebp
mov ebp, esp
....
pop ebp
于是C程序反汇编变成了这样子:
0x080483f0 <+3>: mov DWORD PTR ds:0x804a024,0x2
0x080483fa <+13>: mov DWORD PTR ds:0x804a028,0x3
0x08048404 <+23>: mov edx,DWORD PTR ds:0x804a024
0x0804840a <+29>: mov eax,ds:0x804a028
0x0804840f <+34>: add eax,edx
0x08048411 <+36>: mov ds:0x804a020,eax
0x08048416 <+41>: mov eax,ds:0x804a020
0x0804841c <+47>: ret
还是看起来不太明朗,怎么办?我们追踪里面的数字2、3和add指令,把那些稀奇古怪的符号换成我们认识的标签x、y、z再看看:
0x080483f0 <+3>: mov [x],0x2
0x080483fa <+13>: mov [y],0x3
0x08048404 <+23>: mov edx,[x]
0x0804840a <+29>: mov eax,[y]
0x0804840f <+34>: add eax,edx
0x08048411 <+36>: mov [z],eax
0x08048416 <+41>: mov eax,[z]
0x0804841c <+47>: ret
对比前面我们自己写的汇编代码看看呢?是不是基本是八九不离十了?仅仅有两个地方不一样:1. 使用的寄存器顺序不太一样,但是这个无妨;2. 有两条汇编指令,在C编译后的反汇编代码中对应的是一条指令。
这里我们发现了,原来
mov eax, 2
mov [x], eax
可以被精简为一条语句:
mov [x], 2
好的,按照C编译器给我们提供的信息,我们的汇编程序还可以简化成这样:
global main
main:
mov [x], 0x2
mov [y], 0x3
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret
section .data
x dw 0
y dw 0
z dw 0
然而,当我们把汇编写成这样自己编译的时候,却出错了,这里并不能完全这么写,得做一些小修改,把前两条指令改成:
mov dword [x], 0x2
mov dword [y], 0x3
这样再编译,就没有问题了。通过研究,我们用汇编写出了和前面的C程序编译后代码等价的汇编程序:
global main
main:
mov dword [x], 0x2
mov dword [y], 0x3
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret
section .data
x dw 0
y dw 0
z dw 0
总结
好了,到这里,我们通过nasm、gcc和gdb,将一个简单的C程序,用汇编语言等价地实现出来了。
说一下这一段内容的重点:
- C程序在编译阶段,在逻辑上,会被转化成等价的汇编程序
- 汇编程序经过编译器内置(或外置)的汇编器,编译成机器指令(到可执行文件的过程中还有一个链接阶段,后面再提)
- 我们可以通过gdb反汇编得知一个C程序的汇编形式
其实,学习汇编语言的目的,并非主要是为了今后用汇编语言编程,而是借助于对汇编语言的理解,进一步地去理解高级语言在底层的一些细节,一个C语言的赋值语句,一个C语言的加法表达式,在编译后运行的时候,到底在做些什么。也就是通过汇编认识到计算机中,程序执行的时候到底在做些什么,CPU到底在干什么,借助于此,理解计算机程序在CPU眼里的本质。
后续通过这个,结合各种资料学习汇编语言,将是一个非常不错的选择。在对汇编进行实践和理解的过程中,也能更清楚地知道C语言里的各种写法,到底代表什么含义,加深对C语言的认识。
废话
本节内容涉及的代码和操作就多一些了,当然能够耐心做完是最好的,一天两天不够就三天五天,也是值得的。
文中若有疏漏,欢迎指正。
3.1.5 - 汇编语言入门五:流程控制(一)
回顾
前面说到过这样几个内容:
- 几条简单的汇编指令
- 寄存器
- 内存访问
对应到C语言的学习过程中,无非就是这样几个内容:
- 超级简单的运算
- 变量
好了,到这里,我们继续接下来的话题,程序中的流程控制。
文中涉及一些汇编代码,建议读者自行编程,通过动手实践来加深对程序的理解。
顺序执行
首先,最简单也最好理解的程序流程,便是从前往后的顺序执行。这个非常简单,还是举出前面的例子:
现在有1000个计算题:
99+10=
32-20=
14+21=
47-9=
87+3=
86-8=
...
需要你一个个地从前往后计算,计算结果需要写在专门的答题卡上。当你每做完一个题,你需要继续做下一个题(这不是废话么)。
那么问题来了,我每次计算完一个题目,回头寻找下一个题目的时候,到底哪一个题是我接下来要计算的呢?
你可能会说:瞄一眼答题卡就知道了呀。这就尴尬了,计算机其实是比较傻的,它可没有“瞄一眼”这样的功能。
那这样的话,如果是自己做1000个题目,为了保证做题的时候每一个动作都不是多余的,有一个比较好的办法,就是强行在脑子里记住刚刚那个题目的位置。一会儿回头的时候,就立马知道该继续做哪个题了。
好了,那对于计算机来说呢?前面说到,你做计算题的时候临时留在脑子里的东西,就对应CPU里寄存器的数据。寄存器就充当了临时记住一些东西的功能。那么,在这里,CPU也是用的这个套路,在内部有一个寄存器,专门用来记录程序执行到哪里了。
CPU中的顺序执行过程
前面已经有了一个初步的结论,CPU里有一个寄存器专门存放“程序执行到哪里了”这样一个信息,而且这么做也是说得过去的,那就是:必须有一个东西记录当前程序执行到的位置,否则CPU执行完一条指令之后,就不知道接下来该干什么了。
在x86体系结构的CPU里面,这个执行位置的信息,是保存在叫做eip的寄存器中的。不过很遗憾,这个寄存器比较特殊,无法通过mov指令进行修改,也就是说,这么写mov eip, 0x233是行不通的。
(不要问我为什么,我也不知道,这都是人做出来的东西,支不支持就看人家的心情。反正Intel的CPU做出来就是这个样子的,你可以认为,Intel在做CPU的时候压根就没支持这个功能,他们觉得做了也没什么卵用。虽然你可能觉得有这个功能不是更好么,但是实际上,有时候刻意对功能施加一些限制,可以减少程序员写代码误操作的机会,eip这个东西,很关键)
好了,介绍完eip的作用之后,再说一下细节的东西。在执行一条指令的时候,eip此时代表的是下一条指令的位置,eip里保存的就是下一条指令在内存中的地址。这样,CPU在执行完成一条指令之后,就直接根据eip的值,取出下一条指令,同时还要修改eip,往eip上加一个指令的长度,让它继续指向后一条指令。
有了这样一个过程,CPU就能自动地去从前往后执行每一条指令了。而且,上述过程是在CPU中自动发生的,你写代码的时候根本不需要关心这个东西,只需要按照自己的思路从前往后写就是了。
好了,这一段更多的是讲故事,明白CPU里面有个eip寄存器,它的功能很专一,就是用来表示程序现在执行到哪儿了。说得精确一点,eip一直都指向下一个要执行的指令,这一点是由CPU自己保证的。总之,只要CPU没坏,它就能给你保证eip的精确。
事情没那么简单
前面说了eip能记住程序执行的位置,那么CPU就能顺溜溜地一路走下去了。然而,世界并不是这么美好。因为:
if( a < 1 ){
// some code ...
} else if( a >= 10 ) {
// yi xie dai ma ...
}
实际上有时候我们需要程序有一定的流程控制能力。就是有时候它不是老老实实按照顺序来执行的,中间可能会跳过一些代码,比如上述C代码中的a的值为100的时候。
那么这时候怎么搞呢?照这样说,程序就得具备“修改eip”的能力了,可是前面说了,mov指令不顶用啊?
放心,那帮做CPU的人没那么傻,他们早就想好了怎么办了。他们在设计CPU的时候是这么考虑的:
- 更改eip和更改别的寄存器产生的效果不一样,所以应该特殊对待
- 要更改有着特殊用途的eip,就用特殊的指令来完成,虽然都是在更改寄存器,但是代码写出来,表达给人的意思就不一样了
首先,我们需要更改eip来实现程序突然跳转的效果,进而灵活地对程序的流程进行控制。这里不得不祭出一套新的指令了:跳转指令。
不说了,铺垫也都差不多了,还是直接上代码,直观体验一把,然后再扯别的。先来一份正常的代码:
global main
main:
mov eax, 1
mov ebx, 2
add eax, ebx
ret
如果前面好好学习的话,对这个一定不陌生。还是大致解释一下吧:
eax = 1
ebx = 2
eax = eax + ebx
所以,按照正常逻辑理解,最后eax为3,整个程序退出时会返回3。
好的,到这里,我们来引入新的指令,通过前后对比的变化,来理解新的指令的作用:
global main
main:
mov eax, 1
mov ebx, 2
jmp gun_kai
add eax, ebx
gun_kai:
ret
这段代码相比前面的代码,多了两行:
...
jmp gun_kai
...
gun_kai:
...
好了,这段代码其实没什么功能,存粹是为了演示,运行这个代码,得到的返回结果为1。
好了,最后的结果告诉我们,中间的那一条指令:
add eax, ebx
根本就没有执行,所以最后eax的值就是1,整个程序的返回值就是1。
好了,这里也没什么需要解释的,动手做,稍微对比分析一下就能够知道结论了。程序中出现了一条新的指令jmp,这是一个跳转指令,不解释。这里直接用一个等价的C语言来说明上述功能吧:
int main() {
int a = 1;
int b = 2;
goto gun_kai;
a = a + b;
gun_kai:
return a;
}
实际上,C语言中的goto语句,在编译后就是一条jmp指令。它的功能就是直接跳转到某个地方,你可以往前跳转也可以往后跳转,跳转的目标就是jmp后面的标签,这个标签在经过编译之后,会被处理成一个地址,实际上就是在往某个地址处跳转,而jmp在CPU内部发生的作用就是修改eip,让它突然变成另外一个值,然后CPU就乖乖地跳转过去执行别的地方的代码了。
这玩意有啥用?
不对啊,这跳转指令能用来干啥?反正代码都直接被跳过去了,那我编程的时候干脆直接不写那几条指令不就得了么?使用跳转指令是不是有种脱了裤子放屁的感觉?
并不是,继续。
if在汇编里的样子
前面说到了跳转,但是仿佛没卵用的样子。接下来我们说这样一个C语言程序:
int main() {
int a = 50;
if( a > 10 ) {
a = a - 10;
}
return a;
}
这个程序,最后的返回值是40,这没什么好解释的。那对应的汇编程序呢?其实也非常简单,先直接给出代码再分析:
global main
main:
mov eax, 50
cmp eax, 10 ; 对eax和10进行比较
jle xiaoyu_dengyu_shi ; 小于或等于的时候跳转
sub eax, 10
xiaoyu_dengyu_shi:
ret
这段汇编代码很关键的地方就在于这两条陌生的指令:
cmp eax, 10 ; 对eax和10进行比较
jle xiaoyu_dengyu_shi ; 小于或等于的时候跳转
先细细解释一下:
- 第一条,cmp指令,专门用来对两个数进行比较
- 第二条,条件跳转指令,当前面的比较结果为“小于或等于”的时候就跳转,否则不跳转
到这里,至少上面这个程序,每一条指令都是很清楚的。只是你关心的是下面的问题:
- 我会写a > 10的情况了,那么a < 10怎么办呢?a == 10怎么办呢?a <= 10怎么办呢?a >= 10怎么办呢?
凉拌炒鸡蛋。
别急,先说套路。上面的C语言代码是这样的:
if ( a > 10 ) {
a = a - 10;
}
这是表示:“比较a和10,a大于10的时候,进入if块中执行减法”
而汇编代码:
cmp eax, 10
jle xiaoyu_dengyu_shi
sub eax, 10
xiaoyu_dengyu_shi:
表示的是:“比较eax和10,eax小于等于10的时候,跳过中间的减法”
注意这里最关键的两个表述:
- C语言中:a大于10的时候,进入if块中执行减法
- 汇编语言中:eax小于等于10的时候,跳过中间的减法
C语言和汇编语言中的条件判断,其组织的思路是刚好相反的。这就在编程的时候带来一些思考上的困难,不过这都还是小事情,实在困难你可以先画出流程图,然后对流程图进行改造,就可以了。
有了上面if的套路,接下来趁热打铁,再做一个练习:
int main() {
int x = 1;
if ( x > 100 ) {
x = x - 20;
}
x = x + 1;
return x;
}
好了,这里按照前面的思路,在汇编语言里面,关键就是下面几点:
- 对x对应的东西与100进行比较
- 何时跳过if块中的减法
- x = x + 1是无论如何都会执行的
按照前面的代码,稍作类比,很容易地就能写出下面的代码来:
global main
main:
mov eax, 1
cmp eax, 100
jle xiao_deng_yu_100
sub eax, 20
xiao_deng_yu_100:
add eax, 1
ret
把程序结合着前面的C代码进行对比,参考前面说的if在汇编里组织的套路,这个程序就很容易理解了。你还可以尝试把
mov eax, 1
更改为:
mov eax, 110
试试程序的执行逻辑是不是发生了变化?
再来套路
前面说到了if在汇编中的组织方式,接下来,问题就更加复杂了:
- 我会写a > 10的情况了,那么a < 10怎么办呢?a == 10怎么办呢?a <= 10怎么办呢?a >= 10怎么办呢?
凉拌炒鸡蛋。
前面实际上只提到了两个流程控制相关的指令:
- jmp
- jle
以及一个比较指令:
- cmp
专门用来对两个操作数进行比较。
先从这里入手,总结套路。首先,这两条跳转指令是人想出来的,所以,你很容易想到,仅仅是这两条跳转指令好像还不够。其实,人家做CPU的人早也就想到了。所以,还有这样一些跳转指令:
ja 大于时跳转
jae 大于等于
jb 小于
jbe 小于等于
je 相等
jna 不大于
jnae 不大于或者等于
jnb 不小于
jnbe 不小于或等于
jne 不等于
jg 大于(有符号)
jge 大于等于(有符号)
jl 小于(有符号)
jle 小于等于(有符号)
jng 不大于(有符号)
jnge 不大于等于(有符号)
jnl 不小于
jnle 不小于等于
jns 无符号
jnz 非零
js 如果带符号
jz 如果为零
好了,这就是一些条件跳转指令,将它们配合着前面的cmp指令一起使用,就能够达到if语句的效果。
What?这该不会都得记住吧?其实不用,这里面是有套路的:
- 首先,跳转指令的前面都是字母j
- 关键是j后面的的字母
比如j后面是ne,对应的是jne跳转指令,n和e分别对应not和equal,也就是“不相等”,也就是说在比较指令的结果为“不想等”的时候,就会跳转。
- a: above
- e: equal
- b: below
- n: not
- g: greater
- l: lower
- s: signed
- z: zero
好了,这里列出来了j后面的字母所对应的含义。根据这些字母的组合,和上述大概的规则,你就能清楚怎么写出这些跳转指令了。当然,这里有“有符号”和“无符号”之分,后面有机会再扯,读者也可以自行了解。
那么,接下来,就可以写出这样的程序所对应的汇编代码了:
int main() {
int x = 10;
if ( x > 100 ) {
x = x - 20;
}
if( x <= 10 ) {
x = x + 10;
}
x = x + 1;
return 0;
}
这个程序没什么卵用,存粹是为了演示。按照前面的套路,其实写出汇编代码也就不难了:
global main
main:
mov eax, 10
cmp eax, 100
jle lower_or_equal_100
sub eax, 20
lower_or_equal_100:
cmp eax, 10
jg greater_10
add eax, 10
greater_10:
add eax, 1
ret
至于更多可能的写法,那就可以慢慢玩了。
if都有了,那else if和else怎么办呢?
这里就不再赘述了,理一下思路:
- 首先根据你的需要,画出整个程序的流程图
- 按照流程图中的跳转关系,通过汇编表达出来
也就是说,在汇编里面,实际上没有所谓的if或else的说法,只是前面为方便说明,使用了C语言作类比,实际上汇编还可以写得比C语言的判断更加灵活。
事实上,C语言里面的几种常见的if组织结构,都有对应的汇编语言里的套路。说白了,都是套路。
那你怎么才能知道这些套路呢?很简单,用C语言写一个简单的程序,编译后按之前文章所说的内容,使用gdb去反汇编然后就能知道这里面的具体做法了。
下面来尝试下一下:
int main() {
register int grade = 80;
register int level;
if ( grade >= 85 ){
level = 1;
} else if ( grade >= 70 ) {
level = 2;
} else if ( grade >= 60 ) {
level = 3;
} else {
level = 4;
}
return level;
}
(程序中有一个register关键字,是用来限定这个变量在编译后只能用寄存器来进行表示,方便我们进行分析。读者可以根据需要,去掉register关键字后比较一下反汇编代码有何不同。)
这是一个很经典的多分支程序结构。先编译运行,程序返回值为2。
$ gcc -m32 grade.c -o grade
$ ./grade ; echo $?
2
好了,接下来,用gdb进行反汇编:
$ gdb ./grade
(gdb) set disassembly-flavor intel
(gdb) disas main
得到的反汇编代码如下:
Dump of assembler code for function main:
0x080483ed < +0>: push ebp
0x080483ee < +1>: mov ebp,esp
0x080483f0 < +3>: push ebx
0x080483f1 < +4>: mov ebx,0x50
0x080483f6 < +9>: cmp ebx,0x54
0x080483f9 <+12>: jle 0x8048402 <main+21>
0x080483fb <+14>: mov ebx,0x1
0x08048400 <+19>: jmp 0x804841f <main+50>
0x08048402 <+21>: cmp ebx,0x45
0x08048405 <+24>: jle 0x804840e <main+33>
0x08048407 <+26>: mov ebx,0x2
0x0804840c <+31>: jmp 0x804841f <main+50>
0x0804840e <+33>: cmp ebx,0x3b
0x08048411 <+36>: jle 0x804841a <main+45>
0x08048413 <+38>: mov ebx,0x3
0x08048418 <+43>: jmp 0x804841f <main+50>
0x0804841a <+45>: mov ebx,0x4
0x0804841f <+50>: mov eax,ebx
0x08048421 <+52>: pop ebx
0x08048422 <+53>: pop ebp
0x08048423 <+54>: ret
篇幅有限,这里就留给读者练习分析了。其中有几个需要注意的地方:
- 部分无关指令可以直接忽略掉,如:push、pop等
- 跳转指令后的<main+21>,就对应的是反汇编指令前是<+21>的指令
根据上述反汇编代码,分析出程序的流程图,与C语言程序的代码进行比较。仔细分析,你应该就发现jmp指令有什么用了吧。
状态寄存器
到这里,有一个问题出现了,在汇编语言里面实现“先比较,后跳转”的功能时,后面的跳转指令是怎么利用前面的比较结果的呢?
这就涉及到另一个寄存器了。在此之前,先想一下,如果自己在脑子里思考同样的逻辑,是怎么样的?
- 先比较两个数
- 记住比较结果
- 根据比较结果作出决定
好了,这里又来了一个“记住”的动作了。CPU里面也有一个专用的寄存器,用来专门“记住”这个cmp指令的比较结果的,而且,不仅是cmp指令,它还会自动记住其它一些指令的结果。这个寄存器就是:
eflags
名为“标志寄存器”,它的作用就是记住一些特殊的CPU状态,比如前一次运算的结果是正还是负、计算过程有没有发生进位、计算结果是不是零等信息,而后续的跳转指令,就是根据eflags寄存器中的状态,来决定是否要进行跳转的。
cmp指令实际上是在对两个操作数进行减法,减法后的一些状态最终就会反映到eflags寄存器中。
总结
这回着重说到了汇编语言中与流程控制相关的内容。其中主要包括:
- eip寄存器指示着CPU接下来要执行哪里的代码
- 一系列跳转指令,跳转指令根本上就是修改了eip
- 比较指令,比较指令实际上是在做减法,然后把结果的一些状态放到eflags寄存器中
- eflags寄存器的作用
- 条件跳转指令也就是根据eflags中的信息来决定是否跳转
当然,这里讲述的仅仅是一部分相关的指令,带领读者对这部分内容有一个直观的认识。实际上汇编语言中与流程相关的指令不止这些,读者可自行查阅相关的资料:
- x86标志寄存器
- x86影响标志寄存器的指令
- x86跳转指令
本文内容相比之前要更多一些,若想要完全理解,也需要仔细阅读,多思考、多尝试,多验证,也可以参考更多其它方面的资料。
文中若有疏漏之处,欢迎指正。
3.1.6 - 汇编语言入门六:流程控制(二)
回顾
前面说到在汇编语言中实现类似C语言if-else if-else这样的结构,
实际上,在汇编里面,我们并不关心if了,取而代之的是两种基本的指令:
- 比较
- 跳转
这两种指令即可组成最基本的分支程序结构,虽然跳转指令非常多,但是我们已经有套路了,怎么跳转都不怕了。当然,在编程环境中仅有分支还不够的,我们知道C语言中除了分支结构之外,还有循环这个最基本也是最常用的形式。正好,这也是本节话题的主角。
文中涉及一些汇编代码,建议读者自行编程,通过动手实践来加深对程序的理解。
拆散循环结构
上回说到C语言中if这样的结构,在汇编里对应的是怎么回事,实质上,这就是分支结构的程序在汇编里的表现形式。
实际上,循环结构相比分支结构,本质上,没有多少变化,仅仅是比较合跳转指令的组合的方式与顺序有所不同,所以形成了循环。
当然,这个说法可能稍微拗口了一点。说得简单一点,循环的一个关键特点就是:
- 程序在往回跳转
细细想,好像有道理哦,如果程序每到一个位置就往前跳转,那就是死循环,如果是在这个位置根据条件决定是否要向前跳转,那就是有条件的循环了。
口说无凭,还是先来分析一下一个C语言的while循环:
(Talk is chip, show your code!)
int sum = 0;
int i = 1;
while( i <= 10 ) {
sum = sum + i;
i = i + 1;
}
想必这段程序多数人都非常熟悉了,当年自己第一次学习循环的时候就碰到这个题目,脑子短路了,心里总想着这不就是一个等差数列公式么,题目却强行出现在循环一章的后面,最后结果让人大跌眼睛,这是要我老老实实像SHAB一样去加啊。
跑题了,先大致总结一下这个程序的关键部分到底在干什么:
- 1. 比较i和10的大小
- 2. 如果i <= 10则执行代码块,并回到(1)
- 3. 如果不满足 i <= 10,则跳过代码块
好了,按照这个逻辑,在C语言中不使用循环怎么实现?其实也非常简单:
int sum = 10;
int i = 1;
_start:
if( i <= 10 ) {
sum = sum + i;
i = i + 1;
goto _start;
}
这还不够,我们还得做一次变形,为什么呢?回想一下前面说的分之程序在汇编里的情况:
if ( a > 10 ) {
// some code
}
上述C代码,暂且成为“正宗C代码”,等价的汇编大致结构如下:
cmp eax, 10
jle out_of_block
; some code
out_of_block:
再等价变换回C语言,这里把这种风格叫做“山寨C代码”,实际上就是这样的:
if( a <= 10 ) goto out_of_block;
// some code
out_of_block:
经过比较,我们可以发现“山寨C代码”和“正宗C代码”之间的一些区别:
- 山寨版中,if块里只需要放一条跳转语句即可
- 山寨版中,if里的条件是反过来的
- 山寨版中,跳转语句的功能是跳过“正宗C代码”的if块
相当于是:不满足条件就跳过if中的语句块。
那循环呢?咱们把循环的C等价代码做一次变换,也就是把只含有goto和if的“正宗C代码”变换为“山寨C代码”的形式:
int sum = 10;
int i = 1;
_start:
if( i > 10 ) {
goto _end_of_block;
}
sum = sum + i;
i = i + 1;
goto _start;
_end_of_block:
大致看一下流程,再对比源代码:
int sum = 0;
int i = 1;
while( i <= 10 ) {
sum = sum + i;
i = i + 1;
}
自己在脑子里面模拟一遍,是不是就能发现什么了?这俩货分明就是一个东西,执行的顺序和过程完全就是一样的。
到这里,我们的循环结构,全都被拆散成了最基本的结构,这种结构有一个关键的特点:
- 所有if块中都仅有一条goto语句,别的啥都没了
到这里,本段就到位了。
用汇编写出循环
前面已经介绍了“如何把一个循环拆解成只有if和goto的结构”,有了这个结构之后,其实要写出汇编就非常容易了。
继续看山寨版的循环:
int sum = 10;
int i = 1;
_start:
if( i > 10 ) {
goto _end_of_block;
}
sum = sum + i;
i = i + 1;
goto _start;
_end_of_block:
其实,稍微仔细一点就能发现,把这玩意儿写成汇编,就是逐行翻译就完事儿了。动手:
global main
main:
mov eax, 0
mov ebx, 1
_start:
cmp ebx, 10
jg _end_of_block
add eax, ebx
add ebx, 1
jmp _start
_end_of_block:
ret
这里面其实有一个套路:
- 单条goto语句可以直接用jmp语句替代
- if和goto组合的语句块可以用cmp和j*指令的组合替代
最后,其它语句该干啥干啥。
这?竟然?就?用汇编?写出?循环?来了?
嗯,是的。不需要任何一个新的指令,全都是前面提及过的基本指令,只是套路不一样了而已。
其实这就是一个套路,稍微总结一下就能发现,一个将while循环变换为汇编的过程如下:
- 将while循环拆解成只有if和goto的形式
- 将if形式的语句拆解成if块中仅有一行goto语句的形式
- 从前往后逐行翻译成汇编语言
其它循环呢?
那while循环能够搞定了,其它类型的呢?do-while循环、for循环呢?
其实,在C语言中,这三种循环之间都是可以相互变换的,也就是说for循环可以变形成为while循环,while循环也可以变成for循环。举个例子:
int i = 1;
int sum = 0;
for(i = 0; i <= 10; i ++) {
sum = sum + i;
}
int sum = 0;
int i = 1;
while( i <= 10 ) {
sum = sum + i;
i = i + 1;
}
上述两个片段的代码,其实就是等价的,仅仅是形式不同。只是有的循环思路用for循环写出来好看一些,有的思路用while循环写出来好看一些,别的没什么本质区别,经过编译器一倒腾之后,就更没有任何区别了。
总结
在汇编中,分支和循环结构,都是通过两类基本的指令实现的:
- 比较
- 跳转
只是,分支结构的程序中,所有的跳转目标都是往后,程序一去不复返。而循环结构中,程序会根据条件往前跳转,跳回去执行已经执行过的代码,在绕圈圈,就成循环了。到汇编层面,本质上,没啥区别。
好了,汇编语言中的流程控制,基本就算完事儿了,实际上,在汇编语言中,抓住根本的东西就行了,剩下的就是靠脑子想象了。
文中若有疏漏之处,欢迎指正。
3.1.7 - 汇编语言入门七:函数调用(一)
最近忙了一阵,好几天没更了,不好意思,我来晚了。
转入正题,当在汇编中进行函数调用,是一种什么样的体验?
想象
想象你在计算一个非常复杂的数学题,在算到一半的时候,你需要一个数据,而这个数据需要套用一个比较复杂的公式才能算出来,怎么办?
你不得不把手中的事情停下来,先去套公式、代入数值然后…最后,算出结果来了。
这时候你继续开始攻克这个困难题目的剩下部分。
用脑子想
刚刚说的这个过程,可能有点小问题,尤其是对脑子不太好使的人来说。想象你做题目做到一半的时候,记忆力已经有点不好使了,中间突然停下来去算一个复杂的公式,然后回来,诶?我刚刚算到哪了?我刚刚想到哪了?我刚刚算了些什么结果?
在你工作切换的时候,很容易回头来就忘记了刚刚做的部分事情。这时候,为了保证你套完复杂的公式,把结果拿回来继续算题目的时候不会出差错,你需要把刚才计算题目过程中的关键信息写在纸上。
用CPU想
刚刚去套用一个复杂的公式计算某个数据的情景,就类似在计算机里进行函数调用的情景。
程序需要一个结果,这个结果需要通过一个比较复杂的过程进行计算。这时候,编程人员会考虑将这个独立的复杂过程提取为单独的函数。
而在发生函数调用的时候,CPU就像是先暂停当前所做的事情,转去做那个复杂的计算,算完了之后又跳回来继续整个计算。就像你做题的过程中去套了一个公式计算数据一样。
但是在去套用公式之前,你需要做一些准备。首先,默默记下现在这个题目算到哪一步了,一会套完公式回来接着做;默默记下现在计算出来的一些结果,一会可能还会用到;套用公式需要些什么数据,先记下来,代公式的时候直接代入计算,算出来的结果也需要记在脑子里,回头需要使用。
在CPU里面,也需要这几个过程。
第一个,记下自己现在做事情做到哪里了,一会儿套完公式回来接着做,这也就是CPU在进行函数调用时的现场保存操作,CPU也需要记下自己当前执行到哪里了。
默默记下一些在套用公式的时候需要用到的数据,然后去套公式了。这也就是程序中在调用函数的时候进行参数传递的过程。
然后开始执行函数,等函数执行完了,就需要把结果记下来,回去继续刚才要用到数据的那个地方继续算。这也就是函数调用后返回的动作,这个记下的结果就是返回值。
开撸
说了那么多故事,那么函数调用要干些啥应该就说清楚了。总结一下大概就这么几个事:
- 保存现场(一会好回来接着做)
- 传递参数(可选,套公式的时候需要些什么数据)
- 返回(把计算结果带回来,接着刚才的事)
到这里,我们先来一个事例代码,就着代码去发现函数调用中的套路:
global main
eax_plus_1s:
add eax, 1
ret
ebx_plus_1s:
add ebx, 1
ret
main:
mov eax, 0
mov ebx, 0
call eax_plus_1s
call eax_plus_1s
call ebx_plus_1s
add eax, ebx
ret
首先,运行程序,得到结果:3。
上面的代码其实也比较简单,先从主干main这个地方梳理:
- 让eax和ebx的值都为0
- 调用eax_plus_1s,再调用eax_plus_1s
- 调用ebx_plus_1s
- 执行eax = eax + ebx
上述的两个函数也非常简单,分别就是给eax和ebx加了1。所以,这个程序其实也就是换了个花样给寄存器增加1而已,纯粹演示。
这里出现了一个陌生指令call,这个指令是函数调用专用的指令,从程序的行为上看应该是让程序的执行流程发生跳转。前面说到了跳转指令jmp,这里是call,这两个指令都能让CPU的eip寄存器发生突然变化,然后程序就一下子跳到别的地方去了。但是这两个有区别:
很简单,jmp跳过去了就不知道怎么回来了,而通过call这种方式跳过去后,是可以通过ret指令直接回来的
那这是怎么做到的呢?
其实,在call指令执行的时候,CPU进行跳转之前还要做一个事情,就是把eip保存起来,然后往目标处跳。当遇到ret指令的时候,就把上一次call保存起来的eip恢复回来,我们知道eip直接决定了CPU会执行哪里的代码,当eip恢复的时候,就意味着程序又会到之前的位置了。
一个程序免不了有很多次call,那这些eip的值都是保存到哪里的呢?
有一个地方叫做“栈(stack)”,是程序启动之前,由操作系统指定的一片内存区域,每一次函数调用后的返回地址都存放在栈里面
好了,我们到这里,就明白了函数调用大概是怎么回事了。总结起来就是:
- 本质上也是跳转,但是跳到目标位置之前,需要保存“现在在哪里”的这个信息,也就是eip
- 整个过程由一条指令call完成
- 后面可以用ret指令跳转回来
- call指令保存eip的地方叫做栈,在内存里,ret指令执行的时候是直接取出栈中保存的eip值,并恢复回去达到返回的效果
何为栈?
前面说到call指令会先保存eip的值到栈里面,然后就跳转到目标函数中去了。
这都好说,但是,如果是我在函数里面调用了一个函数,在这个函数里面又调用了一个函数,这个eip是怎么保存来保证每一次都能正确的跳回来呢?
好的,这个问题才是关键,这也说到了栈这样一个东西,我们先来设想一些场景,结合实际代码理解一下CPU所对应的栈。
首先,这个栈和数据结构中的栈是不一样的。数据结构中的栈是通过编程语言来形成程序执行逻辑上的栈。而这里的栈,是CPU内硬件实现的栈。当然了,两者在逻辑上都差不多的。
在这里,先回想一下数据结构中基于数组实现的栈。里面最关键的就是需要一个栈顶指针(或者是一个索引、下标),每次放东西入栈,就将指针后移,每一次从栈中取出东西来,就将指针前移。
到这里,我们先从逻辑上分析下CPU在发生函数调用的过程中是如何使用栈的。
假设现在程序处在一个叫做level1的位置,并调用了函数A,在调用的跳转发生之前,会将当前的eip保存起来,这时候,栈里面就是这样的:
---------- <= top
level1
----------
现在,程序处在level2的位置,又调用了函数B,同样,也会保存这次的eip进去:
---------- <= top
level2
----------
level1
----------
再来,程序这次处在level3,调用了C函数,这时候,整个栈就是这样的:
---------- <= top
level3
----------
level2
----------
level1
----------
好了,这下程序执行到了ret,会发生什么事,是不是就回到level3了?在level3中再次执行ret,是不是就回到level2了?以此类推,最终,程序就能做到一层层的函数调用和返回了。
实际的CPU中
在实际的CPU中,上述的栈顶top也是由一个寄存器来记录的,这个寄存器叫做esp(stack pointer),每次执行call指令的时候。
这里还有一个小细节,在x86的环境下,栈是朝着低地址的方向伸长的。什么意思呢?每一次有东西入栈,那么栈顶指针就会递减一个单位,每一次出栈,栈顶指针就会相应地增加一个单位(和数据结构中一般的做法是相反的)。至于为什么会这样,我也不知道。
eip在入栈的时候,大致就相当于执行了这样一些指令:
sub esp, 4
mov dword ptr[esp], eip
翻译为C语言就是(假如esp是一个void*类型的指针):
esp = (void*)( ((unsigned int)esp) - 4 )
*( (unsigned int*) esp ) = (unsigned int) eip
也就是esp先移动,然后再把eip的值写入到esp指向的内存中。那么,ret执行的时候该干什么,也就非常的清楚了吧。无非就是上述过程的逆过程。
同时,eip寄存器的长度为32位,即4字节,所以每一次入栈出栈的单位大小都是4字节。
动手
没有代码,说个锤子。先来一个简单的程序:
global main
eax_plus_1s:
add eax, 1
ret
main:
mov eax, 0
call eax_plus_1s
ret
这个程序中只有一个函数调用,但不影响我们分析。先编译,得到一个可执行文件,这里先起名为plsone。
然后载入gdb进行调试,进行反汇编:
$ gdb ./plsone
(gdb) disas main
Dump of assembler code for function main:
0x080483f4 <+0>: mov $0x0,%eax
0x080483f9 <+5>: call 0x80483f0 <eax_plus_1s>
0x080483fe <+10>: ret
0x080483ff <+11>: nop
End of assembler dump.
好了,找到反汇编中<+5>所在那一行,对应着的指令是call 0x80483f0,这个指令的地址为:0x080483f9(不同的环境有所不同,根据实际情况来)。按照套路,在这个call指令处打下一个断点,然后运行程序。
(gdb) b *0x080483f9
Breakpoint 1 at 0x80483f9
(gdb) run
Starting program: /home/vagrant/code/asm/07/plsone
Breakpoint 1, 0x080483f9 in main ()
(gdb)
好了,程序执行到断点处,停下来了。再来看反汇编,这次有一个小箭头指向当前的断点了:
(gdb) disas main
Dump of assembler code for function main:
0x080483f4 <+0>: mov $0x0,%eax
=> 0x080483f9 <+5>: call 0x80483f0 <eax_plus_1s>
0x080483fe <+10>: ret
0x080483ff <+11>: nop
End of assembler dump.
接下来,做这样一个事情,看看现在eip的值是多少:
(gdb) info register eip
eip 0x80483f9 0x80483f9 <main+5>
正好指向这个函数调用指令。这里的call指令还没执行,现在的CPU处在上一条指令刚执行完毕的状态。前面说过,CPU中的eip总是指向下一条会执行的指令。在这里,珍惜机会,我们把想看的东西全都看个遍吧:
- esp的值,这个很关键
(gdb) info register esp
esp 0xffffd6ec 0xffffd6ec
- esp所指向的栈顶的东西
(gdb) p/x *(unsigned int*)$esp
$1 = 0xf7e40ad3
该看的都看过了,让程序走吧,让它先执行完了call指令,我们再回头看看什么情况:
(gdb) stepi
0x080483f0 in eax_plus_1s ()
根据提示,程序现在已经执行到函数里面去了。可以直接反汇编看看:
(gdb) disas
Dump of assembler code for function eax_plus_1s:
=> 0x080483f0 <+0>: add $0x1,%eax
0x080483f3 <+3>: ret
End of assembler dump.
现在正等着执行那条加法指令呢。别急,现在函数调用已经发生了,再来看看上面我们看过的一些东西:
- esp的值,这个很关键
(gdb) info register esp
esp 0xffffd6e8 0xffffd6e8
看到了,上次查看esp的时候是0xffffd6ec,进入函数后的esp值是0xffffd6e8。少了个4。
实际上这就是eip被保存到栈里去了,CPU的栈的伸长方向是朝着低地址一侧的,所以每次入栈,esp都会减少一个单位,也就是4。
- esp所指向的栈顶的东西
(gdb) p/x *(unsigned int*)$esp
$2 = 0x80483fe
这次,我们看看栈顶到底是个什么东西,打印出来0x80483fe这么一个玩意儿,这是蛤玩意儿?别急,回头看看main函数的反汇编:
(gdb) disas main
Dump of assembler code for function main:
0x080483f4 <+0>: mov $0x0,%eax
0x080483f9 <+5>: call 0x80483f0 <eax_plus_1s>
0x080483fe <+10>: ret
0x080483ff <+11>: nop
End of assembler dump.
在里面找找0x80483fe呢?刚好在<+10>所在的那一行。这不就是函数调用指令处的后一条指令吗?
对的,也就是说,一会函数返回的时候,就会到<+10>这个地方来。也就是在执行了eax_plus_1s函数里的ret之后。
是不是和前面描述的过程一模一样?
好了,到这里,探究汇编中的函数调用的过程和方法基本就有了,读者可以根据需要自行编写更加奇怪的代码,结合gdb,来探究更多你自己所好奇的东西。
附加一个代码,自己玩耍试试(在自己的环境中玩耍哦):
global main
hahaha:
call hehehe
ret
hehehe:
call hahaha
ret
main:
call hahaha
ret
总结
这回,我们说到这样一些东西:
- 汇编中发生函数调用相关的指令call和ret
- call指令会产生跳转动作,与jmp不同的是,call之后可以通过ret指令跳回来
- call和ret的配合是依靠保存eip的值到栈里,返回时恢复eip实现的
- esp记录着当前栈顶所在的位置,每次call和ret执行都会伴随着入栈和出栈,也就是esp会发生变化
函数调用最基本的”跳转“和”返回“就这么回事了,下回咱们继续分析”函数调用中的参数传递、返回值和状态“相关的问题。
文中若有疏漏或是不当之处,欢迎指正。
3.1.8 - 汇编语言入门八:函数调用(二)
回顾
上回说道,x86汇编中专门提供了两个指令call和ret,用于实现函数调用的效果。实际上函数调用就是程序跳转,只是在跳转之前,CPU会保存当前所在的位置(即返回地址),当函数返回时,又可以从调用的位置恢复。返回地址保存在一个叫做“堆栈”的地方,堆栈中可以保存很多个返回地址,同时借助于堆栈的进出逻辑,还能实现函数嵌套、递归等效果。
同时前面还简单地提到了函数调用过程中的参数和返回值的传递过程。实际上,在汇编语言中,函数调用的参数和返回值均可以通过寄存器来传送,只要函数内外相互配合,就可以精确地进行参数和返回值传递。
没那么简单
到这里,看起来好像函数调用的基本要素都有了,但实际上还是有一些问题的。比如说递归调用这样的场景。通过对递归的研究,你也就能明白前面说到的函数调用机制存在什么样致命的问题。
好了,先说下,这部分内容,很关键。
举个例子,通过递归调用来计算斐波那契数列中的某一项,用高级语言编写已经非常容易:
int fibo(int n) {
if(n == 1 || n == 2) {
return 1;
}
return fibo(n - 1) + fibo(n - 2);
}
我们来进行一波改造,改造成接近汇编的形式:
int fibo(int n) {
if(n == 1) {
return 1;
}
if(n == 2) {
return 1;
}
int x = n - 1;
int y = n - 2;
int a = fibo(x);
int b = fibo(y);
int c = a + b;
return c;
}
拆分成这样之后,就能够比较方便地和汇编对应起来了,再改造一下,把变量名全都换成寄存器名,就能够看得更清楚了(先约定eax寄存器作为函数的第一个参数,通过eax也用来传递返回值):
int fibo(int eax) {
int ebx, ecx;
if(eax == 1) {
return eax;
}
if(eax == 2) {
eax = 1;
return eax;
}
int edx = eax;
eax = edx - 1;
eax = fibo(eax);
ebx = eax;
eax = edx - 2;
eax = fibo(eax);
ecx = eax;
eax = ebx + ecx;
return eax;
}
因为eax会被用作参数和返回值,所以进入函数后就需要将eax保存到别的寄存器,一会需要的时候才能够更方便地使用。
看起来,这里的fibo函数已经比较完美了,这个函数在C语言下是能够正常运行的。接下来把它翻译成汇编:
fibo:
cmp eax, 1
je _get_out
cmp eax, 2
je _get_out
mov edx, eax
sub eax, 1
call fibo
mov ebx, eax
mov eax, edx
sub eax, 2
call fibo
mov ecx, eax
mov eax, ebx
add eax, ecx
ret
_get_out:
mov eax, 1
ret
然而,当你使用这个C语言代码翻译出来的汇编的时候,却发现结果怎么都不对了。
那么,问题出在哪里呢?
问题就出在从C语言翻译到汇编的过程中。
警惕作用域
在C函数中,虽然我们把各个变量名换成寄存器名,把复杂的语句拆分成简单语句,最后就能够和汇编语句等同起来,但是,在将C代码翻译到汇编的过程中,出现了不等价的变换。其中,变量的作用域便是引起不等价的原因之一。这个C代码:
int fibo(int eax) {
int ebx, ecx;
if(eax == 1) {
return eax;
}
if(eax == 2) {
eax = 1;
return eax;
}
int edx = eax;
eax = edx - 1;
eax = fibo(eax);
ebx = eax;
eax = edx - 2;
eax = fibo(eax);
ecx = eax;
eax = ebx + ecx;
return eax;
}
本身是没有任何问题的。但是,翻译后的汇编就有问题了,实际上上述汇编语言等价为这样的C代码:
int ebx, ecx, edx;
void fibo() {
if(eax == 1) {
eax = 1;
return;
}
if(eax == 2) {
eax = 1;
return;
}
edx = eax;
eax = edx - 1;
eax = fibo(eax);
ebx = eax;
eax = edx - 2;
eax = fibo(eax);
ecx = eax;
eax = ebx + ecx;
}
原因很简单,CPU中的寄存器是全局可见的。所以使用寄存器,实际上就是在使用一个像全局变量一样的东西。
那么,到这里,通过这个例子,你应该能够发现问题了,现有的做法,无法实现递归或者嵌套的结构。
到底需要什么
实际上,要实现递归,那么就需要函数的状态是局部可见的,只能在当前这一层函数内访问。递归中会出现层层调用自己的情况,每一层之间的状态都应当保证局部性,不能相互影响。
在C语言的环境下,函数内的局部变量,抽象来看,实际上就是函数执行时的局部状态。在汇编环境下,寄存器是全局可见的,不能用于充当局部变量。
那怎么办呢?
堆栈
前面说到,堆栈是用来保存函数调用后的返回地址。其实在这里,函数的返回地址,其实就是当前这一层函数的一个状态,这个状态对应的是这一层函数当前执行到哪儿了。
借鉴call指令保存返回地址的思路,如果,在每一层函数中都将当前比较关键的寄存器保存到堆栈中,然后才去调用下一层函数,并且,下层的函数返回的时候,再将寄存器从堆栈中恢复出来,这样也就能够保证下层的函数不会破坏掉上层函数的状了。
也就是,当下要解决这样一个问题:被调用函数在使用一些寄存器的时候,不能影响到调用者所使用的寄存器值,否则函数之间就很难配合好了,也很容易乱套。
入栈与出栈
实际上,CPU的设计者们已经考虑过这个问题了,所以还专门提供了对应的指令来干这个事。入栈与出栈分别是两个指令:
push eax ; 将eax的值保存到堆栈中去
pop ebx ; 将堆栈顶的值取出并存放到ebx中
有了这两个玩意儿,递归调用这个问题就可以解决了。注意了,这里发生了入栈和出栈的情况,那么,进行栈操作的时候对应的栈顶指针也会发生相应的移动,这里也一样。
搞一个不会影响全世界的函数
先来试一试堆栈的使用,我就不废话了,举个例子,一个通过循环来计算1+2+3+4+5+6+7+…+n的函数(这里还是约定eax为第一个参数,同时eax也是返回值,暂不考虑参数不合法的情况),直接上代码:
sum_one_to_n:
mov ebx, 0
_go_on:
cmp eax, 0
je _get_out:
add ebx, eax
sub eax, 1
jmp _go_on
_get_out:
mov eax, ebx
ret
你可以发现,在这个函数中,不可避免地需要使用到eax之外的寄存器。但是有一个很致命的问题,调用方或者更上层的函数如果使用了ebx寄存器,这里又拿来用,最终,这个sum_one_to_n不小心把上层函数的状态给改了,最后结果和前面的递归例子差不多,总之不是什么好结果。
那么,这里就需要在使用ebx之前,先把ebx保存起来,使用完了之后,再把ebx恢复回来,就不会产生上述问题了。好了,接下来就需要调整代码了,只需要加一行push和pop就能完事儿了。像这样:
sum_one_to_n:
push ebx
mov ebx, 0
_go_on:
cmp eax, 0
je _get_out:
add ebx, eax
sub eax, 1
jmp _go_on
_get_out:
mov eax, ebx
pop ebx
ret
在函数的第一行和倒数第二行分别加入了push ebx和pop ebx指令。
通过push ebx,将当前的ebx寄存器保存起来。
通过pop ebx,堆栈中保存的ebx寄存器恢复回来。
当然了,进行push和pop的时候也得稍加小心,破坏了call指令保存到堆栈中的返回地址,也会坏事的。不过好在,函数内的入栈和出栈操作是保持一致的,不会影响到call指令保存的返回地址,也就不会影响到ret指令的正常工作。
再来递归
那么,我们就已经解决了函数内保存局部状态的问题了,其中的套路之一便是,让函数在使用某个寄存器之前,先把旧的值保存起来,等用完了之后再恢复回去,那么这个函数执行完毕后,所有的寄存器都是干干净净的,不会被函数玷污。
有了push和pop的解决方案,那么前面那个递归的问题也可以解决了。
先来分析下:
fibo:
cmp eax, 1
je _get_out
cmp eax, 2
je _get_out
mov edx, eax
sub eax, 1
call fibo
mov ebx, eax
mov eax, edx
sub eax, 2
call fibo
mov ecx, eax
mov eax, ebx
add eax, ecx
ret
_get_out:
mov eax, 1
ret
这段代码中使用到了除eax之外的寄存器有ebx、ecx、edx三个。为了保证这三个寄存器不会在不同的递归层级串场,我们需要在函数内使用它们之前将其保存起来,等到不用了之后再还原回去(注意入栈和出栈的顺序是需要反过来的),像这样:。
fibo:
global main
fibo:
cmp eax, 1
je _get_out
cmp eax, 2
je _get_out
push ebx
push ecx
push edx
mov edx, eax
sub eax, 1
call fibo
mov ebx, eax
mov eax, edx
sub eax, 2
call fibo
mov ecx, eax
mov eax, ebx
add eax, ecx
pop edx
pop ecx
pop ebx
ret
_get_out:
mov eax, 1
ret
main:
mov eax, 7
call fibo
ret
编译运行一看,第7项的值为13,诶,这下结果可靠了。我们得到了一个汇编语言实现的、通过递归调用来计算斐波那契数列某一项值的函数。
写在后面
前面扯了这么多,我们说到了这样一些东西:
- 函数调用相关指令
- 通过寄存器传递参数和返回值
- 函数调用后的返回地址会保存到堆栈中
- 函数的局部状态也可以保存到堆栈中
C语言中的函数
在C语言中,x86的32位环境的一般情况下,函数的参数并不是通过寄存器来传递的,返回值也得视情况而定。这取决于编译器怎么做。
实际上,一些基本数据类型,以及指针类型的返回值,一般是通过寄存器eax来传递的,也就是和前面写的汇编一个套路。而参数就不是了,C中的参数一般是通过堆栈来传递的,而非寄存器(当然也可以用寄存器,不过需要加一些特殊的说明)。这里准备了一个例子,供大家体会一下C语言中通过堆栈传递参数的感觉:
(在32位环境下编译)
#include <stdio.h>
int sum(int n, int a, ...) {
int s = 0;
int *p = &a;
for(int i = 0; i < n; i ++) {
s += p[i];
}
return s;
}
int main() {
printf("%d\n", sum(5, 1, 2, 3, 4, 5));
return 0;
}
编译运行:
$ gcc -std=c99 -m32 demo.c -o demo
$ ./demo
15
函数的参数是逐个放到堆栈中的,通过第一个参数的地址,可以挨着往后找到后面所有的参数。你还可以尝试把参数附近的内存都瞧一遍,还能找到混杂在堆栈中的返回地址。
若读者想要对C的函数机制一探究竟,可以尝试编写一些简单的程序,进行反汇编,研究整个程序在汇编这个层面,到底在做些什么。
好了,汇编语言的函数相关部分就可以告一段落了。这部分涉及到一个非常重要的东西:堆栈。这个需要读者下来多了解一些相关的资料,尝试反汇编一些有函数调用的C程序,结合相关的资料不断动手搞事情,去实实在在地体会一下堆栈。
文中若有疏漏或不当之处,欢迎指正。
3.1.9 - 汇编语言入门九:总结与后续(闲扯)
回顾
前面扯了一些个汇编语言的内容,想必读者也应该有了大致的了解。笔者比打算写全面的汇编相关的内容,毕竟目前已经有不少相关的资料了。本入门系列的目的就在于:入门。
完成了入门的任务,入门系列就暂告一段落了。在此,先来对前面提及的内容做一些回顾。前面说到的各项内容大概涉及:
- 环境配置
- 寄存器
- 内存访问
- 流程控制
- 函数调用
- 反汇编
- 调试
我想,学习汇编中比较容易犯难的几个环节,大致也都覆盖到了。并且教程中也提供了可运行的实例,供读者在学习之后用于验证。
学汇编到底学什么
我想,很多新手在了解汇编语言的时候,难免会遇到各种蛋疼的问题。大致有这样一些情况:
- 有参考书,虽然书中的知识体系全面,但是内容多却晦涩难懂
- 内容老旧,一时找不到合适的试验环境来验证,仅仅停留于书本,缺乏强烈直观的感受
- 各种规范各种环境乱七八糟不统一,讨论汇编时太依赖于特定环境,进一步加大了动手验证的难度
这无疑是给学习者泼来一盆冷水,本来只有3分的热情被灭掉了余下0.3分。
其实学习汇编语言,和学习C语言就有所不同了。你不用想着以后用汇编进行编程,学习汇编语言的首要目标是理解CPU运行程序的时候到底在干什么,你编写的C程序或者其他什么代码在CPU的眼里到底是个什么玩意儿,你能够通过汇编去分析程序的行为,解释一些高级语言下无法解释的现象,等等,才是学习的目标。
也就是说,学习汇编语言,应该抱着理解的目标去学习,理解透彻便足矣,无需做到能够流利地用汇编进行编程。
即便如此,笔者前面所述的各方面入门内容也仅仅是入门。不同人有不同的学习历程、只是背景,笔者很难保证自己觉得足够的入门教程,能够让每个读者都刚好受用。鉴于此,笔者将列出在了解了入门内容后需要关心的内容。
后续
前面也有提到,学习汇编所需要侧重的是理解,而非熟练地编代码。汇编语言更像是一套理论知识,用于分析和解释程序在足够底层时的行为和现象。
与其说学习汇编,不如说是揭开高级语言的面纱,深入到更底层的地方去了解计算机原理,靠近计算机程序的本质。深入理解底层原理,有助于建立对计算机更系统的更深入的认识,面对一些看似诡异的问题时能心中有数,有方法有思路有理据去分析和解决。
要做到这一点,是需要循序渐进慢慢学习的。读者可在后续关注这样一些内容:
继续学习汇编语言
笔者前面所述的入门内容只能保证覆盖了核心内容,并未覆盖到汇编语言相关的方方面面。读者至少要让自己学习汇编知识覆盖面达到足以形成图灵完备的最小集合。
可以从分析高级语言(比如C)去学习汇编语言,如前面所述的反汇编。关注这样一些内容:
- 指令
- 寄存器
- 内存访问
- 条件跳转
- 堆栈
- 程序状态
这些概念不仅在x86体系下,在ARM或是MIPS体系下也适用。仅仅是在不同环境下有不同的思路,有不同的表现形式,但是,核心的概念都是一致的。
计算机组成原理
到这里,便是让你对所有计算机系统的认识有一个大统一。上面说到不同CPU平台下都有相当的共性。组成原理便是对所有计算机系统的大统一,不同平台只是在根据自己的目标特点和偏好在对计算机原理进行应用而已。
组成原理会告诉你,计算机在电路这个层面的本质是什么。
有了上述的汇编、组成原理的认识,同时也还应该去了解计算机操作系统。这里所谓的操作系统是指站在专业的角度,讨论操作系统本质上是在做什么事情,解决什么问题。
这些基础知识将会作为今后进一步学习计算机的坚实基础,基于对计算机、对操作系统的理解,计算机中的一切都将不再神秘,其本质都不过如此,基于自己所学去分析、去理解即可。
学习方法
笔者在学习的过程中,也尝试过总结适合自己的方法,在此也谈一谈自己学习的方式。
虽然微积分揭示了自然现象和数学之间很多本质的东西,但是让一个小学生直接学习的话,难免会困难重重。这里的问题并不在于知识体系不够全面、不够严谨,而在于学习者对微积分没有基本的感性认识,根本不知道是个啥玩意儿(计算期末考试分数的新方法?),即使记住了这些公式和证明,但自身难以去自行演绎,这其实是无效的学习。
所以,借助此例,结合自身经历,笔者认为学习的时候应该先关注下面一些方面:
寻求感性认识
学习一个陌生的东西,我都会尝试先寻求一个感性的认识,感性认识达到什么程度呢?就是做到自己能够用一些简洁的白话,把自己接下来要学习的东西到底是什么玩意儿,给解释清楚,最好能够做到让不明白的人也能听明白。
比如什么是计算机?你能想到的就是你面对的那一台电脑,里面有丰富的的软件,可以做很多有趣的事情。
了解边界
笔者所谓的边界,即接下来要学习的这个东西,能做什么,不能做什么。学习之前明白这一点也非常重要,基于此,便能有一个清晰的目标,对学习后会面对的问题也有一定的底。
比如计算机是无法直接驱动一个火箭上天的,但是能够对航天器的行为进行控制。
让学习可验证
学习过程中自己会思考,会想出很多问题,但是这些问题并非都能从书中找到答案。而在学习过程中要刻意的去养成对知识、对自己的新想法进行验证的习惯。这里面大致是这样的过程:
- 脑子里冒出来一个想法,可能是疑惑,可能是矛盾
- 猜想一种最可能的情况来解释
- 通过实践去验证自己的猜想
- 总结、回顾(验证后的结果不能解释自己的猜想,会去重新猜)
这里的动手验证不是说真的得去拿个锤子砸钉子,而是说这里的分析、思考、试验、演绎等过程需要落到实处,而不是看到了某个模糊的说法,就这样糊弄过去了。
学习时尽量去给自己建立一个足以验证自己所学的环境,或者至少保证自己有了问题知道怎么样去验证。这将是支撑持续而有效学习的可能性和动力的重要基础。
比如通过编程、调试这样的手段去面对语言学习时的各种不解、各种矛盾的问题。通过编程看到结果、进行试验,透过调试去分析、简化学习中的稳题。有搞不明白的代码了,就赶紧编个程序来验证,尽量根据自己的想法把程序写出花儿来,看看到底都发生了些什么。
Over
关于汇编的专门介绍到此就告一段落了,后续笔者将会出更多相关话题的内容,不过内容的深度和难度都会有所上升,也可能更加抽象。
文中若有疏漏或不当之处,欢迎指正。
4 - JavaScript
JavaScript
4.1 - Html+Jquery
这个目录里面的内容均整理在2017年以前。有些内容已经不适合现在的项目了, 用之前需要整理和验证
4.1.1 - jquery插件开发
<!DOCTYPE html>
<html lang="en" >
<head>
<meta charset="utf-8" />
<title>HTML5 时钟</title>
<link href="css/main.css" rel="stylesheet" type="text/css" />
<script src="http://code.jquery.com/jquery-latest.min.js"></script>
<style>
.clocks {
height: 500px;
margin: 25px auto;
position: relative;
width: 500px;
}
</style>
</head>
<body>
<ul>
<li>
<a href="http://www.webo.com/liuwayong">我的微博</a>
</li>
<li>
<a href="http://http://www.cnblogs.com/Wayou/">我的博客</a>
</li>
<li>
<a href="http://wayouliu.duapp.com/">我的小站</a>
</li>
</ul>
<div>
这是div标签
</div>
</body>
<script>
/*
1.直接扩展jquery 添加方法 sayHello();
*/
// $.extend({
// sayHello: function(name) {
// alert('Hello,' + (name ? name : 'Dude'));
// }
// });
// $.sayHello(); //调用
// $.sayHello('Wayou'); //带参调用
/*
2.在全局空间定义myPlugin
*/
// $.fn.myPlugin = function(options) {
// var defaults = {//定义默认参数
// 'color': 'red',
// 'fontSize': '12px'
// };
// var settings = $.extend({}, defaults, options);//合并用户的options 和默认的defaults到插件空间
// return this.css({//返回方法,利于链式操作
// 'color': settings.color,
// 'fontSize': settings.fontSize
// });
// }
// $(function(){
// $('a').myPlugin({
// 'color': '#2C9929',
// 'fontSize': '36px'
// });
// $('div').myPlugin();
// })
/*
3.在全局空间中定义匿名函数,中定义一个插件
在匿名函数前面加一个";"是一个好的习惯
($, window, document, undefined)匿名函数的参数是为了防止其他人全局屏蔽这几个参数
*/
;(function($, window, document, undefined){
//定义Beautifier的构造函数
var Beautifier = function(ele, opt) {
this.$element = ele,
this.defaults = {
'color': 'red',
'fontSize': '12px',
'textDecoration':'none'
},
this.options = $.extend({}, this.defaults, opt)
}
//定义Beautifier的方法
Beautifier.prototype = {
beautify: function() {
return this.$element.css({
'color': this.options.color,
'fontSize': this.options.fontSize,
'textDecoration': this.options.textDecoration
});
}
}
//在插件中使用Beautifier对象
$.fn.myPlugin = function(options) {
//创建Beautifier的实体
var beautifier = new Beautifier(this, options);
//调用其方法
//return beautifier;//用于3.1调用
return beautifier.beautify();//用于3.2调用
}
})(jQuery, window, document);
//3.1调用
// $(function() {
// $('a').myPlugin({
// 'color': '#2C9929',
// 'fontSize': '12px'
// }).beautify();
// })
//3.2调用
$(function(){
$('a').myPlugin({
'color': '#2C9929',
'fontSize': '20px',
'textDecoration': 'underline'
});
});
</script>
</html>
4.1.2 - js获取各种节点的方法
如何获取要更新的元素,是首先要解决的问题。令人欣慰的是,使用JavaScript获取节点的方法有很多种,这里简单做一下总结(以下方法在IE7和Firefox2.0.0.11测试通过):
1. 通过顶层document节点获取:
(1) document.getElementById(elementId):该方法通过节点的ID,可以准确获得需要的元素,是比较简单快捷的方法。如果页面上含有多个相同id的节点,那么只返回第一个节点。
如今,已经出现了如prototype、Mootools等多个JavaScript库,它们提供了更简便的方法:$(id),参数仍然是节点的id。这个方法可以看作是document.getElementById()的另外一种写法,不过$()的功能更为强大,具体用法可以参考它们各自的API文档。
(2)document.getElementsByName(elementName):该方法是通过节点的name获取节点,从名字可以看出,这个方法返回的不是一个节点元素,而是具有同样名称的节点数组。然后,我们可以通过要获取节点的某个属性来循环判断是否为需要的节点。
例如:在HTML中checkbox和radio都是通过相同的name属性值,来标识一个组内的元素。如果我们现在要获取被选中的元素,首先获取改组元素,然后循环判断是节点的checked属性值是否为true即可。
(3)document.getElementsByTagName(tagName):该方法是通过节点的Tag获取节点,同样该方法也是返回一个数组,例如:document.getElementsByTagName('A')将会返回页面上所有超链接节点。在获取节点之前,一般都是知道节点的类型的,所以使用该方法比较简单。但是缺点也是显而易见,那就是返回的数组可能十分庞大,这样就会浪费很多时间。那么,这个方法是不是就没有用处了呢?当然不是,这个方法和上面的两个不同,它不是document节点的专有方法,还可以应用其他的节点,下面将会提到。
2、通过父节点获取:
(1)parentObj.firstChild:如果节点为已知节点(parentObj)的第一个子节点就可以使用这个方法。这个属性是可以递归使用的,也就是支持parentObj.firstChild.firstChild.firstChild...的形式,如此就可以获得更深层次的节点。
(2)parentObj.lastChild:很显然,这个属性是获取已知节点(parentObj)的最后一个子节点。与firstChild一样,它也可以递归使用。
在使用中,如果我们把二者结合起来,那么将会达到更加令人兴奋的效果,即:parentObj.firstChild.lastChild.lastChild...
(3)parentObj.childNodes:获取已知节点的子节点数组,然后可以通过循环或者索引找到需要的节点。
注意:经测试发现,在IE7上获取的是直接子节点的数组,而在Firefox2.0.0.11上获取的是所有子节点即包括子节点的子节点。
(4)parentObj.children:获取已知节点的直接子节点数组。
注意:经测试,在IE7上,和childNodes效果一样,而Firefox2.0.0.11不支持。这也是为什么我要使用和其他方法不同样式的原因。因此不建议使用。
(5)parentObj.getElementsByTagName(tagName):使用方法不再赘述,它返回已知节点的所有子节点中类型为指定值的子节点数组。例如:parentObj.getElementsByTagName('A')返回已知的子节点中的所有超链接。
3、通过临近节点获取:
(1)neighbourNode.previousSibling:获取已知节点(neighbourNode)的前一个节点,这个属性和前面的firstChild、lastChild一样都似乎可以递归使用的。
(2)neighbourNode.nextSibling:获取已知节点(neighbourNode)的下一个节点,同样支持递归。
4、通过子节点获取:
(1)childNode.parentNode:获取已知节点的父节点。
上面提到的方法,只是一些基本的方法,如果使用了Prototype等JavaScript库,可能还获得其他不同的方法,例如通过节点的class获取等等。不过,如果能够灵活运用上面的各种方法,相信应该可以应付大部分的程序
4.1.3 - reset.css
@charset "utf-8";
/*css reset*/
body,nav,dl,dt,dd,p,h1,h2,h3,h4,ul,ol,li,input,button,textarea,footer{margin:0;padding:0}
body{font:16px/1.5 'Microsoft Yahei','Simsun'; color:#333;background:#fff;-webkit-text-size-adjust: none; min-width:320px;}
h1,h2,h3,h4,h5,h6{font-size:100%}
form{display:inline}
ul,ol{list-style:none}
a{text-decoration:none;color:#1a1a1a}
a:hover, a:active, a:focus{color:#1a1a1a;text-decoration: none;}
a:active{color:#1a1a1a;}
img{vertical-align:middle;border:0;-ms-interpolation-mode:bicubic;}
button,input,select,textarea{font-size:100%; vertical-align:middle;outline:none;}
textarea{resize:none}
button,input[type="button"],input[type="reset"],input[type="submit"] {cursor:pointer;-webkit-appearance:button;-moz-appearance:button}
input:focus:-moz-placeholder,input:focus::-webkit-input-placeholder {color:transparent}
button::-moz-focus-inner,input::-moz-focus-inner { padding:0; border:0}
table { border-collapse:collapse; border-spacing:0}
.fl{float:left;}.fr{float:right;}.hide{display:none;}.show{display: block;}
.ellipsis { white-space:nowrap; text-overflow:ellipsis; overflow:hidden}
.break { word-break:break-all; word-wrap:break-word}
header, footer, article, section, nav, menu, hgroup {display: block;clear:all;}
.clear {zoom:1;}
.clear:after {content:'';display:block;clear:both;height:0;}
.main{width: 100%;font-size: 62.5%;}
4.1.4 - 曾经的纯JavaScript基础
如题这是曾经纯JavaScript基础,有些写法语法和最新得瑟ES6语法不适用了。留作纪念吧!
控制台输出内容 console.log("content");
数据类型:
Number(整数,浮点数,NaN, Infinity)
Boolean
null表示一个"空"的值
undefined表示"未定义"
NaN === NaN; // false
isNaN(NaN); // true
一定要使用静态模式
在文件或者脚本的最上面写上'use strict'
之后定义变量必须使用var关键字,如果忘记写var则会在控制台报ReferenceError错误
创建对象的构造函数,在strict模式下,this.name = name将报错,因为this绑定为undefined,在非strict模式下,this.name = name不报错,因为this绑定为window,于是无意间创建了全局变量name,并且返回undefined,这个结果更糟糕。
字符串可以用 `` 支持多行模式
alert(`多行
字符串
测试`);
字符串常用
s.length;
s.toUpperCase();//大写
s.toLowerCase();//小写
s.indexOf("..");搜索指定字符串出现的位置
s.substring(0, 5); // 从索引0开始到5(不包括5),返回'hello'
s.substring(7); // 从索引7开始到结束,返回'world'
数组常用
arr.length;
arr.indexOf(value);元素 value 的索引位置
arr.slice();//对应string的substring函数
push('A', 'B')向Array的末尾添加若干元素
arr.pop();//删除数组最后的元素并返回它
arr.unshift('A', 'B');//往Array的头部添加若干元素
arr.shift();//删除数组第一个元素并返回
arr.sort();//数组排序,具体在函数部分
arr.reverse();//反转数组
arr.concat(arr2);//连接两个数组
arr.join('-');//用-将数组连接起来成字符串
对象常用
obj.属性key = 属性value;
delete obj.属性key
'属性key' in ojb;//属性key是否在obj中,继承的也算
obj.hasOwnProperty('属性key');只判断属性key是否在当前对象中
for (var i in 可迭代集合)
for...of//可以循环数组,map,set)
for(var x of a)
var a = ['A', 'B', 'C'];
a.forEach(function (element, index, 被迭代对象) {
// element: 指向当前元素的值
// index: 指向当前索引
// 被迭代对象: 被迭代对象本身
alert(element);
});
map--键值存储
m = new Map([['Michael', 95], ['Bob', 75], ['Tracy', 85]]);//初始化一个map
m.set('Adam', 67);
m.has('Adam');
m.get('Adam');
m.delete('Adam');
set--不重复集合
var s1 = new Set(); // 空Set
var s2 = new Set([1, 2, 3]); // 含1, 2, 3
s.add(4)
s.delete(3);
函数
arguments关键字,收集函数的所有参数到数组(这是隐藏的可以直接使用)
rest关键字定义变量可以 function foo(a,b, ...rest)
除了前两个参数,后面的存在rest数组中
apply
函数名.apply(被绑定对象, 函数参数)//这样使用时在函数体内的this关键字都是指向"被绑定对象"
call -- 与apply区别
apply()把参数打包成Array再传入
call()把参数按顺序传入
Math.max.apply(null, [3, 5, 4]); // 5
Math.max.call(null, 3, 5, 4); // 5
map() reduce()
filter(匿名函数)//过滤,根据匿名函数返回Boolean值决定是否保留
排序函数sort(),原则是按照(规定,对于两个元素x和y,如果认为x < y,则返回-1,如果认为x == y,则返回0,如果认为x > y,则返回1,这样,排序算法就不用关心具体的比较过程,而是根据比较结果直接排序。),并且会修改原数组
数字从小到大排序//从大到小
arr.sort(function (x, y) {
if (x < y) {
return -1;//return 1
}
if (x > y) {
return 1;//return -1
}
return 0;
});
//对字符串数组排序(按照ASCII的小到大)
arr.sort(function (s1, s2) {
x1 = s1.toUpperCase();
x2 = s2.toUpperCase();
if (x1 < x2) {
return -1;
}
if (x1 > x2) {
return 1;
}
return 0;
});
闭包
箭头函数(相当于匿名函数)//还是用匿名函数吧
作用域
使用一个全局变量推荐 window.变量
自己写代码推荐使用一个名字空间(就是建立一个对象,自己的变量都当做对象属性操作)
申明一个块级变量用let
申请一个常量const PI = 3.14;//不可修改
生成器function* fib(参数) {}
js引擎遇到yield就会停止并返回yield后值,并保持函数执行的所有状态,下次调用从上次yield的后面接着执行
调用生成器
一
var f = fib(5);
f.next();
f.next();
f.next();
f.next();
f.next();
二
for (var x of fib(5)) {
console.log(x); // 依次输出0, 1, 1, 2, 3
}
js标准对象
typeof 123; // 'number'
typeof NaN; // 'number'
typeof 'str'; // 'string'
typeof true; // 'boolean'
typeof undefined; // 'undefined'
typeof Math.abs; // 'function'
typeof null; // 'object'
typeof []; // 'object'
typeof {}; // 'object'
总结一下,有这么几条规则需要遵守:
不要使用new Number()、new Boolean()、new String()创建包装对象;
用parseInt()或parseFloat()来转换任意类型到number;
用String()来转换任意类型到string,或者直接调用某个对象的toString()方法;
通常不必把任意类型转换为boolean再判断,因为可以直接写if (myVar) {...};
typeof操作符可以判断出number、boolean、string、function和undefined;
判断Array要使用Array.isArray(arr);
判断null请使用myVar === null;
判断某个全局变量是否存在用typeof window.myVar === 'undefined';
函数内部判断某个变量是否存在用typeof myVar === 'undefined'。
null和undefined没有toString()方法
number使用toString()要(123).toString();
JSON
var xiaoming = {
name: '小明',
age: 14,
gender: true,
height: 1.65,
grade: null,
'middle-school': '\"W3C\" Middle School',
skills: ['JavaScript', 'Java', 'Python', 'Lisp']
};
JSON.stringify(xiaoming); // '{"name":"小明","age":14,"gender":true,"height":1.65,"grade":null,"middle-school":"\"W3C\" Middle School","skills":["JavaScript","Java","Python","Lisp"]}'
JSON.stringify(xiaoming, null, ' ');
{
"name": "小明",
"age": 14,
"gender": true,
"height": 1.65,
"grade": null,
"middle-school": "\"W3C\" Middle School",
"skills": [
"JavaScript",
"Java",
"Python",
"Lisp"
]
}
JSON.stringify(xiaoming, ['name', 'skills'], ' ');
{
"name": "小明",
"skills": [
"JavaScript",
"Java",
"Python",
"Lisp"
]
}
JSON.stringify(xiaoming, convert, ' ');//每个键值都会被convert函数处理
function convert(key, value) {
if (typeof value === 'string') {
return value.toUpperCase();
}
return value;
}
在对象中重写toJSON
var xiaoming = {
name: '小明',
age: 14,
gender: true,
height: 1.65,
grade: null,
'middle-school': '\"W3C\" Middle School',
skills: ['JavaScript', 'Java', 'Python', 'Lisp'],
toJSON: function () {
return { // 只输出name和age,并且改变了key:
'Name': this.name,
'Age': this.age
};
}
};
JSON.stringify(xiaoming); // '{"Name":"小明","Age":14}'
反序列化json
JSON.parse('json字符串')
JSON.parse('json字符串', function(key, value){
//pass
});
js使用classs构建对象
class Student extends 父类{
//构造函数
constructor(name) {
super(name); // 记得用super调用父类的构造方法!
this.name = name;
}
hello() {
alert('Hello, ' + this.name + '!');
}
}
4.1.5 - 常用函数整理
/**
* --------------------------------------------------------------------------
* 小安整理的js函数
* --------------------------------------------------------------------------
* @package JavaScript_function
* @author azhw
* @since Version 1.0
*/
/*-------------------------------------
js获取当前url参数的两种方法
-------------------------------------*/
//方法一
function getQueryString(name) {
var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)", "i");
var r = window.location.search.substr(1).match(reg);
if (r != null) return unescape(r[2]); return null;
}
//调用
// alert(GetQueryString("参数名1"));
// alert(GetQueryString("参数名2"));
// alert(GetQueryString("参数名3"));
//方法二
function GetRequest() {
var url = location.search; //获取url中"?"符后的字串
var theRequest = new Object();
if (url.indexOf("?") != -1) {
var str = url.substr(1);
strs = str.split("&");
for(var i = 0; i < strs.length; i ++) {
theRequest[strs[i].split("=")[0]]=unescape(strs[i].split("=")[1]);
}
}
return theRequest;
}
//调用
// <Script language="javascript">
// var Request = new Object();
// Request = GetRequest();
// var 参数1,参数2,参数3,参数N;
// 参数1 = Request['参数1'];
// 参数2 = Request['参数2'];
// 参数3 = Request['参数3'];
// 参数N = Request['参数N'];
// </Script>
/*
---------------------------------------
*/
/*-------------------------------------
js获取屏幕大小
-------------------------------------*/
function a(){
document.write(
"屏幕分辨率为:"+screen.width+"*"+screen.height
+"<br />"+
"屏幕可用大小:"+screen.availWidth+"*"+screen.availHeight
+"<br />"+
"网页可见区域宽:"+document.body.clientWidth
+"<br />"+
"网页可见区域高:"+document.body.clientHeight
+"<br />"+
"网页可见区域宽(包括边线的宽):"+document.body.offsetWidth
+"<br />"+
"网页可见区域高(包括边线的宽):"+document.body.offsetHeight
+"<br />"+
"网页正文全文宽:"+document.body.scrollWidth
+"<br />"+
"网页正文全文高:"+document.body.scrollHeight
+"<br />"+
"网页被卷去的高:"+document.body.scrollTop
+"<br />"+
"网页被卷去的左:"+document.body.scrollLeft
+"<br />"+
"网页正文部分上:"+window.screenTop
+"<br />"+
"网页正文部分左:"+window.screenLeft
+"<br />"+
"屏幕分辨率的高:"+window.screen.height
+"<br />"+
"屏幕分辨率的宽:"+window.screen.width
+"<br />"+
"屏幕可用工作区高度:"+window.screen.availHeight
+"<br />"+
"屏幕可用工作区宽度:"+window.screen.availWidth
);
}
/*
------------------------------------------------
*/
/*-------------------------------------
js模拟鼠标除法点击
-------------------------------------*/
document.getElementById("target").onclick();
document.getElementById("target").click();
//btnObj.click()是真正地用程序去点击按钮,触发了按钮的onclick()事件
//btnObj.onclick()只是简单地调用了btnObj的onclick所指向的方法,只是调用方法而已,并未触发事件
/*-------------------------------------
js控制option
-------------------------------------*/
//循环一个一个移除,可控
/*
<select name="mySelect" id="selectID">
<option value=1>1</option>
<option value=2>2</option>
</select>
*/
var theSelect=document.all.mySelect;
for(var i=theSelect.options.length-1;i>=0;i--)
theSelect.options.remove(i);
//删除内容
document.getElementById("selectID").innerHTML = "";
//令长度为0
document.getElementById("selectID").options.length=0;
//删除制定位置的选项,在第一种里用过
document.getElementById("selectID").options.remove(index);
//添加内容
var selectObj=document.getElementById("selectID");
selectObj.options[selectObj.length] = new Option("mytest", "2");
//selectObj.options[index] = new Option("mytest", "2");
/*
---------------------------------------------------------
*/
/*-------------------------------------
js日期格式转换成时间戳
-------------------------------------*/
/**
2 0 1 5 - 0 4 - 0 5 _ 1 0 : 1 0 : 1 0
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
注: 下划线(_) 代表空格
*/
function transdate(endTime){
var date=new Date();
date.setFullYear(endTime.substring(0,4));
date.setMonth(endTime.substring(5,7)-1);
date.setDate(endTime.substring(8,10));
date.setHours(endTime.substring(11,13));
date.setMinutes(endTime.substring(14,16));
date.setSeconds(endTime.substring(17,19));
return Date.parse(date)/1000;
}
/*
------------------------------------------
*/
/*-------------------------------------
JavaScript 获取当前时间戳:
-------------------------------------*/
var timestamp = Date.parse(new Date());
//结果:1280977330000 获取的时间戳是把毫秒改成000显示,
var timestamp = (new Date()).valueOf();
var timestamp=new Date().getTime();
//获取了当前毫秒的时间戳
/*-------------------------------------
js删除字符串最后一个字符
-------------------------------------*/
//字符串:string s = "1,2,3,4,5,"
//目标:删除最后一个 "," ---> "1,2,3,4,5"
var s = "1,2,3,4,5,";
s=s.substring(0,s.length-1);
alert(s);
/*-------------------------------------
js DOM树加载完成后加载或执行
-------------------------------------*/
// 1 === 2
$(function(){
$("#a").click(function(){
//adding your code here
});
});
//2 === 1
$(document).ready(function(){
$("#a").click(function(){
//adding your code here
});
});
/*-------------------------------------
js 页面加载完成后加载或执行
整个页面的document全部加载完成以后执行,
而且要求所有的外部图片和资源全部加载完成,
如果外部资源,例如图片需要很长时间来加载,那么这个js效果就会让用户感觉失效了。
js里的DOM加载完成后不知,待查
-------------------------------------*/
//1.
window.onload = function(){
$("#a").click(function(){
//adding your code here
});
}
//2.
function myfun(){
alert("this window.onload");
}
window.onload=myfun;//不要括号
/*-------------------------------------
js在页面输出日期和星期,时间
-------------------------------------*/
var Today = new Date();
var DateName = new Array("星期天", "星期一", "星期二", "星期三", "星期四", "星期五", "星期六");
var MonthName = new Array("1月", "2月", "3月", "4月", "5月", "6月", "7月", "8月", "9月", "10月", "11月", "12月");
document.write("<span class=\"date\">" + Today.getFullYear() + "年" + MonthName[Today.getMonth()] +
Today.getDate() + "日" + " " + DateName[Today.getDay()] + "</span>");
/*-------------------------------------
js控制input[type=text]获取失去焦点
-------------------------------------*/
<input type="text" value="xiaoan" name="nick_name" onfocus="if(this.value == 'xiaoan') this.value = 'xiao'" onblur="if(this.value =='') this.value = 'xiaoa'">
<pre>
onfocus="if(this.value == 'xiaoan') this.value = 'xiao'"
</pre>
<p>当输入框获得焦点时(onfocus) 如果当前值为xiaoan,那么把输入框的值写成xiao</p>
<pre>
onblur="if(this.value =='') this.value = 'xiaoa'"
</pre>
<p>当输入框失去焦点时(onblur) 如果当前值为'',那么把输入框的值写成xiaoa</p>
<p>反正最后达到一个效果让输入框不为空</p>
/*-------------------------------------
改变url参数并可以把不存在的参数添加进url最后
-------------------------------------*/
function changeURLPar(destiny, par, par_value){
var pattern = par+'=([^&]*)';
var replaceText = par+'='+par_value;
if (destiny.match(pattern)){
var tmp = '/\\'+par+'=[^&]*/';
tmp = destiny.replace(eval(tmp), replaceText);
return (tmp);
}
else{
if (destiny.match('[\?]')){
return destiny+'&'+ replaceText;
}
else{
return destiny+'?'+replaceText;
}
}
return destiny+'\n'+par+'\n'+par_value;
}
//destiny是目标字符串,比如是http://www.huistd.com/?id=3&ttt=3
//par是参数名,par_value是参数要更改的值,调用结果如下:
//changeURLPar(test, 'id', 99); // http://www.huistd.com/?id=99&ttt=3
//添加一个不存在的参数haha
//changeURLPar(test, 'haha', 33); // http://www.huistd.com/?id=99&ttt=3&haha=33
/*
--------------------------------------------------------------------------
*/
/**
* 生成一个自定义范围的随机数
*
* @returns {int}
*/
function GetRandomNum(Min, Max){
var Range = Max - Min;
var Rand = Math.random();
return(Min + Math.round(Rand * Range));
}
/*-------------------------------------
js获取各种节点的方法
-------------------------------------*/
1. 通过顶层document节点获取:
(1) document.getElementById(elementId):该方法通过节点的ID,可以准确获得需要的元素,是比较简单快捷的方法。如果页面上含有多个相同id的节点,那么只返回第一个节点。
如今,已经出现了如prototype、Mootools等多个JavaScript库,它们提供了更简便的方法:$(id),参数仍然是节点的id。这个方法可以看作是document.getElementById()的另外一种写法,不过$()的功能更为强大,具体用法可以参考它们各自的API文档。
(2)document.getElementsByName(elementName):该方法是通过节点的name获取节点,从名字可以看出,这个方法返回的不是一个节点元素,而是具有同样名称的节点数组。然后,我们可以通过要获取节点的某个属性来循环判断是否为需要的节点。
例如:在HTML中checkbox和radio都是通过相同的name属性值,来标识一个组内的元素。如果我们现在要获取被选中的元素,首先获取改组元素,然后循环判断是节点的checked属性值是否为true即可。
(3)document.getElementsByTagName(tagName):该方法是通过节点的Tag获取节点,同样该方法也是返回一个数组,例如:document.getElementsByTagName('A')将会返回页面上所有超链接节点。在获取节点之前,一般都是知道节点的类型的,所以使用该方法比较简单。但是缺点也是显而易见,那就是返回的数组可能十分庞大,这样就会浪费很多时间。那么,这个方法是不是就没有用处了呢?当然不是,这个方法和上面的两个不同,它不是document节点的专有方法,还可以应用其他的节点,下面将会提到。
2、通过父节点获取:
(1)parentObj.firstChild:如果节点为已知节点(parentObj)的第一个子节点就可以使用这个方法。这个属性是可以递归使用的,也就是支持parentObj.firstChild.firstChild.firstChild...的形式,如此就可以获得更深层次的节点。
(2)parentObj.lastChild:很显然,这个属性是获取已知节点(parentObj)的最后一个子节点。与firstChild一样,它也可以递归使用。
在使用中,如果我们把二者结合起来,那么将会达到更加令人兴奋的效果,即:parentObj.firstChild.lastChild.lastChild...
(3)parentObj.childNodes:获取已知节点的子节点数组,然后可以通过循环或者索引找到需要的节点。
注意:经测试发现,在IE7上获取的是直接子节点的数组,而在Firefox2.0.0.11上获取的是所有子节点即包括子节点的子节点。
(4)parentObj.children:获取已知节点的直接子节点数组。
注意:经测试,在IE7上,和childNodes效果一样,而Firefox2.0.0.11不支持。这也是为什么我要使用和其他方法不同样式的原因。因此不建议使用。
(5)parentObj.getElementsByTagName(tagName):使用方法不再赘述,它返回已知节点的所有子节点中类型为指定值的子节点数组。例如:parentObj.getElementsByTagName('A')返回已知的子节点中的所有超链接。
3、通过临近节点获取:
(1)neighbourNode.previousSibling:获取已知节点(neighbourNode)的前一个节点,这个属性和前面的firstChild、lastChild一样都似乎可以递归使用的。
(2)neighbourNode.nextSibling:获取已知节点(neighbourNode)的下一个节点,同样支持递归。
4、通过子节点获取:
(1)childNode.parentNode:获取已知节点的父节点。
/*-------------------------------------
js获取各种时间
-------------------------------------*/
var now = new Date();
now; // Wed Jun 24 2015 19:49:22 GMT+0800 (CST)
now.getFullYear(); // 2015, 年份
now.getMonth(); // 5, 月份,注意月份范围是0~11,5表示六月
now.getDate(); // 24, 表示24号
now.getDay(); // 3, 表示星期三
now.getHours(); // 19, 24小时制
now.getMinutes(); // 49, 分钟
now.getSeconds(); // 22, 秒
now.getMilliseconds(); // 875, 毫秒数
now.getTime(); // 1435146562875, 以number形式表示的时间戳
要获取当前时间戳,可以用:
if (Date.now) {
alert(Date.now()); // 老版本IE没有now()方法
} else {
alert(new Date().getTime());
}
function setCookie(name, value, day, path) {
var str = name + "=" + escape(value);
if (day != 0) {
var date = new Date();
var ms = day * 3600 * 1000 * 24;
date.setTime(date.getTime() + ms);
str += ';expires=' + date.toGMTString();
}//undefined
if (typeof (path) != 'undefined') {
str += ';path=' + path
}
document.cookie = str;
}
//获取cookie
function getCookie(c_name)
{
if (document.cookie.length > 0)
{
c_start = document.cookie.indexOf(c_name + "=")
if (c_start != -1)
{
c_start = c_start + c_name.length + 1
c_end = document.cookie.indexOf(";", c_start)
if (c_end == -1)
c_end = document.cookie.length
return unescape(document.cookie.substring(c_start, c_end))
}
}
return ""
}
//这两个函数可以与asp(Server.UrlEncode)、php(urlencode())很好的解码
var test1="http://www.wljcz.com/My first/";
var bb=encodeURIComponent(test1);
var nnow=decodeURIComponent(bb);
document.write(bb+ "<br />");
document.write(nnow);
4.1.6 - 分享到新浪等
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<!--分享到-->
<div class="arthdshare">
<!-- Baidu Button BEGIN -->
<div id="bdshare" class="bdshare_t bds_tools get-codes-bdshare">
<span class="bds_more">分享到:</span>
<a class="bds_qzone"></a>
<a class="bds_tsina"></a>
<a class="bds_tqq"></a>
<a class="bds_renren"></a>
<a class="bds_t163"></a>
<a class="shareCount"></a>
</div>
<script type="text/javascript" id="bdshare_js" data="type=tools&uid=6835930" ></script>
<script type="text/javascript" id="bdshell_js"></script>
<script type="text/javascript">
document.getElementById("bdshell_js").src = "http://bdimg.share.baidu.com/static/js/shell_v2.js?cdnversion=" + Math.ceil(new Date()/3600000)
</script>
<!-- Baidu Button END -->
</div>
<!--分享到-->
</body>
</html>
4.1.7 - 改变url参数并可以把不存在的参数添加进url最后
function changeURLPar(destiny, par, par_value)
{
var pattern = par+'=([^&]*)';
var replaceText = par+'='+par_value;
if (destiny.match(pattern))
{
var tmp = '/\\'+par+'=[^&]*/';
tmp = destiny.replace(eval(tmp), replaceText);
return (tmp);
}
else
{
if (destiny.match('[\?]'))
{
return destiny+'&'+ replaceText;
}
else
{
return destiny+'?'+replaceText;
}
}
return destiny+'\n'+par+'\n'+par_value;
}
destiny是目标字符串,比如是http://www.huistd.com/?id=3&ttt=3
par是参数名,par_value是参数要更改的值,调用结果如下:
changeURLPar(test, 'id', 99); // http://www.huistd.com/?id=99&ttt=3
添加一个不存在的参数haha
changeURLPar(test, 'haha', 33); // http://www.huistd.com/?id=99&ttt=3&haha=33
4.1.8 - 判断浏览器及版本
<!DOCTYPE HTML>
<html>
<head>
<title>JavaScript获取浏览器类型与版本</title>
<meta charset="utf-8"/>
<script type="text/javascript">
var Sys = {};
var ua = navigator.userAgent.toLowerCase();
var s;
(s = ua.match(/msie ([\d.]+)/)) ? Sys.ie = s[1] :
(s = ua.match(/firefox\/([\d.]+)/)) ? Sys.firefox = s[1] :
(s = ua.match(/chrome\/([\d.]+)/)) ? Sys.chrome = s[1] :
(s = ua.match(/opera.([\d.]+)/)) ? Sys.opera = s[1] :
(s = ua.match(/version\/([\d.]+).*safari/)) ? Sys.safari = s[1] : 0;
//以下进行测试
if (Sys.ie) document.write('IE: ' + Sys.ie);
if (Sys.firefox) document.write('Firefox: ' + Sys.firefox);
if (Sys.chrome) document.write('Chrome: ' + Sys.chrome);
if (Sys.opera) document.write('Opera: ' + Sys.opera);
if (Sys.safari) document.write('Safari: ' + Sys.safari);
</script>
<script type="text/javascript">
function getBrowserInfo(){
var Sys = {};
var ua = navigator.userAgent.toLowerCase();
var re =/(msie|firefox|chrome|opera|version).*?([\d.]+)/;
var m = ua.match(re);
Sys.browser = m[1].replace(/version/, "'safari");
Sys.ver = m[2];
return Sys;
}
document.write('<hr/>');
//获取当前的浏览器信息
var sys = getBrowserInfo();
//sys.browser得到浏览器的类型,sys.ver得到浏览器的版本
document.write(sys.browser + "的版本是:" + sys.ver);
</script>
</head>
<body>
</body>
</html>
4.1.9 - 瀑布流
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style type="text/css">
ul li {height: 50px; border: 1px solid red;}
</style>
<script type="text/javascript" src="jquery1.8.2.js"></script>
</head>
<body>
<ul>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
<li>1</li>
</ul>
</body>
<script type="text/javascript">
$(window).load(function(){
;(function($){
var is_do = true;
var range = 50; //距下边界长度/单位px
var maxnum = parseInt(10); //设置加载最多次数-页数
var num = 1; //当前页数
var totalheight = 0;
$(window).scroll(function(){
var srollPos = $(window).scrollTop(); //滚动条距顶部距离(页面超出窗口的高度)
var window_height = $(window).height();//浏览器窗体高度
var document_height = $(document).height();//文档高度
//浏览器窗体高度 + 滚动条距顶部距离 = 文档高度
console.log("滚动条到顶部的垂直高度: "+$(document).scrollTop());
console.log("页面的文档高度 :"+$(document).height());
console.log('浏览器的高度:'+$(window).height());
totalheight = parseFloat(window_height) + parseFloat(srollPos);
if ((document_height-range <= totalheight) && (num < maxnum) && is_do) {
is_do = false;
alert(1);
}
});
})(jQuery);
});
</script>
</html>
4.1.10 - 手机屏幕触摸
<!-- HTML5 -->
<!DOCTYPE html>
<html>
<head>
<title>TouchEvent测试</title>
<meta charset="gbk">
</head>
<body>
<h2>TouchEvent测试</h2>
<br />
<div id="version" style="border:2px solid black;background-color:yellow"></div>
<br />
<br />
<br />
<br />
<br />
<br />
<div id="result" style="border:2px solid red; color:red;">未触发事件!</div>
<div id="test" style="border:2px solid red">
<ul>
<li id="li1">测试条目1</li>
<li id="li2">测试条目2</li>
<li id="li3">测试条目3</li>
<li id="li4">测试条目4</li>
<li id="li5">测试条目5</li>
<li id="li6">测试条目6</li>
<li id="li7">测试条目7</li>
<li id="li8">测试条目8</li>
<li id="li9">测试条目9</li>
<li id="li10">测试条目10</li>
<li id="li11">测试条目11</li>
<li id="li12">测试条目12</li>
<li id="li13">测试条目13</li>
<li id="li14">测试条目14</li>
<li id="li15">测试条目15</li>
<li id="li16">测试条目16</li>
<li id="li17">测试条目17</li>
<li id="li18">测试条目18</li>
<li id="li19">测试条目19</li>
<li id="li20">测试条目20</li>
</ul>
</div>
<script type="text/javascript">
//全局变量,触摸开始位置
var startX = 0, startY = 0;
//touchstart事件
function touchSatrtFunc(evt) {
try
{
//evt.preventDefault(); //阻止触摸时浏览器的缩放、滚动条滚动等
var touch = evt.touches[0]; //获取第一个触点
var x = Number(touch.pageX); //页面触点X坐标
var y = Number(touch.pageY); //页面触点Y坐标
//记录触点初始位置
startX = x;
startY = y;
var text = 'TouchStart事件触发:(' + x + ', ' + y + ')';
document.getElementById("result").innerHTML = text;
}
catch (e) {
alert('touchSatrtFunc:' + e.message);
}
}
//touchmove事件,这个事件无法获取坐标
function touchMoveFunc(evt) {
try
{
//evt.preventDefault(); //阻止触摸时浏览器的缩放、滚动条滚动等
var touch = evt.touches[0]; //获取第一个触点
var x = Number(touch.pageX); //页面触点X坐标
var y = Number(touch.pageY); //页面触点Y坐标
var text = 'TouchMove事件触发:(' + x + ', ' + y + ')';
//判断滑动方向
if (x - startX != 0) {
text += '<br/>左右滑动';
}
if (y - startY != 0) {
text += '<br/>上下滑动';
}
document.getElementById("result").innerHTML = text;
}
catch (e) {
alert('touchMoveFunc:' + e.message);
}
}
//touchend事件
function touchEndFunc(evt) {
try {
//evt.preventDefault(); //阻止触摸时浏览器的缩放、滚动条滚动等
var text = 'TouchEnd事件触发';
document.getElementById("result").innerHTML = text;
}
catch (e) {
alert('touchEndFunc:' + e.message);
}
}
//绑定事件
function bindEvent() {
document.addEventListener('touchstart', touchSatrtFunc, false);
document.addEventListener('touchMoveFunc', touchMoveFunc, false);
document.addEventListener('touchend', touchEndFunc, false);
}
//判断是否支持触摸事件
function isTouchDevice() {
document.getElementById("version").innerHTML = navigator.appVersion;
try {
document.createEvent("TouchEvent");
alert("支持TouchEvent事件!");
bindEvent(); //绑定事件
}
catch (e) {
alert("不支持TouchEvent事件!" + e.message);
}
}
window.onload = isTouchDevice;
</script>
</body>
</html>
4.1.11 - 一些案例
-
js验证身份证号有效性 预览:
-
单选按钮单击一下选中再次单击取消选中 预览:
-
模拟js弹出框 预览alert 预览confirm 预览prompt
-
使用js加载器动态加载外部Javascript文件 无预览
-
html时钟 预览
-
jquery-barcode条形码 预览
-
jQuery1.11.0_20140330.chm 无预览
-
ajax异步提交表单 无预览
-
JQUERY字体超出省略号 预览
-
jqzoom_ev-2.3 商城的商品图片墙 预览 预览 预览 预览 预览 预览
-
一个管理端模板
-
标签切换 预览
-
模拟文件上传 预览
-
日期插件 预览
-
图片滚动 预览
-
网站常用简洁的TAB选项卡 预览
-
页码样式 预览
4.2 - 键盘事件编码
event.keycode大全(javascript)
keycode 8 = BackSpace BackSpace
keycode 9 = Tab Tab
keycode 12 = Clear
keycode 13 = Enter
keycode 16 = Shift_L
keycode 17 = Control_L
keycode 18 = Alt_L
keycode 19 = Pause
keycode 20 = Caps_Lock
keycode 27 = Escape Escape
keycode 32 = space space
keycode 33 = Prior
keycode 34 = Next
keycode 35 = End
keycode 36 = Home
keycode 37 = Left
keycode 38 = Up
keycode 39 = Right
keycode 40 = Down
keycode 41 = Select
keycode 42 = Print
keycode 43 = Execute
keycode 45 = Insert
keycode 46 = Delete
keycode 47 = Help
keycode 48 = 0 equal braceright
keycode 49 = 1 exclam onesuperior
keycode 50 = 2 quotedbl twosuperior
keycode 51 = 3 section threesuperior
keycode 52 = 4 dollar
keycode 53 = 5 percent
keycode 54 = 6 ampersand
keycode 55 = 7 slash braceleft
keycode 56 = 8 parenleft bracketleft
keycode 57 = 9 parenright bracketright
keycode 65 = a A
keycode 66 = b B
keycode 67 = c C
keycode 68 = d D
keycode 69 = e E EuroSign
keycode 70 = f F
keycode 71 = g G
keycode 72 = h H
keycode 73 = i I
keycode 74 = j J
keycode 75 = k K
keycode 76 = l L
keycode 77 = m M mu
keycode 78 = n N
keycode 79 = o O
keycode 80 = p P
keycode 81 = q Q at
keycode 82 = r R
keycode 83 = s S
keycode 84 = t T
keycode 85 = u U
keycode 86 = v V
keycode 87 = w W
keycode 88 = x X
keycode 89 = y Y
keycode 90 = z Z
keycode 96 = KP_0 KP_0
keycode 97 = KP_1 KP_1
keycode 98 = KP_2 KP_2
keycode 99 = KP_3 KP_3
keycode 100 = KP_4 KP_4
keycode 101 = KP_5 KP_5
keycode 102 = KP_6 KP_6
keycode 103 = KP_7 KP_7
keycode 104 = KP_8 KP_8
keycode 105 = KP_9 KP_9
keycode 106 = KP_Multiply KP_Multiply
keycode 107 = KP_Add KP_Add
keycode 108 = KP_Separator KP_Separator
keycode 109 = KP_Subtract KP_Subtract
keycode 110 = KP_Decimal KP_Decimal
keycode 111 = KP_Divide KP_Divide
keycode 112 = F1
keycode 113 = F2
keycode 114 = F3
keycode 115 = F4
keycode 116 = F5
keycode 117 = F6
keycode 118 = F7
keycode 119 = F8
keycode 120 = F9
keycode 121 = F10
keycode 122 = F11
keycode 123 = F12
keycode 124 = F13
keycode 125 = F14
keycode 126 = F15
keycode 127 = F16
keycode 128 = F17
keycode 129 = F18
keycode 130 = F19
keycode 131 = F20
keycode 132 = F21
keycode 133 = F22
keycode 134 = F23
keycode 135 = F24
keycode 136 = Num_Lock
keycode 137 = Scroll_Lock
keycode 187 = acute grave
keycode 188 = comma semicolon
keycode 189 = minus underscore
keycode 190 = period colon
keycode 192 = numbersign apostrophe
keycode 210 = plusminus hyphen macron
keycode 211 =
keycode 212 = copyright registered
keycode 213 = guillemotleft guillemotright
keycode 214 = masculine ordfeminine
keycode 215 = ae AE
keycode 216 = cent yen
keycode 217 = questiondown exclamdown
keycode 218 = onequarter onehalf threequarters
keycode 220 = less greater bar
keycode 221 = plus asterisk asciitilde
keycode 227 = multiply division
keycode 228 = acircumflex Acircumflex
keycode 229 = ecircumflex Ecircumflex
keycode 230 = icircumflex Icircumflex
keycode 231 = ocircumflex Ocircumflex
keycode 232 = ucircumflex Ucircumflex
keycode 233 = ntilde Ntilde
keycode 234 = yacute Yacute
keycode 235 = oslash Ooblique
keycode 236 = aring Aring
keycode 237 = ccedilla Ccedilla
keycode 238 = thorn THORN
keycode 239 = eth ETH
keycode 240 = diaeresis cedilla currency
keycode 241 = agrave Agrave atilde Atilde
keycode 242 = egrave Egrave
keycode 243 = igrave Igrave
keycode 244 = ograve Ograve otilde Otilde
keycode 245 = ugrave Ugrave
keycode 246 = adiaeresis Adiaeresis
keycode 247 = ediaeresis Ediaeresis
keycode 248 = idiaeresis Idiaeresis
keycode 249 = odiaeresis Odiaeresis
keycode 250 = udiaeresis Udiaeresis
keycode 251 = ssharp question backslash
keycode 252 = asciicircum degree
keycode 253 = 3 sterling
keycode 254 = Mode_switch
使用event对象的keyCode属性判断输入的键值
eg:if(event.keyCode==13)alert(“enter!”);
键值对应表
A 0X65 U 0X85
B 0X66 V 0X86
C 0X67 W 0X87
D 0X68 X 0X88
E 0X69 Y 0X89
F 0X70 Z 0X90
G 0X71 0 0X48
H 0X72 1 0X49
I 0X73 2 0X50
J 0X74 3 0X51
K 0X75 4 0X52
L 0X76 5 0X53
M 0X77 6 0X54
N 0X78 7 0X55
O 0X79 8 0X56
P 0X80 9 0X57
Q 0X81 ESC 0X1B
R 0X82 CTRL 0X11
S 0X83 SHIFT 0X10
T 0X84 ENTER 0XD
如果要使用组合键,则可以利用event.ctrlKey,event.shiftKey,event .altKey判断是否按下了ctrl键、shift键以及alt键
4.3 - ES6语法
声明变量
ES6之前声明变量的方式:var 、 let 、 const
var
- 变量提升: 声明的变量会提升到函数作用域的顶部
{
var a = 1;
}
console.log(a);
- var 可以声明多次
var a = 1;
var a = 2;
console.log(a);
let
- 块作用域,具有严格的作用于域
{
let a = 1;
console.log(a);
}
console.log(a); // ReferenceError: a is not defined
- let 只能声明一次
let a = 1;
let a = 2;
console.log(a); // SyntaxError: Identifier 'a' has already been declared
### const
1. const 声明的变量必须初始化,并且不能被改变
```javascript
const a;
console.log(a); // SyntaxError: Missing initializer in const declaration
const a = 1;
a = 2; // TypeError: Assignment to constant variable.
console.log(a);
解构表达式
- 数组解构
let arr = [1,2,3];
// 传统用法
// let a = arr[0];
// let b = arr[1];
// let c = arr[2];
// 解构用法
let [a,b,c] = arr;
- 对象解构
let obj = {
name: 'zhangsan',
age: 18
sex: 'male'
}
// 传统用法
let name = obj.name;
let age = obj.age;
let sex = obj.sex;
// 解构用法
let {name,age,sex} = obj;
console.log(name,age,sex);
字符串扩展
let str = "hello.vue";
console.log(str.startsWith("hello"));//true
console.log(str.endsWith(".vue"));//true
console.log(str.includes("e"));//true
console.log(str.includes("hello"));//true
//多行字符串
let ss = `<div>
<span>hello world<span>
</div>`;
console.log(ss);
// 2、字符串插入变量和表达式。变量名写在 ${} 中,${} 中可以放入 JavaScript 表达式。
function fun() {
return "这是一个函数"
}
let info = `我是${abc},今年${age + 10}了, 我想说: ${fun()}`;
console.log(info);
函数参数优化
- 默认值
//在ES6以前,我们无法给一个函数参数设置默认值,只能采用变通写法:
function add(a, b) {
// 判断b是否为空,为空就给默认值1
b = b || 1;
return a + b;
}
// 传一个参数
console.log(add(10));
//现在可以这么写:直接给参数写上默认值,没传就会自动使用默认值
function add2(a, b = 1) {
return a + b;
}
console.log(add2(20));
- 不定参数
function fun(...values) {
console.log(values.length)
}
fun(1, 2) //2
fun(1, 2, 3, 4) //4
- 箭头函数
// case1
var print = function (obj) {
console.log(obj);
}
var print = obj => console.log(obj);
print("hello");
// case2
var sum = function (a, b) {
c = a + b;
return a + c;
}
// case2 箭头函数1
var sum2 = (a, b) => a + b;
console.log(sum2(11, 12));
// case2 箭头函数2
var sum3 = (a, b) => {
c = a + b;
return a + c;
}
console.log(sum3(10, 20))
// case3 箭头函数+解构
const person = {
name: "jack",
age: 21,
language: ['java', 'js', 'css']
}
// 传统用法
function hello(person) {
console.log("hello," + person.name)
}
//箭头函数+解构
var hello2 = ({name}) => console.log("hello," +name);
hello2(person); // 直接把包含name属性的一个对象扔进来就行
对象优化
// case1
const person = {
name: "jack",
age: 21,
language: ['java', 'js', 'css']
}
// [
// "name",
// "age",
// "language"
// ]
console.log(Object.keys(person));
// [
// "jack",
// 21,
// [
// "java",
// "js",
// "css"
// ]
// ]
console.log(Object.values(person));
// [
// [
// "name",
// "jack"
// ],
// [
// "age",
// 21
// ],
// [
// "language",
// [
// "java",
// "js",
// "css"
// ]
// ]
// ]
console.log(Object.entries(person));//[Array(2), Array(2), Array(2)]
// case2
const target = { a: 1 };
const source1 = { b: 2 };
const source2 = { c: 3 };
//{a:1,b:2,c:3}
Object.assign(target, source1, source2);
// {
// "a": 1,
// "b": 2,
// "c": 3
// }
console.log(target);
// case3 声明对象简写
const age = 23
const name = "张三"
const person1 = { age: age, name: name }
const person2 = { age, name }
console.log(person2);
// case4 对象的函数属性简写
let person3 = {
name: "jack",
// 以前:
eat: function (food) {
console.log(this.name + "在吃" + food);
},
//箭头函数this不能使用,对象.属性
eat2: food => console.log(person3.name + "在吃" + food),
eat3(food) {
console.log(this.name + "在吃" + food);
}
}
person3.eat("香蕉");
person3.eat2("苹果")
person3.eat3("橘子");
// case5 对象拓展运算符
// 1、拷贝对象(深拷贝)
let p1 = { name: "Amy", age: 15 }
let someone = { ...p1 }
console.log(someone) //{name: "Amy", age: 15}
// 2、合并对象
let age1 = { age: 15 }
let name1 = { name: "Amy" }
let p2 = {name:"zhangsan"}
p2 = { ...age1, ...name1 }
console.log(p2)
map和reduce
数组中新增了map和reduce方法。
map():接收一个函数,将原数组中的所有元素用这个函数处理后放入新数组返回。
let arr = ['1', '20', '-5', '3'];
// arr = arr.map((item)=>{
// return item*2
// });
arr = arr.map(item=> item*2);
console.log(arr);
reduce() 为数组中的每一个元素依次执行回调函数,不包括数组中被删除或从未被赋值的元素,
[2, 40, -10, 6]
arr.reduce(callback,[initialValue])
/**
1、previousValue (上一次调用回调返回的值,或者是提供的初始值(initialValue))
2、currentValue (数组中当前被处理的元素)
3、index (当前元素在数组中的索引)
4、array (调用 reduce 的数组)
*/
let result = arr.reduce((a,b)=>{
console.log("上一次处理后:"+a);
console.log("当前正在处理:"+b);
return a + b;
},100);
console.log(result)
promise
promise 是一个对象,用于表示一个异步操作,有三种状态:pending(进行中)、fulfilled(已成功)和 rejected(已失败)。promise 对象的构造函数接受一个函数作为参数,该函数的两个参数分别是 resolve 和 reject。resolve 是一个函数,用于将 promise 状态从 pending 转换为 fulfilled,reject 是一个函数,用于将 promise 状态从 pending 转换为 rejected。promise 对象的 then 方法接受两个参数,第一个参数是 promise 成功的回调函数,第二个参数是 promise 失败的回调函数
设定一个功能
- 查出当前用户信息
- 按照当前用户的id查出他的课程
- 按照当前课程id查出分数
传统的写法
$.ajax({
url: "mock/user.json",
success(data) {
console.log("查询用户:", data);
$.ajax({
url: `mock/user_corse_${data.id}.json`,
success(data) {
console.log("查询到课程:", data);
$.ajax({
url: `mock/corse_score_${data.id}.json`,
success(data) {
console.log("查询到分数:", data);
},
error(error) {
console.log("出现异常了:" + error);
}
});
},
error(error) {
console.log("出现异常了:" + error);
}
});
},
error(error) {
console.log("出现异常了:" + error);
}
});
Promise可以封装异步操作 // mock shuju
// mock/user.json
{
"id": 1,
"name": "zhangsan",
"password": "123456"
}
//mock/user_corse_${obj.id}.json
{
"id": 10,
"name": "chinese"
}
// mock/corse_score_${data.id}.json
{
"id": 100,
"score": 90
}
// 第一种
let p = new Promise((resolve, reject) => {
//1、异步操作
$.ajax({
url: "mock/user.json",
success: function (data) {
console.log("查询用户成功:", data)
resolve(data);
},
error: function (err) {
reject(err);
}
});
});
p.then((obj) => {
return new Promise((resolve, reject) => {
$.ajax({
url: `mock/user_corse_${obj.id}.json`,
success: function (data) {
console.log("查询用户课程成功:", data)
resolve(data);
},
error: function (err) {
reject(err)
}
});
})
}).then((data) => {
console.log("上一步的结果", data)
$.ajax({
url: `mock/corse_score_${data.id}.json`,
success: function (data) {
console.log("查询课程得分成功:", data)
},
error: function (err) {
}
});
})
// 方法二
function get(url, data) {
return new Promise((resolve, reject) => {
$.ajax({
url: url,
data: data,
success: function (data) {
resolve(data);
},
error: function (err) {
reject(err)
}
})
});
}
get("mock/user.json")
.then((data) => {
console.log("用户查询成功~~~:", data)
return get(`mock/user_corse_${data.id}.json`);
})
.then((data) => {
console.log("课程查询成功~~~:", data)
return get(`mock/corse_score_${data.id}.json`);
})
.then((data)=>{
console.log("课程成绩查询成功~~~:", data)
})
.catch((err)=>{
console.log("出现异常",err)
});
模块化
hello.js
// 默认导出
export default {
sum(a, b) {
return a + b;
}
}
// 具名导出
// export const util = {
// sum(a, b) {
// return a + b;
// }
// }
// export {util}
//`export`不仅可以导出对象,一切JS变量都可以导出。比如:基本类型变量、函数、数组、对象。
user.js
var name = "jack"
var age = 21
function add(a,b){
return a + b;
}
export {name,age,add} // 导出了 变量和函数
main.js
import abc from "./hello.js"
import {name,add} from "./user.js"
abc.sum(1,2);
console.log(name);
add(1,3);
4.4 - mybatisSql语句拼装
mybatisSql语句拼装的html代码可以直接本地运行
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Mybatis Log Helper</title>
<meta name=viewport content="width=device-width,initial-scale=1,maximum-scale=1,user-scalable=no" />
<link rel="shortcut icon" href="" />
<script src="https://unpkg.com/vue@2.6.11/dist/vue.js"></script>
<!-- 引入样式 -->
<link rel="stylesheet" href="https://unpkg.com/element-ui/lib/theme-chalk/index.css">
<!-- 引入组件库 -->
<script src="https://unpkg.com/element-ui/lib/index.js"></script>
<style>
#app {
margin-top: 70px;
display: flex;
justify-content: space-evenly;
align-items: center;
font-family: "Helvetica Neue", Helvetica, "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "微软雅黑", Arial, sans-serif;
}
</style>
</head>
<body>
<div id="app">
<el-input type="textarea" v-model="pre" placeholder="请复制输入Mybatis打印的日志,须完整Prepareing语句和Parameter语句"
:rows="28" style="width: 600px"></el-input>
<el-button type="success" @click="convert" style="height: 60px; width: 80px;">转换</el-button>
<el-input type="textarea" v-model="res" placeholder="输出结果"
:rows="28" style="width: 600px"></el-input>
</div>
<script type="text/javascript">
const app = new Vue({
el: '#app',
data() {
return {
// 原始str
pre: '',
// 输出结果
res: ''
}
},
methods: {
convert() {
const str = this.pre
if (str.indexOf('Preparing') == -1 || str.indexOf('Parameters') == -1) {
this.$message({
message: '请将Preparing和Parameters语句复制进来',
type: 'error',
center: true
})
}
// str为完整的三行或两行SQL 提取预编译语句
// const prepare = str.substring(str.indexOf('Preparing') + 11, str.indexOf('\n'))
var prepare=""
var params=new Array()
var arr = str.split("\n");
for(const strItem of arr) {
if (strItem.indexOf("Preparing") != -1) {
prepare = strItem.substring(strItem.indexOf('Preparing') + 11)
// console.log("prepare="+prepare)
}
if (strItem.indexOf("Parameters") != -1) {
params.push(strItem.substring(strItem.indexOf('Parameters') + 12))
// console.log("params["+i+"]="+params[i])
}
}
if(params.length > 1) {
var placeholder = prepare.substring(prepare.indexOf('( ?')-1)
console.log(prepare)
for(let i=0; i < params.length-1;i++) {
prepare = prepare+','+placeholder
}
console.log(prepare)
}
var paramStr = params.join(',')
// 获取参数,去空格
paramStr = paramStr.replace(/ /g, '')
// 参数数组
const array = paramStr.split(',')
console.log(array)
// 循环替换占位符,字符串方式替换每次替换第一个
array.map(item => {
youKuoHaoWeiZhi = item.indexOf('(')
console.log(item+":右侧括号"+youKuoHaoWeiZhi)
let newValue = ""
if (youKuoHaoWeiZhi != -1) {
newValue = item.substring(0, item.indexOf('('))
console.log(item+":最新值"+newValue)
// 获取参数类型
const type = item.substring(item.indexOf('(') + 1, item.indexOf(')'))
console.log(item+":参数"+type)
if ('String' === type) {
newValue = "'" + newValue + "'"
}
} else {
newValue = item
}
prepare = prepare .replace('?', newValue)
})
this.res = prepare
}
}
})
// 返回字符串str中的第n字符串reg在str中的索引值index
function index(str, reg, n) {
if (!str || !reg || n <= 0) return -1
// 先求出第一个,再递归n-1
if (n === 1) {
return str.indexOf(reg)
}
// 注意n-1的索引后一定要加1,负责会一直是第一个reg的索引
return str.indexOf(reg, index(str, reg, n - 1) + 1)
}
// 测试index函数
// const str = 'hello world ok'
// const reg = 'o'
// console.log(index(str, reg, 3))
</script>
</body>
</html>
4.5 - Vue
看看人家的就行了:
4.6 - cookie、localStorage和sessionStorage 三者之间的区别以及存储、获取、删除等使用方式
写在前面:
前端开发的时候,在网页刷新的时候,所有数据都会被清空,这时候就要用到本地存储的技术,前端本地存储的方式有三种,分别是cookie,localstorage和sessionStorage ,这是大家都知道的。本文的主要内容就是针对这三者的存放、获取,区别、应用场景。有需要的朋友可以做一下参考,希望可以帮到大家。
本文首发于blog:obkoro1.com 本文版权归作者所有,转载请注明出处。
使用方式:
很多文档都是说了一大堆,后面用法都没有说,先要学会怎么用,不然后面的都是扯淡,所以这里我先把使用方式弄出来。
cookie:
保存cookie值:
var dataCookie='110';
document.cookie = 'token' + "=" +dataCookie; 复制代码
获取指定名称的cookie值
function getCookie(name) { //获取指定名称的cookie值
// (^| )name=([^;]*)(;|$),match[0]为与整个正则表达式匹配的字符串,match[i]为正则表达式捕获数组相匹配的数组;
var arr = document.cookie.match(new RegExp("(^| )"+name+"=([^;]*)(;|$)"));
if(arr != null) {
console.log(arr);
return unescape(arr[2]);
}
return null;
}
var cookieData=getCookie('token'); //cookie赋值给变量。复制代码
先贴这两个最基础的方法,文末有个demo里面还有如何设置cookie过期时间,以及删除cookie的、
localStorage和sessionStorage:
localStorage和sessionStorage所使用的方法是一样的,下面以sessionStorage为栗子:
var name='sessionData';
var num=120;
sessionStorage.setItem(name,num);//存储数据
sessionStorage.setItem('value2',119);
let dataAll=sessionStorage.valueOf();//获取全部数据
console.log(dataAll,'获取全部数据');
var dataSession=sessionStorage.getItem(name);//获取指定键名数据
var dataSession2=sessionStorage.sessionData;//sessionStorage是js对象,也可以使用key的方式来获取值
console.log(dataSession,dataSession2,'获取指定键名数据');
sessionStorage.removeItem(name); //删除指定键名数据
console.log(dataAll,'获取全部数据1');
sessionStorage.clear();//清空缓存数据:localStorage.clear();
console.log(dataAll,'获取全部数据2'); 复制代码
使用方式,基本上就上面这些,其实也是比较简单的。大家可以把这个copy到自己的编译器里面,或者文末有个demo,可以点开看看。
三者的异同:
上面的使用方式说好了,下面就唠唠三者之间的区别,这个问题其实很多大厂面试的时候也都会问到,所以可以注意一下这几个之间的区别。
生命周期:
cookie:可设置失效时间,没有设置的话,默认是关闭浏览器后失效
localStorage:除非被手动清除,否则将会永久保存。
sessionStorage: 仅在当前网页会话下有效,关闭页面或浏览器后就会被清除。
存放数据大小:
cookie:4KB左右
localStorage和sessionStorage:可以保存5MB的信息。
http请求:
cookie:每次都会携带在HTTP头中,如果使用cookie保存过多数据会带来性能问题
localStorage和sessionStorage:仅在客户端(即浏览器)中保存,不参与和服务器的通信
易用性:
cookie:需要程序员自己封装,源生的Cookie接口不友好
localStorage和sessionStorage:源生接口可以接受,亦可再次封装来对Object和Array有更好的支持
应用场景:
从安全性来说,因为每次http请求都会携带cookie信息,这样无形中浪费了带宽,所以cookie应该尽可能少的使用,另外cookie还需要指定作用域,不可以跨域调用,限制比较多。但是用来识别用户登录来说,cookie还是比stprage更好用的。其他情况下,可以使用storage,就用storage。
storage在存储数据的大小上面秒杀了cookie,现在基本上很少使用cookie了,因为更大总是更好的,哈哈哈你们懂得。
localStorage和sessionStorage唯一的差别一个是永久保存在浏览器里面,一个是关闭网页就清除了信息。localStorage可以用来夸页面传递参数,sessionStorage用来保存一些临时的数据,防止用户刷新页面之后丢失了一些参数。
浏览器支持情况:
localStorage和sessionStorage是html5才应用的新特性,可能有些浏览器并不支持,这里要注意。

cookie的浏览器支持没有找到,可以通过下面这段代码来判断所使用的浏览器是否支持cookie:
if(navigator.cookieEnabled) {
alert("你的浏览器支持cookie功能");//提示浏览器支持cookie
} else {
alert("你的浏览器不支持cookie");//提示浏览器不支持cookie }复制代码
数据存放处:
Cookie、localStorage、sessionStorage数据存放处
番外:各浏览器Cookie大小、个数限制。
cookie 使用起来还是需要小心一点,有兴趣的可以看一下这个链接。
demo链接
把上面的demo代码,上传到github上面了,有需要的小伙伴们,可以看一下。传送门
后话
最后要说的是:不要把什么数据都放在 Cookie、localStorage 和 sessionStorage中,毕竟前端的安全性这么低。只要打开控制台就可以任意的修改 Cookie、localStorage 和 sessionStorage的数据了。涉及到金钱或者其他比较重要的信息,还是要存在后台比较好。
最后:如需转载,请放上原文链接并署名。码字不易,感谢支持!本人写文章本着交流记录的心态,写的不好之处,不撕逼,但是欢迎指点。然后就是希望看完的朋友点个喜欢,也可以关注一下我。
blog网站 and 掘金个人主页
<script>
cookieFn();
strogeFn();
function cookieFn() {
var dataCookie='110';
document.cookie = 'token' + "=" +dataCookie;//直接设置cookie
function getCookie(name) { //获取指定名称的cookie值
// (^| )name=([^;]*)(;|$),match[0]为与整个正则表达式匹配的字符串,match[i]为正则表达式捕获数组相匹配的数组;
var arr = document.cookie.match(new RegExp("(^| )"+name+"=([^;]*)(;|$)"));
if(arr != null) {
console.log(arr,'正则表达式捕获数组相匹配的数组');
return unescape(arr[2]);
}
return null;
}
var cookieData=getCookie('token');
console.log(cookieData,'获取指定名称的cookie值');
function setTime() {
//存储cookie值并且设置cookie过期时间
var date=new Date();
var expiresDays=10;//设置十天过期
date.setTime(date.getTime()+expiresDays*24*3600*1000);
document.cookie="userId=828; expires="+date.toGMTString();
console.log(document.cookie,'存储cookie值并且设置cookie过期时间');
}
setTime();
function delCookie(cookieName1) {
//删除cookie
var date2=new Date();
date2.setTime(date2.getTime()-10001);//把时间设置为过去的时间,会自动删除
document.cookie= cookieName1+"=v; expires="+date2.toGMTString();
console.log(document.cookie,'删除cookie');
}
delCookie('userId');
}
function strogeFn() {
var name='sessionData';
var num=120;
sessionStorage.setItem(name,num);//存储数据
sessionStorage.setItem('value2',119);
let dataAll=sessionStorage.valueOf();//获取全部数据
console.log(dataAll,'获取全部数据');
var dataSession=sessionStorage.getItem(name);//获取指定键名数据
var dataSession2=sessionStorage.sessionData;//sessionStorage是js对象,也可以使用key的方式来获取值
console.log(dataSession,dataSession2,'获取指定键名数据');
sessionStorage.removeItem(name); //删除指定键名数据
console.log(dataAll,'获取全部数据1');
sessionStorage.clear();//清空缓存数据:localStorage.clear();
console.log(dataAll,'获取全部数据2');
}
</script>